Keras模型训练的断点续训、早停、效果可视化
训练:model.fit()函数
fit(x=None, y=None, batch_size=None, epochs=, verbose=, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=, steps_per_epoch=None, validation_steps=None, validation_freq=)
x:输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array y:标签,numpy array batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步 epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录 callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数 validation_split:~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀 validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱 class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练) sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’ initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用
效果可视化:keras.callbacks.History()函数
fit()函数训练时默认调用History函数,每轮训练收集损失和准确率,返回一个history的对象,其history.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
# 查看history对象中收集的数据 print(history.history.keys())
['acc', 'loss', 'val_acc', 'val_loss']
以此绘制训练精度/损失曲线图,观察:
- 模型收敛的速度(斜率)
- 模型是否已经收敛(稳定性)
- 模型是否过拟合(验证数据集)
# Visualize training history
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# Fix random seed for reproducibility
numpy.random.seed(7)
# Load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# Split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# Create model
model = Sequential()
model.add(Dense(12, input_dim=8, init='uniform', activation='relu'))
model.add(Dense(8, init='uniform', activation='relu'))
model.add(Dense(1, init='uniform', activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
history = model.fit(X, Y, validation_split=0.33, nb_epoch=150, batch_size=10, verbose=0) # List all data in history
print(history.history.keys())
# Summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left') plt.show()
# Summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left') plt.show()
# 训练-验证-精度:从精度图看,最后几次迭代的训练精度仍在上升,有可能过拟合,但对比验证集的效果差不多,应该没有过拟合
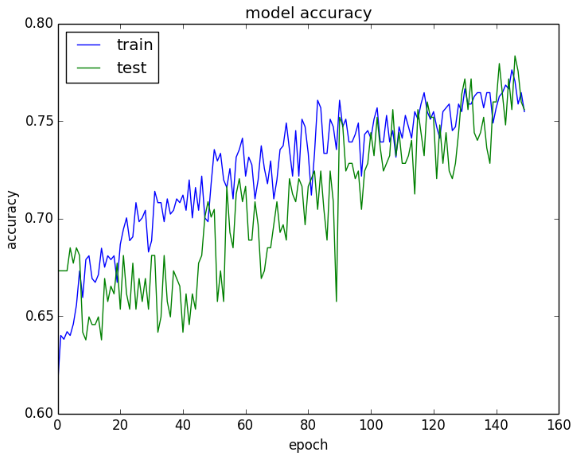
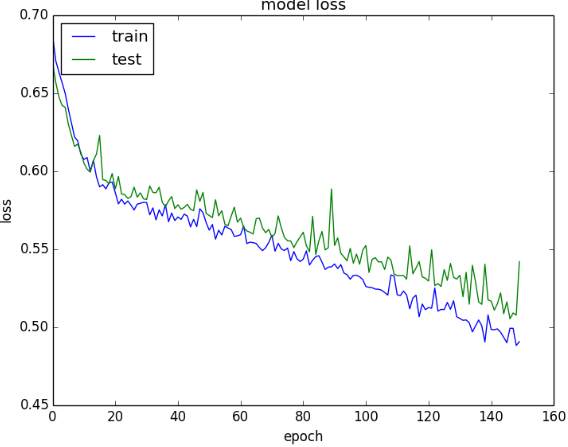
# 训练-验证-损失:从损失图看,训练集和验证集两个数据集的性能差不多(如果两条线开始分开,有可能应该提前终止训练)
效果可视化:TensorBoard()函数
TensorBoard是一个机器学习的可视化工具,能够有效地展示Tensorflow在运行过程中的计算图、各种指标随着时间的变化趋势以及训练中使用到的数据信息。
keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=0, write_graph=True, write_images=False, embeddings_freq=0, embeddings_layer_names=None, embeddings_metadata=None)
log_dir:保存日志文件的地址,该文件将被TensorBoard解析以用于可视化 histogram_freq:计算各个层激活值直方图的频率(每多少个epoch计算一次),如果设置为0则不计算。 write_graph: 是否在Tensorboard上可视化图,当设为True时,log文件可能会很大 write_images: 是否将模型权重以图片的形式可视化 embeddings_freq: 依据该频率(以epoch为单位)筛选保存的embedding层 embeddings_layer_names:要观察的层名称的列表,若设置为None或空列表,则所有embedding层都将被观察。 embeddings_metadata: 字典,将层名称映射为包含该embedding层元数据的文件名,参考这里获得元数据文件格式的细节。如果所有的embedding层都使用相同的元数据文件,则可传递字符串。
from keras.callbacks import Tensorboard
......
model_name = "kaggle_cat_dog-cnn-64x2-{}".format(int(time.time()))
tensorboard = TensorBoard(log_dir='logs/{}'.format(model_name))
callback_lists = [tensorboard] # 因为callback是list型,必须转化为list
model.fit(x_train,y_train,bach_size=batch_size,epochs=epoch,shuffle='True',verbose='True',callbacks=callback_lists)# 程序运行完毕之后,在python文件的同级文件夹下面会出现一个logs文件夹,文件夹下面会有存放我们刚才训练的模型的tfevent文件的目录




断点:keras.callbacks.Callback()函数 & keras.callbacks.ModelCheckpoint()函数
.Callback()
Blog:https://keras-cn.readthedocs.io/en/latest/other/callbacks/ https://machinelearningmastery.com/check-point-deep-learning-models-keras/ https://keras.io/callbacks/ http://keras-cn.readthedocs.io/en/latest/other/callbacks/ https://cloud.tencent.com/developer/article/1049579 http://keras-cn.readthedocs.io/en/latest/other/callbacks/#modelcheckpoint
回调函数callbacks是一组在训练的特定阶段被调用的函数集,训练阶段使用回调函数来观察训练过程中网络内部的状态和统计信息。然后在模型上调用Sequential或Model类型的fit()函数时,可以将包含ModelCheckpoint等关键字参数的列表的回调函数传递给训练过程。然后在训练时,相应的回调函数的方法就会被在各自的阶段被调用。训练深度学习模型时,Checkpoint是模型的权重,ModelCheckpoint回调类允许自定义:模型权重的位置,文件命名方式,以及在什么情况下创建模型的Checkpoint。
# 回调函数的抽象类,定义新的回调函数必须继承自该类 keras.callbacks.Callback()
# 类属性 params:字典,训练参数集(如信息显示方法verbosity,batch大小,epoch数) model:keras.models.Model对象,为正在训练的模型的引用
# 回调函数以字典logs为参数,该字典包含了一系列与当前batch或epoch相关的信息# 目前,模型的.fit()中有下列参数会被记录到logs中:
- 在每个epoch的结尾处(on_epoch_end),logs将包含训练的正确率和误差,acc和loss,如果指定了验证集,还会包含验证集正确率和误差val_acc和val_loss,val_acc还额外需要在.compile中启用metrics=['accuracy']
- 在每个batch的开始处(on_batch_begin):logs包含size,即当前batch的样本数
- 在每个batch的结尾处(on_batch_end):logs包含loss,若启用accuracy则还包含acc
.ModelCheckpoint()
该回调函数将在每个epoch后保存模型到filepath,filepath可以包括命名格式选项,可以由epoch的值和logs的键(由on_epoch_end参数传递)来填充
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
filepath: 是格式化的字符串,保存模型的路径,里面的占位符将会被epoch值和传入on_epoch_end的logs关键字所填入
filepath = weights.{epoch:02d-{val_loss:.2f}}.hdf5 # 生成对应epoch和验证集loss的多个文件
monitor: 被监测的数据。val_acc或这val_loss
verbose: 详细信息模式,0 或者 1 。0为不打印输出信息,1打印
save_best_only: 如果 save_best_only=True, 将只保存在验证集上性能最好的模型
mode: {auto, min, max} 的其中之一。 如果 save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于 val_acc,模式就会是 max,而对于 val_loss,模式就需要是 min,等等。在 auto 模式中,方向会自动从被监测的数据的名字中判断出来
save_weights_only: 如果 True,那么只有模型的权重会被保存 (model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))
period: 每个检查点之间的间隔(训练轮数)
实现过程
① 从keras.callbacks导入ModelCheckpoint类
from keras.callbacks import ModelCheckpoint
② 在训练阶段的model.compile之后加入下列代码实现每一次epoch(period=1)保存最好的参数
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', save_weights_only=True, verbose=1, save_best_only=True, period=1)
③ 在训练阶段的model.fit之前加载先前保存的参数
if os.path.exists(filepath):
model.load_weights(filepath)
# 若成功加载前面保存的参数,输出下列信息
print("checkpoint_loaded")
④ 在model.fit添加callbacks=[checkpoint]实现回调
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=3,
initial_epoch=0,
callbacks=[checkpoint])
训练过程:
第一次运行train.py执行训练,没有已训练模型可以加载,不会打印“checkpoint_loaded”
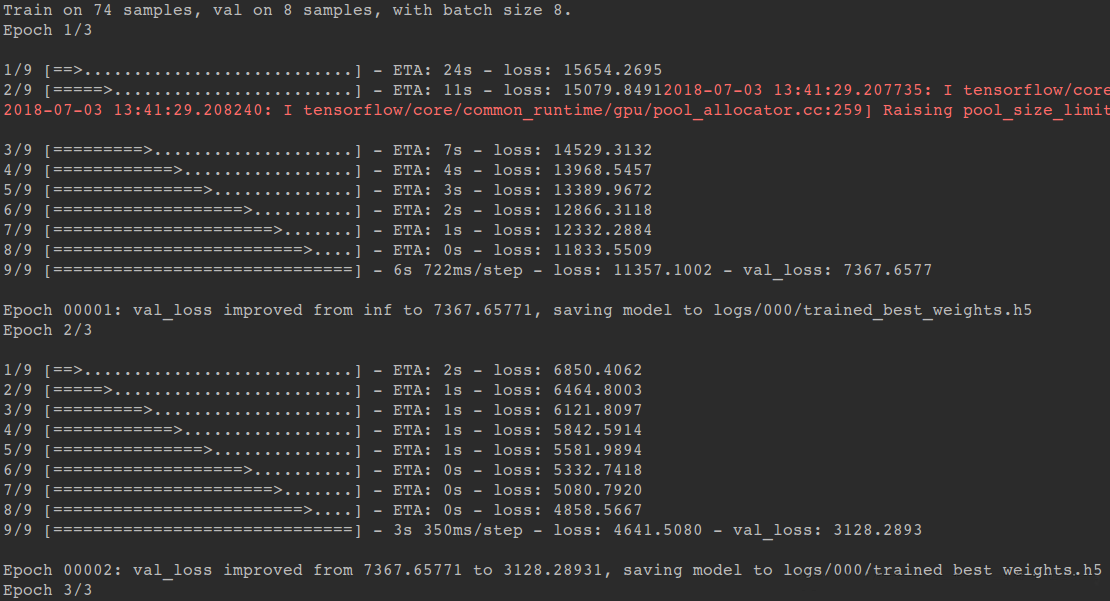
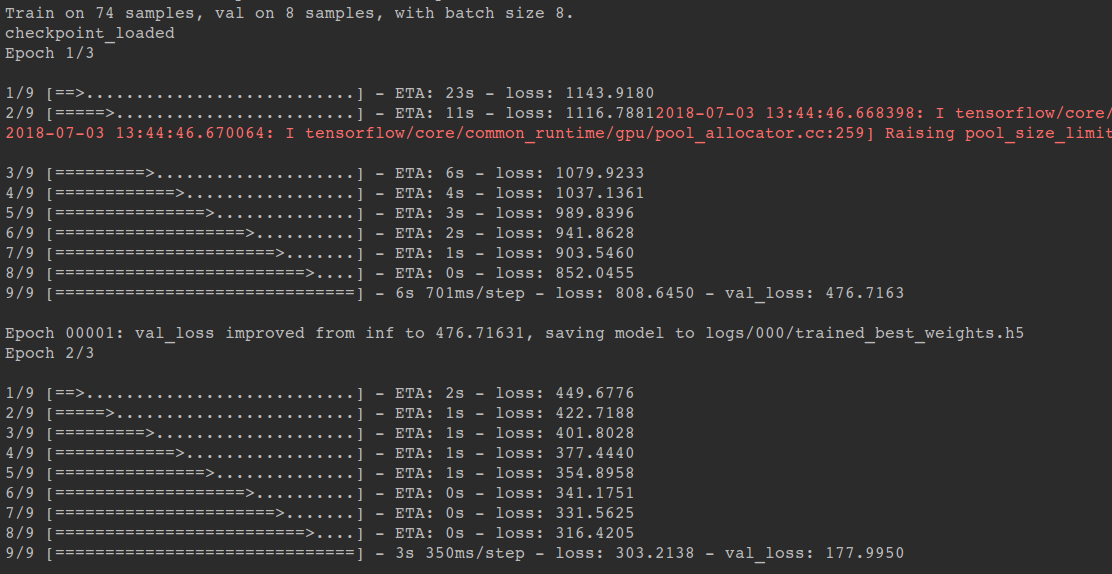
再次运行train.py执行训练,在model.fit之前会加载前一次训练保存的模型参数,继续训练。此轮训练输出“checkpoint_load”表示成功加载前面保存的模型参数
from __future__ import print_function
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import ModelCheckpoint
import os
batch_size = 128
num_classes = 10
epochs = 30
num_predictions = 20
save_dir = os.path.join(os.getcwd(), 'saved_models')
model_name = 'keras_cifar10_trained_model.h5'
# The data, split between train and test sets:
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# Convert class vectors to binary class matrices.
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# Create model
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
# Initiate RMSprop optimizer
opt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6)
# Let's train the model
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
filepath="model_{epoch:02d}-{val_acc:.2f}.hdf5" # filepath = "best_weights.h5"
checkpoint = ModelCheckpoint(os.path.join(save_dir, filepath), monitor='val_acc', verbose=1, save_best_only=True)
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test), shuffle=True, callbacks=[checkpoint])
print(history.history.keys())
# Save model and weights
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
model_path = os.path.join(save_dir, model_name)
model.save(model_path)
print('Saved trained model at %s ' % model_path)
# Score trained model.
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# 训练过程 - 发现有部分epoch未保存checkpoint,如Epoch 00006 x_train shape: (50000, 32, 32, 3) 50000 train samples 10000 test samples Train on 50000 samples, validate on 10000 samples Epoch 1/30 50000/50000 [==============================] - 5s 106us/step - loss: 1.9831 - acc: 0.2734 - val_loss: 1.7195 - val_acc: 0.3934 Epoch 00001: val_acc improved from -inf to 0.39340, saving model to /home/weiliu/PG/keras/saved_models/model_01-0.39.hdf5 Epoch 2/30 50000/50000 [==============================] - 4s 84us/step - loss: 1.6651 - acc: 0.3963 - val_loss: 1.5001 - val_acc: 0.4617 Epoch 00002: val_acc improved from 0.39340 to 0.46170, saving model to /home/weiliu/PG/keras/saved_models/model_02-0.46.hdf5 Epoch 3/30 50000/50000 [==============================] - 4s 88us/step - loss: 1.5249 - acc: 0.4482 - val_loss: 1.4158 - val_acc: 0.4923 Epoch 00003: val_acc improved from 0.46170 to 0.49230, saving model to /home/weiliu/PG/keras/saved_models/model_03-0.49.hdf5 Epoch 4/30 50000/50000 [==============================] - 4s 87us/step - loss: 1.4479 - acc: 0.4775 - val_loss: 1.3469 - val_acc: 0.5199 Epoch 00004: val_acc improved from 0.49230 to 0.51990, saving model to /home/weiliu/PG/keras/saved_models/model_04-0.52.hdf5 Epoch 5/30 50000/50000 [==============================] - 4s 89us/step - loss: 1.3838 - acc: 0.5048 - val_loss: 1.3058 - val_acc: 0.5332 Epoch 00005: val_acc improved from 0.51990 to 0.53320, saving model to /home/weiliu/PG/keras/saved_models/model_05-0.53.hdf5 Epoch 6/30 50000/50000 [==============================] - 4s 87us/step - loss: 1.3359 - acc: 0.5226 - val_loss: 1.3543 - val_acc: 0.5226 Epoch 00006: val_acc did not improve from 0.53320 Epoch 7/30 50000/50000 [==============================] - 4s 88us/step - loss: 1.2934 - acc: 0.5399 - val_loss: 1.1970 - val_acc: 0.5769 Epoch 00007: val_acc improved from 0.53320 to 0.57690, saving model to /home/weiliu/PG/keras/saved_models/model_07-0.58.hdf5 Epoch 8/30 50000/50000 [==============================] - 4s 87us/step - loss: 1.2522 - acc: 0.5536 - val_loss: 1.1682 - val_acc: 0.5865
早停止:keras.callbacks.EarlyStopping()函数
callbacks = [
EarlyStopping(monitor='val_loss', patience=2, verbose=0), # 当两次迭代损失未改善,Keras停止训练
ModelCheckpoint(kfold_weights_path, monitor='val_loss', save_best_only=True, verbose=0),
]
model.fit(X_train.astype('float32'), Y_train, batch_size=batch_size, nb_epoch=nb_epoch, shuffle=True, verbose=1, validation_data=(X_valid, Y_valid), callbacks=callbacks)
自定义早停止回调函数 - 在损失小于常数“THR”之后停止训练:
if val_loss < THR:
breakclass EarlyStoppingByLossVal(Callback):
def __init__(self, monitor='val_loss', value=0.00001, verbose=0):
super(Callback, self).__init__()
self.monitor = monitor
self.value = value
self.verbose = verbose
def on_epoch_end(self, epoch, logs={}):
current = logs.get(self.monitor)
if current is None:
warnings.warn("Early stopping requires %s available!" % self.monitor, RuntimeWarning)
if current < self.value:
if self.verbose > 0:
print("Epoch %05d: early stopping THR" % epoch)
self.model.stop_training = True
callbacks = [
EarlyStoppingByLossVal(monitor='val_loss', value=0.00001, verbose=1),
ModelCheckpoint(kfold_weights_path, monitor='val_loss', save_best_only=True, verbose=0),
]
model.fit(X_train.astype('float32'), Y_train, batch_size=batch_size, nb_epoch=nb_epoch, shuffle=True, verbose=1, validation_data=(X_valid, Y_valid), callbacks=callbacks)
Keras模型训练的断点续训、早停、效果可视化的更多相关文章
- Keras入门(六)模型训练实时可视化
在北京做某个项目的时候,客户要求能够对数据进行训练.预测,同时能导出模型,还有在页面上显示训练的进度.前面的几个要求都不难实现,但在页面上显示训练进度当时笔者并没有实现. 本文将会分享如何在K ...
- A TensorBoard plugin for visualizing arbitrary tensors in a video as your network trains.Beholder是一个TensorBoard插件,用于在模型训练时查看视频帧。
Beholder is a TensorBoard plugin for viewing frames of a video while your model trains. It comes wit ...
- 在Keras模型中one-hot编码,Embedding层,使用预训练的词向量/处理图片
最近看了吴恩达老师的深度学习课程,又看了python深度学习这本书,对深度学习有了大概的了解,但是在实战的时候, 还是会有一些细枝末节没有完全弄懂,这篇文章就用来总结一下用keras实现深度学习算法的 ...
- 人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型
人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型 经过前面稍显罗嗦的准备工作,现在,我们终于可以尝试训练我们自己的卷积神经网络模型了.CNN擅长图像处理,keras库的te ...
- keras 保存训练的最佳模型
转自:https://anifacc.github.io/deeplearning/machinelearning/python/2017/08/30/dlwp-ch14-keep-best-mode ...
- 早停!? earlystopping for keras
为了获得性能良好的神经网络,网络定型过程中需要进行许多关于所用设置(超参数)的决策.超参数之一是定型周期(epoch)的数量:亦即应当完整遍历数据集多少次(一次为一个epoch)?如果epoch数量太 ...
- 谷歌大规模机器学习:模型训练、特征工程和算法选择 (32PPT下载)
本文转自:http://mp.weixin.qq.com/s/Xe3g2OSkE3BpIC2wdt5J-A 谷歌大规模机器学习:模型训练.特征工程和算法选择 (32PPT下载) 2017-01-26 ...
- Keras/Tensorflow训练逻辑研究
Keras是什么,以及相关的基础知识,这里就不做详细介绍,请参考Keras学习站点http://keras-cn.readthedocs.io/en/latest/ Tensorflow作为backe ...
- 将keras模型在django中应用时出现的小问题——ValueError: Tensor Tensor("dense_2/Softmax:0", shape=(?, 8), dtype=float32) is not an element of this graph.
本文原出处(感谢作者提供):https://zhuanlan.zhihu.com/p/27101000 将keras模型在django中应用时出现的小问题 王岳王院长 10 个月前 keras 一个做 ...
随机推荐
- Vue 新手学习笔记:vue-element-admin 之安装,配置及入门开发
所属专栏: Vue 开发学习进步 说实话都是逼出来的,对于前端没干过ES6都不会的人,vue视频也就看了基础的一些但没办法,接下来做微服务架构,前端就用 vue,这块你负责....说多了都是泪,脚手架 ...
- [BZOJ2730]:[HNOI2012]矿场搭建(塔尖)
题目传送门 题目描述 煤矿工地可以看成是由隧道连接挖煤点组成的无向图.为安全起见,希望在工地发生事故时所有挖煤点的工人都能有一条出路逃到救援出口处.于是矿主决定在某些挖煤点设立救援出口,使得无论哪一个 ...
- go面试题
1)解释什么是GO? GO是一种开源编程语言,可以轻松构建简单.可靠和高效的软件.程序是从包中构建的,其属性允许有效地管理依赖关系. 2)GO中的语法是什么? GO中的语法遵循Extended Bac ...
- 2018-2019-2 20165205 网络对抗技术 Exp9 Web安全基础
2018-2019-2 20165205 网络对抗技术 Exp9 Web安全基础 1.基础问题 SQL注入攻击原理,如何防御 原理: SQL注入指攻击者在提交查询请求时将SQL语句插入到请求内容中,同 ...
- java编程出现的错误对应的解决方法
error: could not open D:\java\jre1.8\lib\amd64\jvm.cfg 解决方法:把java的环境变量%JAVA_HOME%/bin上移到最上面 优化 查看网页源 ...
- vmalloc详解
vmalloc是一个接口函数, 内核代码使用它来分配在虚拟内存中连续但在物理内存中不一定连续的内存. 只需要一个参数,以字节为单位. 使用vmalloc的最著名的实例是内核对模块的实现. 因为模块可能 ...
- Dao操作的抽取
package com.loaderman.demo.c_jdbc; public class Admin { private int id; private String userName; pri ...
- javascript之注册事件
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- vue-template-compiler作用
vue-template-compiler的作用是什么: 看起来 template-compiler是给parse函数使用的, 那么parse函数是干什么的呢 先看一下parse的结果: 结论:使用v ...
- 阶段3 3.SpringMVC·_04.SpringMVC返回值类型及响应数据类型_3 响应之返回值是void类型
定义先的标签 返回void 测试默认的跳转 虽然是404但是方法执行了. 默认请求了 testVoid.jsp这个页面.请求路径叫什么 就访问哪个jsp页面. 使用request请求转发 抛出的异常 ...