Greenplum 调优--数据倾斜排查(二)
上次有个朋友咨询我一个GP数据倾斜的问题,他说查看gp_toolkit.gp_skew_coefficients表时花费了20-30分钟左右才出来结果,后来指导他分析原因并给出其他方案来查看数据倾斜。
其实很多朋友经常使用如下的方式来检查数据分布:
select gp_segment_id,count(1) from person_info group by 1;
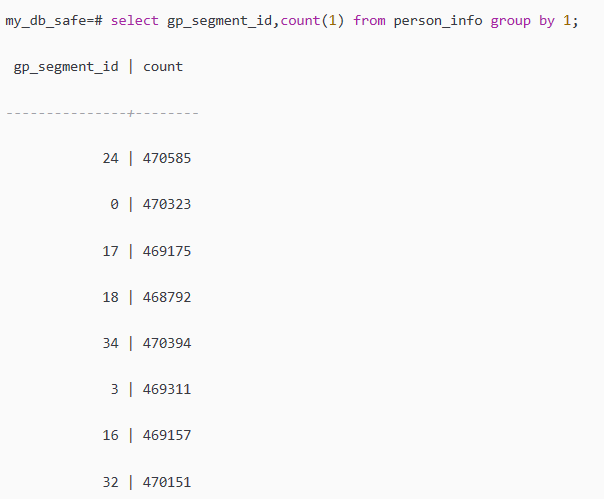
但是这种方法太简单,只有判断存储是否倾斜,不能够去对数据处理是否会出现倾斜做出判断。而且判断的维度很少,不直观。
后来Greenplum提供了gp_toolkit.gp_skew_coefficients等工具来进行检查判断。
首先我们来看一下gp_toolkit.gp_skew_coefficients这个视图的逻辑:
my_db_safe=# \d+ gp_toolkit.gp_skew_coefficients
View "gp_toolkit.gp_skew_coefficients"
View definition: SELECT skew.skewoid AS skcoid, pgn.nspname AS skcnamespace, pgc.relname AS skcrelname, skew.skewval AS skccoeff
FROM gp_toolkit.__gp_skew_coefficients() skew(skewoid, skewval)
JOIN pg_class pgc ON skew.skewoid = pgc.oid
JOIN pg_namespace pgn
ON pgc.relnamespace = pgn.oid;
当我们使用视图gp_toolkit.gp_skew_coefficients来检查表数据倾斜时,该视图会基于表的行数据量来检查,如果表数据量越大,检查时间就会越长。
select * from gp_toolkit.gp_skew_coefficients;
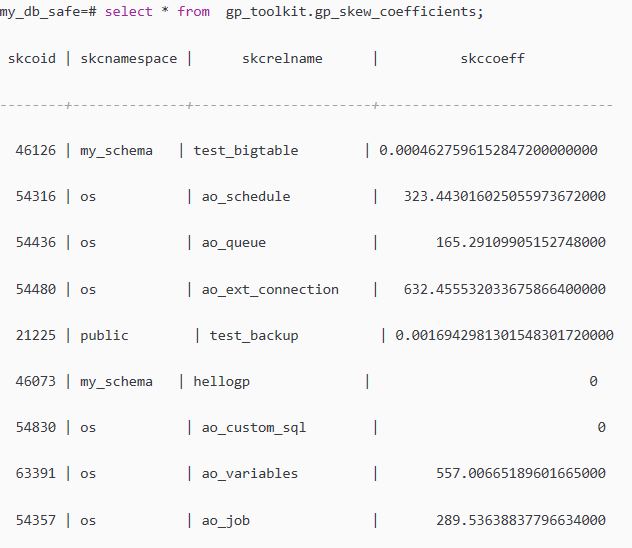
其中skccoeff 通过存储记录均值计算出的标准差,这个值越低说明数据存放约均匀,反之说明数据存储分布不均匀,要考虑分布键选择是否合理。
另外一个视图gp_toolkit.gp_skew_idle_fractions 通过计算表扫描过程中,系统闲置的百分比,帮助用户快速判断,是否存在分布键选择不合理,导致数据处理倾斜的问题。
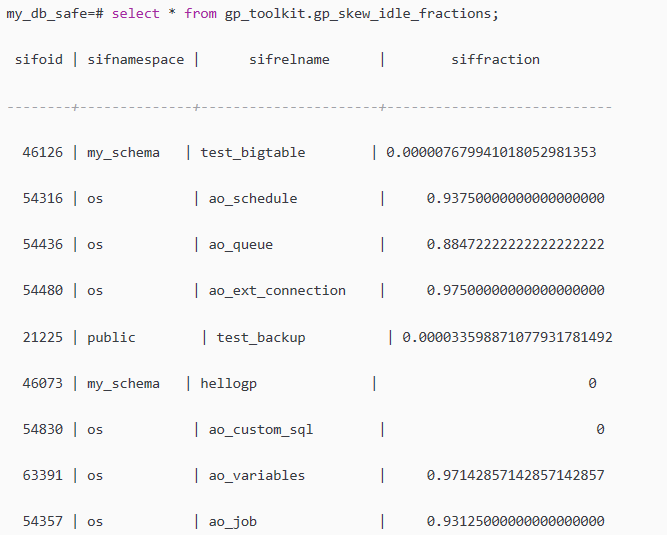
siffraction字段表示表扫描过程中系统闲置的百分比,比如0.1表示10%的倾斜。
结合上面两个视图的结果,我们可以看到某些表的结论是数据倾斜很厉害,
比如ao_schedule表,但是实际上这些表是因为数据量太少,只有几条,那只能分布在某几个segment节点上,其他segment节点都没有数据,
比如:
select gp_segment_id,count(1) from os.ao_schedule group by 1;
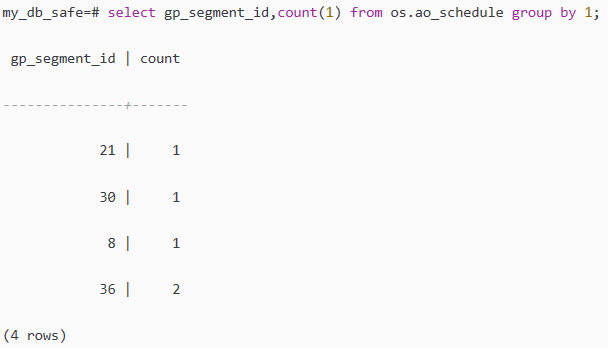
可以看出,os.ao_schedule表只有5条数据,所有判断数据倾斜时要结合多方面来判断。
本文章会介绍一种替代上面两个视图低效查询数据倾斜的方式。
解决方案的原理:这次方案也是使用视图来观察每个segment上的每个表的文件大小。
它将仅仅输出那些表至少一个segment大小比预期的大20%以上。 下面一个工具,一个能够快速给出表倾斜的信息。
执行如下的创建函数的SQL:
CREATE OR REPLACE FUNCTION my_func_for_files_skew() RETURNS void AS $$ DECLARE v_function_name text := 'my_create_func_for_files_skew'; v_location_id int; v_sql text; v_db_oid text; v_number_segments numeric; v_skew_amount numeric; BEGIN --定义代码的位置,方便用来定位问题-- v_location_id := 1000; --获取当前数据库的oid-- SELECT oid INTO v_db_oid FROM pg_database WHERE datname = current_database(); --文件倾斜的视图并创建该视图-- v_location_id := 2000; v_sql := 'DROP VIEW IF EXISTS my_file_skew_view'; v_location_id := 2100; EXECUTE v_sql; --保存db文件的外部表并创建该外部表-- v_location_id := 2200; v_sql := 'DROP EXTERNAL TABLE IF EXISTS my_db_files_web_tbl'; v_location_id := 2300; EXECUTE v_sql; --获取 segment_id,relfilenode,filename,size 信息-- v_location_id := 3000; v_sql := 'CREATE EXTERNAL WEB TABLE my_db_files_web_tbl ' || '(segment_id int, relfilenode text, filename text, size numeric) ' || 'execute E''ls -l $GP_SEG_DATADIR/base/' || v_db_oid || ' | grep gpadmin | ' || E'awk {''''print ENVIRON["GP_SEGMENT_ID"] "\\t" $9 "\\t" ' || 'ENVIRON["GP_SEG_DATADIR"] "/' || v_db_oid || E'/" $9 "\\t" $5''''}'' on all ' || 'format ''text'''; v_location_id := 3100; EXECUTE v_sql; --获取所有primary segment的个数-- v_location_id := 4000; SELECT count(*) INTO v_number_segments FROM gp_segment_configuration WHERE preferred_role = 'p' AND content >= 0; --如果primary segment总数为40个,那么此处v_skew_amount=1.2*0.025=0.03-- v_location_id := 4100; v_skew_amount := 1.2*(1/v_number_segments); --创建记录文件倾斜的视图-- v_location_id := 4200; v_sql := 'CREATE OR REPLACE VIEW my_file_skew_view AS ' || 'SELECT schema_name, ' || 'table_name, ' || 'max(size)/sum(size) as largest_segment_percentage, ' || 'sum(size) as total_size ' || 'FROM ( ' || 'SELECT n.nspname AS schema_name, ' || ' c.relname AS table_name, ' || ' sum(db.size) as size ' || ' FROM my_db_files_web_tbl db ' || ' JOIN pg_class c ON ' || ' split_part(db.relfilenode, ''.'', 1) = c.relfilenode ' || ' JOIN pg_namespace n ON c.relnamespace = n.oid ' || ' WHERE c.relkind = ''r'' ' || ' GROUP BY n.nspname, c.relname, db.segment_id ' || ') as sub ' || 'GROUP BY schema_name, table_name ' || 'HAVING sum(size) > 0 and max(size)/sum(size) > ' || --只记录大于合适的才输出--- v_skew_amount::text || ' ' || 'ORDER BY largest_segment_percentage DESC, schema_name, ' || 'table_name'; v_location_id := 4300; EXECUTE v_sql; EXCEPTION WHEN OTHERS THEN RAISE EXCEPTION '(%:%:%)', v_function_name, v_location_id, sqlerrm;END;$$ language plpgsql;
然后我们执行函数,创建相关的对象:
select my_func_for_files_skew();
这时我们就可以查看我们计划的倾斜表:
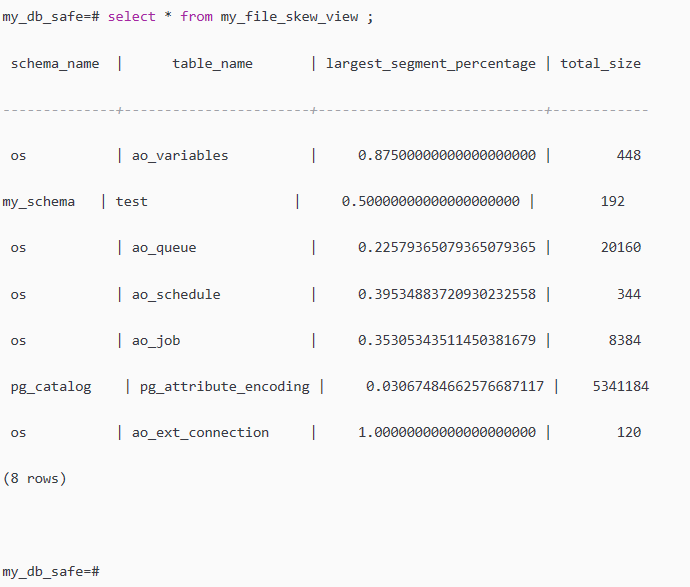
select * from my_file_skew_view ;
我们也可以选择按照倾斜度的大小进行排序:
select * from my_file_skew_view order by largest_segment_percentage desc;
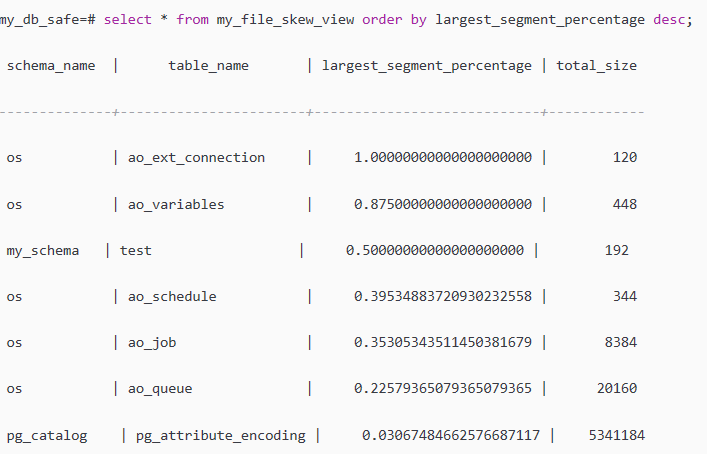
根据查看结果,需要我们关注的是largest_segment_percentage这个字段的值,越靠近1说明一个segment上面的数据比集群的其他节点更多,
比如os.ao_variables表的largest_segment_percentage为0.875,说明87.5%的数据在一个segment上面。
我们可以验证一下:

很显然,共有7条数据(总共8条数据)都在gp_segment_id为35的segment上面,占87.5%。
如果大家对Greenplum数据库熟悉的话,就会发现上面工具的一个问题,即表膨胀。
当我们对表执行DML操作时,对于删除的空间并没有立马释放给操作系统,所以我们的计算结果可能会包含这部分大小。
个人建议在执行这个查看表文件倾斜之前,对需要统计的表进行Vacuum回收空间,或使用CTAS方式进行表重建。
另外补充一点,如果你想对单个表进行统计倾斜度时,可以修改函数,添加一个参数,用来传入表名或表的oid即可。
整理自:
https://blog.csdn.net/jiangshouzhuang/article/details/51792580
Greenplum 调优--数据倾斜排查(二)的更多相关文章
- Greenplum 调优--数据倾斜排查(一)
对于分布式数据库来说,QUERY的运行效率取决于最慢的那个节点. 当数据出现倾斜时,某些节点的运算量可能比其他节点大.除了带来运行慢的问题,还有其他的问题,例如导致OOM,或者DISK FULL等问题 ...
- Spark调优 数据倾斜
1. Spark数据倾斜问题 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce ...
- spark调优——数据倾斜
Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce点一共要处理100万条数据,第 ...
- spark性能调优 数据倾斜 内存不足 oom解决办法
[重要] Spark性能调优——扩展篇 : http://blog.csdn.net/zdy0_2004/article/details/51705043
- 1-Spark-1-性能调优-数据倾斜1-特征/常见原因/后果/常见调优方案
数据倾斜特征:个别Task处理大部分数据 后果:1.OOM;2.速度变慢,甚至变得慢的不可接受 常见原因: 数据倾斜的定位: 1.WebUI(查看Task运行的数据量的大小). 2.Log,查看log ...
- 2-Spark-1-性能调优-数据倾斜2-Join/Broadcast的使用场景
技术点:RDD的join操作可能产生数据倾斜,当两个RDD不是非常大的情况下,可以通过Broadcast的方式在reduce端进行类似(Join)的操作: broadcast是进程级别的,只读的. b ...
- Greenplum 调优--VACUUM系统表
Greenplum 调优--VACUUM系统表 1.VACUUM系统表原因 Greenplum是基于MVCC版本控制的,所有的delete并没有删除数据,而是将这一行数据标记为删除, 而且update ...
- [redis]复制机制,调优,故障排查
在redis的安装目录下首先启动一个redis服务,使用默认的配置文件,作为主服务 ubuntu@slave1:~/redis2$ ./redis-server ./redis.conf & ...
- 专访周金可:我们更倾向于Greenplum来解决数据倾斜的问题
周金可,就职于听云,维护MySQL和GreenPlum的正常运行,以及调研适合听云业务场景的数据库技术方案. 听云周金可 9月24日,周金可将参加在北京举办的线下活动,并做主题为<GreenPl ...
随机推荐
- 2019年6月12日——开始记录并分享学习心得——Python3.7中对列表进行排序
Python中对列表的排序按照是排序是否可以恢复分为:永久性排序和临时排序. Python中对列表的排序可以按照使用函数的不同可以分为:sort( ), sorted( ), reverse( ). ...
- 《C++语言程序设计》初学者必备教材
很多刚开始学习C++语言的同学,都会遇到一个问题:很多教材都不适合零基础的初学者.它们有的枯燥乏味,让人难以消化吸收,有的层次结构混乱,很难理清楚知识点,有的更是难度太大,没有代码的过渡,就开始讲解算 ...
- 模板模式(Template Pattern)
模板模式(Template Pattern) -- 定义一个操作中的算法的骨架,而将一些步骤延迟到子类中.Template Method使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤. ...
- dev 从表处理
从表列名,从表选中行和主表选中一样,var selectrow = detailView.GetRow(detailView.FocusedRowHandle) as obj; private voi ...
- Python——初识网络爬虫(网页爬取)
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫 ...
- HTML认识一
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- Dubbo服务发布、引用
DUBBO原理.应用与面经总结 Dubbo原理和源码解析之服务暴露 Dubbo原理和源码解析之服务引用 服务发布 服务的发布总共做了以下几件事,这个也可以从日志log上看出来: 暴露本地服务 暴露远程 ...
- MYSQL安装与卸载(一)
系统:win10(其他版本系统不在本次内容) MYSQL下载地址:https://dev.mysql.com/downloads/mysql/ MySQL安装主流分为两种:msi,zip Zip:压缩 ...
- RestFramework之序列化组件
一.restframework的序列化组件的使用 1.导入序列化组件与模型类 from rest_framework import serializers from app01.models impo ...
- Python requests.post嵌套多层json参数调用接口
#coding:utf-8 import requests,json #第一行注解的#coding:utf-8表示可以支持中文,不然代码里面有中文会报错 url = "http://xxx& ...