python基础(数据库、可视化软件Navicat、python操作MySQL)
多表查询的两种方法
数据准备:
- 建表
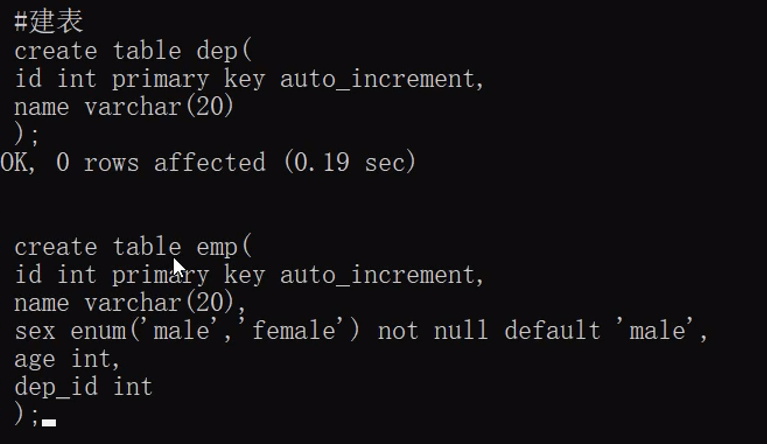
create table dep(
id int primary key auto_increment,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
- 插入数据
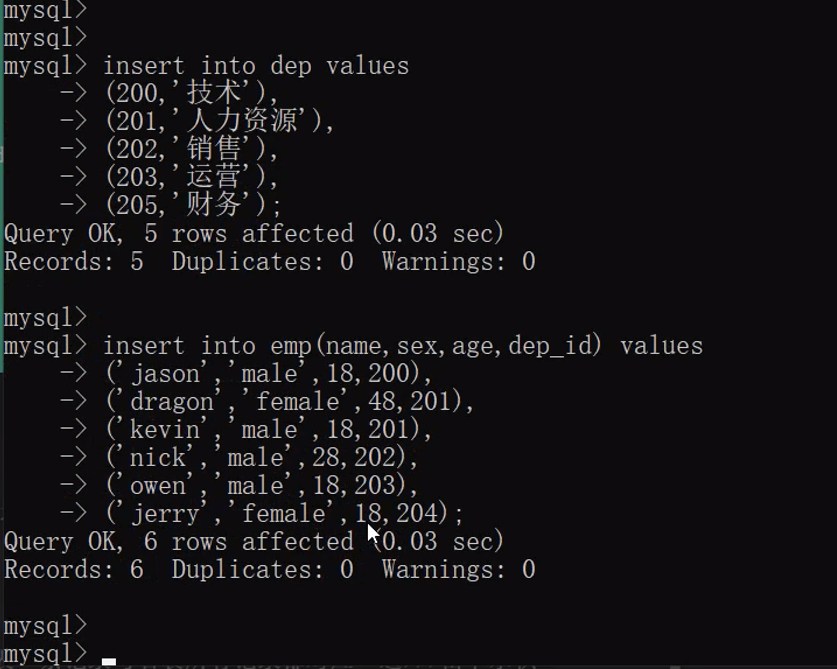
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'安保');
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('tony','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
方式1:连表操作
- inner join 内连接
select * from emp inner join dep on emp.dep_id=dep.id;
"""只连接两张表中公有的数据部分"""

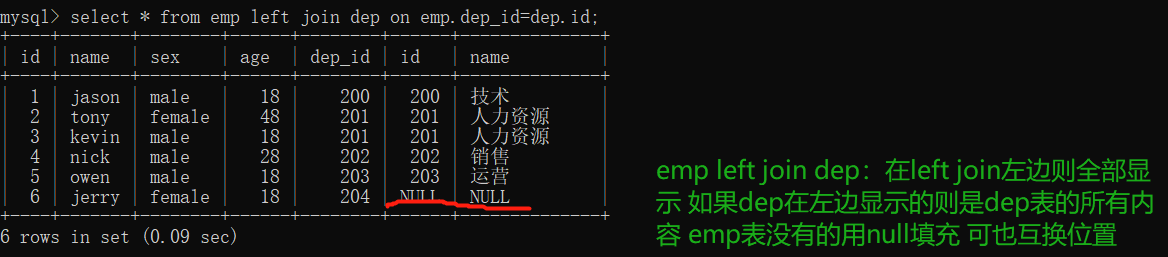
- left join 左连接
select * from emp left join dep on emp.dep_id=dep.id;
"""以左表为基准 展示左表所有的数据 如果没有对应项则用NULL填充"""
- right join 右连接
select * from emp right join dep on emp.dep_id=dep.id;
"""以右表为基准 展示右表所有的数据 如果没有对应项则用NULL填充"""

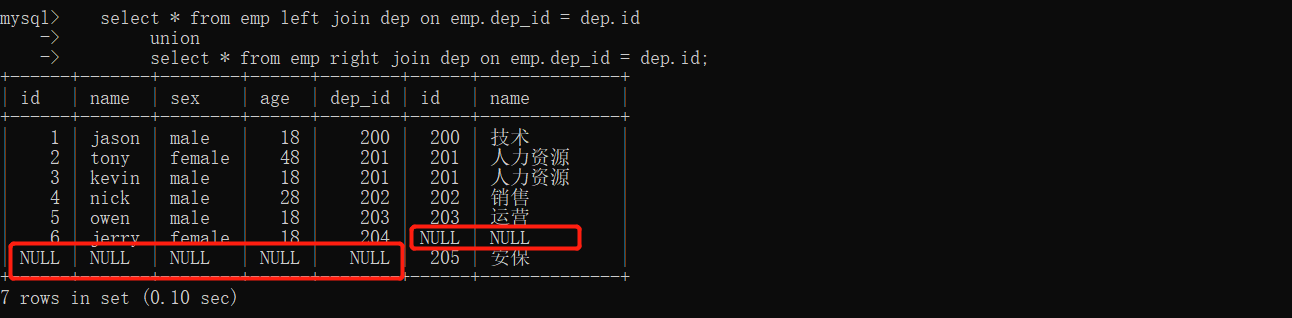
- union 全连接
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
"""以左右表为基准 展示所有的数据 各自没有的全部NULL填充"""
- 总结
'''
学会了连表操作之后也就可以连接N多张表
思路:将拼接之后的表起别名当成一张表再去与其他表拼接 再起别名当一张表 再去与其他表拼接 其次往复即可
'''
方式2:子查询
- 子查询是什么?
"""就是将一条SQL语句用括号括起来当成另外一条SQL语句的查询条件"""
- 题目:求姓名是jason的员工部门名称
"""子查询类似于我们日常生活中解决问题的方式>>>:分步操作"""
- 步骤1:先根据jason获取部门编号
select dep_id from emp where name='jason';
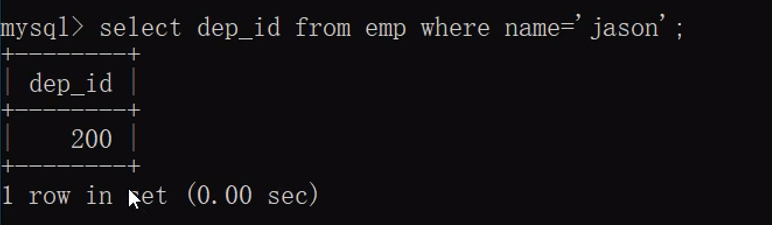
- 步骤2:再根据部门编号获取部门名称
select name from dep where id=200;
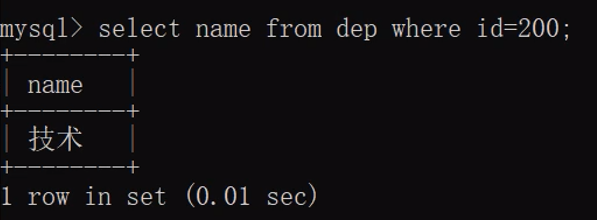
- 总结
select name from dep where id=(select dep_id from emp where name='jason');
'''
很多时候多表查询需要结合实际情况判断用哪种 更多时候甚至是相互配合使用
'''

小知识点补充说明
- 1.concat与concat_ws
"""concat用于分组之前的字段拼接操作"""
select concat(name,'$',sex) from emp;
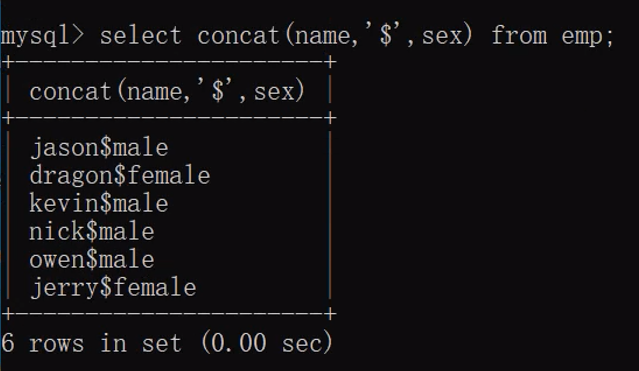
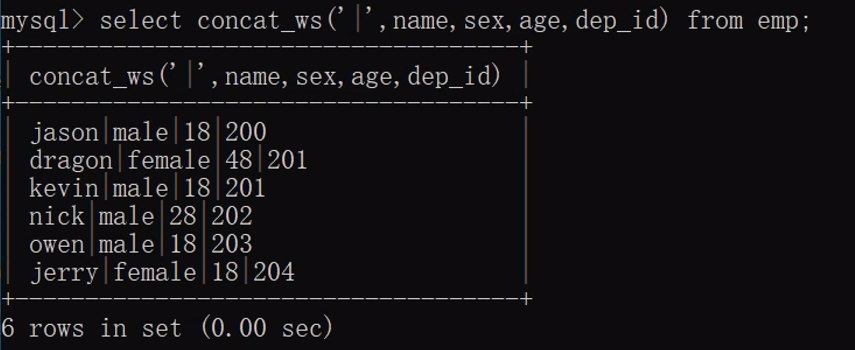
"""concat_ws拼接多个字段并且中间的连接符一致"""
select concat_ws('|',name,sex,age,dep_id) from emp;
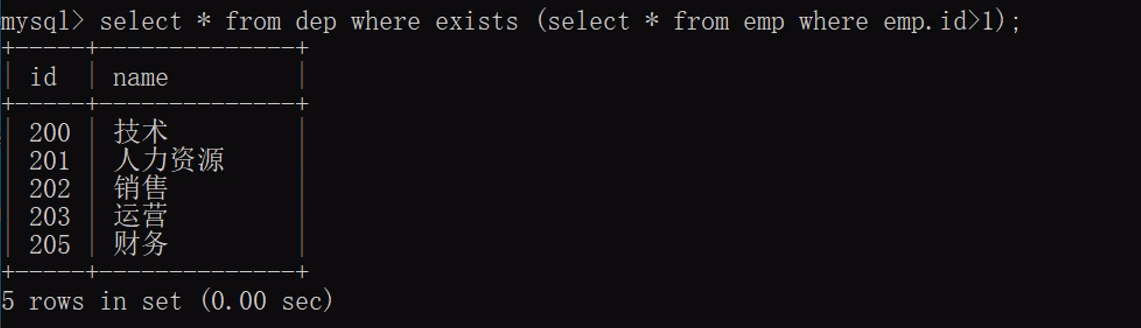
- 2.exists
"""sql2有结果的情况下才会执行sql1 否则不执行sql1 返回空数据"""
sql1 exists sql2

- 3.表相关SQL补充
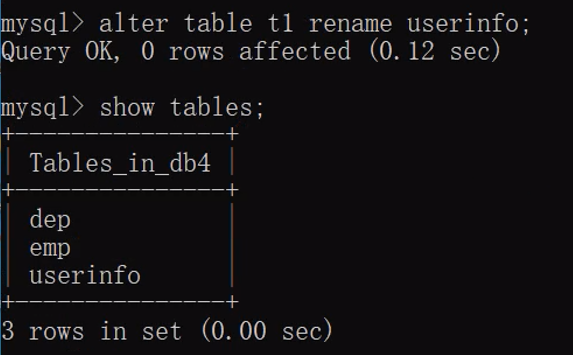
alter table 表名 rename 新表名; # 修改表名
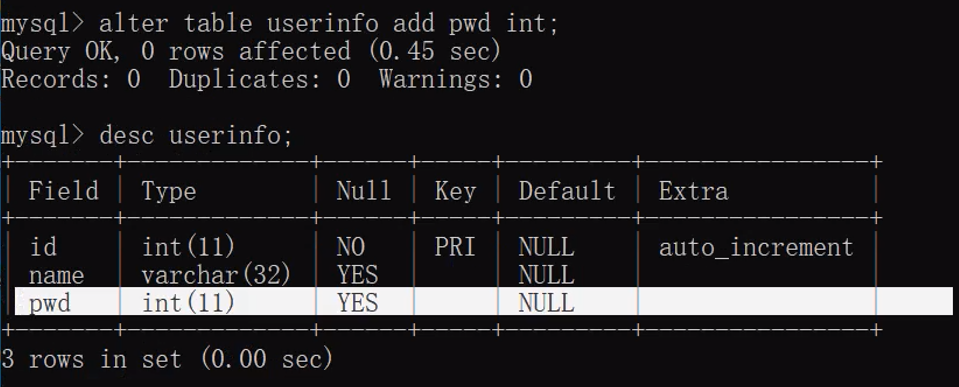
alter table 表名 add 字段名 字段类型(数字) 约束条件; # 添加字段
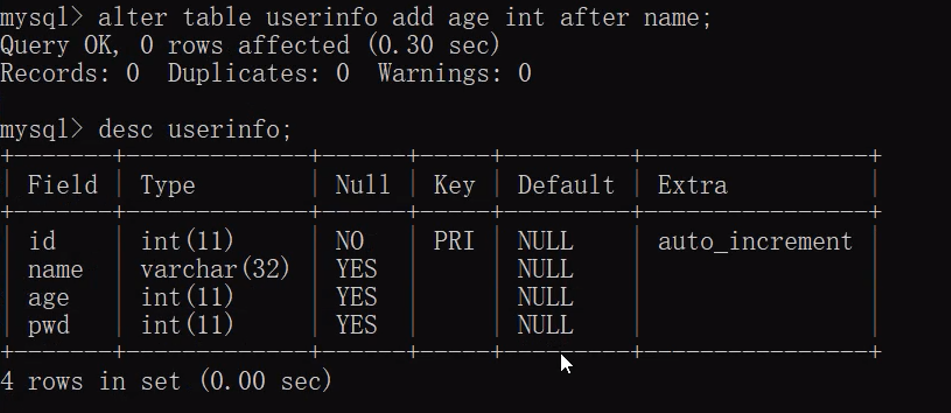
alter table 表名 add 字段名 字段类型(数字) 约束条件 after 已有字段;
alter table 表名 add 字段名 字段类型(数字) 约束条件 first; # 修改字段
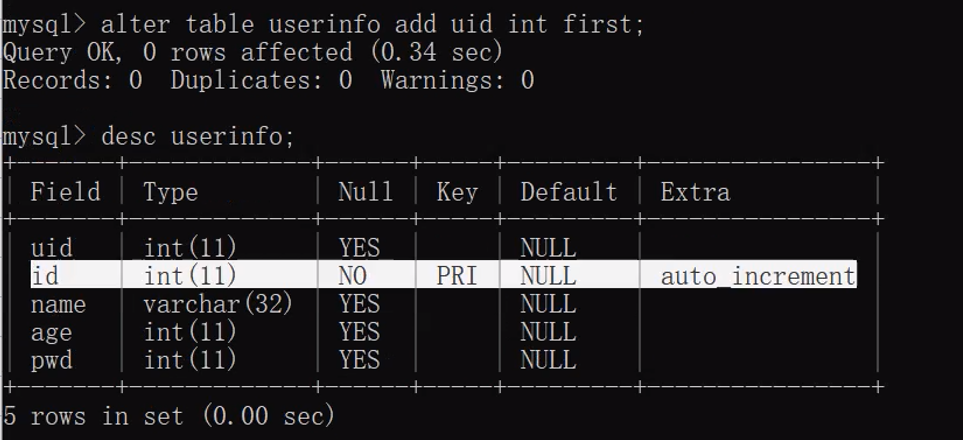
alter table 表名 change 旧字段名 新字段名 字段类型(数字) 约束条件;
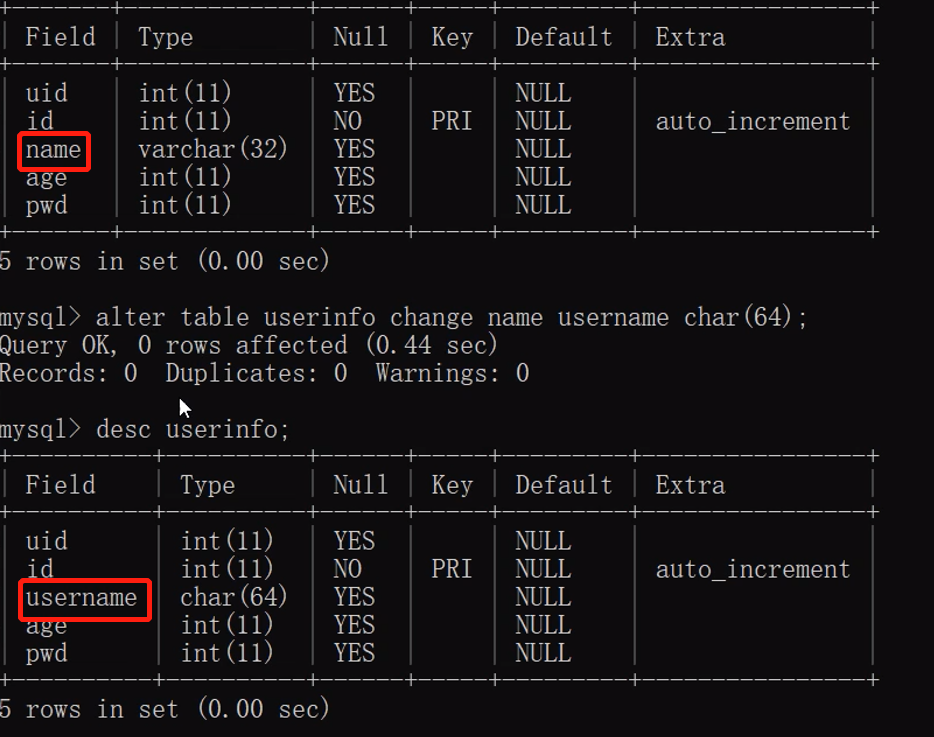
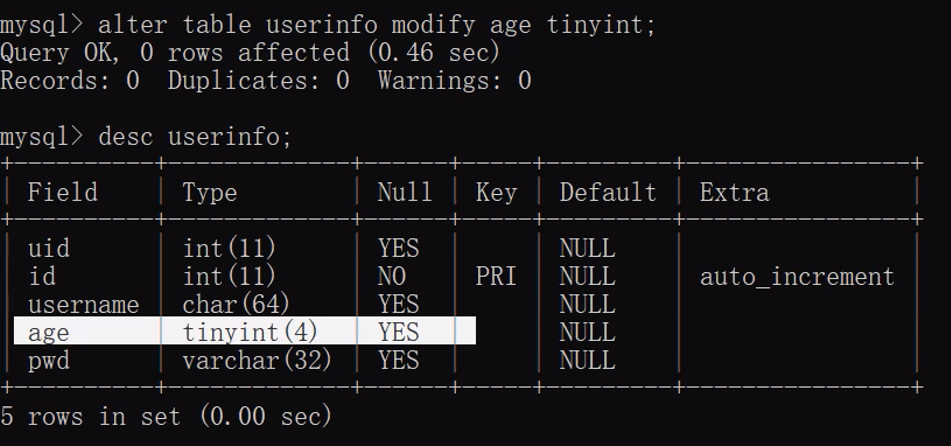
alter table 表名 modify 字段名 新字段类型(数字) 约束条件;
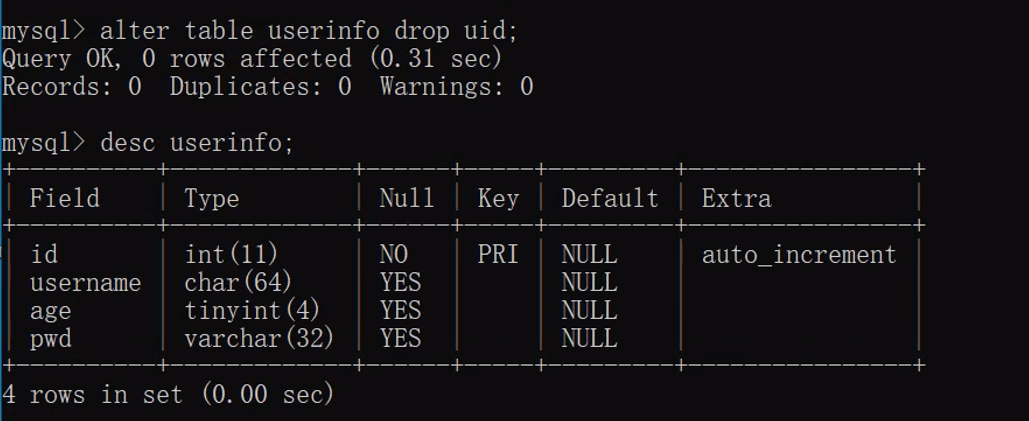
alter table 表名 drop 字段名; # 删除字段
可视化软件Navicat
简介
第三方开发的用来充当数据库客户端的简单快捷的操作界面
无论第三方软件有多么的花里胡哨 底层的本质还是SQL
能够操作数据库的第三方可视化软件有很多 其中针对MySQL最出名的就是Navicat
1.官网下载地址
版本很多、能够充当的数据库客户端也很多
2.破解教程
3.常用操作
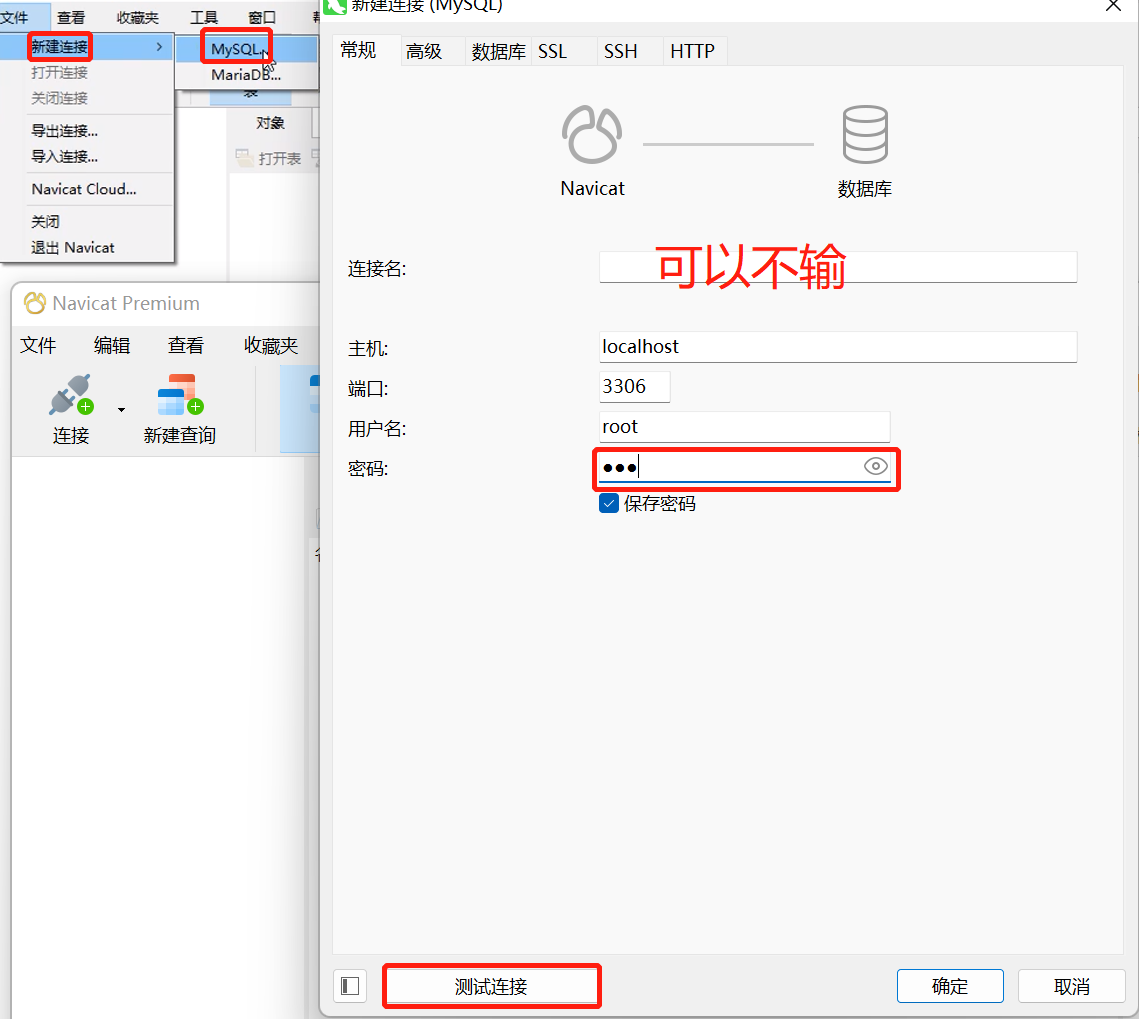
- 有些功能可能需要自己修改SQL预览
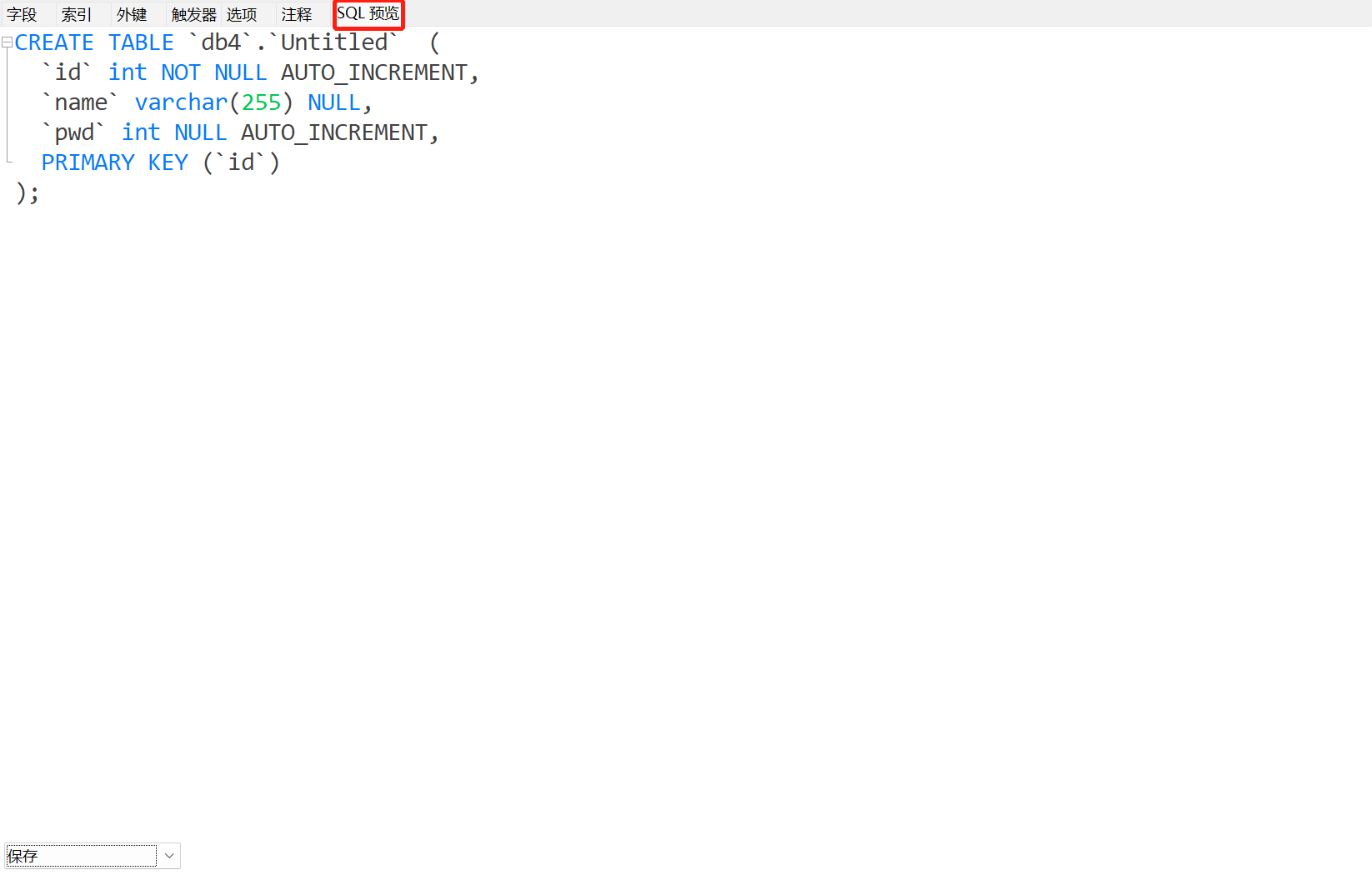
- 创建库
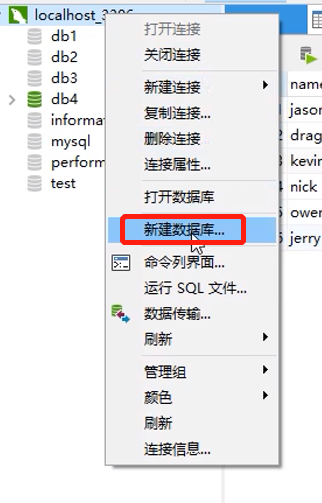
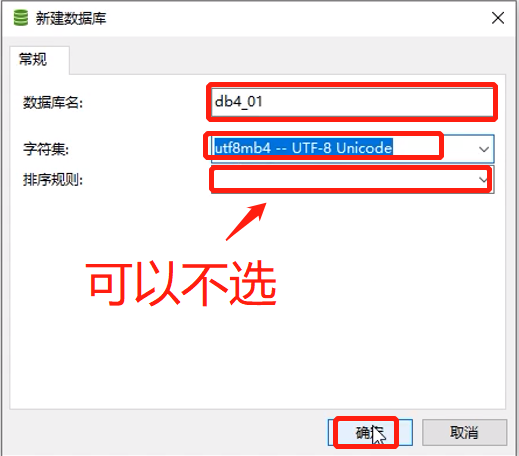
- 创建表
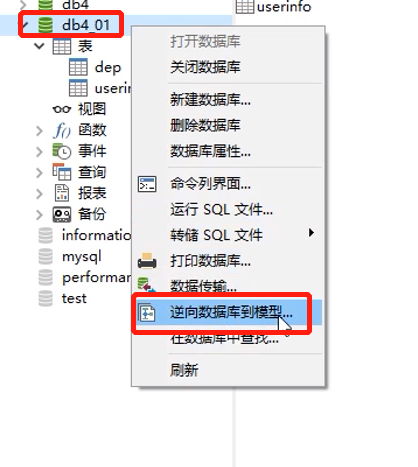
- 逆向数据库到模型
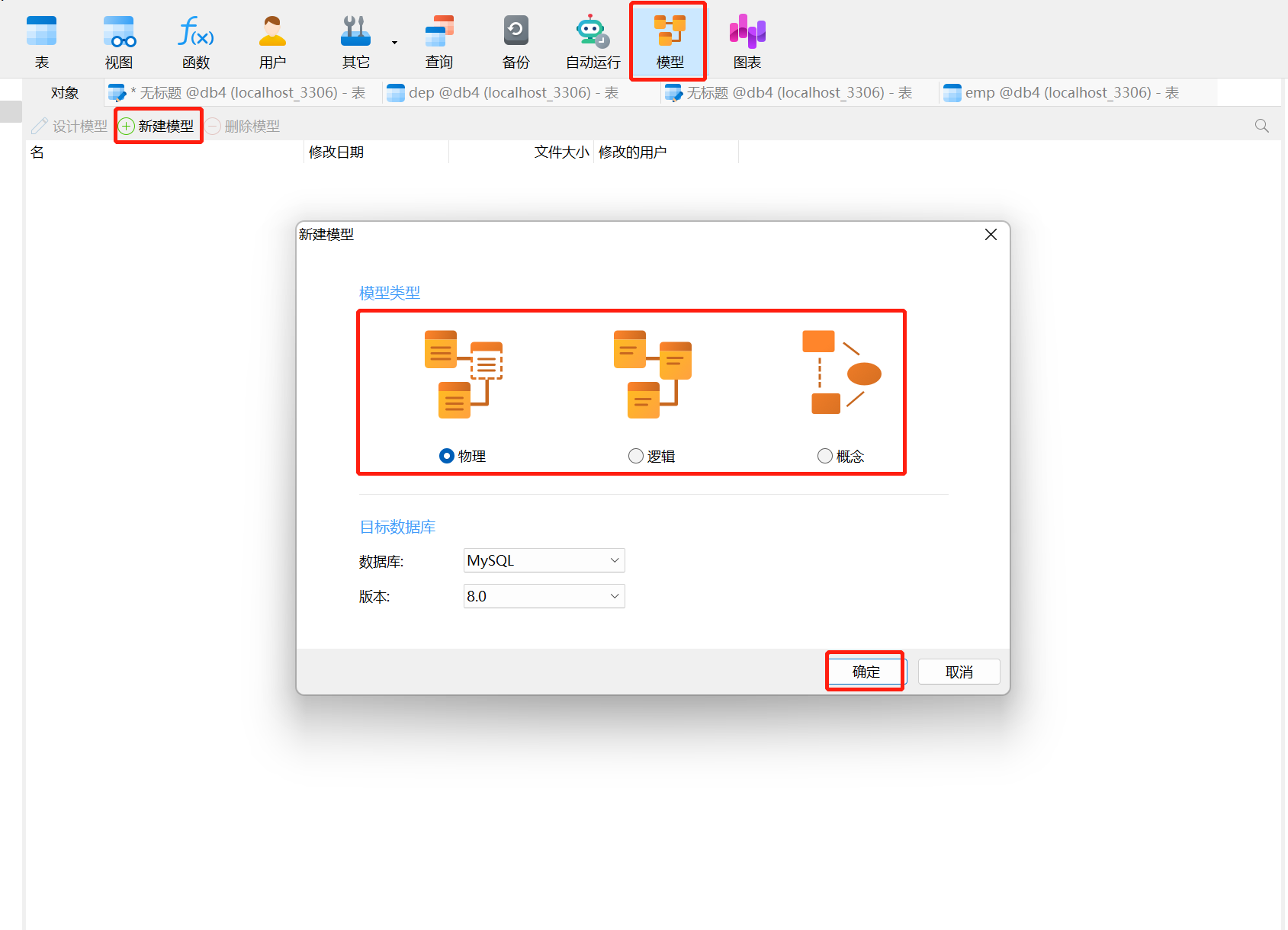
- 模型创建
新建查询可以编写SQL语句并自带提示功能
SQL语句注释语法
--、#、**

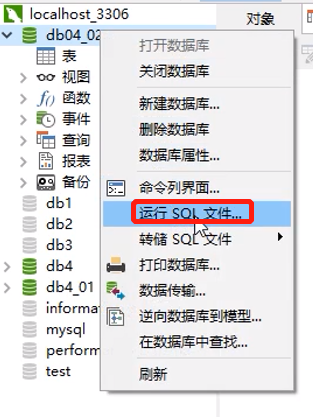
运行、转储SQL文件
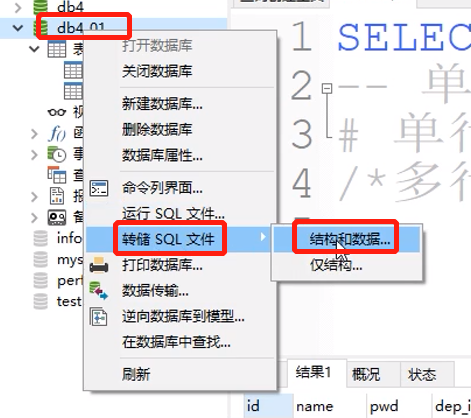
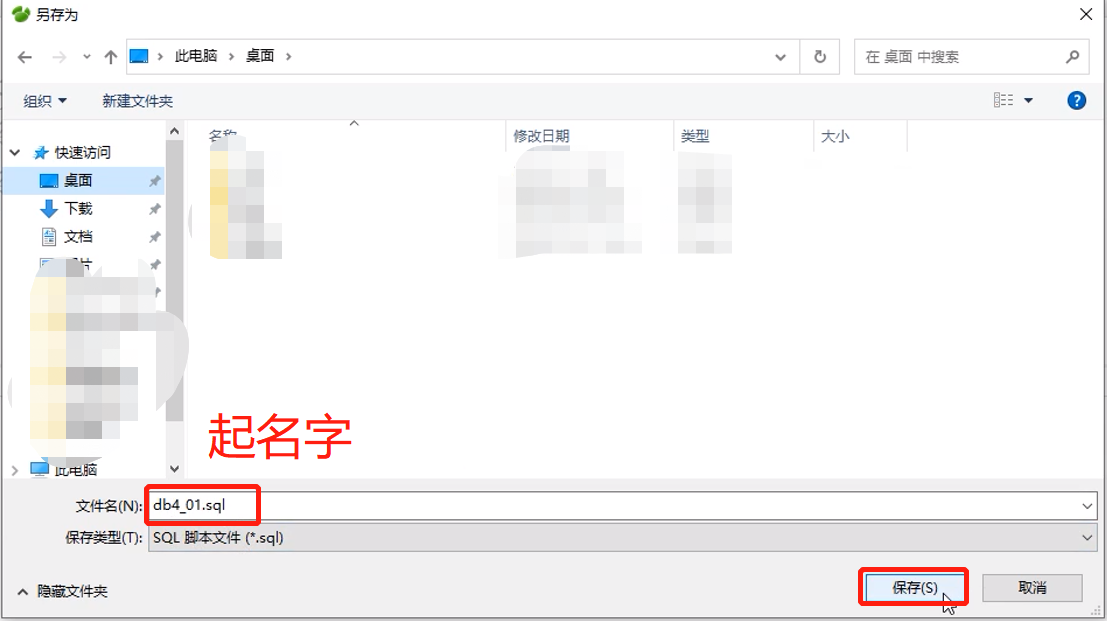

接收数据
多表查询练习题
"""
编写复杂的SQL不要想着一口气写完
一定要先明确思路 然后一步步写一步步查一步步补
"""
1、查询所有的课程的名称以及对应的任课老师姓名
2、查询平均成绩大于八十分的同学的姓名和平均成绩
3、查询没有报李平老师课的学生姓名
4、查询没有同时选修物理课程和体育课程的学生姓名
5、查询挂科超过两门(包括两门)的学生姓名和班级
-- 1、查询所有的课程的名称以及对应的任课老师姓名
# 1.先确定需要用到几张表 课程表 分数表
# 2.预览表中的数据 做到心中有数
-- select * from course;
-- select * from teacher;
# 3.确定多表查询的思路 连表 子查询 混合操作
-- SELECT
-- teacher.tname,
-- course.cname
-- FROM
-- course
-- INNER JOIN teacher ON course.teacher_id = teacher.tid;
-- 2、查询平均成绩大于八十分的同学的姓名和平均成绩
# 1.先确定需要用到几张表 学生表 分数表
# 2.预览表中的数据
-- select * from student;
-- select * from score;
# 3.根据已知条件80分 选择切入点 分数表
# 求每个学生的平均成绩 按照student_id分组 然后avg求num即可
-- select student_id,avg(num) as avg_num from score group by student_id having avg_num>80;
# 4.确定最终的结果需要几张表 需要两张表 采用连表更加合适
-- SELECT
-- student.sname,
-- t1.avg_num
-- FROM
-- student
-- INNER JOIN (
-- SELECT
-- student_id,
-- avg(num) AS avg_num
-- FROM
-- score
-- GROUP BY
-- student_id
-- HAVING
-- avg_num > 80
-- ) AS t1 ON student.sid = t1.student_id;
-- 3、查询没有报李平老师课的学生姓名
# 1.先确定需要用到几张表 老师表 课程表 分数表 学生表
# 2.预览每张表的数据
# 3.确定思路 思路1:正向筛选 思路2:筛选所有报了李平老师课程的学生id 然后取反即可
# 步骤1 先获取李平老师教授的课程id
-- select tid from teacher where tname = '李平老师';
-- select cid from course where teacher_id = (select tid from teacher where tname = '李平老师');
# 步骤2 根据课程id筛选出所有报了李平老师的学生id
-- select distinct student_id from score where course_id in (select cid from course where teacher_id = (select tid from teacher where tname = '李平老师'))
# 步骤3 根据学生id去学生表中取反获取学生姓名
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid NOT IN (
-- SELECT DISTINCT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN (
-- SELECT
-- cid
-- FROM
-- course
-- WHERE
-- teacher_id = (
-- SELECT
-- tid
-- FROM
-- teacher
-- WHERE
-- tname = '李平老师'
-- )
-- )
-- )
-- 4、查询没有同时选修物理课程和体育课程的学生姓名(报了两门或者一门不报的都不算)
# 1.先确定需要的表 学生表 分数表 课程表
# 2.预览表数据
# 3.根据给出的条件确定起手的表
# 4.根据物理和体育筛选课程id
-- select cid from course where cname in ('物理','体育');
# 5.根据课程id筛选出所有跟物理 体育相关的学生id
-- select * from score where course_id in (select cid from course where cname in ('物理','体育'))
# 6.统计每个学生报了的课程数 筛选出等于1的
-- select student_id from score where course_id in (select cid from course where cname in ('物理','体育'))
-- group by student_id
-- having count(course_id) = 1;
# 7.子查询获取学生姓名即可
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid IN (
-- SELECT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN (
-- SELECT
-- cid
-- FROM
-- course
-- WHERE
-- cname IN ('物理', '体育')
-- )
-- GROUP BY
-- student_id
-- HAVING
-- count(course_id) = 1
-- )
-- 5、查询挂科超过两门(包括两门)的学生姓名和班级
# 1.先确定涉及到的表 分数表 学生表 班级表
# 2.预览表数据
-- select * from class
# 3.根据条件确定以分数表作为起手条件
# 步骤1 先筛选掉大于60的数据
-- select * from score where num < 60;
# 步骤2 统计每个学生挂科的次数
-- select student_id,count(course_id) from score where num < 60 group by student_id;
# 步骤3 筛选次数大于等于2的数据
-- select student_id from score where num < 60 group by student_id having count(course_id) >= 2;
# 步骤4 连接班级表与学生表 然后基于学生id筛选即可
SELECT
student.sname,
class.caption
FROM
student
INNER JOIN class ON student.class_id = class.cid
WHERE
student.sid IN (
SELECT
student_id
FROM
score
WHERE
num < 60
GROUP BY
student_id
HAVING
count(course_id) >= 2
);
python操作MySQL
pymysql模块
pip3 install pymysql
import pymysql
# 1.连接MySQL服务端
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
db='db4_03',
charset='utf8mb4'
)
# 2.产生游标对象
# cursor = conn.cursor() # 括号内不填写额外参数 数据是元组 指定性不强 [(),()]
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # [{},{}]
# 3.编写SQL语句
# sql = 'select * from teacher;'
sql = 'select * from score;'
# 4.发送SQL语句
affect_rows = cursor.execute(sql) # execute也有返回值 接收的是SQL语句影响的行数
print(affect_rows)
# 5.获取SQL语句执行之后的结果
res = cursor.fetchall()
print(res)
pymysql补充说明
1.获取数据
fetchall() 获取所有的结果
fetchone() 获取结果集的第一个数据
fetchmany() 获取指定数量的结果集
ps:注意三者都有类似于文件光标移动的特性
cursor.scroll(1,'relative') # 基于当前位置往后移动
cursor.scroll(0,'absolute') # 基于数据的开头往后移动
2.增删改查
autocommit=True # 针对增 删 改 自动确认(直接配置)
conn.commit() # 针对 增 删 改 需要二次确认(代码确认)
python基础(数据库、可视化软件Navicat、python操作MySQL)的更多相关文章
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- 数据库——可视化工具Navicat、pymysql模块、sql注入问题
数据库--可视化工具Navicat.pymysql模块.sql注入问题 Navicat可视化工具 Navicat是数据库的一个可视化工具,可直接在百度搜索下载安装,它可以通过鼠标"点点点&q ...
- Python进阶----数据库引擎(InnoDB),表的创建,mysql的数据类型,mysql表的约束
Python进阶----数据库引擎(InnoDB),表的创建,mysql的数据类型,mysql表的约束 一丶MySQL的存储引擎 什么是存储引擎: MySQL中的数据用各种不同的技术存储在文件( ...
- 多表查询思路、navicat可视化软件、python操作MySQL、SQL注入问题以及其他补充知识
昨日内容回顾 外键字段 # 就是用来建立表与表之间的关系的字段 表关系判断 # 一对一 # 一对多 # 多对多 """通过换位思考判断""" ...
- PyVista:一款Python的三维可视化软件
技术背景 三维可视化是一项在工业领域中非常重要的技术,而Python中最热门的可视化工具matplotlib和plotly,更加倾向于在数据领域的可视化,用于展现数据的结果.类似的还有百度的pyech ...
- 第二章:Python基础の快速认识基本数据类型和操作实战
本课主题 字符串和操作实战 二进制操作实战 List 列表和操作实战 Tuple 元組和操作实战 Dict 字典和操作实战 作業需求 引言 这遍文章简单介绍了 Python 字符串和集合的方法和应用, ...
- Python基础__Python序列基本类型及其操作(1)
本节考虑的Python的一个中要的内置对象序列, 所谓的序列即一个有序对象的集合.这里的对象可以是数字.字符串等.根据功能的不同将序列分为字符串.列表.元组,本文将以下这几种对象做一些介绍. 一. 字 ...
- Python基础入门(9)- Python文件操作
1.文件的读写 1.1.文件的创建与写入 利用内置函数open获取文件对象 文件操作的模式之写入 文件对象的操作方法之写入保存 1 # coding:utf-8 2 3 import os 4 5 c ...
- MySQL— pymysql模块(防止sql注入),可视化软件Navicat
一.Pymysql import pymysql #python2.X 中是 mysqldb 和 pythonmysql 用法是一模一样的 #pymysql可以伪装成上面这两个模块 user = in ...
- python基础知识第一篇(认识Python)
开发语言: 高级语言:python java php c++ 生成的字节码 字节码转换为机器码 计算机识别运行 低级语言:C 汇编 生成的机器码 PHP语言:适用于网页,局限性 Python,Java ...
随机推荐
- PAT (Basic Level) Practice 1031 查验身份证 分数 15
一个合法的身份证号码由17位地区.日期编号和顺序编号加1位校验码组成.校验码的计算规则如下: 首先对前17位数字加权求和,权重分配为:{7,9,10,5,8,4,2,1,6,3,7,9,10,5,8, ...
- frp服务利用云主机docker服务实现Windows远程连接
1.云主机配置 1.docker部署 # 创建文件 mkdir -p /root/docker/frp && touch /root/docker/frp/frps.ini # 配置文 ...
- PTA 520钻石争霸赛 2021
7-1 自动编程 签到题 #include<bits/stdc++.h> typedef long long ll; const int maxm = 1e5 + 5; const int ...
- Sun 的 BASE64Encoder替代
可以使用 org.apache.commons.codec.binary.Base64替代 Maven依赖如下 <dependency> <groupId>commons-co ...
- Vue学习之--------Scoped样式(2022/8/1)
1.场景 一个页面开发团队进行页面的开发设计.无可避免的会发生样式选择器命名的重复(id的重复.class的重复等).这样间接导致的后果就是.自己的页面样式好好的.在整合一起的时候.可能就会发生样式的 ...
- 齐博x1给表单某个字段设置初始值
自定义表单虽然后台可以设置默认初始值,但是有时候想在前台动态设置初始值的话,可以在URL中添加该字段名,给他动态赋值即可.比如下面的price字段就是动态赋值的.
- Python 根据两个字段排序 中文排序 汉字排序 升序 降序
Python3写法 代码 # -*- coding: utf-8 -*- # 需求:年龄倒序,姓名正序 from itertools import chain from pypinyin import ...
- Selenium4.0+Python3系列(四) - 常见元素操作(含鼠标键盘事件)
一.写在前面 上篇文章介绍的是关于浏览器的常见操作,接下来,我们将继续分享关于元素的常见操作,建议收藏.转发! 二.元素的状态 在操作元素之前,我们需要了解元素的常见状态. 1.常见元素状态判断,傻傻 ...
- iptables入门到精通
iptables其实不是真正的防火墙,我们可以把它理解成一个客户端代理,用户通过iptables这个代理,将用户的安全设定执行到对应的"安全框架"中,这个"安全框架&qu ...
- Golang 和Python 几个小时前 几分钟 几天前的处理
在用golang爬虫的时候 总会遇到 10天前 10分钟前 刚刚这种很影响我们爬取正常事件 所以我写了个方法 来格式化这种事件 golang 版本 package utils import ( &qu ...