NLP之基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention)
@
1.理论
1.1 机器翻译
1.1.1 模型输出结果处理
在解码过程之后,由输出结果获得预测单词y的方法有以下几种:
- 贪婪法(Greedy Search): 根据字面意思,就是经过softmax之后取argmax,这种方式是最简单的,但也存在着问题:局部最优不一定是全局最优
入门项目实验所选择的均为贪婪法
- 暴力搜索: 这只是一种理论上的方法,但它的复杂度是\(O(∣V∣^m)\),V是词库大小,显然是不可行的
- 束搜索(Beam Search): 结合了贪婪搜索和暴力搜索的特点,根据集束宽每次取概率最大的前k个,这样选取的最后结果是一棵树,我们只需要选取路径得分最大的即可。这种算法的复杂度虽然是指数级别的,但只要k不取太大,最后的复杂度可以控制在\(O(k^n)\)。
- 改进集束搜索:
- 长度归一化: 由于束搜索每次取k个值之后计算的概率会累积,所以长句的概率往往十分接近0造成数值下溢.因此我们实际中常常把概率记录成log(P),最大化log的求和公式
- 目标函数归一化: 原来的目标函数中长句的概率很低,因此比如偏向于简短结果,因此可以通过除以翻译结果的单词书了,进行归一化,减小对输出长句结果的惩罚
- 改进集束搜索:
1.1.2 BLEU得分
BLEU得分常用来衡量机器翻译结果的好坏
N-Gram:
假设所使用的词组颗粒度为n,则\(BLEU=\frac{\sum各个n元词组(去重)在参考句子中出现的最多次数}{n元词组总数(不去重)}\)
Example:
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
Machine Translate output: The cat cat the cat on the mat.
- 设n=1,翻译结果共有4个词组:"the"、"cat"、"on"、"mat".
- 其中,"the"在两个参考句分别出现了2次和1次,取2;
- "cat"、"on"、"mat"均最多出现1次,取1;
- 因此,结果为(2+1+1+1)/8=5/8
- 设n=2,翻译结果共有"the cat"、"cat the"、"cat on"、"on the"和"the mat"共5个词组.
- 其中,"the cat"、"cat on"、"on the"和"the mat"在两个句子在最多出现1次,取1;
- "cat the"没有出现,取0;
- 因此,结果为(1+1+1+1)/6=2/3 (注意,虽然在翻译结果中"the cat"有两个,算出现次数的时候只算一个,但是计算二元词组总数时,需要计算两次)
1.2 注意力模型
1.2.1 Attention模型
注意力机制(Attention Mechanism)的本质是对于给定目标,通过生成一个权重系数对输入进行加权求和,来识别输入中哪些特征对于目标是重要的,哪些特征是不重要的;
为了实现注意力机制,我们将输入的原始数据看作<Key,Value>键值对的形式,根据给定的任务目标中的查询值Query计算Key与Query之间的相似系数,可以得到Value值对应的权重系数,即注意力权重,之后再用权重系数对Value值进行加权求和,即可得到输出.我们使用Q,K,V分别表示Query,Key和Value.
注意力机制在深度学习各个领域都有很多的应用.不过需要注意的是,注意力并不是一个统一的模型,它只是一个机制,在不同的应用领域有不同的实现方法。
- 注意力权重系数W的公式如下:\(W=softmax(QK^T)\)
- 注意力权重系数W与Value做点积操作(加权求和)得到融合了注意力的输出:
\(Attention(Q,K,V)=W⋅V=softmax(QK^T)⋅V\)
注意力模型的详细结构如下图所示:
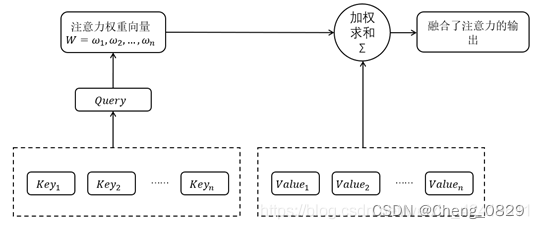
在本实验中Query是指decoder_output, Key和Value都是指encoder_outputs, 注意力权重W是指attn_weights
- 在对decoder时间步的遍历循环中,用dot点积得到每个时间步decoder_output_one和encoder_outputs之间的注意力权重,最后生成注意力权重列表trained_attn
- 把每一个decoder时间步生成的注意力权重attn_weights和encoder_outpus用bmm()函数进行加权求和,得到融合了注意力的输出context
- 当然,在Seq2Seq任务中,求出的context还需要和decoder_output进行combine和fc
传统机器翻译和加了注意力机制之后的机器翻译的BLEU得分对比: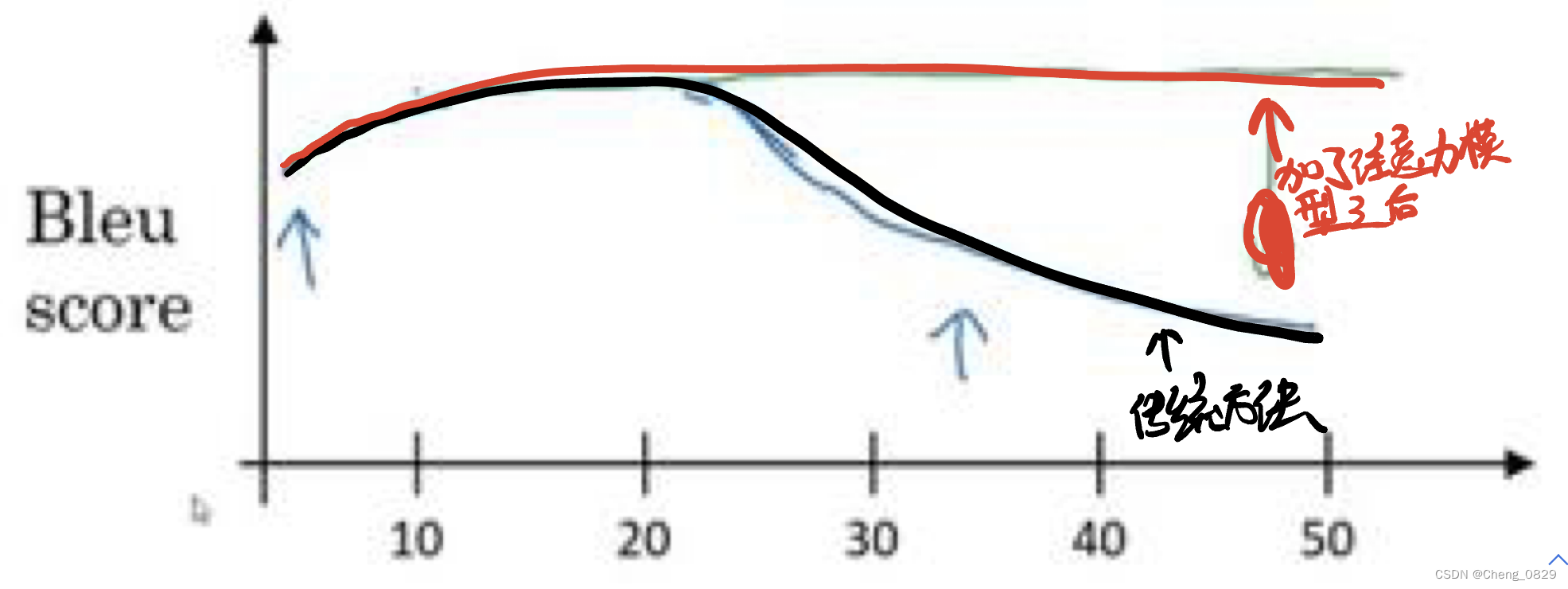
1.2.2 Seq2Seq(Attention)模型结构
在添加了注意力模型前后,编码器结构并没有什么变化;但是,在解码器中,传统的解码器结构发生了很大改变.
1.2.2.1 Encoder
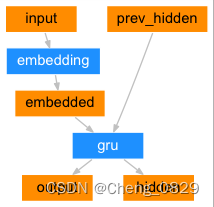
1.2.2.2 Decoder
1.2.2.2.1 原始解码器
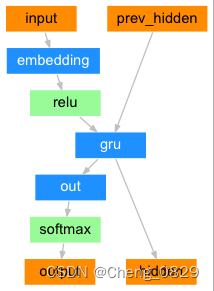
1.2.2.2.2 带有注意力机制的解码器

1.3 特殊字符
在序列模型的处理中,我们往往会在解码器的输入添加开始符\(S\),在输出添加结束符\(E\),同时用空白符\(P\)把所有词/句填充至相同长度
空白符: 填充至等长,便于统一操作;
开始符: 添加开始符是因为解码器Decoder的第一个时间步没有来自上一个解码器时间步的输入(虽然Decoder的第一个时间步有编码器Encoder的输出作为输入,但并不是来自解码器Decoder的),为了各个时间步处理的统一性,选择了一个可学习的特殊字符进行填充,这样的效果比单纯的空白字符更好;
结束符: 添加结束符是为了在预测单词时告诉模型终止输出.在训练集数据很多时,句子显然不可能都是等长的,翻译结果也应该不等长,为了控制翻译结果的长度,我们会在训练数据的target末尾加入结束符,这样翻译短句时,模型看见了结束符也就不会继续翻译了.(当然也可以不设置终止符,而设置一个最大输出长度,超过长度自动结束翻译输出)
开始符和结束符在训练时都被当做普通的一个单词或者字符进行训练,而他们的位置是固定的,开始符\(S\)只出现在解码器的输入,结束符\(E\)只出现在解码器的输出.当预测时,我们只在编码器Encoder中有输入,而解码器Decoder的输入就是'SPPP···'
2.实验
2.1 实验步骤
- 数据预处理,得到字典、样本数等基本数据
- 构建Seq2Seq(Attention)模型,分别设置编解码器的输入
- 训练
- 代入数据,输入编码器,然后输入解码器
- 得到模型输出值,取其中最大值的索引,找到字典中对应的字母,即为模型预测的下一个字母.
- 把模型输出值和真实值相比,求得误差损失函数,运用Adam动量法梯度下降
- 测试: 贪婪搜索
- 可视化注意力权重矩阵
2.2 算法模型
2.2.1 Encoder
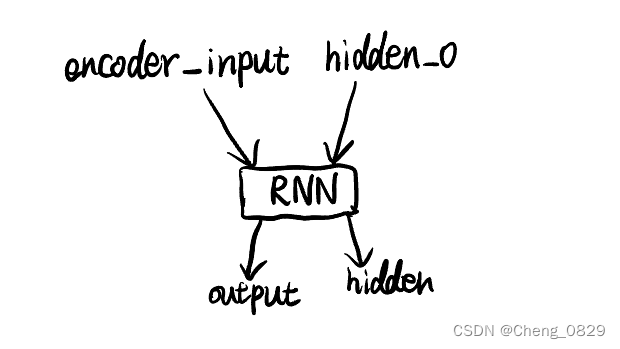
2.2.2 Decoder
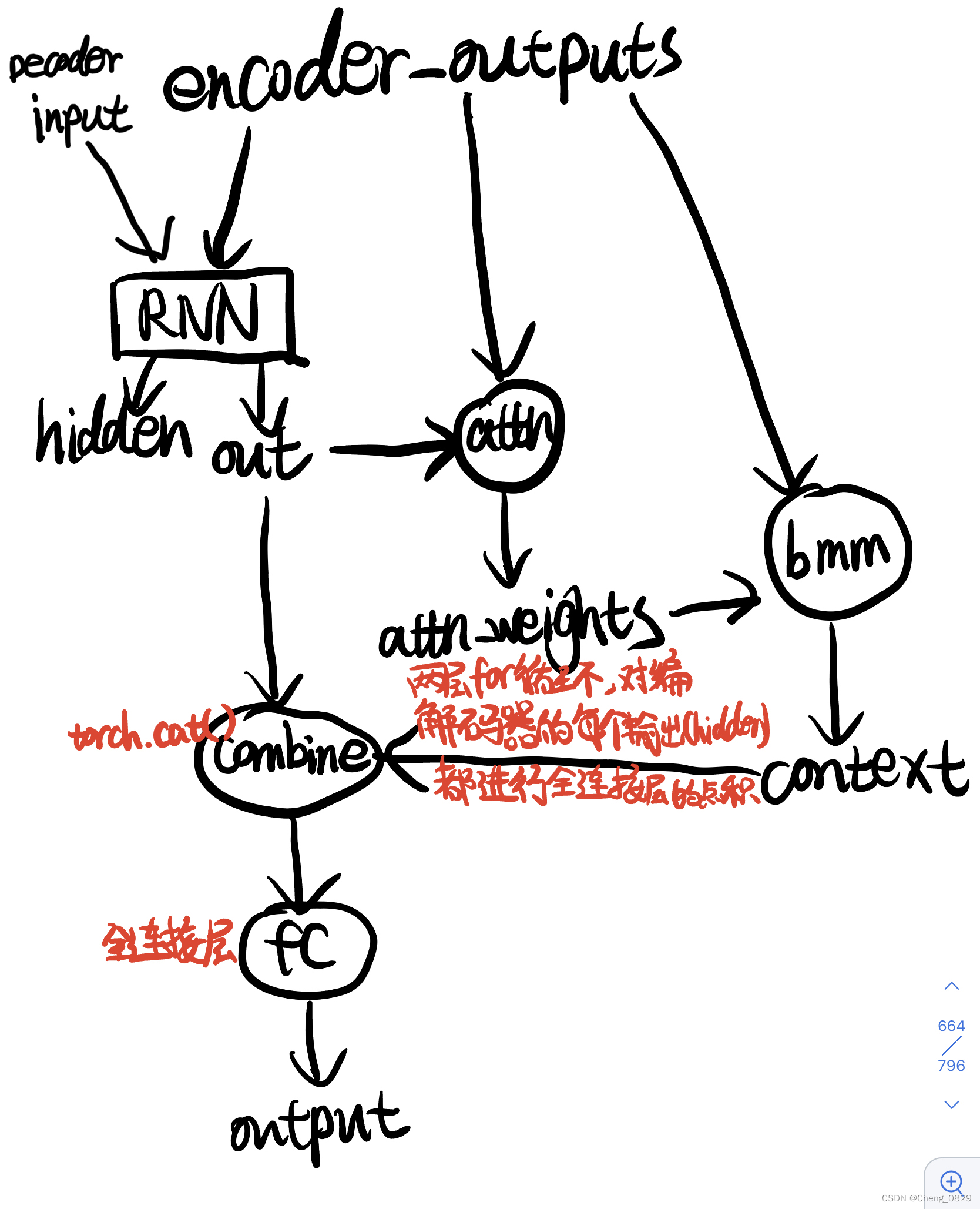
"""
Task: 基于Seq2Seq和注意力机制的句子翻译
Author: ChengJunkai @github.com/Cheng0829
Email: chengjunkai829@gmail.com
Date: 2022/09/13
Reference: Tae Hwan Jung(Jeff Jung) @graykode
"""
from tkinter import font
import numpy as np
import torch, time, os, sys
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
# S: 表示开始进行解码输入的符号。
# E: 表示结束进行解码输出的符号。
# P: 当前批次数据大小小于时间步长时将填充空白序列的符号
'''1.数据预处理'''
def pre_process(sentences):
# 分词
word_sequence = " ".join(sentences).split()
# 去重
word_list = []
'''
如果用list(set(word_sequence))来去重,得到的将是一个随机顺序的列表(因为set无序),
这样得到的字典不同,保存的上一次训练的模型很有可能在这一次不能用
(比如上一次的模型预测碰见我:0,,就输出i:7,但这次模型i在字典8号位置,也就无法输出正确结果)
'''
for word in word_sequence:
if word not in word_list:
word_list.append(word)
word_dict = {w:i for i, w in enumerate(word_list)}
number_dict = {i:w for i, w in enumerate(word_list)}
# 词库大小,也是嵌入向量维度
n_class = len(word_dict) # 12
return word_list, word_dict, number_dict, n_class
'''根据句子数据,构建词元的嵌入向量'''
def make_batch(sentences,word_dict):
# [1, 6, 12] [样本数, 输入句子长度, 嵌入向量维度(单词类别数)]
input_batch = [np.eye(n_class)[[word_dict[n] for n in sentences[0].split()]]]
# [1, 5, 12] [样本数, 输出句子长度, 嵌入向量维度(单词类别数)]
output_batch = [np.eye(n_class)[[word_dict[n] for n in sentences[1].split()]]]
# [1, 5] [样本数, 输出句子长度]
target_batch = [[word_dict[n] for n in sentences[2].split()]]
input_batch = torch.FloatTensor(np.array(input_batch)).to(device)
output_batch =torch.FloatTensor(np.array(output_batch)).to(device)
target_batch = torch.LongTensor(np.array(target_batch)).to(device)
return input_batch, output_batch, target_batch
'''2.构建模型'''
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
self.encoder_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.decoder_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
# Linear for attention
self.attn = nn.Linear(n_hidden, n_hidden)
self.out = nn.Linear(2*n_hidden, n_class)
'''output, _ = model(input_batch, hidden_0, output_batch)'''
def forward(self, encoder_inputs, hidden_0, decoder_inputs):
# [6, 1, 12] [输入句子长度(n_step), 样本数, 嵌入向量维度(单词类别数)]
encoder_inputs = encoder_inputs.transpose(0, 1) # encoder_inputs: [n_step(=n_step, time step), batch_size, n_class]
# [5, 1, 12] [输出句子长度(n_step), 样本数, 嵌入向量维度(单词类别数)]
decoder_inputs = decoder_inputs.transpose(0, 1) # decoder_inputs: [n_step(=n_step, time step), batch_size, n_class]
# print(encoder_inputs.shape, decoder_inputs.shape)
'''编码器encoder'''
# encoder_outputs : [实际的n_step, batch_size, num_directions(=1)*n_hidden] # [5,1,128]
# encoder_states : [num_layers*num_directions, batch_size, n_hidden] # [1,1,128]
'''encoder_states是最后一个时间步的输出(即隐藏层状态),和encoder_outputs的最后一个元素一样'''
encoder_outputs, encoder_states = self.encoder_cell(encoder_inputs, hidden_0)
encoder_outputs = encoder_outputs # [6,1,128]
encoder_states = encoder_states # [1,1,128]
# print(encoder_outputs.shape, encoder_states.shape)
n_step = len(decoder_inputs) # 5
# 返回一个未初始化的张量,内部均为随机数
output = torch.empty([n_step, 1, n_class]).to(device) # [5,1,12]
'''获取注意力权重 : between(整个编码器上的隐状态, 整个解码器上的隐状态)
有两次加权求和,一次是bmm,一次是dot,对应两个for循环
'''
trained_attn = []
'''解码器上的每个时间步'''
for i in range(n_step): # 5
'''解码器'''
'''decoder_inputs[i]即只需要第i个时间步上面的解码器输入,但必须是三维,所以用unsqueeze升一维'''
decoder_input_one = decoder_inputs[i].unsqueeze(0) # 升维
'''decoder_output_one 和 encoder_states 其实是一样的 因为decoder_cell只算了一个时间步'''
decoder_output_one, encoder_states = self.decoder_cell(decoder_input_one, encoder_states)
decoder_output_one = decoder_output_one
encoder_states = encoder_states
'''attn_weights是一个解码器时间步隐状态和整个编码器之间的注意力权重'''
# attn_weights : [1, 1, n_step] # [1,1,6]
attn_weights = self.get_attn_one_to_all(decoder_output_one, encoder_outputs)
#
'''squeeze():[1,1,6]->[6,] data:只取数据部分,剔除梯度部分 numpy:转换成一维矩阵'''
trained_attn.append(attn_weights.squeeze().data.numpy())
# numpy遍历不能存在于cuda,所以必须先作为cpu变量进行操作,再进行转换
attn_weights = attn_weights.to(device)
"""a.bmm(b)和torch.bmm(a,b)一样
a:(z,x,y)
b:(z,y,c)
则result = torch.bmm(a,b),维度为:(z,x,c)
"""
'''利用attn第i时刻Encoder的隐状态的加权求和,得到上下文向量,即融合了注意力的模型输出'''
# context:[1,1,n_step(=5)]x[1,n_step(=5),n_hidden(=128)]=[1,1,128]
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
# decoder_output_one : [batch_size(=1), num_directions(=1)*n_hidden]
decoder_output_one = decoder_output_one.squeeze(0) # [1,1,128] -> [1,128]
# [1, num_directions(=1)*n_hidden] # [1,128]
context = context.squeeze(1)
'''把上下文向量和解码器隐状态进行concat,得到融合了注意力的模型输出'''
# torch.cat的dim=1代表在第二个维度上拼接 ,所以[1,128]+[1,128]->[1,256]
# output[i] = self.out(torch.cat((decoder_output_one, context), 1))
output[i] = self.out(torch.cat((decoder_output_one, context), 1))
# output: [5,1,12] -> [1,5,12] -> [5,12]
return output.transpose(0, 1).squeeze(0), np.array(trained_attn)
'''获取注意力权重 : between(解码器的一个时间步的隐状态, 整个编码器上的隐状态)'''
def get_attn_one_to_all(self, decoder_output_one, encoder_outputs):
n_step = len(encoder_outputs) # 6
attn_scores = torch.zeros(n_step) # attn_scores : [n_step,] -> [6,]
'''对解码器的每个时间步获取注意力权重'''
for i in range(n_step):
encoder_output_one = encoder_outputs[i]
attn_scores[i] = self.get_attn_one_to_one(decoder_output_one, encoder_output_one)
"""F.softmax(matrix,dim) 将scores标准化为0到1范围内的权重
softmax(x_i) = exp(x_i) / sum( exp(x_1) + ··· + exp(x_n) )
由于attn_scores是一维张量,所以F.softmax不用指定dim
"""
# .view(1,1,-1)把所有元素都压到最后一个维度上,把一维的张量变成三维的
return F.softmax(attn_scores).view(1, 1, -1) # [6,] -> [1,1,6]
'''获取注意力权重 : between(编码器的一个时间步的隐状态, 解码器的一个时间步的隐状态)'''
def get_attn_one_to_one(self, decoder_output_one, encoder_output_one):
# decoder_output_one : [batch_size, num_directions(=1)*n_hidden] # [1,128]
# encoder_output_one : [batch_size, num_directions(=1)*n_hidden] # [1,128]
# score : [batch_size, n_hidden] -> [1,128]
score = self.attn(encoder_output_one)
'''X.view(shape)
>>> X = torch.ones((3,2))
>>> X = X.view(2,3) # X形状变为(2,3)
>>> X = X.view(-1) # X形状变为一维
'''
# decoder_output_one : [n_step(=1), batch_size(=1), num_directions(=1)*n_hidden] -> [1,1,128]
# score : [batch_size, n_hidden] -> [1,128]
# 求点积
return torch.dot(decoder_output_one.view(-1), score.view(-1)) # inner product make scalar value
def translate(sentences):
input_batch, output_batch, target_batch = make_batch(sentences,word_dict)
blank_batch = [np.eye(n_class)[[word_dict[n] for n in 'SPPPP']]]
# test_batch: [1,5,12] [batch_size,len_sen,dict_size]
test_batch = torch.FloatTensor(np.array(blank_batch)).to(device)
dec_inputs = torch.FloatTensor(np.array(blank_batch)).to(device)
'''贪婪搜索'''
for i in range(len(test_batch[0])):
# predict: [len_sen, dict_size] [5,12]
predict, trained_attn = model(input_batch, hidden_0, dec_inputs)
predict = predict.data.max(1, keepdim=True)[1] # [5,1] [sen_len,1]
# 覆盖之前的padding字符
dec_inputs[0][i][word_dict['P']] = 0
dec_inputs[0][i][predict[i][0]] = 1
predict, trained_attn = model(input_batch, hidden_0, dec_inputs)
predict = predict.data.max(1, keepdim=True)[1] # [5,1] [sen_len,1]
decoded = [word_list[i] for i in predict]
real_decoded = decoded # 记录不清除特殊字符的decoded
'''清除特殊字符'''
'''训练集的target均以E结尾,所以模型输出最后一个值也会是E'''
if 'E' in decoded:
end = decoded.index('E') # 5
decoded = decoded[:end] # 删除结束符及之后的所有字符
else:
return # 报错
while(True):
if 'P' in decoded:
del decoded[decoded.index('P')] # 删除空白符
else:
break
# 把列表元素合成字符串
translated = ' '.join(decoded)
real_output = ' '.join(real_decoded)
return translated, real_output
if __name__ == '__main__':
# n_step = 5 # number of cells(= number of Step)
chars = 30 * '*'
n_hidden = 128 # number of hidden units in one cell
'''GPU比CPU慢的原因大致为:
数据传输会有很大的开销,而GPU处理数据传输要比CPU慢,
而GPU在矩阵计算上的优势在小规模神经网络中无法明显体现出来
'''
device = ['cuda:0' if torch.cuda.is_available() else 'cpu'][0]
sentences = ['我 想 喝 啤 酒 P', 'S i want a beer', 'i want a beer E']
'''1.数据预处理'''
word_list, word_dict, number_dict, n_class = pre_process(sentences)
input_batch, output_batch, target_batch = make_batch(sentences,word_dict)
# hidden_0 : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
hidden_0 = torch.zeros(1, 1, n_hidden).to(device) # [1,1,128]
'''2.构建模型'''
model = Attention()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
if os.path.exists('model_param.pt') == True:
# 加载模型参数到模型结构
model.load_state_dict(torch.load('model_param.pt', map_location=device))
'''3.训练'''
print('{}\nTrain\n{}'.format('*'*30, '*'*30))
loss_record = []
for epoch in range(1000):
optimizer.zero_grad()
output, trained_attn = model(input_batch, hidden_0, output_batch)
output = output.to(device)
loss = criterion(output, target_batch.squeeze(0)) # .squeeze(0)降成1维
loss.backward()
optimizer.step()
if loss >= 0.0001: # 连续30轮loss小于0.01则提前结束训练
loss_record = []
else:
loss_record.append(loss.item())
if len(loss_record) == 30:
torch.save(model.state_dict(), 'model_param.pt')
break
if (epoch + 1) % 100 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'Loss = {:.6f}'.format(loss))
torch.save(model.state_dict(), 'model_param.pt')
'''4.测试'''
print('{}\nTest\n{}'.format('*'*30, '*'*30))
input = sentences[0]
output, real_output = translate(input)
print(sentences[0].replace(' P', ''), '->', output)
'''5.可视化注意力权重矩阵'''
trained_attn = trained_attn.round(2)
fig = plt.figure(figsize=(len(input.split()), len(real_output.split()))) # (5,5)
ax = fig.add_subplot(1, 1, 1)
ax.matshow(trained_attn, cmap='viridis')
ax.set_xticklabels([''] + input.split(), \
fontdict={'fontsize': 14}, fontproperties='SimSun') # 宋体
ax.set_yticklabels([''] + real_output.split(), \
fontdict={'fontsize': 14}, fontproperties='SimSun')
plt.show()
NLP之基于Seq2Seq和注意力机制的句子翻译的更多相关文章
- 基于Seq2Seq和注意力机制的句子翻译
Seq2Seq(Attention) 目录 Seq2Seq(Attention) 1.理论 1.1 机器翻译 1.1.1 模型输出结果处理 1.1.2 BLEU得分 1.2 注意力模型 1.2.1 A ...
- NLP之基于Bi-LSTM和注意力机制的文本情感分类
Bi-LSTM(Attention) @ 目录 Bi-LSTM(Attention) 1.理论 1.1 文本分类和预测(翻译) 1.2 注意力模型 1.2.1 Attention模型 1.2.2 Bi ...
- NLP教程(6) - 神经机器翻译、seq2seq与注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- NLP之基于Seq2Seq的单词翻译
Seq2Seq 目录 Seq2Seq 1.理论 1.1 基本概念 1.2 模型结构 1.2.1 Encoder 1.2.2 Decoder 1.3 特殊字符 2.实验 2.1 实验步骤 2.2 算法模 ...
- TensorFlow从1到2(十)带注意力机制的神经网络机器翻译
基本概念 机器翻译和语音识别是最早开展的两项人工智能研究.今天也取得了最显著的商业成果. 早先的机器翻译实际脱胎于电子词典,能力更擅长于词或者短语的翻译.那时候的翻译通常会将一句话打断为一系列的片段, ...
- 自注意力机制(Self-attention Mechanism)——自然语言处理(NLP)
近年来,注意力(Attention)机制被广泛应用到基于深度学习的自然语言处理(NLP)各个任务中.随着注意力机制的深入研究,各式各样的attention被研究者们提出.在2017年6月google机 ...
- 深度学习教程 | Seq2Seq序列模型和注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/35 本文地址:http://www.showmeai.tech/article-det ...
- 注意力机制(Attention Mechanism)应用——自然语言处理(NLP)
近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了最近神经网络研究的一个热点,下面是一些基于attention机制的神经网络在 ...
- 深度学习之注意力机制(Attention Mechanism)和Seq2Seq
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容: 1.注意力机制是为了解决什么问题而提出来的? 2.软性注意力机制的数学原理: 3.软性注意力机制. ...
随机推荐
- 文件上传接入阿里云OSS
目的:将文件交给阿里云进行管理,可避免文件对本地服务器资源的占用,阿里云OSS还可根据读写偏好选择合适的文件存储类型服务器,文件异地备份等 一.阿里云OSS基础了解(前提) 1.存储空间(Bucket ...
- Ubuntu 20.04安装Docker
Docker学习系列文章 入门必备:十本你不容错过的Docker入门到精通书籍推荐 day1.全面的Docker快速入门教程 day2.CentOS 8.4安装Docker day3.Windows1 ...
- Vue+Koa+MongoDB从零打造一个任务管理系统
大概是在18年的时候,当时还没有疫情.当时工作中同时负责多个项目,有 PC 端运营管理后台的,有移动端 M 站的,有微信小程序的,每天 git 分支切到头昏眼花,每个需求提测需要发送邮件,而且周五要写 ...
- python包合集-shutil
一.简介 shutil是 python 中的高级文件操作模块,与os模块形成互补的关系,os主要提供了文件或文件夹的新建.删除.查看等方法,还提供了对文件以及目录的路径操作.shutil模块提供了移动 ...
- fast json 乱序问题解决过程
解决问题:保存到redis中的jsonstring在转回jsonObject的时候乱序: 解决方案:https://inlhx.iteye.com/blog/2312512 解决过程: 1 看fast ...
- 分库分表之ShardingSphere
目录 分库分表诞生的前景 分库分表的方式(垂直拆分,水平复制) 1.垂直拆分 1.1 垂直分库 1.2 垂直分表 2.水平拆分 2.1 水平分库 2.2 水平分表 分库分库中间件 ShardingSp ...
- 算法模板:dijkstra
#include<iostream> #include<algorithm> #include<cstring> #include<string> #i ...
- 有一个线性表,采用带头结点的单链表L来存储,设计一个算法将其逆置,且不能建立新节点,只能通过表中已有的节点的重新组合来完成。
有一个线性表,采用带头结点的单链表L来存储,设计一个算法将其逆置,且不能建立新节点,只能通过表中已有的节点的重新组合来完成. 分析:线性表中关于逆序的问题,就是用建立链表的头插法.而本题要求不能建立新 ...
- 058_末晨曦Vue技术_过渡 & 动画之过渡的类名
进入/离开 & 列表过渡 点击打开视频讲解更加详细 概述 Vue 在插入.更新或者移除 DOM 时,提供多种不同方式的应用过渡效果.包括以下工具: 在 CSS 过渡和动画中自动应用 class ...
- 第七十三篇:解决Vue组件中的样式冲突
好家伙, 1.组件之间的样式冲突 默认情况下,写在.vue组件中的样式会全局生效,因此很容易造成多个组件之间的样式冲突问题. 举个例子: 我们在Left.vue的组件中添加样式 <templat ...