雪花算法-Java分布式系统自增id
1、雪花算法的用途
分布式系统中ID生成方案,比较简单的是UUID(Universally Unique Identifier,通用唯一识别码),但是其存在两个明显的弊端:
一、UUID是128位的,长度过长;
二、UUID是完全随机的,无法生成递增有序的UUID。
而现在流行的基于 Snowflake 雪花算法的ID生成方案就可以很好的解决了UUID存在的这两个问题
2、算法原理
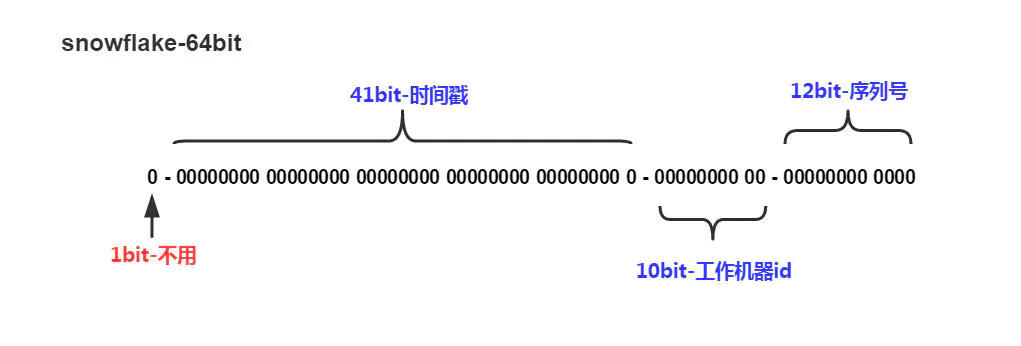
1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
41bit-时间戳,用来记录时间戳,毫秒级。
- 41位可以表示个数字,
- 如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至
- 也就是说41位可以表示年
10bit-工作机器id,用来记录工作机器id。
- 可以部署在个节点,包括5位datacenterId和5位workerId
- 5位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId
12bit-序列号,序列号,用来记录同毫秒内产生的不同id。
- 12位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
3、Java 实现雪花算法
public class IdWorker{
//下面两个每个5位,加起来就是10位的工作机器id
private long workerId; //工作id
private long datacenterId; //数据id
//12位的序列号
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence){
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
//初始时间戳
private long twepoch = 1288834974657L;
//长度为5位
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
//最大值
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列号id长度
private long sequenceBits = 12L;
//序列号最大值
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//工作id需要左移的位数,12位
private long workerIdShift = sequenceBits;
//数据id需要左移位数 12+5=17位
private long datacenterIdShift = sequenceBits + workerIdBits;
//时间戳需要左移位数 12+5+5=22位
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//上次时间戳,初始值为负数
private long lastTimestamp = -1L;
public long getWorkerId(){
return workerId;
}
public long getDatacenterId(){
return datacenterId;
}
public long getTimestamp(){
return System.currentTimeMillis();
}
//下一个ID生成算法
public synchronized long nextId() {
long timestamp = timeGen();
//获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
//获取当前时间戳如果等于上次时间戳(同一毫秒内),则在序列号加一;否则序列号赋值为0,从0开始。
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
//将上次时间戳值刷新
lastTimestamp = timestamp;
/**
* 返回结果:
* (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数
* (datacenterId << datacenterIdShift) 表示将数据id左移相应位数
* (workerId << workerIdShift) 表示将工作id左移相应位数
* | 是按位或运算符,例如:x | y,只有当x,y都为0的时候结果才为0,其它情况结果都为1。
* 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id
*/
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
//获取时间戳,并与上次时间戳比较
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
//获取系统时间戳
private long timeGen(){
return System.currentTimeMillis();
}
//---------------测试---------------
public static void main(String[] args) {
IdWorker worker = new IdWorker(1,1,1);
for (int i = 0; i < 30; i++) {
System.out.println(worker.nextId());
}
}
}
雪花算法-Java分布式系统自增id的更多相关文章
- 开源一个比雪花算法更好用的ID生成算法(雪花漂移)
比雪花算法更好用的ID生成算法(单机或分布式唯一ID) 转载及版权声明 本人从未在博客园之外的网站,发表过本算法长文,其它网站所现文章,均属他人拷贝之作. 所有拷贝之作,均须保留项目开源链接,否则禁止 ...
- 使用雪花算法为分布式下全局ID、订单号等简单解决方案考虑到时钟回拨
1.snowflake简介 互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同 ...
- 雪花算法 Java 版
雪花算法根据时间戳生成有序的 64 bit 的 Long 类型的唯一 ID 各 bit 含义: 1 bit: 符号位,0 是正数 1 是负数, ID 为正数,所以恒取 0 41 bit: 时间差,我们 ...
- SnowflakeId雪花ID算法,分布式自增ID应用
概述 snowflake是Twitter开源的分布式ID生成算法,结果是一个Long型的ID.其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器I ...
- 雪花算法,生成分布式唯一ID
2.3 基于算法实现 [转载] 这里介绍下Twitter的Snowflake算法——snowflake,它把时间戳,工作机器id,序列号组合在一起,以保证在分布式系统中唯一性和自增性. snowfla ...
- 全局唯一Id:雪花算法
雪花算法-snowflake 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有 ...
- 雪花算法生成分布式ID
分布式主键ID生成方案 分布式主键ID的生成方案有以下几种: 数据库自增主键 缺点: 导入旧数据时,可能会ID重复,导致导入失败 分布式架构,多个Mysql实例可能会导致ID重复 UUID 缺点: 占 ...
- 雪花算法-snowflake
雪花算法-snowflake 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有 ...
- 分布式系统为什么不用自增id,要用雪花算法生成id???
1.为什么数据库id自增和uuid不适合分布式id id自增:当数据量庞大时,在数据库分库分表后,数据库自增id不能满足唯一id来标识数据:因为每个表都按自己节奏自增,会造成id冲突,无法满足需求. ...
- 【Java】分布式自增ID算法---雪花算法 (snowflake,Java版)
一般情况,实现全局唯一ID,有三种方案,分别是通过中间件方式.UUID.雪花算法. 方案一,通过中间件方式,可以是把数据库或者redis缓存作为媒介,从中间件获取ID.这种呢,优点是可以体现全局的递增 ...
随机推荐
- 破解练习-CRACKME001
001-注册算法分析 一.工具和调试环境 动态调试工具:x64dbg 系统环境:win10 1909 二.分析Serial/name的算法 由于Serial里面就是一个字符串比较,没有啥算法,这里就不 ...
- PostgresSQL 常用操作方法
1.后台生成XML作为参数然后数据库解析获取数据 var idList = ids.Split(new string[] { "," }, StringSplitOptions.R ...
- 实现简单的`Blazor`低代码
本篇博客只实现基本的低代码,比如新增组件,动态修改组件参数 创建项目 首先创建一个空的Blazor Server,并且命名LowCode.Web 实现我们还需要引用一个Blazor组件库,由于作者用M ...
- 非线性优化-NLopt
通过 对 一个 数学 模型 的求解 来介绍 NLopt的使用方法 数学模型: 这个是目标函数 求满足 条件的情况下 x2的开平方最小 边界约束 非线性不等式约束如下 有两个参数 x1 和 x2 ,其中 ...
- CSS常用属性(2)
(4) position(定位) fixed 一般用来写网页顶端的固定导航条,或者两侧的菜单. <!--对于块级标签来说加上position:fixed之后,该div就不会占一整行,一般需要手动 ...
- 安卓逆向 ARM基础篇
1.ARM 与 Andorid 的关系 android 的操作系统是 LINUX 内核 LINux又是ARM 2.ARM汇编规范 3.ARM指令格式 ARM常用指令开始 1.ARM 的跳转指令 PC ...
- 【译】.NET 7 中的性能改进(五)
原文 | Stephen Toub 翻译 | 郑子铭 循环提升和克隆 (Loop Hoisting and Cloning) 我们之前看到PGO是如何与循环提升和克隆互动的,这些优化也有其他改进. 从 ...
- Os-hackNos
Os-hackNos 目录 Os-hackNos 1 环境配置 1.1 靶场环境 1.2 靶机未获取到IP时配置 2 信息收集 2.1 端口扫描 2.2 目录扫描 3 对Drupal 7.57版本安全 ...
- pytorch学习笔记一之张量
1. 张量¶ 1.1. 概述¶ 张量(tensor)是pytorch中的一种较为基础的数据结构,类比于numpy中的ndarrays,在pytorch中,张量可以在GPU中进行运算 通 ...
- nginx中多ip多域名多端口配置
1.Nginx中多IP配置: server { listen 80; server_name 192.168.15.7; location / { root /opt/Super_Marie; ind ...