JAVA缓存规范 —— 虽迟但到的JCache API与天生不俗的Spring Cache

大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
有诗云“纸上得来终觉浅,绝知此事要躬行”,在上一篇文章《手写本地缓存实战2—— 打造正规军,构建通用本地缓存框架》中,我们一起论证并逐步实现了一套简化版本的通用本地缓存框架,并在过程中逐步剖析了缓存设计关键要素的实现策略。本篇文章中,我们一起来聊一聊缓存框架实现所需要遵循的规范。
为何需要规范
上一章中构建的最简化版本的缓存框架,虽然可以使用,但是也存在一个问题,就是它对外提供的实现接口都是框架根据自己的需要而自定义的。这样一来,项目集成了此缓存框架,后续如果想要更换缓存框架的时候,业务层面的改动会比较大。 —— 因为是自定义的框架接口,无法基于里氏替换原则来进行灵活的更换。
在业界各大厂商或者开源团队都会构建并提供一些自己实现的缓存框架或者组件,提供给开发者按需选择使用。如果大家都是各自闭门造车,势必导致业务中集成并使用某一缓存实现之后,想要更换缓存实现组件会难于登天。
千古一帝秦始皇统一天下后,颁布了书同文、车同轨等一系列法规制度,使得所有的车辆都遵循统一的轴距,然后都可以在官道上正常的通行,大大提升了流通性。而正所谓“国有国法、行有行规”,为了保证缓存框架的通用性、提升项目的可移植性,JAVA行业也迫切需要这么一个缓存规范,来约束各个缓存提供商给出的缓存框架都遵循相同的规范接口,业务中按照标准接口进行调用,无需与缓存框架进行深度耦合,使得缓存组件的更换成为一件简单点的事情。
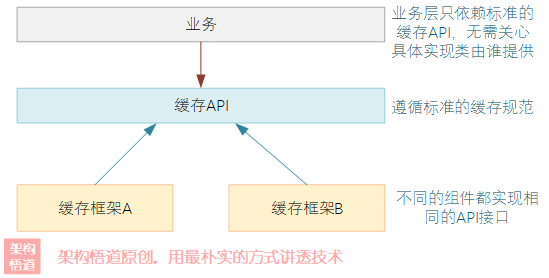
在JAVA的缓存领域,流传比较广泛的主要是JCache API和Spring Cache两套规范,下面就一起来看下。

虽迟但到的JSR107 —— JCache API
提到JAVA中的“行业规矩”,JSR是一个绕不开的话题。它的全称为Java Specification Requests,意思是JAVA规范提案。在该规范标准中,有公布过一个关于JAVA缓存体系的规范定义,也即JSR 107规范(JCache API),主要明确了JAVA中基于内存进行对象缓存构建的一些要求,涵盖内存对象的创建、查询、更新、删除、一致性保证等方面内容。
JSR107规范早在2012年时草案就被提出,但却直到2014年才正式披露首个规范版本,也即JCache API 1.0.0版本,至此JAVA领域总算是有个正式的关于缓存的官方规范要求。
揭秘JSR107 —— JCache API内容探究
JSR107规范具体的要求形式,都以接口的形式封装在javax.cache包中进行提供。我们要实现的缓存框架需要遵循该规范,也就是需要引入javax.cache依赖包,并实现其中提供的相关接口即可。对于使用maven构建的项目中,可以在pom.xml中引入javax.cache依赖:
<dependency><groupId>javax.cache</groupId><artifactId>cache-api</artifactId><version>1.1.1</version></dependency>
在JCache API规范中,定义的缓存框架相关接口类之间的关系逻辑梳理如下:

我们要实现自己的本地缓存框架,也即需要实现上述各个接口。对上述各接口类的含义介绍说明如下:
| 接口类 | 功能定位描述 |
|---|---|
| CachingProvider | SPI接口,缓存框架的加载入口。每个Provider中可以持有1个或者多个CacheManager对象,用来提供不同的缓存能力 |
| CacheManager | 缓存管理器接口,每个缓存管理器负责对具体的缓存容器的创建与管理,可以管理1个或者多个不同的Cache对象 |
| Cache | Cache缓存容器接口,负责存储具体的缓存数据,可以提供不同的容器能力 |
| Entry | Cache容器中存储的key-value键值对记录 |
作为通用规范,这里将CachingProvider定义为了一个SPI接口(Service Provider Interface,服务提供接口),主要是借助JDK自带的服务提供发现能力,来实现按需加载各自实现的功能逻辑,有点IOC的意味。这样设计有一定的好处:
- 对于框架:
需要遵循规范,提供上述接口的实现类。然后可以实现热插拔,与业务解耦。
- 对于业务:
先指定需要使用的SPI的具体实现类,然后业务逻辑中便无需感知缓存具体的实现,直接基于JCache API通用接口进行使用即可。后续如果需要更换缓存实现框架,只需要切换下使用的SPI的具体实现类即可。
根据上述介绍,一个基于JCache API实现的缓存框架在实际项目中使用时的对象层级关系可能会是下面这种场景(假设使用LRU策略存储部门信息、使用普通策略存储用户信息):
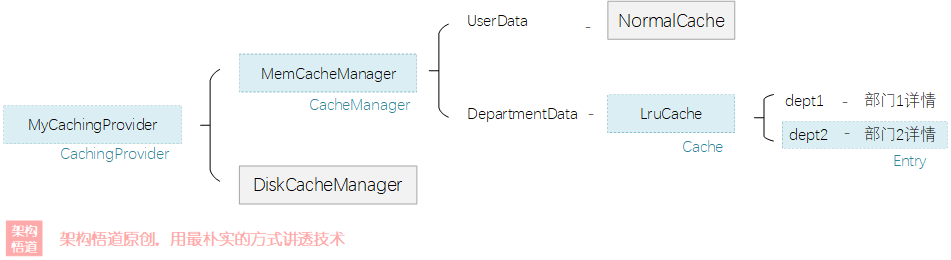
那么如何去理解JCache API中几个接口类的关系呢?
几个简单的说明:
CachingProvider并无太多实际逻辑层面的功能,只是用来基于SPI机制,方便项目中集成插拔使用。内部持有CacheManager对象,实际的缓存管理能力,由CacheManager负责提供。
CacheManager负责具体的缓存管理相关能力实现,实例由
CachingProvider提供并持有,CachingProvider可以持有一个或者多个不同的CacheManager对象。这些CacheManager对象可以是相同类型,也可以是不同类型,比如我们可以实现2种缓存框架,一种是基于内存的缓存,一种是基于磁盘的缓存,则可以分别提供两种不同的CacheManager,供业务按需调用。Cache是CacheManager负责创建并管理的具体的缓存容器,也可以有一个或者多个,如业务中会涉及到为用户列表和部门列表分别创建独立的
Cache存储。此外,Cache容器也可以根据需要提供不同的Cache容器类型,以满足不同场景对于缓存容器的不同诉求,如我们可以实现一个类似HashMap的普通键值对Cache容器,也可以提供一个基于LRU淘汰策略的Cache容器。
至此呢,我们厘清了JCache API规范的大致内容。
插叙 —— SPI何许人也
按照JSR107规范试编写缓存具体能力时,我们需要实现一个SPI接口的实现类,然后由JDK提供的加载能力将我们扩展的缓存服务加载到JVM中供使用。
提到API我们都耳熟能详,也就是我们常规而言的接口。但说起SPI也许很多小伙伴就有点陌生了。其实SPI也并非是什么新鲜玩意,它是JDK内置的一种服务的提供与发现、加载机制。按照JAVA的面向对象编码的思想,为了降低代码的耦合度、提升代码的灵活性,往往需要利用好抽象这一特性,比如一般会比较推荐基于接口进行编码、而尽量避免强依赖某个具体的功能实现类 —— 这样才能让构建出的系统具有更好的扩展性,更符合面向对象设计原则中的里式替换原则。SPI便是为了支持这一诉求而提供的能力,它允许将接口具体的实现类交由业务或者三方进行独立构建,然后加载到JVM中以供业务进行使用。
为了这一点,我们需要在resource/META-INF/services目录下新建一个文件,文件名即为SPI接口名称javax.cache.spi.CachingProvider,然后在文件内容中,写入我们要注入进入的我们自己的Provider实现类:

这样,我们就完成了将我们自己的MyCachingProvider功能注入到系统中。在业务使用时,可以通过Caching.getCachingProvider()获取到注入的自定义Provider。
public static void main(String[] args) {CachingProvider provider = Caching.getCachingProvider();System.out.println(provider);}
从输出的结果可以看出,获取到了自定义的Provider对象:
com.veezean.skills.cache.fwk.MyCachingProvider@7adf9f5f
获取到Provider之后,便可以进一步的获取到Manager对象,进而业务层面层面可以正常使用。
JCache API规范的实现
JSR作为JAVA领域正统行规,制定的时候往往考虑到各种可能的灵活性与通用性。作为JSR中根正苗红的JCache API规范,也沿袭了这一风格特色,框架接口的定义与实现也非常的丰富,几乎可以扩展自定义任何你需要的处理策略。 —— 但恰是这一点,也让其整个框架的接口定义过于重量级。对于缓存框架实现者而言,遵循JCache API需要实现众多的接口,需要做很多额外的实现处理。
比如,我们实现CacheManager的时候,需要实现如下这么多的接口:
public class MemCacheManager implements CacheManager {private CachingProvider cachingProvider;private ConcurrentHashMap<String, Cache> caches;public MemCacheManager(CachingProvider cachingProvider, ConcurrentHashMap<String, Cache> caches) {this.cachingProvider = cachingProvider;this.caches = caches;}@Overridepublic CachingProvider getCachingProvider() {}@Overridepublic URI getURI() {}@Overridepublic ClassLoader getClassLoader() {}@Overridepublic Properties getProperties() {}@Overridepublic <K, V, C extends Configuration<K, V>> Cache<K, V> createCache(String s, C c) throws IllegalArgumentException {}@Overridepublic <K, V> Cache<K, V> getCache(String s, Class<K> aClass, Class<V> aClass1) {}@Overridepublic <K, V> Cache<K, V> getCache(String s) {}@Overridepublic Iterable<String> getCacheNames() {}@Overridepublic void destroyCache(String s) {}@Overridepublic void enableManagement(String s, boolean b) {}@Overridepublic void enableStatistics(String s, boolean b) {}@Overridepublic void close() {}@Overridepublic boolean isClosed() {}@Overridepublic <T> T unwrap(Class<T> aClass) {}}
长长的一摞接口等着实现,看着都令人上头,作为缓存提供商,便需要按照自己的能力去实现这些接口,以保证相关缓存能力是按照规范对外提供。也正是因为JCache API这种不接地气的表现,让其虽是JAVA 领域的正统规范,却经常被束之高阁,沦落成为了一种名义规范。业界主流的本地缓存框架中,比较出名的当属Ehcache了(当然,Spring4.1中也增加了对JSR规范的支持)。此外,Redis的本地客户端Redisson也有实现全套JCache API规范,用户可以基于Redisson调用JCache API的标准接口来进行缓存数据的操作。
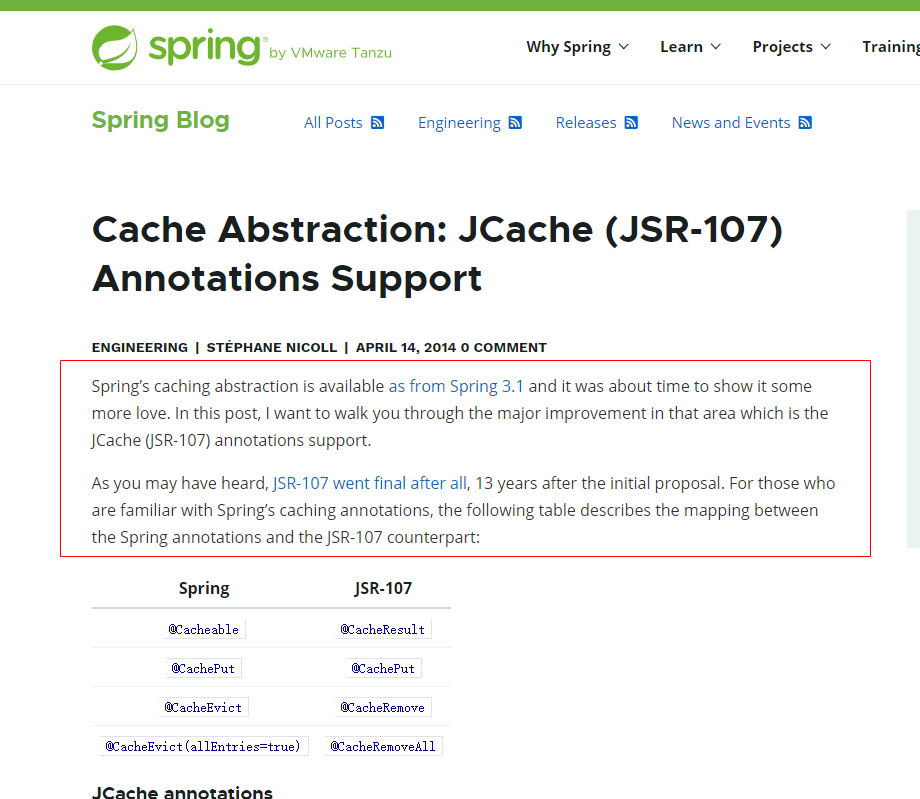
JSR107提供的注解操作方法
前面提到了作为供应商想要实现JSR107规范的时候会比较复杂,需要做很多自己的处理逻辑。但是对于业务使用者而言,JSR107还是比较贴心的。比如JSR107中就将一些常用的API方法封装为注解,利用注解来大大简化编码的复杂度,降低缓存对于业务逻辑的侵入性,使得业务开发人员可以更加专注于业务本身的开发。
JSR107规范中常用的一些缓存操作注解方法梳理如下面的表格:
| 注解 | 含义说明 |
|---|---|
| @CacheResult | 将指定的key和value映射内容存入到缓存容器中 |
| @CachePut | 更新指定缓存容器中指定key值缓存记录内容 |
| @CacheRemove | 移除指定缓存容器中指定key值对应的缓存记录 |
| @CacheRemoveAll | 字面含义,移除指定缓存容器中的所有缓存记录 |
| @CacheKey | 作为接口参数前面修饰,用于指定特定的入参作为缓存key值的组成部分 |
| @CacheValue | 作为接口参数前面的修饰,用于指定特定的入参作为缓存value值 |
上述注解主要是添加在方法上面,用于自动将方法的入参与返回结果之间进行一个映射与自动缓存,对于后续请求如果命中缓存则直接返回缓存结果而无需再次执行方法的具体处理,以此来提升接口的响应速度与承压能力。
比如下面的查询接口上,通过@CacheResult注解可以将查询请求与查询结果缓存起来进行使用:
@CacheResult(cacheName = "books")public Book findBookByName(@CacheKey String bookName) {return bookDao.queryByName(bookName);}
当Book信息发生变更的时候,为了保证缓存数据的准确性,需要同步更新缓存内容。可以通过在更新方法上面添加@CachePut接口即可达成目的:
@CachePut(cacheName = "books")public void updateBookInfo(@CacheKey String bookName, @CacheValue Book book) {bookDao.updateBook(bookName, book);}
这里分别适用了@CacheKey和@CacheValue指定了需要更新的缓存记录key值,以及需要将其更新为的新的value值。
同样地,借助注解@CacheRemove可以完成对应缓存记录的删除:
@CacheRemove(cacheName = "books")public void deleteBookInfo(@CacheKey String bookName) {bookDao.deleteBookByName(bookName)}
爱屋及乌 —— Spring框架制定的Cache规范
JSR 107(JCache API)规范的诞生可谓是一路坎坷,拖拖拉拉直到2014年才发布了首个1.0.0版本规范。但是在JAVA界风头无两的Spring框架早在2011年就已经在其3.1版本中提供了缓存抽象层的规范定义,并借助Spring的优秀设计与良好生态,迅速得到了各个软件开发团体的青睐,各大缓存厂商也陆续提供了符合Spring Cache规范的自家缓存产品。
Spring Cache并非是一个具体的缓存实现,而是和JSR107类似的一套缓存规范,基于注解并可实现与Spring的各种高级特性无缝集成,受到了广泛的追捧。各大缓存提供商几乎都有基于Spring Cache规范进行实现的缓存组件。比如后面我们会专门介绍的Guava Cache、Caffeine Cache以及同样支持JSR107规范的Ehcache等等。
得力于Spring在JAVA领域无可撼动的地位,造就了Spring Cache已成为JAVA缓存领域的“事实标准”,深有“功高盖主”的味道。
Spring Cache使用不同缓存组件
如果要基于Spring Cache规范来进行缓存的操作,首先在项目中需要引入此规范的定义:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency>
这样,在业务代码中,就可以使用Spring Cache规范中定义的一些注解方法。前面有提过,Spring Cache只是一个规范声明,可以理解为一堆接口定义,而并没有提供具体的接口功能实现。具体的功能实现,由业务根据实际选型需要,引入相应缓存组件的jar库文件依赖即可 —— 这一点是Spring框架中极其普遍的一种做法。
假如我们需要使用Guava Cache来作为我们实际缓存能力提供者,则我们只需要引入对应的依赖即可:
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>30.1.1-jre</version></dependency>
这样一来,我们便实现了使用Guava cache作为存储服务提供者、且基于Spring Cache接口规范进行缓存操作。Spring作为JAVA领域的一个相当优秀的框架,得益于其优秀的封装设计思想,使得更换缓存组件也显得非常容易。比如现在想要将上面的Guava cache更换为Caffeine cache作为新的缓存能力提供者,则业务代码中将依赖包改为Caffeine cache并简单的做一些细节配置即可:
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.1.1</version></dependency>
这样一来,对于业务使用者而言,可以方便的进行缓存具体实现者的替换。而作为缓存能力提供商而言,自己可以轻易的被同类产品替换掉,所以也鞭策自己去提供更好更强大的产品,巩固自己的地位,也由此促进整个生态的良性演进。
Spring Cache规范提供的注解
需要注意的是,使用Spring Cache缓存前,需要先手动开启对于缓存能力的支持,可以通过@EnableCaching注解来完成。
除了@EnableCaching,在Spring Cache中还定义了一些其它的常用注解方法,梳理归纳如下:
| 注解 | 含义说明 |
|---|---|
| @EnableCaching | 开启使用缓存能力 |
| @Cacheable | 添加相关内容到缓存中 |
| @CachePut | 更新相关缓存记录 |
| @CacheEvict | 删除指定的缓存记录,如果需要清空指定容器的全部缓存记录,可以指定allEntities=true来实现 |
具体的使用上,其实和JSR107规范中提供的注解用法相似。
当然了,JAVA领域缓存事实规范地位虽已奠定,但是Spring Cache依旧是保持着一个兼收并蓄的姿态,并积极的兼容了JCache API相关规范,比如Spring4.1起项目中可以使用JSR107规范提供的相关注解方法来操作。
小结回顾
好啦,关于JAVA中的JSR107规范以及Spring Cache规范,以及各自典型代表,我们就聊到这里。
那么,关于本文中提及的缓存规范的内容,你是否有自己的一些想法与见解呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
补充说明1 :
本文属于《深入理解缓存原理与实战设计》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学。
如果有兴趣,也欢迎关注此专栏。
补充说明2 :
- 关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。

JAVA缓存规范 —— 虽迟但到的JCache API与天生不俗的Spring Cache的更多相关文章
- 一个缓存使用案例:Spring Cache VS Caffeine 原生 API
最近在学习本地缓存发现,在 Spring 技术栈的开发中,既可以使用 Spring Cache 的注解形式操作缓存,也可用各种缓存方案的原生 API.那么是否 Spring 官方提供的就是最合适的方案 ...
- Java日志规范
前言 一个在生产环境里运行的程序如果没有日志是很让维护者提心吊胆的,有太多杂乱又无意义的日志也是令人伤神.程序出现问题时候,从日志里如果发现不了问题可能的原因是很令人受挫的.本文想讨论的是如何在Jav ...
- 阿里java开发规范学习(附P3C IDEA插件 帮助规范的养成)
浅析 阿里巴巴 Java 开发规约 (未完成) 更加优秀的页面展现请到浅析 阿里巴巴 Java 开发规约 contents 为什么要学 编程规约 P3C IDEA 插件 why-use 我们知道,一般 ...
- CheckStyle,定制属于自己的Java编码规范
前言 如今,代码规范几乎是当下稍有追求的团队都要求做到的,但是对于Java编码规范,不同的公司或团队却有着不同的标准.尽管官方提供了一些标准,但是在基本规则的基础上,各大公司又有自己的规范,比如Sun ...
- 更好用 更简单的Java缓存框架 jscache
比Spring Cache 更好用 更简单的缓存工具 jscache 取名意义为 java simple cache,基于AOP实现,支持注解到接口 自定义单个缓存过期时间配置 ttl,轻松扩展缓存实 ...
- 高效能团队的Java研发规范(进阶版)
目前大部分团队是使用的阿里巴巴Java开发规范,不过在日常开发中难免遇到覆盖不到的场景,本文在阿里巴巴Java开发规范基础上,补充一些常用的规范,用于提升代码质量及增强代码可读性. 编程规约 1.基础 ...
- Java模块化规范之争(转载)
经过近20年的发展,Java语言已成为今日世界上最成功.使用的开发者人数最多的语言之一,Java世界中无数商业的或开源的组织.技术和产品共同构成了一个无比庞大的生态系统. 与大多数开发人员的普遍认知不 ...
- [Java 缓存] Java Cache之 Guava Cache的简单应用.
前言 今天第一次使用MarkDown的形式发博客. 准备记录一下自己对Guava Cache的认识及项目中的实际使用经验. 一: 什么是Guava Guava工程包含了若干被Google的 Java项 ...
- JAVA语言规范-线程和锁章节之同步、等待和通知
JAVA语言规范:线程和锁 1 同步 java编程语言提供了线程间通信的多种机制.这些方法中最基本的是同步化,此方法是使用监视器实现的.JAVA中每个对象与一个监视器相关联,一个线程可以加锁和解锁监视 ...
- 转!!Java代码规范、格式化和checkstyle检查配置文档
为便于规范各位开发人员代码.提高代码质量,研发中心需要启动代码评审机制.为了加快代码评审的速度,减少不必要的时间,可以加入一些代码评审的静态检查工具,另外需要为研发中心配置统一的编码模板和代码格式化模 ...
随机推荐
- Python入门系列(三)一学就会-基础数据类型
数据类型 您可以使用type()函数获取任何对象的数据类型. x = 5 print(type(x)) 数字类型 x = 1 # int y = 2.8 # float z = 1j # comple ...
- Android Kotlin Annotation Processer
Annotation Processer 注解处理器(Annotation Processer)是javac内置的注解处理工具,可以在编译时处理注解,让我们自己做相应的处理.比如生成重复度很高的代码, ...
- Configuration的学习
创建 //1.创建,调用的空惨 Configuration conf = new Configuration(); 加载主配置 //2.读取主配置文件==>如果是空参方法则自动加载sec下的re ...
- K8S之YAML配置文件
通过 YAML 配置文件 部署 Deployment 使用命令(类似 docker-compose) // 部署 kubectl create -f xxx.yml // 删除 kubectl del ...
- Java 热更新 Groovy 实践及踩坑指南
Groovy 是什么? Apache的Groovy是Java平台上设计的面向对象编程语言.这门动态语言拥有类似Python.Ruby和Smalltalk中的一些特性,可以作为Java平台的脚本语言使用 ...
- 从Spring中学到的【1】--读懂继承链
最近看了一些 Spring 源码,发现源码分析的文章很多,而底层思想分析的文章比较少,这个系列文章准备总结一下Spring中给我的启示,包括设计模式思想.SOLID设计原则等,涉及一些编程的基本原则, ...
- 思维导图学《On Java》基础卷 + 进阶卷
说明 目录 思维导图 导读 第 1 章 什么是对象 第 3 章 一切都是对象 第 6 章 初始化和清理 第 7 章 实现隐藏 第 8 章 复用 第 9 章 多态 第 10 章 接口 第 11 章 内部 ...
- 在k8s中部署前后端分离项目进行访问的两种配置方式
第一种方式 (1) nginx配置中只写前端项目的/根路径配置 前端项目使用的Dockerfile文件内容 把前端项目编译后生成的dist文件夹放在nginx的html默认目录下,浏览器访问前端项目时 ...
- 在k8s中将nginx.conf文件内容创建为ConfigMap挂载到pod容器中
将nginx.conf文件内容创建为ConfigMap user nginx; worker_processes auto; error_log /var/log/nginx/error.log er ...
- Kafka QuickStart
环境版本 操作系统:CentOS release 6.6 (Final) java版本: jdk1.8 kafka 版本: kafka_2.11-1.1.1.tgz 安装kafka 1. 下载压缩包, ...