Colab教程(超级详细版)及Colab Pro/Colab Pro+使用评测
一、Colab介绍
Colab是什么?
Colab相关的概念
二、Colab工作流程
准备工作
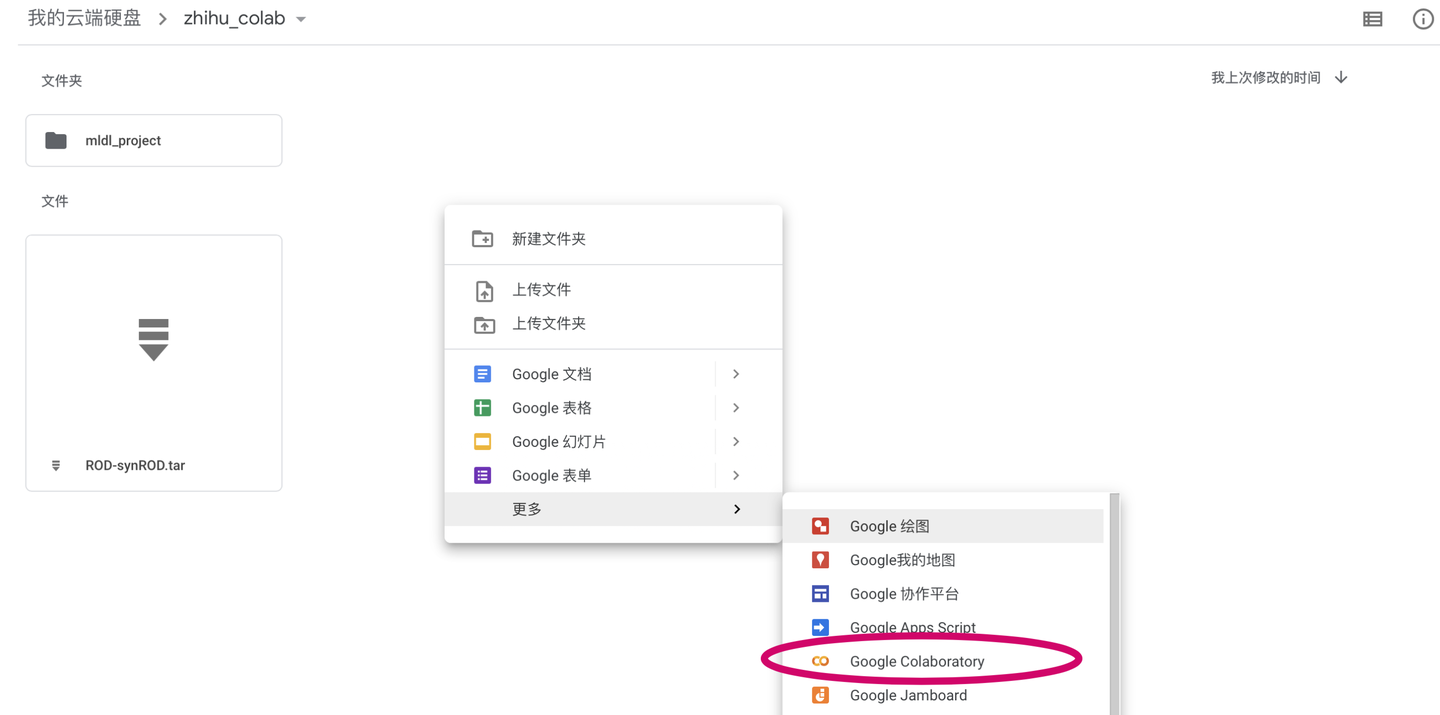
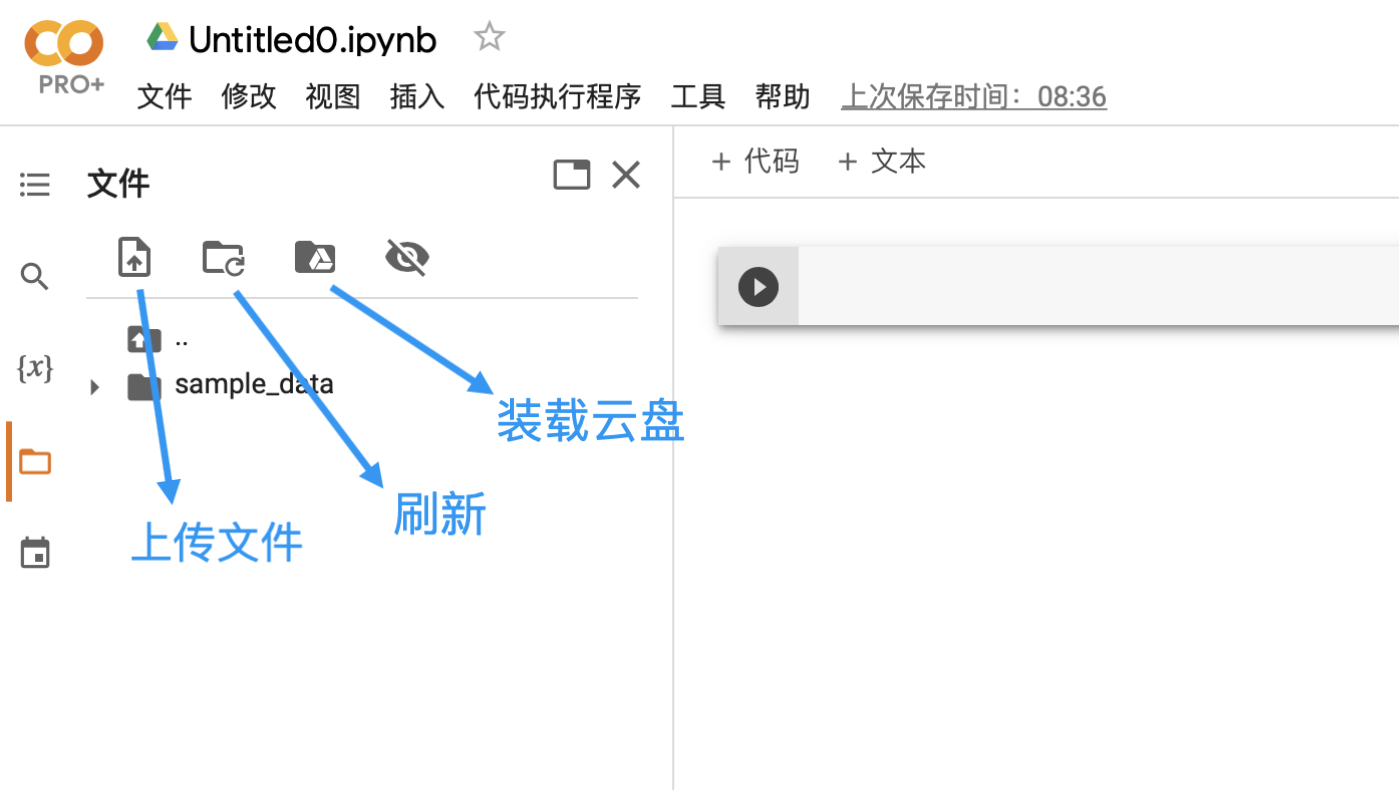
新建笔记本
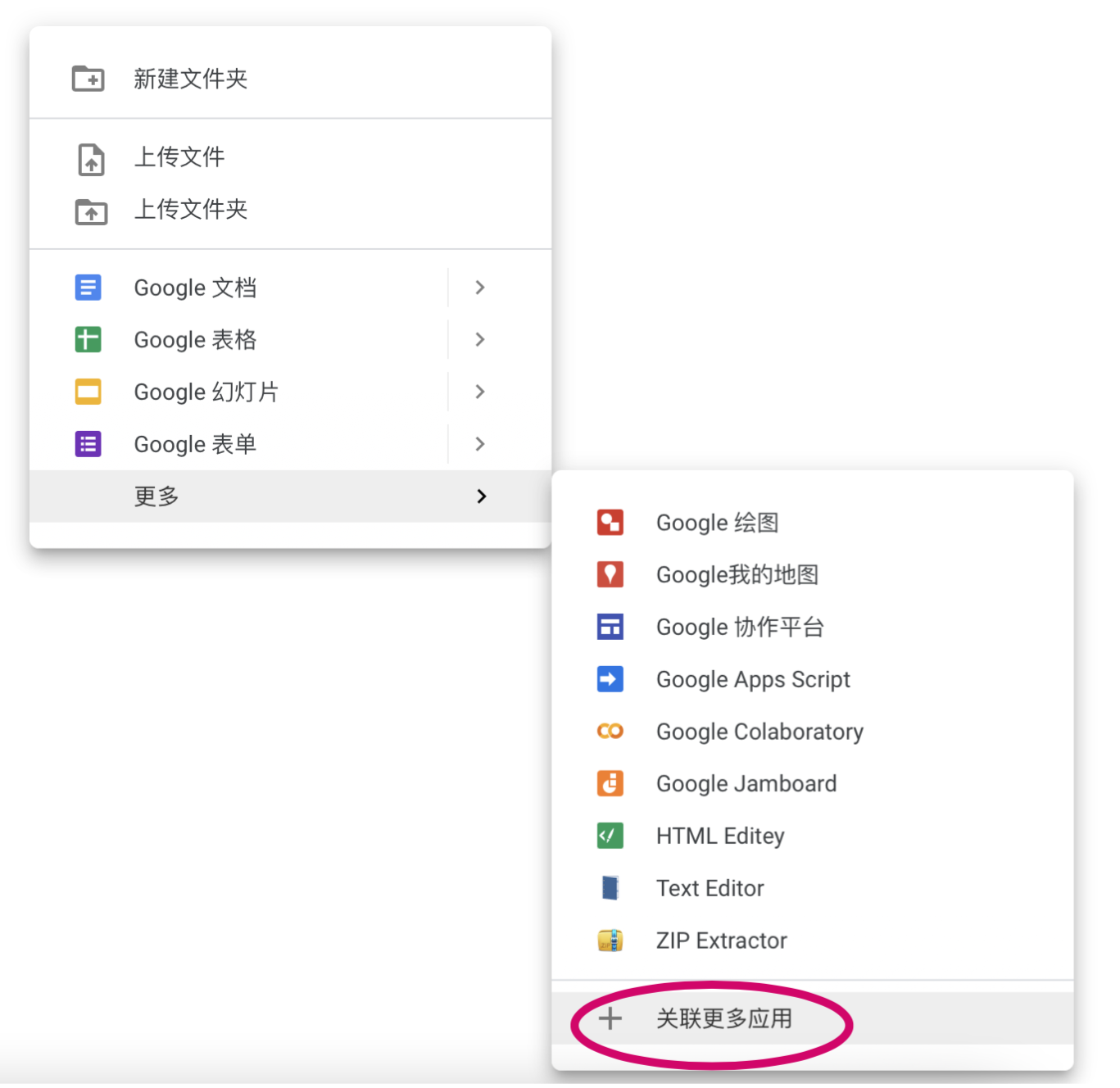
载入笔记本
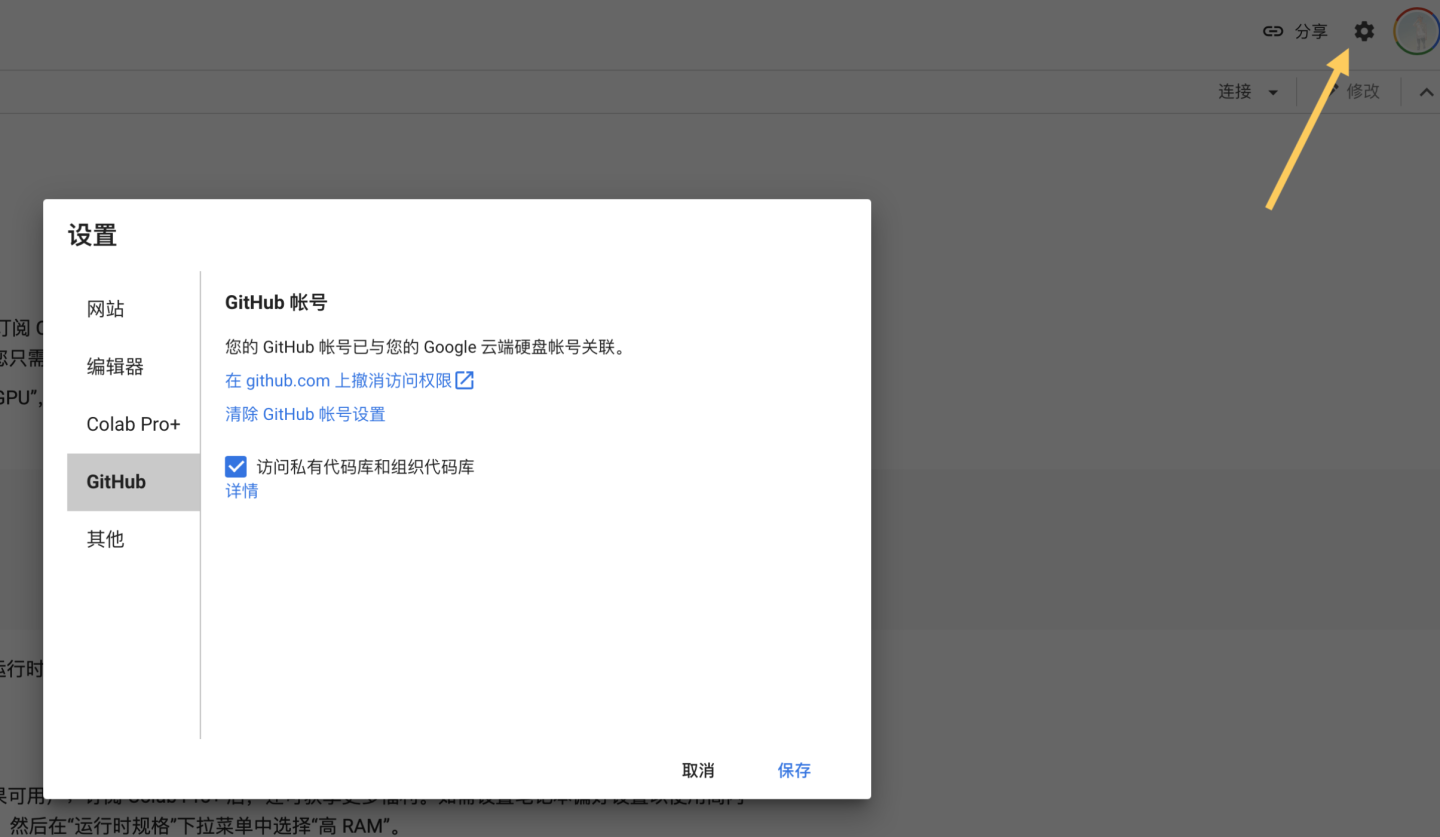
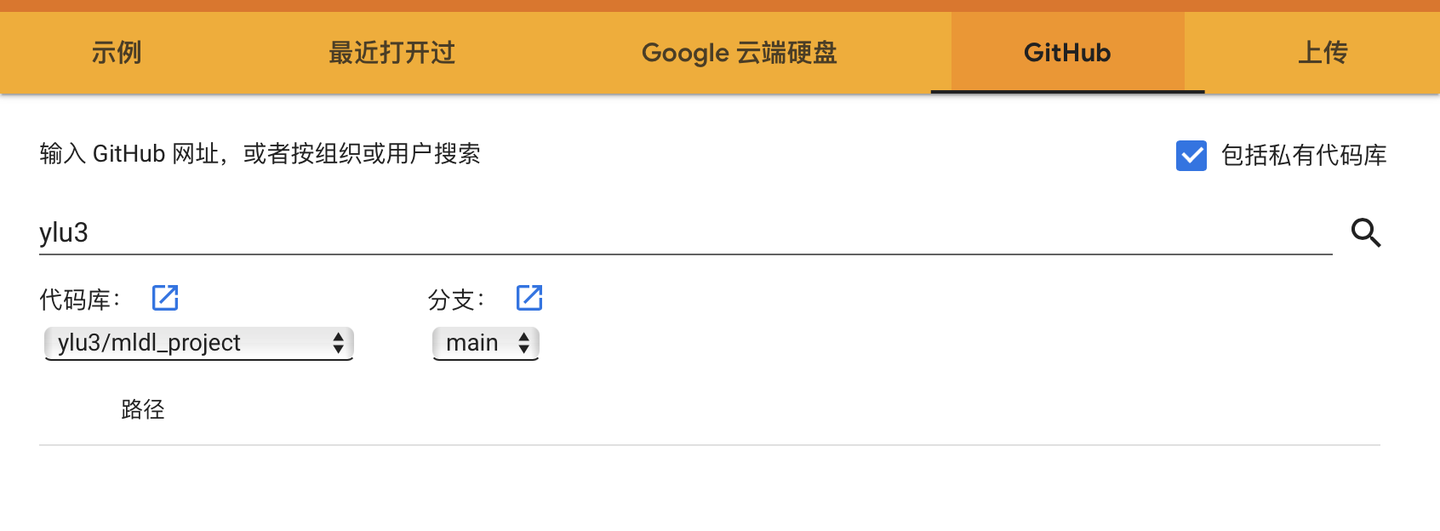
笔记本界面
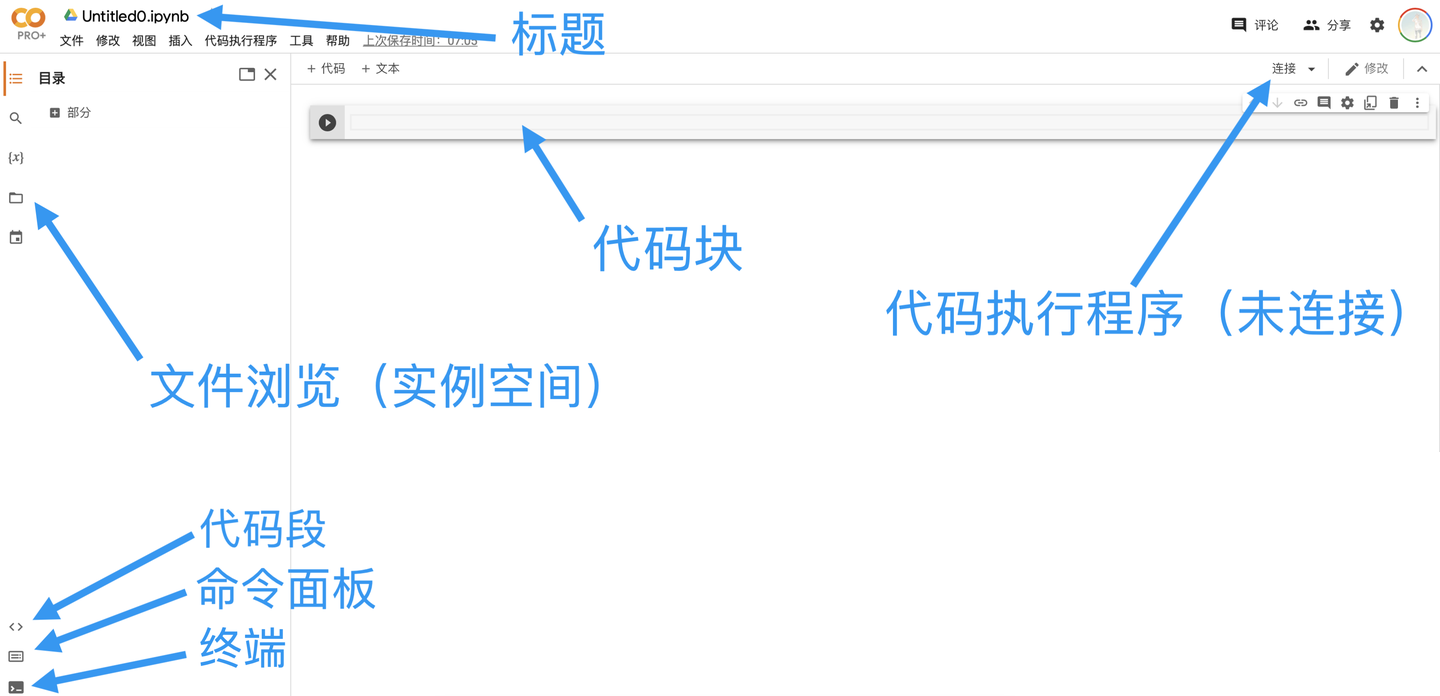
连接代码执行程序
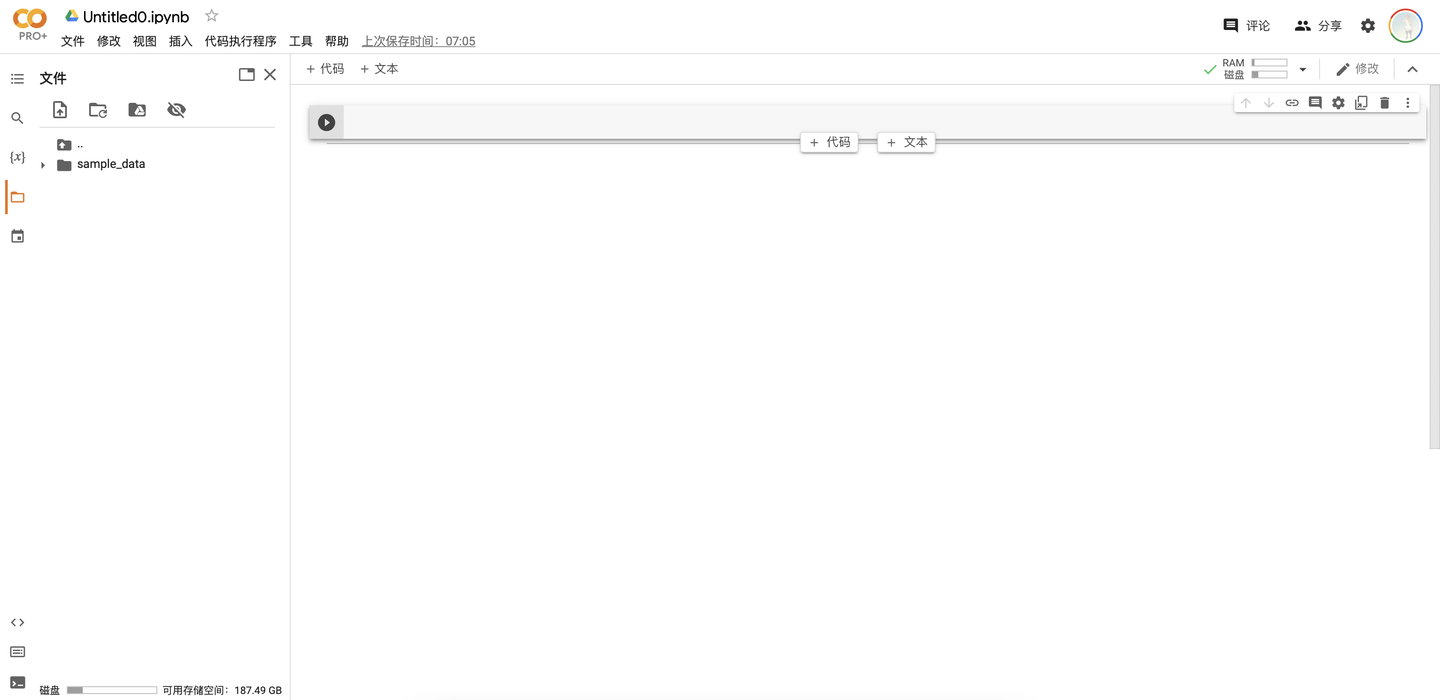
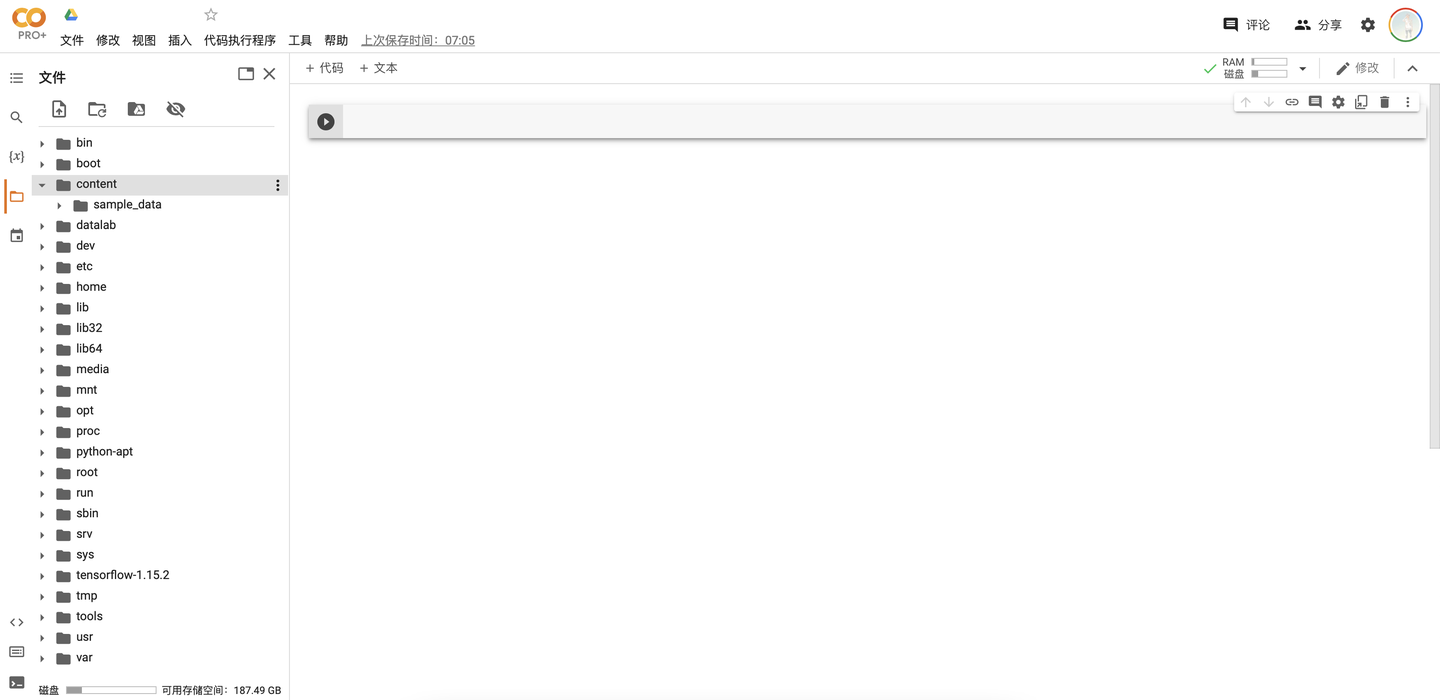
执行代码块
# 加载云端硬盘
from google.colab import drive
drive.mount('/content/drive') # 查看分配到的GPU
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Not connected to a GPU')
else:
print(gpu_info) # 安装python包
!pip3 install <package>
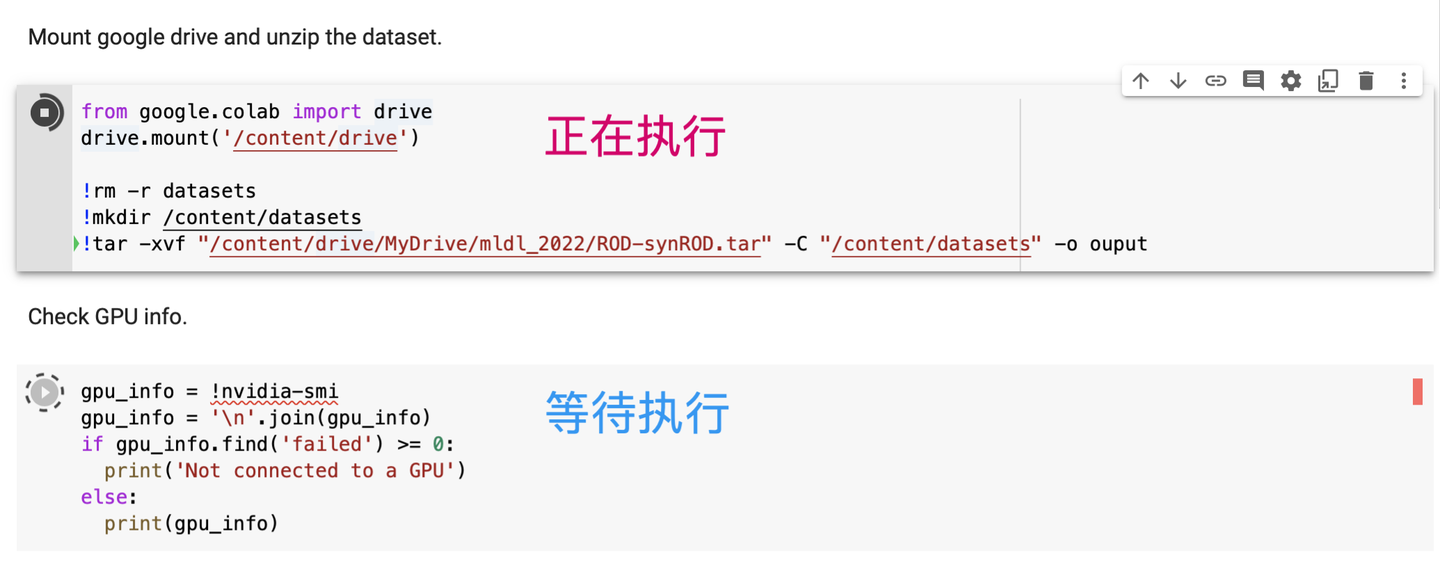
设置笔记本的运行时类型
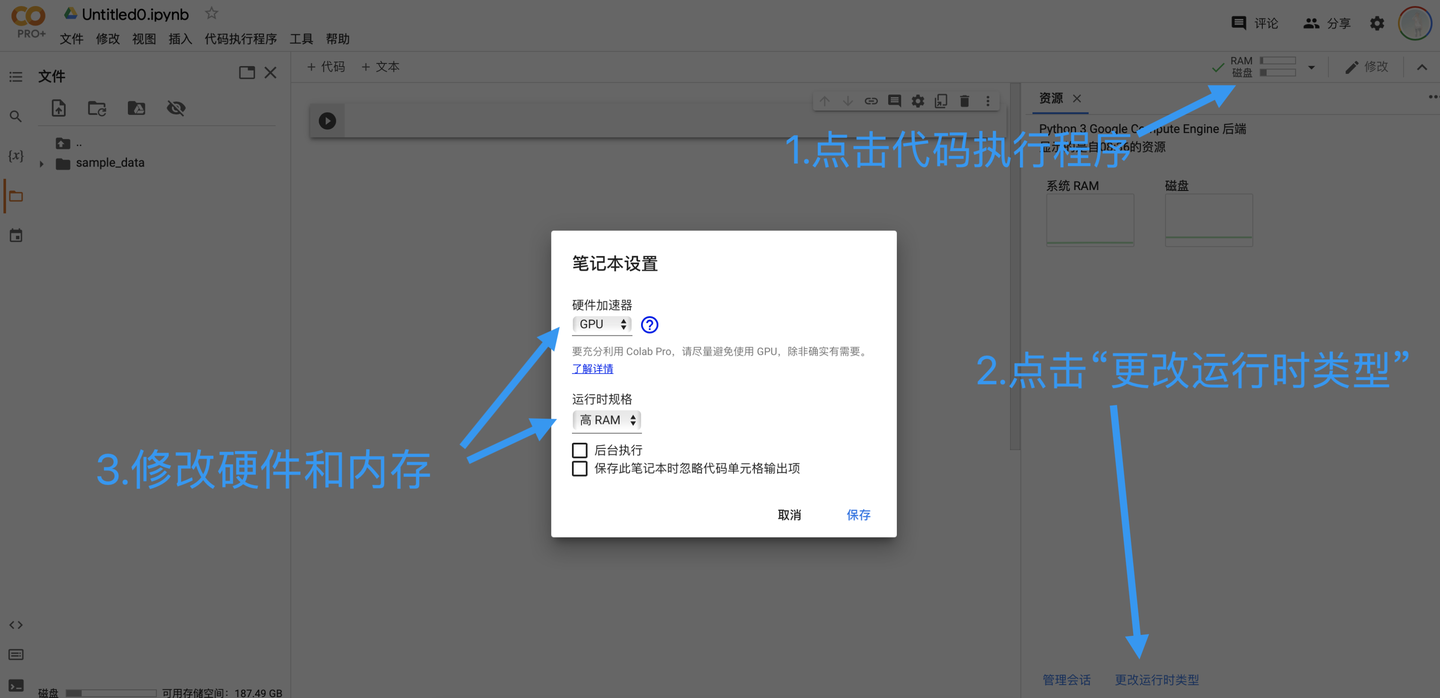
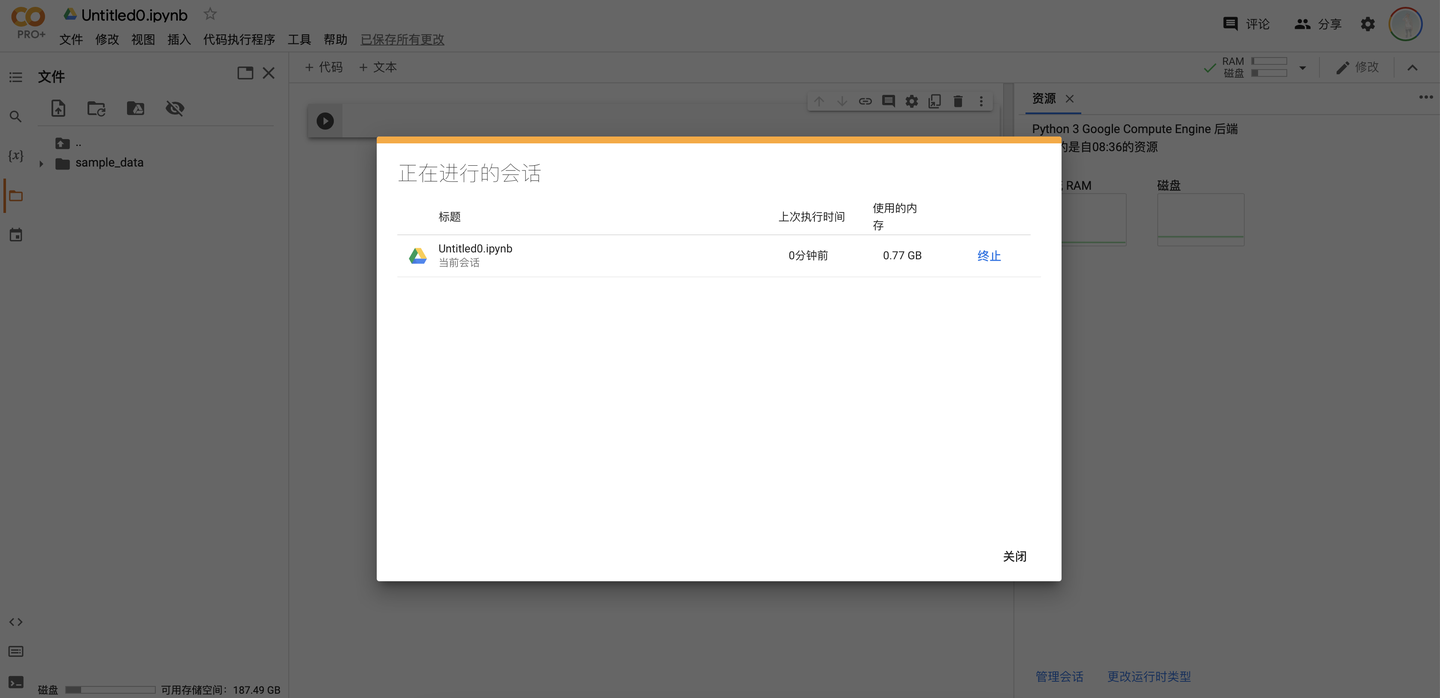
管理会话Session
三、Colab重要特性
资源使用的限制




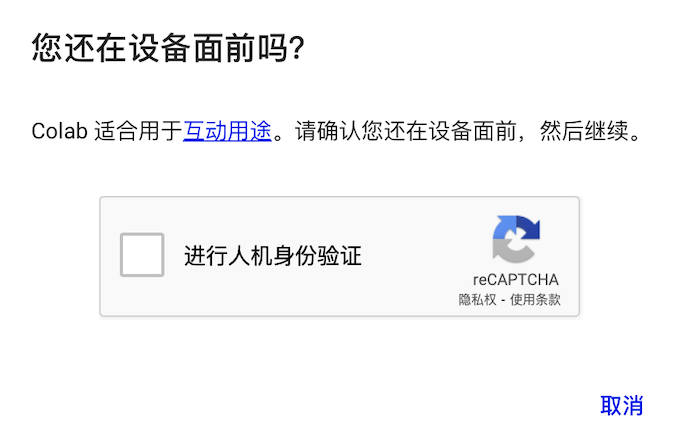
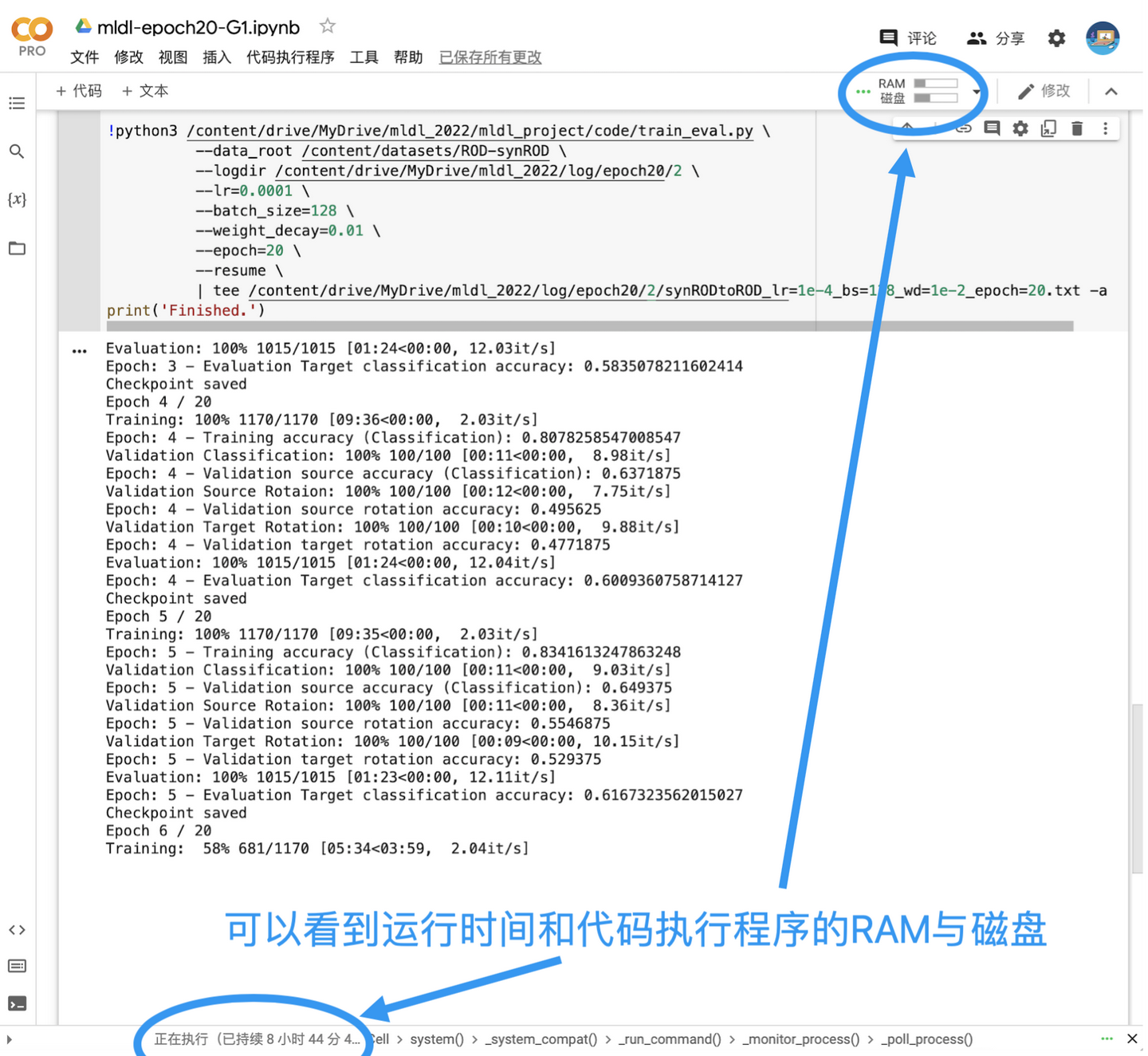
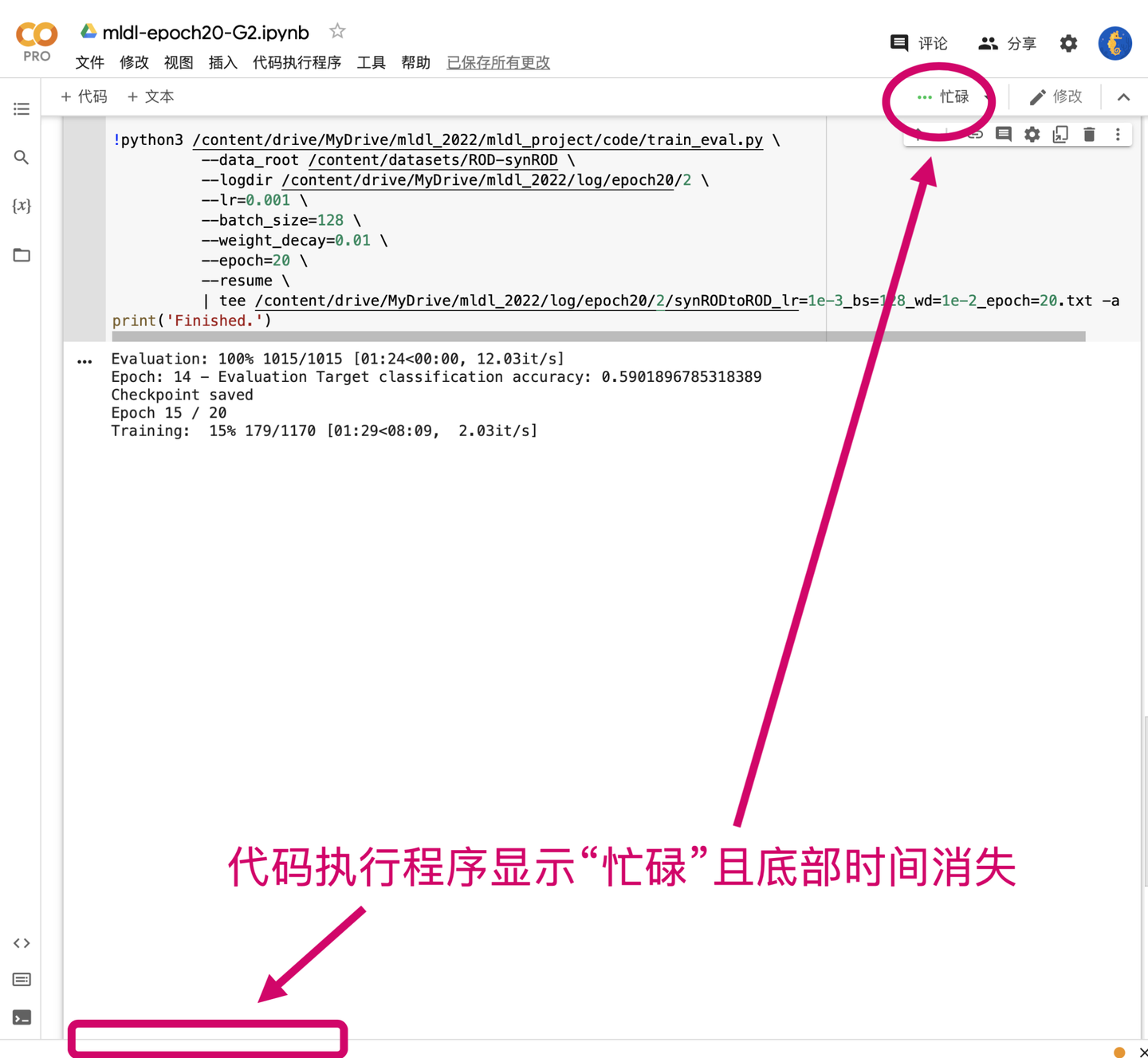
如何合理使用资源?
- 将训练过后的模型日志和其他重要的文件保存到谷歌云盘,而不是本地的实例空间
- 运行的代码必须支持“断点续传”能力,简单来说就是必须定义类似checkpoint功能的函数;假设我们一共需要训练40个epochs,在第30个epoch掉线了之后模型能够从第30个epoch开始训练而不是从头再来
- 仅在模型训练时开启GPU模式,在构建模型或其他非必要情况下使用None模式
- 在网络稳定的情况下开始训练,每隔一段时间查看一下训练的情况
- 注册多个免费的谷歌账号交替使用
四、Colab项目组织
加载数据集
运行Github项目
# 克隆仓库到/content/my-repo目录下
!git clone https://github.com/my-github-username/my-git-repo.git %cd my-git-repo !./train.py --logdir /my/log/path --data_root /my/data/root --resume
from train import my_training_method
my_training_method(arg1, arg2, ...)
import sys
sys.path.append('/content/my-git-repo') # 把git仓库的目录添加到系统目录
如何处理简单项目?
五、实例演示
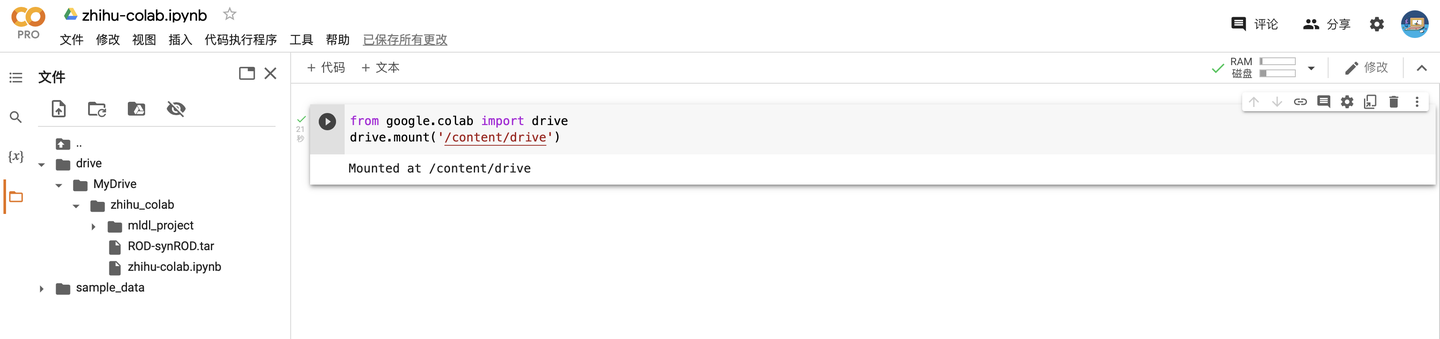
from google.colab import drive
drive.mount('/content/drive')
!mkdir /content/datasets !tar -xvf "/content/drive/MyDrive/zhihu_colab/ROD-synROD.tar" -C "/content/datasets"
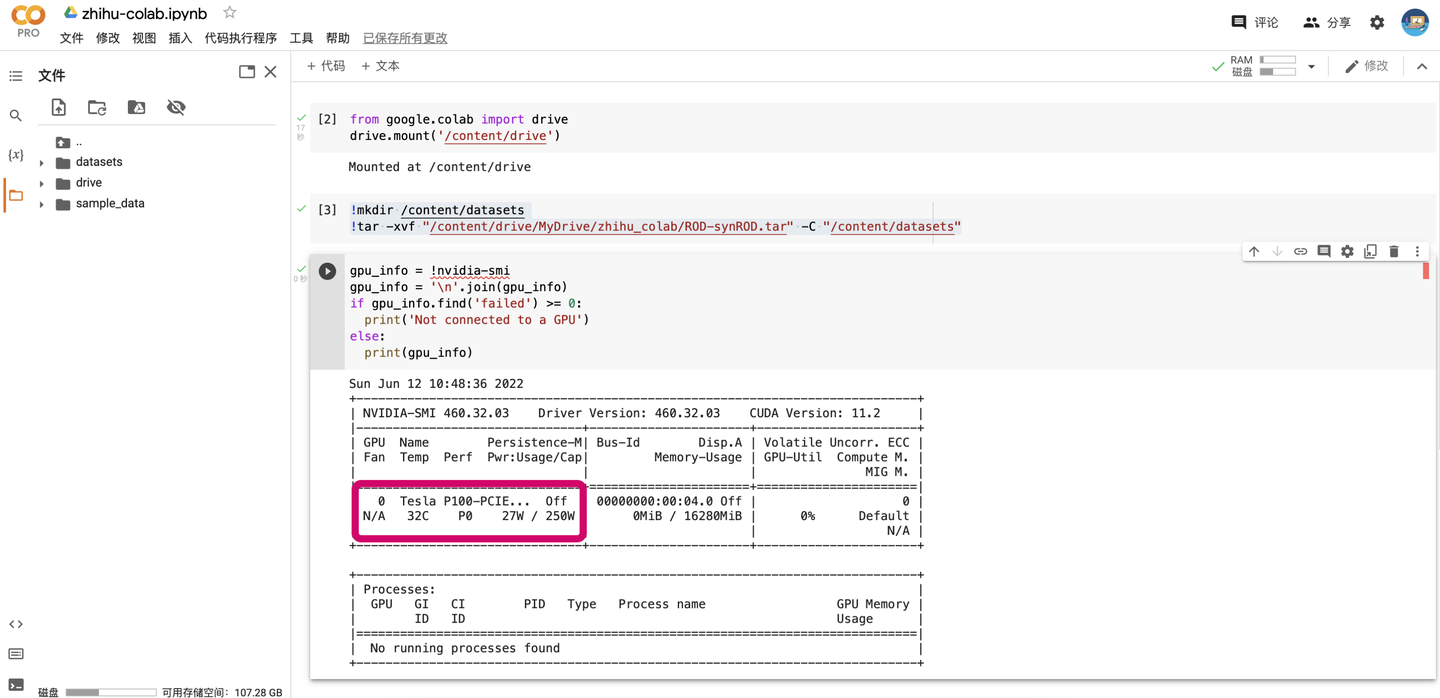
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Not connected to a GPU')
else:
print(gpu_info)
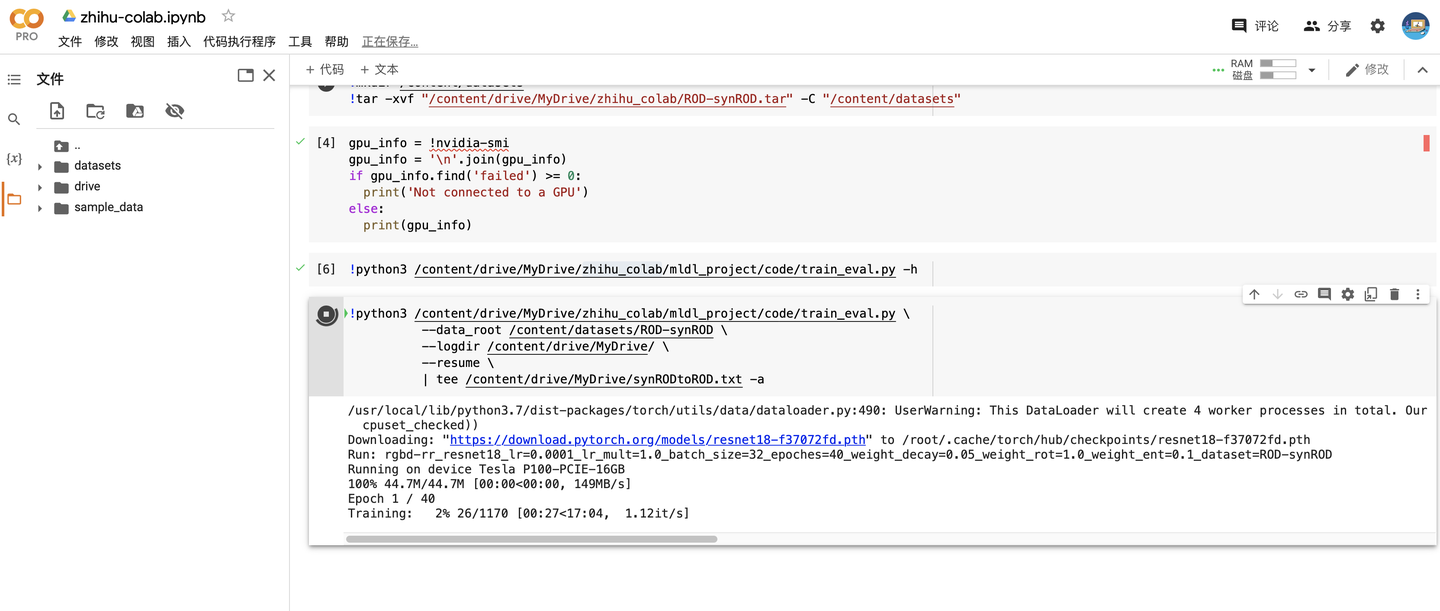
!python3 /content/drive/MyDrive/zhihu_colab/mldl_project/code/train_eval.py \
--data_root /content/datasets/ROD-synROD \
--logdir /content/drive/MyDrive/ \ --
resume \
| tee /content/drive/MyDrive/synRODtoROD.txt -a
六、Colab Pro / Pro+
RAM-磁盘
|
高RAM
|
磁盘
|
后台运行
|
|
|---|---|---|---|
|
免费
|
|
66GB?
|
|
|
Pro
|
25GB
|
166GB
|
|
|
Pro+
|
52GB
|
225GB
|
|
GPU模式下会话数量
|
标准RAM
|
高RAM
|
后台运行
|
|
|---|---|---|---|
|
免费
|
1
|
|
|
|
Pro
|
2
|
1
|
|
|
Pro+
|
3
|
3
|
2(无论是否高RAM)
|
使用Pro/Pro+的个人感受

七、补充内容
如何让代码有“断点续传”的能力?
def save_checkpoint(path: Text,
epoch: int,
modules: Union[nn.Module, Sequence[nn.Module]],
optimizers: Union[opt.Optimizer, Sequence[opt.Optimizer]],
safe_replacement: bool = True):
"""
Save a checkpoint of the current state of the training, so it can be resumed.
This checkpointing function assumes that there are no learning rate schedulers or gradient scalers for automatic
mixed precision.
:param path:
Path for your checkpoint file
:param epoch:
Current (completed) epoch
:param modules:
nn.Module containing the model or a list of nn.Module objects
:param optimizers:
Optimizer or list of optimizers
:param safe_replacement:
Keep old checkpoint until the new one has been completed
:return:
""" # This function can be called both as
# save_checkpoint('/my/checkpoint/path.pth', my_epoch, my_module, my_opt)
# or
# save_checkpoint('/my/checkpoint/path.pth', my_epoch, [my_module1, my_module2], [my_opt1, my_opt2])
if isinstance(modules, nn.Module):
modules = [modules]
if isinstance(optimizers, opt.Optimizer):
optimizers = [optimizers] # Data dictionary to be saved
data = {
'epoch': epoch,
# Current time (UNIX timestamp)
'time': time.time(),
# State dict for all the modules
'modules': [m.state_dict() for m in modules],
# State dict for all the optimizers
'optimizers': [o.state_dict() for o in optimizers]
} # Safe replacement of old checkpoint
temp_file = None
if os.path.exists(path) and safe_replacement:
# There's an old checkpoint. Rename it!
temp_file = path + '.old'
os.rename(path, temp_file) # Save the new checkpoint
with open(path, 'wb') as fp:
torch.save(data, fp)
# Flush and sync the FS
fp.flush()
os.fsync(fp.fileno()) # Remove the old checkpoint
if temp_file is not None:
os.unlink(path + '.old') def load_checkpoint(path: Text,
default_epoch: int,
modules: Union[nn.Module, Sequence[nn.Module]],
optimizers: Union[opt.Optimizer, Sequence[opt.Optimizer]],
verbose: bool = True):
"""
Try to load a checkpoint to resume the training.
:param path:
Path for your checkpoint file
:param default_epoch:
Initial value for "epoch" (in case there are not snapshots)
:param modules:
nn.Module containing the model or a list of nn.Module objects. They are assumed to stay on the same device
:param optimizers:
Optimizer or list of optimizers
:param verbose:
Verbose mode
:return:
Next epoch
"""
if isinstance(modules, nn.Module):
modules = [modules]
if isinstance(optimizers, opt.Optimizer):
optimizers = [optimizers] # If there's a checkpoint
if os.path.exists(path):
# Load data
data = torch.load(path, map_location=next(modules[0].parameters()).device) # Inform the user that we are loading the checkpoint
if verbose:
print(f"Loaded checkpoint saved at {datetime.fromtimestamp(data['time']).strftime('%Y-%m-%d %H:%M:%S')}. "
f"Resuming from epoch {data['epoch']}") # Load state for all the modules
for i, m in enumerate(modules):
modules[i].load_state_dict(data['modules'][i]) # Load state for all the optimizers
for i, o in enumerate(optimizers):
optimizers[i].load_state_dict(data['optimizers'][i]) # Next epoch
return data['epoch'] + 1
else:
return default_epoch
在主程序train.py正式开始训练前,添加下面的语句:
if args.resume: # args.resume是命令行输入的参数,用于指示要不要加载上次训练的结果
first_epoch = load_checkpoint(checkpoint_path, first_epoch, net_list, optims_list)
# Save checkpoint
save_checkpoint(checkpoint_path, epoch, net_list, optims_list)
如果分到了Tesla T4怎么办?
结语:一不留神写了一万多字了!希望这个超详细的Colab教程能对大家有所帮助,大家要是发现了什么新的技巧欢迎在评论区留言~
Colab教程(超级详细版)及Colab Pro/Colab Pro+使用评测的更多相关文章
- 手把手Maven搭建SpringMVC+Spring+MyBatis框架(超级详细版)
手把手Maven搭建SpringMVC+Spring+MyBatis框架(超级详细版) SSM(Spring+SpringMVC+Mybatis),目前较为主流的企业级架构方案.标准的MVC设计模式, ...
- CentOS 6.4 服务器版安装教程(超级详细图解)
附:CentOS 6.4下载地址 32位:http://mirror.centos.org/centos/6.4/isos/i386/CentOS-6.4-i386-bin-DVD1to2.torre ...
- caffe学习--使用caffe中的imagenet对自己的图片进行分类训练(超级详细版) -----linux
http://blog.csdn.net/u011244794/article/details/51565786 标签: caffeimagenet 2016-06-02 12:57 9385人阅读 ...
- VMware Workstation 12 Pro安装CentOs图文教程(超级详细)
本文记录了VMware Workstation 12 Pro安装CentOs的整个过程,具体如下: VMware Workstation 12: CENTOS 6.4 : 创建虚拟机 1.首先安装好V ...
- CentOS 服务器版安装教程(超级详细图解)
使用安装说明:http://www.jb51.net/os/85895.html
- Navicate12激活教程(完整详细版)
写在前面 最近身边的小伙伴苦于没有Navicat12的激活工具,不能使用最新版的Navicat,鉴于此,遂将自己整理的文章贴出来,供大家参考,不过个人还是主张维护正版的意愿,如果经济实力允许的话,还是 ...
- Windows 10 + kali Linux 双系统安装教程(详细版)
准备工具如下: kali Linux 镜像 准备一4G以上的U盘 制作U盘启动盘工具- Win32DiskImager 添加引导工具-EasyBCD 留出一个空的盘,哪个盘的空间比较大可以压缩出大概2 ...
- hexo+github搭建博客(超级详细版,精细入微)
# 前言 你了解[Hexo]( https://hexo.io/zh-cn/ "Hexo官网")吗? Hexo是一个静态博客框架,基于Node.js,将Markdown文章通过渲染 ...
- cnpm的安装(超级详细版)
1. 安装node 打开黑窗口 安装node 网上教程很多,我就不加上了 2.node -v 查看node是否已安装 3.安装淘宝镜像 npm install -g cnpm -registry ...
随机推荐
- Python知识结构
Python知识结构(点我) 欢迎评论提修改意见
- python——如何import包目录
文件位置 文件所在位置包括 , 源根目录的位置 该文件位置(也可以叫相对位置). 导入包的时候会从文件位置进行查找,并导入. 导入包 1. 什么是包? pycharm中包的图片 其中文件夹上有个圆点的 ...
- linux find命令 -mtime参数 根据修改时间查找文件
命令:find 搜索路径 -mtime n 主要说明n的含义: 例: n=5 "5"指的是前 5~6 天那一天修改的文件 n=-5 "-5"指的是 5 天内修改 ...
- LAN交换机自学习算法
LAN交换机自学习算法 提示 第二层交完全忽略帧的数据部分协议,仅根据第二层以太网的MAC地址做出转发决策. MAC地址表有时又被称作内容可编址内存(CAM)表 检查源MAC地址 如果源MAC地址不存 ...
- Unity—TextMeshPro
矢量文字,不会因为放大缩小而变的不清晰: 1.TextAsset Window/TextMeshPro/Font Assets Creator 创建TextAsset字体: SourceFont是.t ...
- 【ACM程序设计】差分
差分 假设有一个数列,我们需要对数列中的一个区间加上或减去一个值,直接想到的便是对该区间进行一次循环逐项加减. 但是当请求的操作变得非常多的时候,每次请求都进行一次循环会很容易爆时间,因此我们引入了差 ...
- 服务器BIOS和BMC等知识详解
一个执着于技术的公众号 引言:以BIOS为核心的固件产业,是信创产业链的重要组成部分,可被誉为信创产业的"山海关".在计算机体系中,BIOS 有着比操作系统更为底层和基础性的作用, ...
- 论文解读(SAGPool)《Self-Attention Graph Pooling》
论文信息 论文标题:Self-Attention Graph Pooling论文作者:Junhyun Lee, Inyeop Lee, Jaewoo Kang论文来源:2019, ICML论文地址:d ...
- Hive 3.x 配置&详解
Hive 1. 数据仓库概述 1.1 基本概念 数据仓库(英语:Data Warehouse,简称数仓.DW),是一个用于存储.分析.报告的数据系统. 数据仓库的目的是构建面向分析的集成化数据环境,分 ...
- C# 编写一个简单易用的 Windows 截屏增强工具
半年前我开源了 DreamScene2 一个小而快并且功能强大的 Windows 动态桌面软件.有很多的人喜欢,这使我有了继续做开源的信心.这是我的第二个开源作品 ScreenshotEx 一个简单易 ...