数据分析04-pandas(apply函数、排序、数据合、分组聚合、透视表、交叉表及项目分析)
数据分析-04
apply函数
pandas提供了apply函数方便的处理Series与DataFrame;apply函数支持逐一处理数据集中的每个元素都会执行一次目标函数,把返回值存入结果集中。:
# series.apply()
ary = np.array(['80公斤','83公斤','78公斤','74公斤','84公斤'])
s = pd.Series(ary)
def func(x):
return x[:2]
s.apply(func)
# dataframe.apply()
def func(x):
x[pd.isna(x)] = x.mean()
return x
ratings.apply(func, axis=1)
排序
Pandas有两种排序方式,它们分别是按标签与按实际值排序。
import numpy as np
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack','Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
unsorted_df = pd.DataFrame(d)
按标签(行)排序
使用sort_index()方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。 默认情况下,按照升序对行标签进行排序。
# 按照行标进行排序
sorted_df=unsorted_df.sort_index()
print (sorted_df)
# 控制排序顺序
sorted_df = unsorted_df.sort_index(ascending=False)
print (sorted_df)
按标签(列)排序
# 按照列标签进行排序
sorted_df=unsorted_df.sort_index(axis=1)
print (sorted_df)
按某列值排序
像索引排序一样,sort_values()是按值排序的方法。它接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
sorted_df = unsorted_df.sort_values(by='Age')
print (sorted_df)
# 先按Age进行升序排序,然后按Rating降序排序
sorted_df = unsorted_df.sort_values(by=['Age', 'Rating'], ascending=[True, False])
print (sorted_df)
数据合并
concat
concat函数是在pandas的方法,可以根据不同的轴合并数据集。
r = pd.concat(datas, axis=0, join='outer', ignore_index=False,
keys=['x', 'y', 'z'])
纵向合并:
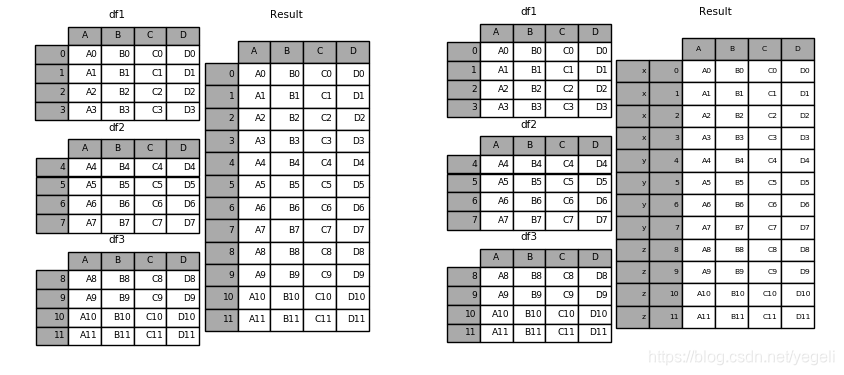
横向合并:
merge & join
panda具有全功能、高性能的内存连接操作,与SQL之类的关系数据库非常相似。与其他开源实现相比,这些方法的性能要好得多(在某些情况下要好一个数量级以上)
pandas提供了merge函数实现高效的内存链接操作:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False)
| 参数名称 | 说明 |
|---|---|
| left | 接收DataFrame或Series。表示要添加的新数据。无默认。 |
| right | 接收DataFrame或Series。表示要添加的新数据。无默认。。 |
| how | 接收inner,outer,left,right。表示数据的连接方式。默认为inner。 |
| on | 接收string或sequence。表示外键字段名。默认为None。 |
| left_on | 接收string或sequence。关联操作时左表中的关联字段名。 |
| right_on | 接收string或sequence。关联操作时右表中的关联字段名。 |
| left_index | 接收boolean。表示是否将left参数接收数据的index作为连接主键。默认为False。 |
| right_index | 接收boolean。表示是否将right参数接收数据的index作为连接主键。默认为False。 |
| sort | 接收boolean。表示是否根据连接键对合并后的数据进行排序。默认为False。 |
| suffixes | 接收接收tuple。表示用于追加到left和right参数接收数据重叠列名的尾缀默认为(’_x’, ‘_y’)。 |
合并两个DataFrame:
import pandas as pd
left = pd.DataFrame({
'student_id':[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],
'student_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung', 'Billy', 'Brian', 'Bran', 'Bryce', 'Betty', 'Emma', 'Marry', 'Allen', 'Jean', 'Rose', 'David', 'Tom', 'Jack', 'Daniel', 'Andrew'],
'class_id':[1,1,1,2,2,2,3,3,3,4,1,1,1,2,2,2,3,3,3,2],
'gender':['M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F'],
'age':[20,21,22,20,21,22,23,20,21,22,20,21,22,23,20,21,22,20,21,22],
'score':[98,74,67,38,65,29,32,34,85,64,52,38,26,89,68,46,32,78,79,87]})
right = pd.DataFrame(
{'class_id':[1,2,3,5],
'class_name': ['ClassA', 'ClassB', 'ClassC', 'ClassE']})
# 合并两个DataFrame
data = pd.merge(left,right)
print(data)
其他合并方法同数据库相同:
| 合并方法 | SQL等效 | 描述 |
|---|---|---|
left |
LEFT OUTER JOIN |
使用左侧对象的键 |
right |
RIGHT OUTER JOIN |
使用右侧对象的键 |
outer |
FULL OUTER JOIN |
使用键的联合 |
inner |
INNER JOIN |
使用键的交集 |
实验:
# 合并两个DataFrame (左连接)
rs = pd.merge(left,right,on='subject_id', how='right')
print(rs)
# 合并两个DataFrame (左连接)
rs = pd.merge(left,right,on='subject_id', how='outer')
print(rs)
# 合并两个DataFrame (左连接)
rs = pd.merge(left,right,on='subject_id', how='inner')
print(rs)
分组聚合
pandas提供了功能类似于数据库中group by语句的用于拆分数据组的方法pd.groupby();该方法提供的是分组聚合步骤中的拆分功能,能根据索引或字段对数据进行分组(Split) 进而针对得到的多组数据执行聚合操作(Apply),最终合并为最终结果(Combine)。
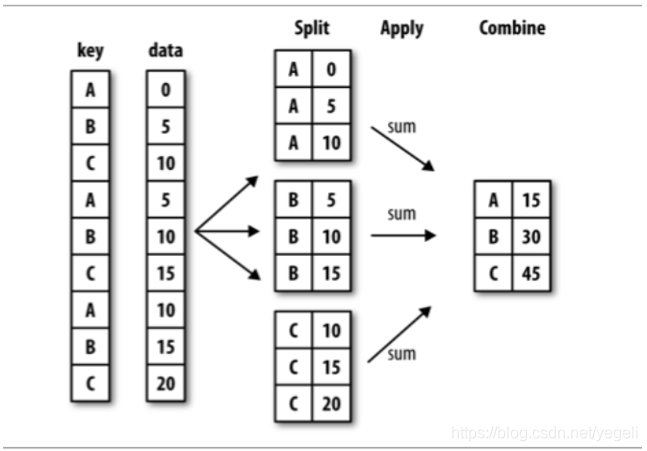
分组
groupby方法的参数及其说明:
DataFrame.groupby(by=None, axis=0, as_index=True, sort=True)
| 参数名称 | 说明 |
|---|---|
| by | 接收list,string,mapping或generator。用于确定进行分组的依据。无默认。 |
| axis | 接收int。表示操作的轴向,默认对行进行操作。默认为0。 |
| as_index | 接收boolearn。表示聚合后的聚合标签是否以DataFrame索引形式输出。默认为True。 |
| sort | 接收boolearn。表示是否对分组依据分组标签进行排序。默认为True。 |
用groupby方法分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。实际上分组后的数据对象(Groupby对象)类似Series与DataFrame,是pandas提供的一种对象。
Groupby对象的常用方法:
| 方法 | 说明 |
|---|---|
| groupObject.get_group(‘A’) | 返回A组的详细数据 |
| groupObject.size() | 返回每一组的频数 |
grouped = data.groupby(by=['class_id', 'gender'])
grouped.get_group((1, 'M'))
grouped = data.groupby(by=['class_id', 'gender'])
grouped.get_group((1, 'M'))
聚合
聚合函数为每个组返回聚合值。当创建了分组(groupby)对象,就可以对每个分组的其他字段数据执行求和、求标准差等操作。
使用聚合函数agg进行组内计算:
grouped = data.groupby(by='class_id')
grouped.agg({'score':np.mean})
对于某个字段希望只做求均值操作,而对另一个字段则希望只做求和操作,可以使用字典的方式,将两个字段名分别作为key:
grouped.agg({'age':np.max, 'score':np.mean})
还可以这样:
result = grouped.agg(
{'age':np.max, 'score':[np.mean, np.max]})
pandas支持的聚合函数有:
| 方法名称 | 说明 |
|---|---|
| count | 计算分组的数目,包括缺失值。 |
| head | 返回每组的前n个值。 |
| max | 返回每组最大值。 |
| mean | 返回每组的均值。 |
| median | 返回每组的中位数。 |
| cumcount | 对每个分组中组员的进行标记,0至n-1。 |
| size | 返回每组的大小。 |
| min | 返回每组最小值。 |
| std | 返回每组的标准差。 |
| sum | 返回每组的和。 |
透视表与交叉表
透视表
透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行分组聚合,并根据每个分组进行数据汇总。
# 以class_id与gender做分组汇总数据,默认聚合统计所有列
print(data.pivot_table(index=['class_id', 'gender']))
# 以class_id与gender做分组汇总数据,聚合统计score列
print(data.pivot_table(index=['class_id', 'gender'], values=['score']))
# 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计
print(data.pivot_table(index=['class_id', 'gender'], values=['score'], columns=['age']))
# 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计,添加行、列小计
print(data.pivot_table(index=['class_id', 'gender'], values=['score'], columns=['age'], margins=True))
# 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计,添加行、列小计
print(data.pivot_table(index=['class_id', 'gender'], values=['score'], columns=['age'], margins=True, aggfunc='max'))
交叉表
交叉表(cross-tabulation, 简称crosstab)是一种用于计算分组频率的特殊透视表:
# 按照class_id分组,针对不同的gender,统计数量
print(pd.crosstab(data.class_id, data.gender, margins=True))
项目:分析影响学生成绩的因素
资源文件下载
https://download.csdn.net/download/yegeli/12562286
在我的资源中下载:StudentsPerformance.csv
| 字段 | 说明 |
|---|---|
| gender | 性别 |
| race/ethnicity | 种族 |
| parental level of education | 父母教育水平 |
| lunch | 午餐 |
| test preparation course | 是否通过预科考试 |
| math score | 数学得分 |
| reading score | 阅读得分 |
| writing score | 写作得分 |
学生成绩影响因素分析
import numpy as np
import pandas as pd
data = pd.read_csv('StudentsPerformance.csv')
data['total score'] = data.sum(axis=1)
# 参数number,object意为:统计数字列与字符串列
data.describe(include=['number', 'object'])
| gender | race/ethnicity | parental level of education | lunch | test preparation course | math score | reading score | writing score | total score | |
|---|---|---|---|---|---|---|---|---|---|
| count | 1000 | 1000 | 1000 | 1000 | 1000 | 1000.00000 | 1000.000000 | 1000.000000 | 1000.000000 |
| unique | 2 | 5 | 6 | 2 | 2 | NaN | NaN | NaN | NaN |
| top | female | group C | some college | standard | none | NaN | NaN | NaN | NaN |
| freq | 518 | 319 | 226 | 645 | 642 | NaN | NaN | NaN | NaN |
| mean | NaN | NaN | NaN | NaN | NaN | 66.08900 | 69.169000 | 68.054000 | 203.312000 |
| std | NaN | NaN | NaN | NaN | NaN | 15.16308 | 14.600192 | 15.195657 | 42.771978 |
| min | NaN | NaN | NaN | NaN | NaN | 0.00000 | 17.000000 | 10.000000 | 27.000000 |
| 25% | NaN | NaN | NaN | NaN | NaN | 57.00000 | 59.000000 | 57.750000 | 175.000000 |
| 50% | NaN | NaN | NaN | NaN | NaN | 66.00000 | 70.000000 | 69.000000 | 205.000000 |
| 75% | NaN | NaN | NaN | NaN | NaN | 77.00000 | 79.000000 | 79.000000 | 233.000000 |
| max | NaN | NaN | NaN | NaN | NaN | 100.00000 | 100.000000 | 100.000000 | 300.000000 |
# 分析性别对学习成绩的影响(按性别分组)
data.pivot_table(index='gender')
| math score | reading score | total score | writing score | |
|---|---|---|---|---|
| gender | ||||
| female | 63.633205 | 72.608108 | 208.708494 | 72.467181 |
| male | 68.728216 | 65.473029 | 197.512448 | 63.311203 |
总体来说,女生的成绩普遍比较好,但是男生更善于数学。
# 分析种族对学习成绩的影响
data.pivot_table(index='race/ethnicity')
| math score | reading score | total score | writing score | |
|---|---|---|---|---|
| race/ethnicity | ||||
| group A | 61.629213 | 64.674157 | 188.977528 | 62.674157 |
| group B | 63.452632 | 67.352632 | 196.405263 | 65.600000 |
| group C | 64.463950 | 69.103448 | 201.394984 | 67.827586 |
| group D | 67.362595 | 70.030534 | 207.538168 | 70.145038 |
| group E | 73.821429 | 73.028571 | 218.257143 | 71.407143 |
种族划分(优秀-及格): E - D - C - B - A
# 分析父母教育水平对学习成绩的影响
r = data.pivot_table(index='parental level of education')
r.sort_values(by='total score', ascending=False)
| math score | reading score | total score | writing score | |
|---|---|---|---|---|
| parental level of education | ||||
| master's degree | 69.745763 | 75.372881 | 220.796610 | 75.677966 |
| bachelor's degree | 69.389831 | 73.000000 | 215.771186 | 73.381356 |
| associate's degree | 67.882883 | 70.927928 | 208.707207 | 69.896396 |
| some college | 67.128319 | 69.460177 | 205.429204 | 68.840708 |
| some high school | 63.497207 | 66.938547 | 195.324022 | 64.888268 |
| high school | 62.137755 | 64.704082 | 189.290816 | 62.448980 |
父母受教育水平越高,学习成绩越好。
# 分析中午饭学习成绩的影响
r = data.pivot_table(index='lunch')
r.sort_values(by='total score', ascending=False)
| math score | reading score | total score | writing score | |
|---|---|---|---|---|
| lunch | ||||
| standard | 70.034109 | 71.654264 | 212.511628 | 70.823256 |
| free/reduced | 58.921127 | 64.653521 | 186.597183 | 63.022535 |
# 分析中午饭学习成绩的影响
r = data.pivot_table(index='test preparation course')
r.sort_values(by='total score', ascending=False)
| math score | reading score | total score | writing score | |
|---|---|---|---|---|
| test preparation course | ||||
| completed | 69.695531 | 73.893855 | 218.008380 | 74.418994 |
| none | 64.077882 | 66.534268 | 195.116822 | 64.504673 |
r = data.pivot_table(index=['gender','test preparation course'])
r
| math score | reading score | total score | writing score | ||
|---|---|---|---|---|---|
| gender | test preparation course | ||||
| female | completed | 67.195652 | 77.375000 | 223.364130 | 78.793478 |
| none | 61.670659 | 69.982036 | 200.634731 | 68.982036 | |
| male | completed | 72.339080 | 70.212644 | 212.344828 | 69.793103 |
| none | 66.688312 | 62.795455 | 189.133117 | 59.649351 |
分析前100名与后100名同学的不同情况
r = data.sort_values(by='total score', ascending=False)
top100 = r.head(100)
tail100 = r.tail(100)
r1 = pd.DataFrame({'top100':top100['gender'].value_counts(),
'tail100':tail100['gender'].value_counts()})
r1
| tail100 | top100 | |
|---|---|---|
| female | 38 | 66 |
| male | 62 | 34 |
data['parental level of education'].value_counts()
some college 226
associate's degree 222
high school 196
some high school 179
bachelor's degree 118
master's degree 59
Name: parental level of education, dtype: int64
r2 = pd.DataFrame({'top100':top100['parental level of education'].value_counts(),
'tail100':tail100['parental level of education'].value_counts()})
r2
| tail100 | top100 | |
|---|---|---|
| associate's degree | 17 | 29 |
| bachelor's degree | 8 | 20 |
| high school | 32 | 6 |
| master's degree | 1 | 15 |
| some college | 14 | 21 |
| some high school | 28 | 9 |
代码总结
import numpy as np
import pandas as pd
# apply() 应用于Series
ary = np.array(['80公斤','83公斤','78公斤','74公斤','84公斤'])
s = pd.Series(ary)
s
def func(item):
return float(item[:-2])
s = s.apply(func)
s
0 80.0
1 83.0
2 78.0
3 74.0
4 84.0
dtype: float64
# apply() 应用于 DataFrame
ratings = pd.read_json('../../data/ratings.json')
def func(item):
item[item.isna()] = item.mean()
return item
ratings.apply(func, axis=0)
<ipython-input-7-ebdfbe0e051f>:5: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
item[item.isna()] = item.mean()
| John Carson | Michelle Peterson | William Reynolds | Jillian Hobart | Melissa Jones | Alex Roberts | Michael Henry | |
|---|---|---|---|---|---|---|---|
| Inception | 2.5 | 3.0 | 2.50 | 3.5 | 3 | 3.0 | 3.166667 |
| Pulp Fiction | 3.5 | 3.5 | 3.00 | 3.5 | 4 | 4.0 | 4.500000 |
| Anger Management | 3.0 | 1.5 | 3.25 | 3.0 | 2 | 3.7 | 3.166667 |
| Fracture | 3.5 | 5.0 | 3.50 | 4.0 | 3 | 5.0 | 4.000000 |
| Serendipity | 2.5 | 3.5 | 3.25 | 2.5 | 2 | 3.5 | 1.000000 |
| Jerry Maguire | 3.0 | 3.0 | 4.00 | 4.5 | 3 | 3.0 | 3.166667 |
排序
d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack','Lee','David','Gasper','Betina','Andres']),
'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]),
'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])}
unsorted_df = pd.DataFrame(d)
unsorted_df
| Name | Age | Rating | |
|---|---|---|---|
| 0 | Tom | 25 | 4.23 |
| 1 | James | 26 | 3.24 |
| 2 | Ricky | 25 | 3.98 |
| 3 | Vin | 23 | 2.56 |
| 4 | Steve | 30 | 3.20 |
| 5 | Minsu | 29 | 4.60 |
| 6 | Jack | 23 | 3.80 |
| 7 | Lee | 34 | 3.78 |
| 8 | David | 40 | 2.98 |
| 9 | Gasper | 30 | 4.80 |
| 10 | Betina | 51 | 4.10 |
| 11 | Andres | 46 | 3.65 |
unsorted_df.sort_index(axis=1, ascending=True)
| Age | Name | Rating | |
|---|---|---|---|
| 0 | 25 | Tom | 4.23 |
| 1 | 26 | James | 3.24 |
| 2 | 25 | Ricky | 3.98 |
| 3 | 23 | Vin | 2.56 |
| 4 | 30 | Steve | 3.20 |
| 5 | 29 | Minsu | 4.60 |
| 6 | 23 | Jack | 3.80 |
| 7 | 34 | Lee | 3.78 |
| 8 | 40 | David | 2.98 |
| 9 | 30 | Gasper | 4.80 |
| 10 | 51 | Betina | 4.10 |
| 11 | 46 | Andres | 3.65 |
unsorted_df.sort_index(ascending=False)
| Name | Age | Rating | |
|---|---|---|---|
| 11 | Andres | 46 | 3.65 |
| 10 | Betina | 51 | 4.10 |
| 9 | Gasper | 30 | 4.80 |
| 8 | David | 40 | 2.98 |
| 7 | Lee | 34 | 3.78 |
| 6 | Jack | 23 | 3.80 |
| 5 | Minsu | 29 | 4.60 |
| 4 | Steve | 30 | 3.20 |
| 3 | Vin | 23 | 2.56 |
| 2 | Ricky | 25 | 3.98 |
| 1 | James | 26 | 3.24 |
| 0 | Tom | 25 | 4.23 |
按照某列字段进行排序
unsorted_df.sort_values(
by=['Age', 'Rating'], ascending=[True, False])
| Name | Age | Rating | |
|---|---|---|---|
| 6 | Jack | 23 | 3.80 |
| 3 | Vin | 23 | 2.56 |
| 0 | Tom | 25 | 4.23 |
| 2 | Ricky | 25 | 3.98 |
| 1 | James | 26 | 3.24 |
| 5 | Minsu | 29 | 4.60 |
| 9 | Gasper | 30 | 4.80 |
| 4 | Steve | 30 | 3.20 |
| 7 | Lee | 34 | 3.78 |
| 8 | David | 40 | 2.98 |
| 11 | Andres | 46 | 3.65 |
| 10 | Betina | 51 | 4.10 |
Merge & join
left = pd.DataFrame({
'student_id':[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],
'student_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung', 'Billy', 'Brian', 'Bran', 'Bryce', 'Betty', 'Emma', 'Marry', 'Allen', 'Jean', 'Rose', 'David', 'Tom', 'Jack', 'Daniel', 'Andrew'],
'class_id':[1,1,1,2,2,2,3,3,3,4,1,1,1,2,2,2,3,3,3,2],
'gender':['M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F', 'M', 'M', 'F', 'F'],
'age':[20,21,22,20,21,22,23,20,21,22,20,21,22,23,20,21,22,20,21,22],
'score':[98,74,67,38,65,29,32,34,85,64,52,38,26,89,68,46,32,78,79,87]})
right = pd.DataFrame(
{'class_id':[1,2,3,5],
'class_name': ['ClassA', 'ClassB', 'ClassC', 'ClassE']})
left
| student_id | student_name | class_id | gender | age | score | |
|---|---|---|---|---|---|---|
| 0 | 1 | Alex | 1 | M | 20 | 98 |
| 1 | 2 | Amy | 1 | M | 21 | 74 |
| 2 | 3 | Allen | 1 | F | 22 | 67 |
| 3 | 4 | Alice | 2 | F | 20 | 38 |
| 4 | 5 | Ayoung | 2 | M | 21 | 65 |
| 5 | 6 | Billy | 2 | M | 22 | 29 |
| 6 | 7 | Brian | 3 | F | 23 | 32 |
| 7 | 8 | Bran | 3 | F | 20 | 34 |
| 8 | 9 | Bryce | 3 | M | 21 | 85 |
| 9 | 10 | Betty | 4 | M | 22 | 64 |
| 10 | 11 | Emma | 1 | F | 20 | 52 |
| 11 | 12 | Marry | 1 | F | 21 | 38 |
| 12 | 13 | Allen | 1 | M | 22 | 26 |
| 13 | 14 | Jean | 2 | M | 23 | 89 |
| 14 | 15 | Rose | 2 | F | 20 | 68 |
| 15 | 16 | David | 2 | F | 21 | 46 |
| 16 | 17 | Tom | 3 | M | 22 | 32 |
| 17 | 18 | Jack | 3 | M | 20 | 78 |
| 18 | 19 | Daniel | 3 | F | 21 | 79 |
| 19 | 20 | Andrew | 2 | F | 22 | 87 |
right
| class_id | class_name | |
|---|---|---|
| 0 | 1 | ClassA |
| 1 | 2 | ClassB |
| 2 | 3 | ClassC |
| 3 | 5 | ClassE |
r = pd.merge(left, right, how='inner')
r
| student_id | student_name | class_id | gender | age | score | class_name | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | Alex | 1 | M | 20 | 98 | ClassA |
| 1 | 2 | Amy | 1 | M | 21 | 74 | ClassA |
| 2 | 3 | Allen | 1 | F | 22 | 67 | ClassA |
| 3 | 11 | Emma | 1 | F | 20 | 52 | ClassA |
| 4 | 12 | Marry | 1 | F | 21 | 38 | ClassA |
| 5 | 13 | Allen | 1 | M | 22 | 26 | ClassA |
| 6 | 4 | Alice | 2 | F | 20 | 38 | ClassB |
| 7 | 5 | Ayoung | 2 | M | 21 | 65 | ClassB |
| 8 | 6 | Billy | 2 | M | 22 | 29 | ClassB |
| 9 | 14 | Jean | 2 | M | 23 | 89 | ClassB |
| 10 | 15 | Rose | 2 | F | 20 | 68 | ClassB |
| 11 | 16 | David | 2 | F | 21 | 46 | ClassB |
| 12 | 20 | Andrew | 2 | F | 22 | 87 | ClassB |
| 13 | 7 | Brian | 3 | F | 23 | 32 | ClassC |
| 14 | 8 | Bran | 3 | F | 20 | 34 | ClassC |
| 15 | 9 | Bryce | 3 | M | 21 | 85 | ClassC |
| 16 | 17 | Tom | 3 | M | 22 | 32 | ClassC |
| 17 | 18 | Jack | 3 | M | 20 | 78 | ClassC |
| 18 | 19 | Daniel | 3 | F | 21 | 79 | ClassC |
分组聚合
grouped = r.groupby(by=['class_id', 'gender'])
# 返回每个分组的频数
grouped.size()
class_id gender
1 F 3
M 3
2 F 4
M 3
3 F 3
M 3
dtype: int64
# 获取某一个分组细节
grouped.get_group((2, 'F'))
| student_id | student_name | class_id | gender | age | score | class_name | |
|---|---|---|---|---|---|---|---|
| 6 | 4 | Alice | 2 | F | 20 | 38 | ClassB |
| 10 | 15 | Rose | 2 | F | 20 | 68 | ClassB |
| 11 | 16 | David | 2 | F | 21 | 46 | ClassB |
| 12 | 20 | Andrew | 2 | F | 22 | 87 | ClassB |
# 针对每小组执行聚合操作 agg()
grouped.agg({'score':np.mean})
r = grouped.agg({'score':np.mean, 'age':[np.max, np.min]})
r
| score | age | |||
|---|---|---|---|---|
| mean | amax | amin | ||
| class_id | gender | |||
| 1 | F | 52.333333 | 22 | 20 |
| M | 66.000000 | 22 | 20 | |
| 2 | F | 59.750000 | 22 | 20 |
| M | 61.000000 | 23 | 21 | |
| 3 | F | 48.333333 | 23 | 20 |
| M | 65.000000 | 22 | 20 | |
透视表
data = pd.merge(left, right)
# 透视表
data.pivot_table(index='class_id')
| age | score | student_id | |
|---|---|---|---|
| class_id | |||
| 1 | 21.000000 | 59.166667 | 7.000000 |
| 2 | 21.285714 | 60.285714 | 11.428571 |
| 3 | 21.166667 | 56.666667 | 13.000000 |
data
| student_id | student_name | class_id | gender | age | score | class_name | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | Alex | 1 | M | 20 | 98 | ClassA |
| 1 | 2 | Amy | 1 | M | 21 | 74 | ClassA |
| 2 | 3 | Allen | 1 | F | 22 | 67 | ClassA |
| 3 | 11 | Emma | 1 | F | 20 | 52 | ClassA |
| 4 | 12 | Marry | 1 | F | 21 | 38 | ClassA |
| 5 | 13 | Allen | 1 | M | 22 | 26 | ClassA |
| 6 | 4 | Alice | 2 | F | 20 | 38 | ClassB |
| 7 | 5 | Ayoung | 2 | M | 21 | 65 | ClassB |
| 8 | 6 | Billy | 2 | M | 22 | 29 | ClassB |
| 9 | 14 | Jean | 2 | M | 23 | 89 | ClassB |
| 10 | 15 | Rose | 2 | F | 20 | 68 | ClassB |
| 11 | 16 | David | 2 | F | 21 | 46 | ClassB |
| 12 | 20 | Andrew | 2 | F | 22 | 87 | ClassB |
| 13 | 7 | Brian | 3 | F | 23 | 32 | ClassC |
| 14 | 8 | Bran | 3 | F | 20 | 34 | ClassC |
| 15 | 9 | Bryce | 3 | M | 21 | 85 | ClassC |
| 16 | 17 | Tom | 3 | M | 22 | 32 | ClassC |
| 17 | 18 | Jack | 3 | M | 20 | 78 | ClassC |
| 18 | 19 | Daniel | 3 | F | 21 | 79 | ClassC |
# 结果集中只希望看到score列的均值
data.pivot_table(index='class_id', values='score')
| score | |
|---|---|
| class_id | |
| 1 | 59.166667 |
| 2 | 60.285714 |
| 3 | 56.666667 |
# 依据class_id 与 gender 同时做分组
data.pivot_table(index=['class_id','gender'], values='score')
| score | ||
|---|---|---|
| class_id | gender | |
| 1 | F | 52.333333 |
| M | 66.000000 | |
| 2 | F | 59.750000 |
| M | 61.000000 | |
| 3 | F | 48.333333 |
| M | 65.000000 |
data.pivot_table(index=['class_id','gender'],
columns='age', values='score')
| age | 20 | 21 | 22 | 23 | |
|---|---|---|---|---|---|
| class_id | gender | ||||
| 1 | F | 52.0 | 38.0 | 67.0 | NaN |
| M | 98.0 | 74.0 | 26.0 | NaN | |
| 2 | F | 53.0 | 46.0 | 87.0 | NaN |
| M | NaN | 65.0 | 29.0 | 89.0 | |
| 3 | F | 34.0 | 79.0 | NaN | 32.0 |
| M | 78.0 | 85.0 | 32.0 | NaN |
data.pivot_table(index=['class_id','gender'],
columns='age', values='score', aggfunc=np.max)
| age | 20 | 21 | 22 | 23 | |
|---|---|---|---|---|---|
| class_id | gender | ||||
| 1 | F | 52.0 | 38.0 | 67.0 | NaN |
| M | 98.0 | 74.0 | 26.0 | NaN | |
| 2 | F | 68.0 | 46.0 | 87.0 | NaN |
| M | NaN | 65.0 | 29.0 | 89.0 | |
| 3 | F | 34.0 | 79.0 | NaN | 32.0 |
| M | 78.0 | 85.0 | 32.0 | NaN |
r = data.pivot_table(index=['class_id','gender'],
columns='age', values='score', aggfunc=np.max,
margins=True)
r
| age | 20 | 21 | 22 | 23 | All | |
|---|---|---|---|---|---|---|
| class_id | gender | |||||
| 1 | F | 52.0 | 38.0 | 67.0 | NaN | 67 |
| M | 98.0 | 74.0 | 26.0 | NaN | 98 | |
| 2 | F | 68.0 | 46.0 | 87.0 | NaN | 87 |
| M | NaN | 65.0 | 29.0 | 89.0 | 89 | |
| 3 | F | 34.0 | 79.0 | NaN | 32.0 | 79 |
| M | 78.0 | 85.0 | 32.0 | NaN | 85 | |
| All | 98.0 | 85.0 | 87.0 | 89.0 | 98 |
数据分析04-pandas(apply函数、排序、数据合、分组聚合、透视表、交叉表及项目分析)的更多相关文章
- 利用Python进行数据分析-Pandas(第五部分-数据规整:聚合、合并和重塑)
在许多应用中,数据可能分散在许多文件或数据库中,存储的形式也不利于分析.本部分关注可以聚合.合并.重塑数据的方法. 1.层次化索引 层次化索引(hierarchical indexing)是panda ...
- pandas.apply()函数
1.介绍 apply函数是pandas里面所有函数中自由度最高的函数.该函数如下: DataFrame.apply(func, axis=0, broadcast=False, raw=False, ...
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
数据不完整在数据分析的过程中很常见. pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据. pandas使用isnull()和notnull()函数来判断缺失情况. 对于缺失数据一般处理 ...
- pandas apply()函数参数 args
#!/usr/bin/python import pandas as pd data = {'year':[2000,2001,2002,2001,2002],'value':[1.5,1.7,3.6 ...
- SQLServer中利用NTILE函数对数据进行分组的一点使用
本文出处:http://www.cnblogs.com/wy123/p/6908377.html NTILE函数可以按照指定的排序规则,对数据按照指定的组数(M个对象,按照某种排序分N个组)进行分组, ...
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- 数据分析05 /pandas的高级操作
数据分析05 /pandas的高级操作 目录 数据分析05 /pandas的高级操作 1. 替换操作 2. 映射操作 3. 运算工具 4. 映射索引 / 更改之前索引 5. 排序实现的随机抽样/打乱表 ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- (数据科学学习手札99)掌握pandas中的时序数据分组运算
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在使用pandas分析处理时间序列数据 ...
- Flask聚合函数(基本聚合函数、分组聚合函数、去重聚合函数))
Flask聚合函数 1.基本聚合函数(sun/count/max/min/avg) 使用聚合函数先导入:from sqlalchemy import func 使用方法: sun():func.sum ...
随机推荐
- git的回退以及合并,删除什么的
有时候不小心合并了别的分支中的commit.我们需要回退某些提交记录.可以通过reset来操作,reset 会回退到指定commit.这种方式会删除记录,我们最好使用revert命令来操作 git r ...
- C++ 文件知识
#include "iostream" #include "filesystem" #include "fstream" #ifdef WI ...
- el-admin登录详解
1.进入登陆界面后,就会自动获取验证码. 2.前端访问auth/code接口获取后端生成的验证码(包括uuid,img,结果值),然后放入redis,设置2分钟过期,并返回识别码.图片url给前端. ...
- 观察APP运行日志
一.Android采用log工具打印日志,他将各类日志分为五个等级 1.log.e:表示错误信息,比如可能导致程序崩溃的异常 2.log.w:表示警告信息 3.log.i:表示一般信息 4.log.d ...
- finereport连接mysql8.0
1.java包更新 2.下载地址:https://dev.mysql.com/downloads/connector/j/ 3.替换文件为8.0删除5.1版本 4.驱动器手动输入com.mysql.c ...
- badapple最后一步,讲黑白图转为字符图,然后输出就行了。
from PIL import Image import os char_s = list(" .,-'`:!1+*abcdefghijklmnopqrstuvwxyz<>()\ ...
- vivo 短视频用户访问体验优化实践
作者:vivo 互联网运维团队- Hu Tao 本文介绍了vivo短视频用户访问体验优化的实践思路,并简单讲解了实践背后的几点原理. 一.背景 我们平时在看抖音快手视频的时候,如果滑动到某个视频画面一 ...
- MySQL与Java常用数据类型的对应关系
一.字符串数据类型: MySQL类型名 大小 用途 对应Java类名 char 0-255 bytes 定长字符串 (姓名.性别.学号) String varchar 0-65535 bytes 变长 ...
- API网关:开源Apinto网关快速入门
Apinto网关基于GO语言模块化开发,5分钟极速部署,配置简单.易于维护,支持集群与动态扩容,开箱即用.Apinto除了提供丰富的网关插件外,还提供监控告警.用户角色等扩展应用,同时支持自定义网关插 ...
- 逍遥自在学C语言 | 算数运算符
前言 一.人物简介 第一位闪亮登场,有请今后会一直教我们C语言的老师 -- 自在. 第二位上场的是和我们一起学习的小白程序猿 -- 逍遥. 二.算数运算符简介 C语言的算数运算符,是用来完成基本的算术 ...