用requests-html和SelectorGadget轻松精准抓取网页数据
我们在抓取网页数据时,最常採用Python的requests搭配BeautifulSoup的模式来完成。然而,requests-html整合了上述2个套件,又添加了新的功能,或许是抓取网页数据值得考虑的新选项。我们来看个实例,假设我们想要抓取stackoverflow网站上有关Python问题第1页的标题,先在网页上按"F12"查看网页原始码;我们会发现"a.s-link"可能会是个不错的CSS Selector。
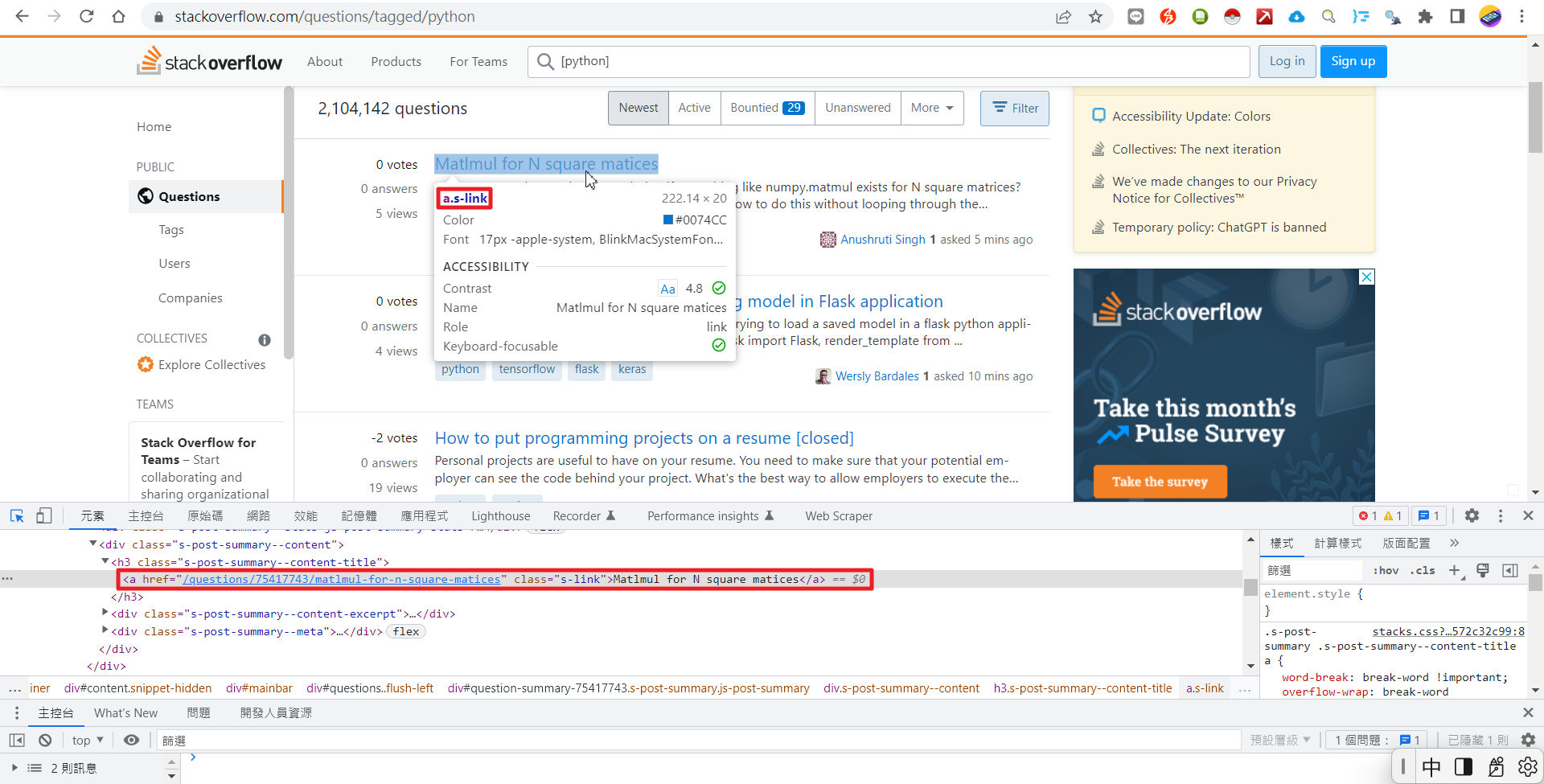
因此,初步尝试撰写爬虫代码如下:
1 from requests_html import HTMLSession
2
3 session = HTMLSession()
4 keyword = 'Python'
5 url = f'https://stackoverflow.com/questions/tagged/{keyword}'
6 r = session.get(url)
7 titles = r.html.find('a.s-link')
8
9 for title in titles:
10 print(title.text)
可是,程式执行之后;我们会看到数据的上方多了2行空白,下方的"Hot Network Quesions"又不是我们想要的数据。
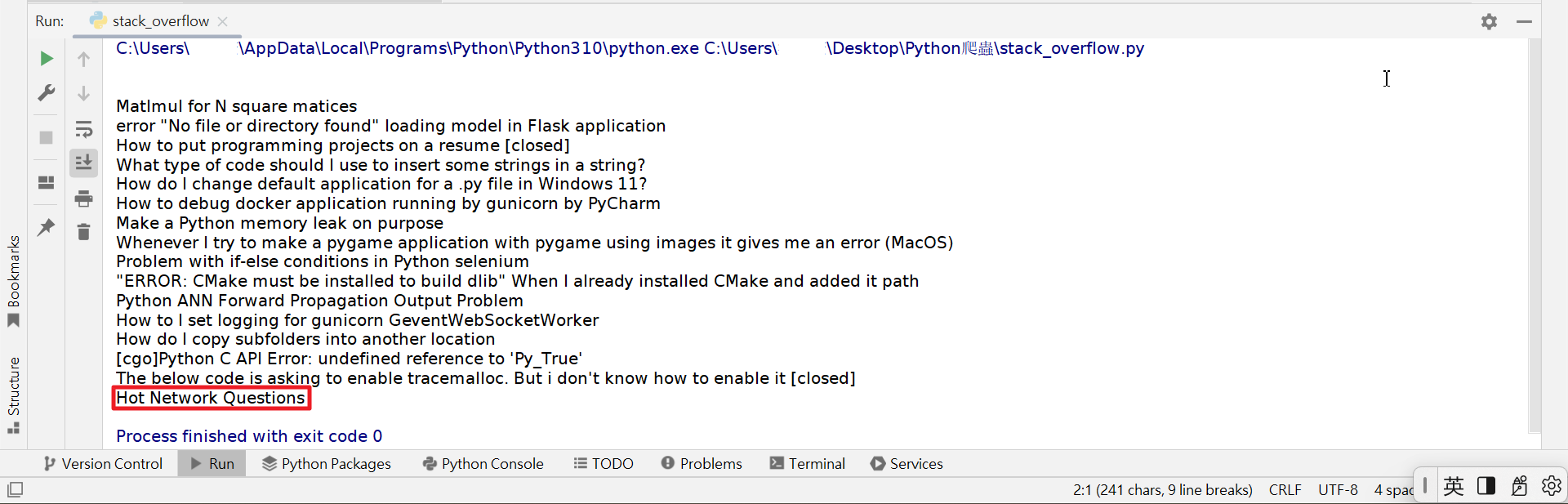
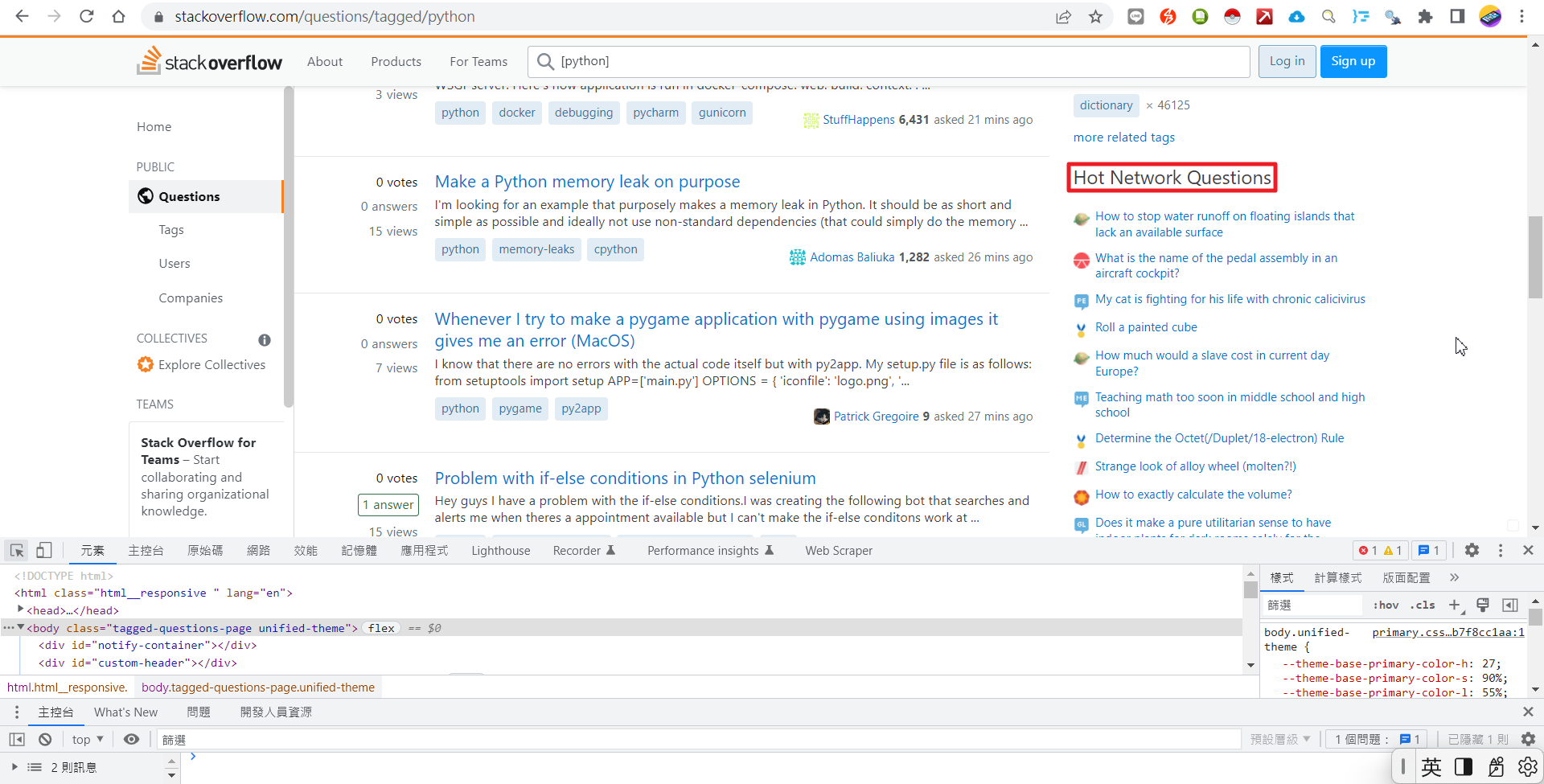
显然,我们设定的CSS Selector不太正确。在修正这个问题之前,我们先把SelectorGadget这个Chrome浏览器的插件安装好,并钉选在工具列上以方便日后操作。启动SelectorGadget之后,点选stackoverflow页面上的任1个问题的标题;选中的标题会变成绿色,其他的标题会变成黄色;但同时会看到"Hot Network Quesions"也变成了黄色。此时,再点选"Hot Network Quesions",会让"Hot Network Quesions"变成红色而被排除在外。
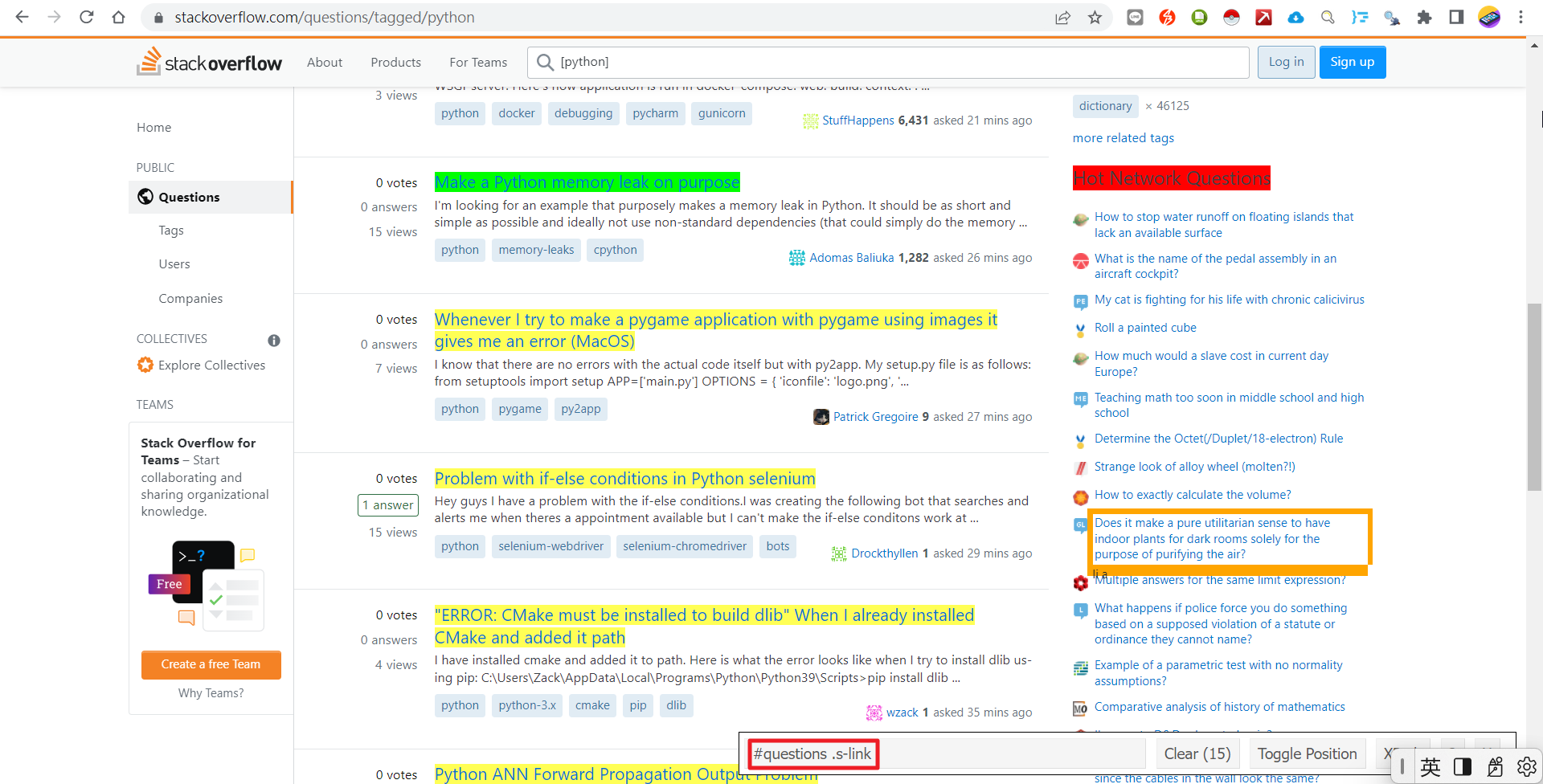
对SelectorGadget视窗左方的CSS Selector按滑鼠右键选"複製",取代原先代码中的CSS Selector。
titles = r.html.find('#questions .s-link')
再次执行程式,我们会看到果然输出了正确的结果。
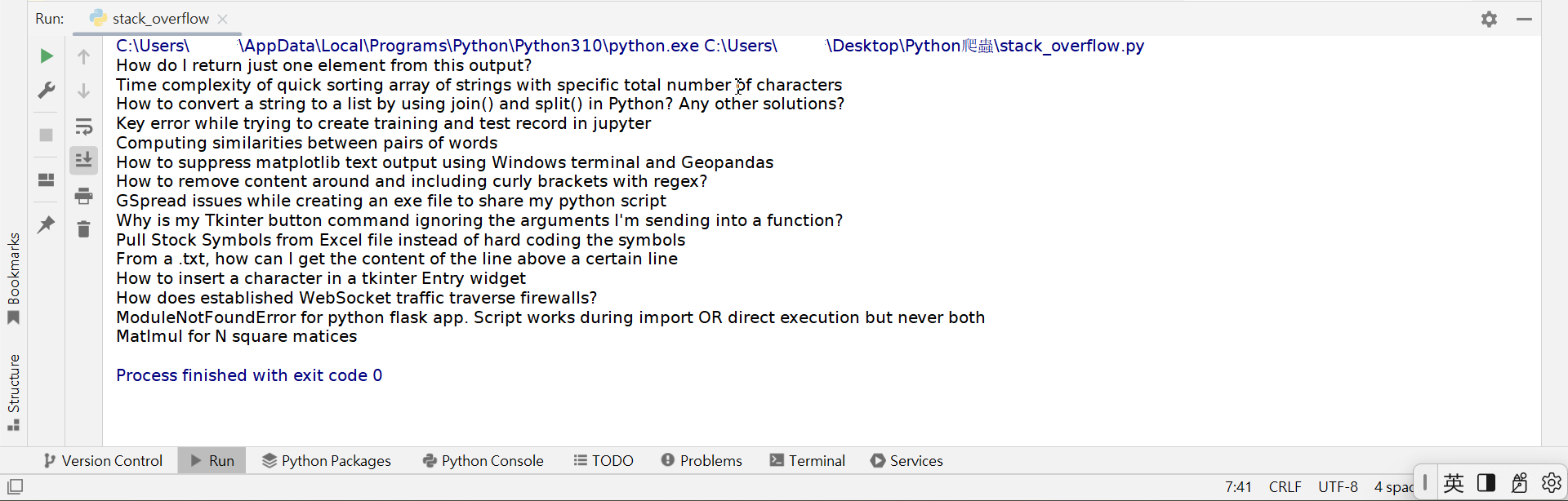
如果我们想要更进一步精准地从上面的标题中挑出含有"Python"的标题,也是非常容易地喔。只要在find()方法中添加containing参数即可。
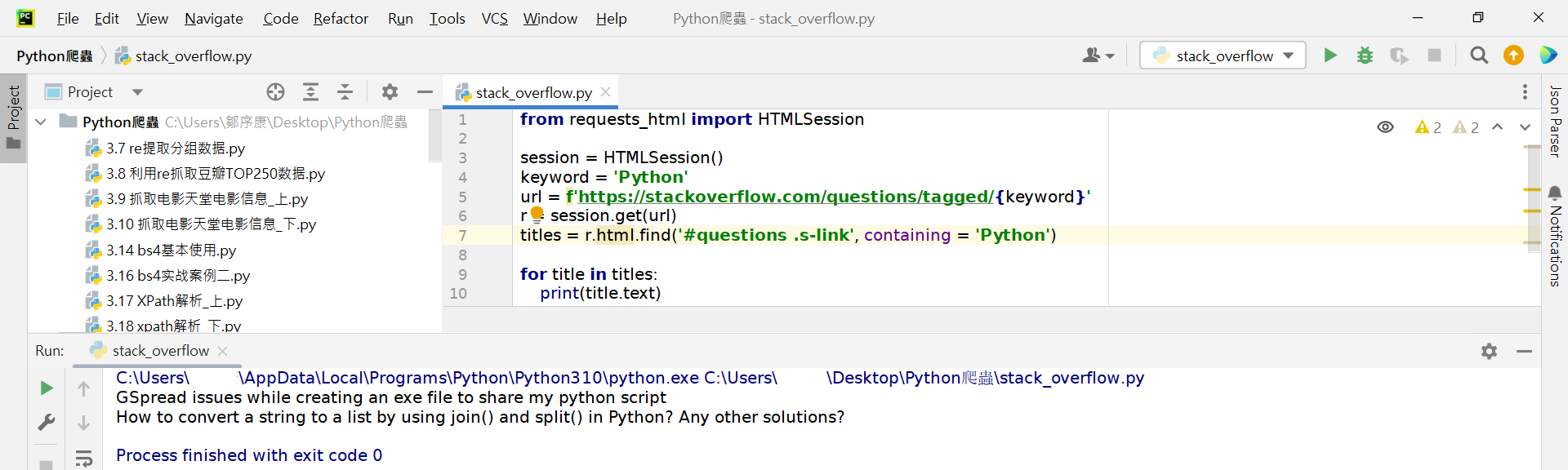
有没有发现requests-html搭配SelectorGadget真得是超好用的呢?!
用requests-html和SelectorGadget轻松精准抓取网页数据的更多相关文章
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
- Asp.net 使用正则和网络编程抓取网页数据(有用)
Asp.net 使用正则和网络编程抓取网页数据(有用) Asp.net 使用正则和网络编程抓取网页数据(有用) /// <summary> /// 抓取网页对应内容 /// </su ...
- 使用HtmlAgilityPack批量抓取网页数据
原文:使用HtmlAgilityPack批量抓取网页数据 相关软件点击下载登录的处理.因为有些网页数据需要登陆后才能提取.这里要使用ieHTTPHeaders来提取登录时的提交信息.抓取网页 Htm ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- c#抓取网页数据
写了一个简单的抓取网页数据的小例子,代码如下: //根据Url地址得到网页的html源码 private string GetWebContent(string Url) { string strRe ...
- 使用JAVA抓取网页数据
一.使用 HttpClient 抓取网页数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ...
- 【iOS】正則表達式抓取网页数据制作小词典
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/xn4545945/article/details/37684127 应用程序不一定要自己去提供数据. ...
- 01 UIPath抓取网页数据并导出Excel(非Table表单)
上次转载了一篇<UIPath抓取网页数据并导出Excel>的文章,因为那个导出的是table标签中的数据,所以相对比较简单.现实的网页中,有许多不是通过table标签展示的,那又该如何处理 ...
- Node.js的学习--使用cheerio抓取网页数据
打算要写一个公开课网站,缺少数据,就决定去网易公开课去抓取一些数据. 前一阵子看过一段时间的Node.js,而且Node.js也比较适合做这个事情,就打算用Node.js去抓取数据. 关键是抓取到网页 ...
- Java抓取网页数据(原网页+Javascript返回数据)
有时候由于种种原因,我们需要采集某个网站的数据,但由于不同网站对数据的显示方式略有不同! 本文就用Java给大家演示如何抓取网站的数据:(1)抓取原网页数据:(2)抓取网页Javascript返回的数 ...
随机推荐
- drf-day2——restful规范、序列化反序列化、基于django编写五个原生接口、drf介绍和快速使用、cbv源码分析
目录 一.restful规范(重要,不难) 概念 十个规范 二.序列化反序列化 三.基于django原生编写5个接口 四.drf介绍和快速使用 概念 安装 代码 五.cbv源码分析 六.作业 1.使用 ...
- ES6块级作用域let声明和const声明以及与var之间的区别
一.ES6块级作用域 let 声明 块级声明用于声明在指定作用域之外无法访问的变量,存在于: ①函数内部 ②块内(字符{和}之间的区域) 禁止重声明 (1)如果在作用域由已经存在某个标识,再用let声 ...
- python线程池等待全部任务结束再继续
import json import time from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED impor ...
- 学习ASP.NET Core Blazor编程系列二十六——登录(5)
学习ASP.NET Core Blazor编程系列文章之目录 学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应 ...
- sublime text中开启本地服务器
步骤: 1 Ctrl+shift+p-> 输入选中install package 2 输入sublimeserver回车安装即可 3 安装完了以后,需要开启服务器 4 回到页面上右键 转载于:h ...
- WPF Xaml标签的一些特殊符号 如何输入
小于号 < 输入 < 注意有分号 大于号 > 输入 > 符号 & 输入 & 引号 " 输入 "
- .Net DI(Dependency Injection)依赖注入机制
1.简介 DI:Dependency Injection,即依赖注入,他是IOC的具体实现. 在DI中,底层服务对象不再负责依赖关系的创建,而是交由顶端调用进行管理注入 好处:降低组件之间的耦合度,使 ...
- 添加material ui库
ng add @angular/material 自定义预构建主题 ? Choose a prebuilt theme name, or "custom" for a custom ...
- pdf.js 跨域完美解决!
在网上查看很多方法去解决此类跨域问题,及如何动态加载pdf文件.看来看去 请求的由后台处理加header头的 pdf.js 自带的 获取地址栏param参数值的 都是很麻烦的步骤并且有时不能有效解决 ...
- Vulnhub:Five86-2靶机
kali:192.168.111.111 靶机:192.168.111.211 信息收集 端口扫描 nmap -A -v -sV -T5 -p- --script=http-enum 192.168. ...