ML-决策树
信息增益
- 香农熵: 指混乱程度,越混乱,值越大
- 信息增益(information gain): 在划分数据集前后信息发生的变化称为信息增益(香农熵的差)
基尼不纯度也可度量集合的无序程度
香农熵的计算公式如下:
\]
- xi是目标变量的某个取值,
- H是一个数学期望
- 因为p(xi)<1,所以最后结果是正数
def calcShannonEnt(dataSet):
"""计算香农熵"""
labelCounts={}
numEntries = len(dataSet) # 数据集的总数,用于计算比例P
# 1. 计算出每个label对应的数量
for line in dataSet:
label = line[-1]
if label not in labelCounts.keys():
labelCounts[label] = 0
labelCounts[label] += 1
# 2. 使用labelCounts计算prob和H
shannonEnt = 0.0 # 熵的初值
for label, count in labelCounts.items():
prob = float(count) / numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt
找到最好的划分方式
划分数据集
splitDataSet(dataSet,0,1) 表示先选出满足条件"第0个标签的值等于0"的数据,再把数据中的第0个标签剔除掉。
>>> dataSet
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
>>> splitDataSet(dataSet, 0, 1)
[[1, 'yes'], [1, 'yes'], [0, 'no']]
>>> splitDataSet(dataSet, 0, 0)
[[1, 'no'], [1, 'no']]
def splitDataSet(dataSet, axis, value):
"""划分数据集。python使用引用传递列表,因此创建一个新的结果列表"""
returnDataSet = []
for line in dataSet:
if line[axis] == value:
newline = line[:axis]
newline.extend(line[axis+1:])
returnDataSet.append(newline)
return returnDataSet
数据必须满足两点要求:
- 数据集必须是列表的列表,且每条数据长度相同
- 数据的最后一列是分类结果
寻找最好的特征进行分类
对每个特征进行划分,找到划分后,信息增益最大的特征
- 需要遍历所有特征,计算每次的信息增益
- 特征i可能有很多取值,会产生很多分支,对每个分支计算香农熵。最后的熵取所有分支熵的数学期望。
- 信息增益=原始熵-按特征i划分后各个分支熵的数学期望
def chooseBestFeatureToSplit(dataSet):
"""寻找最好的分类特征==> 寻找分类后,信息增益最大的特征"""
numberOfFeature = len(dataSet[0]) -1 # 最后一位不要,因为他是分类结果
numberOfDataSet = len(dataSet)
baseEntropy = calcShannonEnt(dataSet) # 原始香农熵
bestInfoGain = 0.0 # 用于记录最大信息熵
bestFeature = -1 # 用于记录最大信息熵对应的特征下标
# 对每个特征进行划分,找到划分后,信息增益最大的特征
for i in range(numberOfFeature):
# 1. 找到该特征的所有可能取值,去重
values = [example[i] for example in dataSet]
uniqueValue = set(values)
# 2. 计算香农熵。需要对于每一个取值计算一次。香农熵本身就类似一个数学期望(这一部分可以封装成一个香农熵函数)
newShannonEnt = 0.0
for value in uniqueValue:
splitedDataSet = splitDataSet(dataSet, i, value)
prob = float(len(splitedDataSet)) / numberOfDataSet
newShannonEnt += prob * calcShannonEnt(splitedDataSet)
# 3. 寻找最大信息增益
infoGain = baseEntropy - newShannonEnt
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
# 寻找最大的数学期望,返回该特征
return bestFeature
构建决策树
递归创建决策树,递归终止的条件有两个:
- 遍历完所有划分数据集的属性(每次划分会消耗一个属性,属性已经用完)
- 该分支下所有实例都是相同的分类
def createTree(dataSet, labels):
"""创建决策树。labels 是对每个特征值的含义的解释,方便建立决策树"""
# 递归终止条件
classList = [example[-1] for example in dataSet]
# (1)属性已经用完
if len(dataSet[0]) == 1:
majorithCnt(classList)
# (2)所有分类已经一致
if classList.count(classList[0]) == len(classList):
return classList[0]
# 1. 寻找最优特征
bestFeature = chooseBestFeatureToSplit(dataSet)
bestFeatureLabel = labels[bestFeature] # 只是标签,用于建树
mytree = {bestFeatureLabel: {}} # 初始化树
subLabels = labels[:] # 复制该列表,因为labels是引用。避免值被改变
del subLabels[bestFeature] # subLabels
# 2. 当前最优特征的所有取值,去重
totalValues = [example[bestFeature] for example in dataSet]
uniqueValues = set(totalValues)
# 3. 每个value一个分支,确定每个分支的值。因为是递归,所以分支下可能还有分支(字典里可能嵌套字典),如果该分支已经可以结束,则返回返回classList中的一个(分类结果)
for value in uniqueValues:
subDataSet = splitDataSet(dataSet, bestFeature, value)
mytree[bestFeatureLabel][value] = createTree(subDataSet, subLabels)
return mytree
使用决策树分类
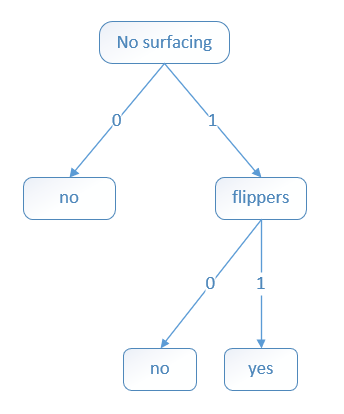
这部分很简单,将数据集按照树的结构从上往下查找即可。数据集如下:
| no surfacing | flippers | fish(目标变量) |
|---|---|---|
| 1 | 1 | yes |
| 1 | 1 | yes |
| 1 | 0 | no |
| 0 | 1 | no |
| 0 | 1 | no |
将构建的决策树用图形表示:
def classify(inputTree, featureLabels, testVec):
"""
:param inputTree: 构建好的决策树
:param featureLabels: 标签列表,也就是每个分类的属性名
:param testVec: 测试数据
"""
firstStr = list(inputTree.keys())[0] # 其实根元素只有一个
secondDict = inputTree[firstStr] # 第二层
featureIndex = featureLabels.index(firstStr) # 当前属性的下标
for key in secondDict.keys():
if testVec[featureIndex] == key:
if type(secondDict[key]).__name__ == "dict":
classLabel = classify(secondDict[key], featureLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
保存决策树
将决策树保存到文件中。python使用pickle模块序列化对象
pickle.dump(obj, file): 将obj写入到file中。file=open(filename,"bw")pickle.load(file): 读取file中的内容,转换为obj。file=open(filename, "rb")
def storeTree(inputTree, fileName):
import pickle
with open(fileName, "wb") as file:
pickle.dump(inputTree, file)
def grabTree(fileName):
import pickle
with open(fileName, "rb") as file:
return pickle.load(file)
案例:预测隐形眼镜类型
准备训练数据集。该数据集有5项,4个特征变量和一个目标变量。 各个属性名分别是:
['age', 'prescript', 'astigmatic', 'tearRate']
部分数据集:
young myope no reduced no lenses
young myope no normal soft
young myope yes reduced no lenses
young myope yes normal hard
young hyper no reduced no lenses
young hyper no normal soft
young hyper yes reduced no lenses
......
- 收集数据:保存数据的文本文件
- 准备数据:解析文本文件,将文件读入内存。数据包括:(1)符合规范的数据集(dataSet),(2) 数据集的属性名称列表(labels)
- 分析数据:检查数据(我也不知道咋检查)
- 训练算法:使用
createTree(dataSet, labels)生成决策树myTree - 测试算法:编写函数验证决策树
classify(myTree, labels, testVec) - 使用算法:保存决策树以供下次使用(KNN就无法做到)
- 数据集必须是二维列表 & 每条数据长度一致 & 最后一列是分类结果(当然也可以不这么做,一般都是X,y)
- labels 必须与dataSet配套,labels保存了每个属性的属性名,用于建立易于理解的决策树。在这个案例中就是:['age', 'prescript', 'astigmatic', 'tearRate']
- classify(inputTree, labels, testVec) 训练好决策树后,就可以使用classify函数分类
简而言之:
- 准备
dataSet和labels,通过createTree(dataSet, labels)==>mytree - 准备测试数据
test,通过classify(myTree, labels, testVec)==> 结果
def lense():
with open("dataset/lenses.txt") as file:
fileContent = file.readlines()
dataSet = [example.strip().split("\t") for example in fileContent]
labels = ['age', 'prescript', 'astigmatic', 'tearRate']
myTree = createTree(dataSet, labels)
print("计算出的决策树是:", myTree)
result = classify(myTree, labels, ['young', 'myope', 'no', 'reduced'])
print("预测的结果是:", result)
计算出的决策树:
{'tearRate': {'normal': {'astigmatic': {'no': {'age': {'presbyopic': {'prescript': {'hyper': 'soft', 'myope': 'no lenses'}}, 'young': 'soft', 'pre': 'soft'}}, 'yes': {'prescript': {'hyper': {'age': {'presbyopic': 'no lenses', 'young': 'hard', 'pre': 'no lenses'}}, 'myope': 'hard'}}}}, 'reduced': 'no lenses'}}
总结
- 完整的决策树远没有这么简单。该算法只能预测离散型的结果,无法预测连续型数据
- 书中选择特征使用的是信息增益算法(ID3),除此之外,还有信息增益比(C4.5算法)、基尼指数(CART算法)。好复杂,以后再学习吧
ML-决策树的更多相关文章
- ML——决策树模型
决策树模型 优点:高效简单.易于理解,可以处理不相关特征. 缺点:容易过拟合,训练集在特征上是完备的 决策树过程:特征选择.划分数据集.构建决策树.决策树剪枝 决策树选择最优的划分特征,将数据集按照最 ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- Spark2 ML包之决策树分类Decision tree classifier详细解说
所用数据源,请参考本人博客http://www.cnblogs.com/wwxbi/p/6063613.html 1.导入包 import org.apache.spark.sql.SparkSess ...
- ML(4): 决策树分类
决策树(Decision Tree)是用于分类和预测的主要技术,它着眼于从一组无规则的事例推理出决策树表示形式的分类规则,采用自顶向下的递归方式,在决策树的内部节点进行属性值的比较,并根据不同属性判断 ...
- ML二(决策树学习)
决策树学习 Decision Tree Learning 1 基本概念 属性(attribute):树上的每个结点说明了对实例的某个属性的测试,该结点的每一个后继分支对应该属性的一个可能值. 熵(en ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- Spark中决策树源码分析
1.Example 使用Spark MLlib中决策树分类器API,训练出一个决策树模型,使用Python开发. """ Decision Tree Classifica ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- Core ML 机器学习
在WWDC 2017开发者大会上,苹果宣布了一系列新的面向开发者的机器学习 API,包括面部识别的视觉 API.自然语言处理 API,这些 API 集成了苹果所谓的 Core ML 框架.Core M ...
- Spark ML源码分析之四 树
之前我们讲过,在Spark ML中所有的机器学习模型都是以参数作为划分的,树相关的参数定义在treeParams.scala这个文件中,这里构建一个关于树的体系结构.首先,以Decis ...
随机推荐
- Vue 3-150行代码实现新国标红绿灯效果案例
昨天刷视频,都是关于新国标红绿灯的,看大家议论纷纷,下班就用150行代码通过Vue组件实践红绿模拟演示,视频也跟大家展示过了.今天接着更新图文版本,大家跟着优雅哥通过该案例实操模拟一下. 不过新国标红 ...
- HBase集群部署与基础命令
HBase 集群部署 安装 hbase 之前需要先搭建好 hadoop 集群和 zookeeper 集群.hadoop 集群搭建可以参考:https://www.cnblogs.com/javammc ...
- KingbaseES V8R6集群外部备份案例
案例说明: 本案例采用sys_backup.sh执行物理备份,备份使用如下逻辑架构:集群采用CentOS 7系统,repo采用kylin V10 Server. 一主一备+外部备份 此场景为主备双机常 ...
- 运维利器-ClusterShell
前言 和ansible类似,但是更加高效 安装 yum install -y clustershell clush命令: clush -a 全部 等于 clush -g all clush -g 指定 ...
- Gitea 1.17.1 正式发布 | 08 累积更新
Gitea 1.17.1 已正式发布.在这个小的版本更新中我们合并了 35 个 PR,没有包含功能性的更改,但我们强烈建议用户升级到此版本以获得重要的修复补丁. 致谢:感谢报告问题的安全研究人员,同时 ...
- Markdown学习 .md学习
# Markdown学习## 标题## 二级标题### 三级标题#### 四级标题## 字体**两个*是粗体***一个是斜体****三个是斜体加粗***~~两个~是删除线~~## 引用>走向人生 ...
- ThreadLocal源码学习笔记
系列文章目录和关于我 一丶ThreadLocal结构 每一个Thread对象都有一个名为threadLocals类型为ThreadLocal.ThreadLocalMap的属性,ThreadLocal ...
- Mysql 安全加固经验总结
本文为博主原创,转载请注明出处: 目录 1.内网部署Mysql 2. 使用独立用户运行msyql 3.为不同业务创建不同的用户,并设置不同的密钥 4.指定mysql可访问用户ip和权限 5. 防sql ...
- 基于HBuilderX+UniApp+ThorUI的手机端前端开发处理
现在的很多程序应用,基本上都是需要多端覆盖,因此基于一个Web API的后端接口,来构建多端应用,如微信.H5.APP.WInForm.BS的Web管理端等都是常见的应用.本篇随笔概括性的介绍基于HB ...
- HCIA-STP原理与配置
STP协议生成树协议: 为了保证网络可靠,所以在组网时需要设置冗余链路和设备,从而在物理结构上形成结构,又因为交换机的工作特点导致二层网络中产生广播风暴和MAC地址表震荡现象,影响用户体验. 广播风暴 ...