JavaEE Day06 JDBC连接池&JDBCTemplate
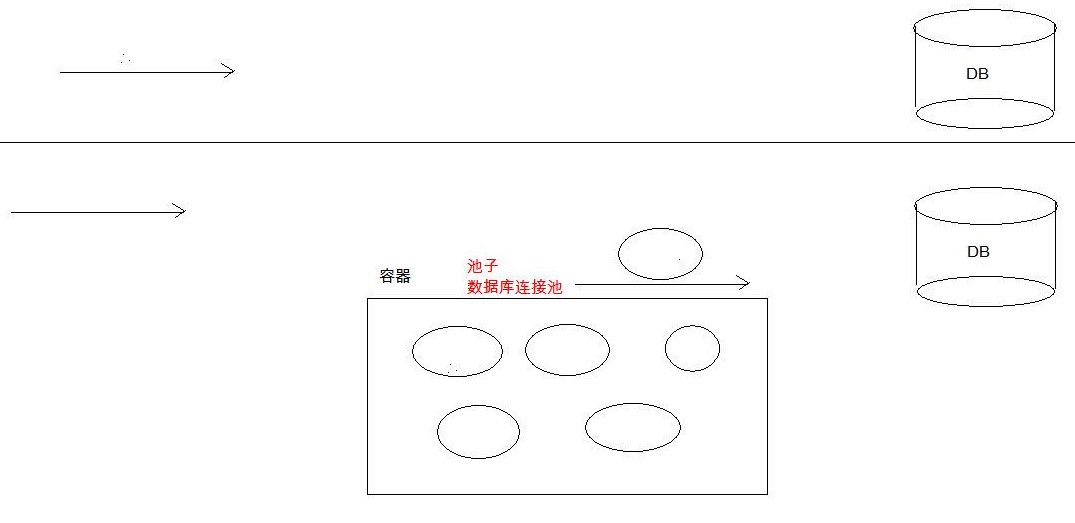
- 数据库连接池
- 简化操作--Spring JDBC提供的 JDBC Template(JDBC的封装)
- 节约资源
- 用户访问高效

- 基本实现 - 生成标准的
Connection对象 - 连接池实现 - 生成将自动参与连接池的
Connection对象。 此实现与中间层连接池管理器配合使用。 - 分布式事务实现 - 生成可用于分布式事务的
Connection对象,并且几乎总是参与连接池。 此实现与中间层事务管理器一起工作,并且几乎总是使用连接池管理器。
- C3P0:数据库连接池技术
- Druid:德鲁伊数据库连接池实现技术,由阿里巴巴提供

- 使用步骤
- 导入两个jar包 c3p0-0.9.5.2.jar 和 mchange-commons-java-0.2.12.jar(doc里面有文档)
- 定义配置文件
- 名称c3p0.properties或 c3p0-config.xml
- 路径:直接蒋文杰放到src目录下即可
- 创建核心对象--数据库连接池对象---ComboPooledDataSource
- 获取连接:getConnection
package cn.itcast.datasource.c3p0;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
/**
* c3p0的演示
*/
public class C3p0Demo1 {
public static void main(String[] args) throws SQLException {
//1.创建数据库连接池对象
DataSource ds = new ComboPooledDataSource();
//2.获取连接对象
Connection conn = ds.getConnection();
//3.打印
System.out.println(conn);
}
}
package cn.itcast.datasource.c3p0;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import java.sql.Connection;
import java.sql.SQLException;
/**
* 演示:连接池参数的验证
*/
public class C3poDemo2 {
public static void main(String[] args) throws SQLException {
//1.获取DataSource连接池,使用默认配置
//ComboPooledDataSource ds = new ComboPooledDataSource();
//2.获取连接
/*
* <!--最大的连接池数量-->
<property name="maxPoolSize">10</property>*/
/* for (int i=1;i<=11;i++){
//超过最大连接池数量会等待三秒,然后报错
Connection conn = ds.getConnection();
System.out.println(i+":"+conn);
if (i==5){
conn.close();
}
}*/
//new C3poDemo2().testNamedConfig();
testNamedConfig();
}
public static void testNamedConfig() throws SQLException {
//1.1获取DataSource连接池,使用指定名称的配置
ComboPooledDataSource ds = new ComboPooledDataSource("otherc3p0");
//2.获取连接
/*
* <!--最大的连接池数量-->
<property name="maxPoolSize">10</property>*/
for (int i=1;i<=10;i++){
//超过最大连接池数量会等待三秒,然后报错
Connection conn = ds.getConnection();
System.out.println(i+":"+conn);
}
}
}<c3p0-config>
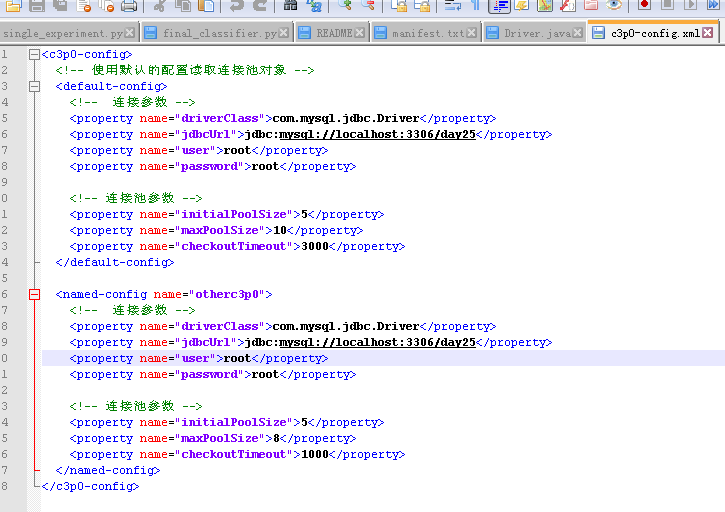
<!-- 使用默认的配置读取连接池对象 -->
<default-config>
<!-- 连接参数 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/day25</property>
<property name="user">root</property>
<property name="password">root</property>
<!-- 连接池参数 -->
<property name="initialPoolSize">5</property>
<property name="maxPoolSize">10</property>
<property name="checkoutTimeout">3000</property>
</default-config>
<named-config name="otherc3p0">
<!-- 连接参数 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/day25</property>
<property name="user">root</property>
<property name="password">root</property>
<!-- 连接池参数 -->
<property name="initialPoolSize">5</property>
<property name="maxPoolSize">8</property>
<property name="checkoutTimeout">1000</property>
</named-config>
</c3p0-config>- maxPoolSize最大连接个数,checkoutTimeout失败后等待时间
- 可以配置多个连接池,不再使用default,而是<named-config name="otherc3p0">
- ComboPooledDataSource构造函数中则需要对应传递参数
- 导入jar包druid-1.0.9.jar
- 定义配置文件
- 配置文件是properties形式的
- 可以叫任意名称,可以放至任意目录下(需要手动加载)
- 加载配置文件,Properties
- 获取数据库连接池对象:通过工厂类获取 DruidSourceFactory
- 获取连接:getConnection()
package cn.itcast.datasource.druid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.util.Properties;
/**
* Druid演示
*/
public class DruidDemo {
public static void main(String[] args) throws Exception {
//1.导入jar包
//2.定义配置文件
//3.加载配置文件
Properties pro=new Properties();
InputStream is = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
pro.load(is);
//4.获取连接池对象
DataSource ds = DruidDataSourceFactory.createDataSource(pro);
//5.获取连接
Connection conn=ds.getConnection();
System.out.println(conn);
}
}- 定义一个工具类JDBCUtils
- 提供静态代码块,加载配置文件并初始化连接池对象
- 提供方法
- 获取连接方法:通过数据库连接池获取连接
- 释放资源(关闭连接 )
- 获取连接池的方法
package cn.itcast.datasource.utils;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* Druid连接池的工具类
*/
public class JDBCUtils {
//1.定义一个成员变量 DataSource
private static DataSource ds;
static{
try {
//1.加载配置文件
Properties pro=new Properties();
pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
//2.获取DataSource
ds = DruidDataSourceFactory.createDataSource(pro);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取连接
*/
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
/**
* 释放资源
*/
public static void close(Statement stmt,Connection conn){
/*if (stmt!=null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn!=null){
try {
conn.close();//归还连接
} catch (SQLException e) {
e.printStackTrace();
}
}*/
//简化书写
close(null,stmt,conn);
}
//方法重载
public static void close(ResultSet rs,Statement stmt, Connection conn){
if (rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (stmt!=null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn!=null){
try {
conn.close();//归还连接
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 获取连接池方法
*/
public static DataSource getDataSource(){
return ds;
}
}package cn.itcast.datasource.druid;
import cn.itcast.datasource.utils.JDBCUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 使用新的工具类
*/
public class DruidDemo2 {
public static void main(String[] args) {
/**
* 完成添加的操作,给account表添加一条记录
*/
Connection conn=null;
PreparedStatement pstmt=null;
try {
//1.获取连接
conn = JDBCUtils.getConnection();
//2.定义sql
String sql="insert into account values(null,?,?)";
//3.获取pstmt对象
pstmt = conn.prepareStatement(sql);
//4.给?赋值
pstmt.setString(1,"王五");
pstmt.setDouble(2,3000);
int count = pstmt.executeUpdate();
System.out.println(count);
} catch (SQLException e) {
e.printStackTrace();
}finally {
//6.释放资源
JDBCUtils.close(pstmt,conn);
}
}
}
- 导入jar包
- 创建JDBCTemplate对象,该对象依赖于数据源DataSource
- 如:JDBCTemplate template =new JDBCTemplate(ds)
- 调用JDBCTemplat的方法来完成CRUD的操作(update和query)
- update()---执行DML语句,实现增删改语句
- queryForMap()--查询结果,将结果集封装为map集合
- 注意:结果集长度只能为1
- 将列名作为key,将值作为value,将这条记录封装为一个map集合
- queryForList()--查询结果,将结果集封装为list集合
- 将每一条记录封装为一个map集合,再将map集合封装为list集合
- query()--JavaBean查询结果,将结果集封装为JavaBean对象
- 需要的参数包括RowMapper接口,常使用其实现类BeanPropertyRowMapper,可以完成数据到javabean的自动封装
- new BeanPropertyRowMapper<类型>(类型.class)
- queryForObject()--对象查询结果,将结果集封装为对象
- 一般用于聚合函数的查询
package cn.itcast.datasource.jdbctemplate;
import cn.itcast.datasource.utils.JDBCUtils;
import org.springframework.jdbc.core.JdbcTemplate;
/**
* JDBCtemplate入门
*/
public class JdbcTemplateDemo1 {
public static void main(String[] args) {
//1.导入jar包
//2.创建JDBCTemplate对象
//ctrl+p查看参数
//jdbc资源的释放和申请操作由JDBCTemplate完成
JdbcTemplate template=new JdbcTemplate(JDBCUtils.getDataSource());
//3.调用方法
String sql="update account set balance =5000 where id=?";
int count = template.update(sql, 3);
System.out.println(count);
}
}- 修改1号数据的salary为10000
- 添加一条记录
- 删除刚才添加的记录
- 查询所有id为1的记录,将其封装为map集合
- 查询所有记录,将其封装为list集合
- 查询所有记录,将其 封装为 Emp对象的list集合
- 查询总的记录数(count')
package cn.itcast.jdbctemplate;
import cn.itcast.utils.JDBCUtils;
import org.junit.Test;
import org.springframework.jdbc.core.JdbcTemplate;
public class JdbcTemplateDemo2 {
//Junit单元测试,可以让方法独立执行
//1.获取JDBCtemplate对象
private JdbcTemplate template=new JdbcTemplate(JDBCUtils.getDataSource());
/**
* 修改1号数据的salary为10000
*/
@Test
public void test1(){
//2.定义sql
String sql="update emp set salary =10000 where id=1001";
//3.执行sql
int count = template.update(sql);
System.out.println(count);
}
/**
* 添加一条记录
*/
@Test
public void test2(){
String sql="insert into emp(id,ename,dept_id) values(?,?,?)";
int count = template.update(sql, 1015, "郭靖", 10);
System.out.println(count);
}
/**
* 删除刚才添加的记录
*/
@Test
public void test3(){
String sql="delete from emp where id=?";
int count = template.update(sql, 1015);
System.out.println(count);
}
} /**
* 查询所有id为1的记录,将其封装为map集合
*/
@Test
public void test4(){
String sql="select * from emp where id=?";
Map<String, Object> map = template.queryForMap(sql, 1001);
System.out.println(map);
//{id=1001, ename=孙悟空, job_id=4, mgr=1004, joindate=2000-12-17, salary=10000.00, bonus=null, dept_id=20}
}
/**
* 如果有多条记录
* 注意:此方法queryForMap结果集长度只能为1
*/
@Test
public void test5(){
String sql="select * from emp where id= ? or id= ?";
Map<String, Object> map = template.queryForMap(sql, 1001,1002);
System.out.println(map);
//{id=1001, ename=孙悟空, job_id=4, mgr=1004, joindate=2000-12-17, salary=10000.00, bonus=null, dept_id=20}
}
/**
* 查询所有记录,将其封装为list集合
*/
@Test
public void test6(){
String sql="select * from emp";
List<Map<String, Object>> list = template.queryForList(sql);
for (Map<String, Object> stringObjectMap : list) {
System.out.println(stringObjectMap);
}
}
/**
* 查询所有记录,将其封装为 Emp对象的list集合
*/
@Test
public void test7(){
String sql="select * from emp";
List<Emp> list = template.query(sql, new RowMapper<Emp>() {
@Nullable
@Override
public Emp mapRow(ResultSet rs, int i) throws SQLException {
Emp emp=new Emp();
int id = rs.getInt("id");
String ename = rs.getString("ename");
int job_id = rs.getInt("job_id");
int mgr = rs.getInt("mgr");
Date joindate = rs.getDate("joindate");
double salary = rs.getDouble("salary");
double bonus = rs.getDouble("bonus");
int dept_id = rs.getInt("dept_id");
emp.setId(id);
emp.setEname(ename);
emp.setJob_id(job_id);
emp.setMgr(mgr);
emp.setJoindate(joindate);
emp.setSalary(salary);
emp.setBonus(bonus);
emp.setDept_id(dept_id);
return emp;
}
});
for (Emp emp : list) {
System.out.println(emp);
}
}
/**
* 查询所有记录,将其封装为 Emp对象的list集合
* template已经提供了实现类
*/
@Test
public void test8(){
String sql="select * from emp";
List<Emp> list = template.query(sql,new BeanPropertyRowMapper<Emp>(Emp.class));
//提示空值不能转换为double,则需要修改javabean为引用数据类型
for (Emp emp : list) {
System.out.println(emp);
}
}
/**
* 查询总的记录数(count')
*/@Test
public void test9(){
String sql="select count(id) from emp";
Long total = template.queryForObject(sql, Long.class);//用于执行聚合函数
System.out.println(total);
}
}JavaEE Day06 JDBC连接池&JDBCTemplate的更多相关文章
- Java中JDBC连接池&JDBCTemplate
数据库连接池 概念:其实就是一个容器(集合),存放数据库连接的容器. 当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归 ...
- JavaWeb——JDBC连接池&JDBCTemplate
今日内容 1. 数据库连接池 2. Spring JDBC : JDBC Template 数据库连接池 1. 概念:其实就是一个容器(集合),存放数据库连接的容器. 当系统初始化好后,容器被创建,容 ...
- JDBC连接池&JDBCTemplate
今日内容 1. 数据库连接池 2. Spring JDBC : JDBC Template 数据库连接池 1. 概念:其实就是一个容器(集合),存放数据库连接的容器. 当系统初始化好后,容器被创建,容 ...
- 四大流行的jdbc连接池之C3P0篇
C3P0是一个开放源代码的JDBC连接池,它在lib目录中与Hibernate一起发布,包括了实现jdbc3和jdbc2扩展规范说明的Connection 和Statement 池的DataSourc ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(九)数据层优化-jdbc连接池简述、druid简介
日常啰嗦 终于回到既定轨道上了,这一篇讲讲数据库连接池的相关知识,线程池以后有机会再结合项目单独写篇文章(自己给自己挖坑,不知道什么时候能填上),从这一篇文章开始到本阶段结束的文章都会围绕数据库和da ...
- JDBC连接池-C池3P0连接
JDBC连接池-C3P0连接 c3p0连接池的学习英语好的看英文原版 c3p0 - JDBC3 Connection and Statement Pooling 使用c3p0连接池 三种方 ...
- JDBC连接池(三)DBCP连接池
JDBC连接池(三)DBCP连接池 在前面的随笔中提到 了 1.JDBC自定义连接池 2. C3P0连接池 今天将介绍DBCP连接池 第一步要导入jar包 (注意:mysql和mysql 驱动 ...
- JDBC连接池-自定义连接池
JDBC连接池 java JDBC连接中用到Connection 在每次对数据进行增删查改 都要 开启 .关闭 ,在实例开发项目中 ,浪费了很大的资源 ,以下是之前连接JDBC的案例 pack ...
- Jmeter(九)JDBC连接池
JDBC为java访问数据库提供通用的API,可以为多种关系数据库提供统一访问.因为SQL是关系式数据库管理系统的标准语言,只要我们遵循SQL规范,那么我们写的代码既可以访问MySQL又可以访问SQL ...
- jdbc连接池&改进dbUtil成C3P0Util
一.jdbc连接池 1.连接池的存在理由 前面介绍的dbUtils工具类虽然实现了一个对jdbc的简单封装.但它依旧采取从驱动管理获取连接 (DriverManager.getConnection ...
随机推荐
- Kubernetes HPA 使用详解
文章转载自:https://www.qikqiak.com/post/k8s-hpa-usage/ Kubernetes 提供了这样的一个资源对象:Horizontal Pod Autoscaling ...
- R语言、02 案例2-1 Pelican商店、《商务与经济统计》案例题
编程教材 <R语言实战·第2版>Robert I. Kabacoff 课程教材<商务与经济统计·原书第13版> (安德森) P48.案例2-1 Pelican 商店 PS C: ...
- 「国产系统」Tubian 0.1,兼容Windows和Android的GNU/Linux系统!
Tubian 0.42已发布:https://www.cnblogs.com/tubentubentu/p/16745926.html Tubian是我的自用系统整理而成的Linux发行版,基于Deb ...
- Codeforces Round #823 (Div. 2) A-D
比赛链接 A 题解 知识点:贪心. 对于一个轨道,要么一次性清理,要么一个一个清理.显然,如果行星个数大于直接清理的花费,那么选择直接清理,否则一个一个清理.即 \(\sum \min (c,cnt[ ...
- 学习ASP.NET Core Blazor编程系列六——初始化数据
学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应用程序(上) 学习ASP.NET Core Blazor编程系 ...
- React魔法堂:echarts-for-react源码略读
前言 在当前工业4.0和智能制造的产业升级浪潮当中,智慧大屏无疑是展示企业IT成果的最有效方式之一.然而其背后怎么能缺少ECharts的身影呢?对于React应用而言,直接使用ECharts并不是最高 ...
- 华为设备配置和使用FTP服务命令
配置SFTP Server与Client server:aaa 进入aaa视图 local-user huawei2 password cipher huawei2 设置用户名和密码 local-us ...
- python基础作业2
目录 编写一个用户认证装饰器 利用有参装饰器编写多种用户登录校验策略 利用递归函数依次打印列表中每一个数据值 获取用户权限并校验用户登录 编写一个用户认证装饰器 """ ...
- 基于vite3+tauri模拟QQ登录切换窗体|Tauri自定义拖拽|最小/大/关闭
前两天有给大家分享tauri+vue3快速搭建项目.封装桌面端多开窗口.今天继续来分享tauri创建启动窗口.登录窗口切换到主窗口及自定义拖拽区域的一些知识.希望对想要学习或正在学习的小伙伴有些帮助. ...
- 题解 P6745 『MdOI R3』Number
前言 不知道是不是正解但是觉得挺好理解. 科学计数法 将一个数表示为\(a\times 10^x\) 的形式.其中\(a\leq10\),\(x\) 为整数. \(\sf Solution\) 其实这 ...