分库分表ShardingSphere-JDBC笔记整理
一、分库分表解决的现状问题
解决数据库本身瓶颈
连接数: 连接数过多时,就会出现‘too many connections’的错误,访问量太大或者数据库设置的最大连接数太小的原因
Mysql默认的最大连接数为100.可以修改,而mysql服务允许的最大连接数为16384
数据库分表可以解决单表海量数据的查询性能问题
数据库分库可以解决单台数据库的并发访问压力问题
解决系统本身IO、CPU瓶颈
- 磁盘读写IO瓶颈,热点数据太多,尽管使用了数据库本身缓存,但是依旧有大量IO,导致sql执行速度慢
- 网络IO瓶颈,请求的数据太多,数据传输大,网络带宽不够,链路响应时间变长
- CPU瓶颈,尤其在基础数据量大单机复杂SQL计算,SQL语句执行占用CPU使用率高,也有扫描行数大、锁冲突、锁等待等原因
- 可以通过 show processlist; 、show full processlist,发现 CPU 使用率比较高的SQL
- 常见的对于查询时间长,State 列值是 Sending data,Copying to tmp table,Copying to tmp table on disk,Sorting result,Using filesort 等都是可能有性能问题SQL,清楚相关影响问题的情况可以kill掉
- 也存在执行时间短,但是CPU占用率高的SQL,通过上面命令查询不到,这个时候最好通过执行计划分析explain进行分析
二、垂直和水平分库分表区别
- 垂直角度(表结构不一样)
- 垂直分表: 将一个表字段拆分多个表,每个表存储部分字段
- 好处: 避免IO时锁表的次数,分离热点字段和非热点字段,避免大字段IO导致性能下降
- 原则:业务经常组合查询的字段一个表;不常用字段一个表;text、blob类型字段作为附属表
- 垂直分库:根据业务将表分类,放到不同的数据库服务器上
- 好处:避免表之间竞争同个物理机的资源,比如CPU/内存/硬盘/网络IO
- 原则:根据业务相关性进行划分,领域模型,微服务划分一般就是垂直分库
- 垂直分表: 将一个表字段拆分多个表,每个表存储部分字段
- 水平角度(表结构一样)
- 水平分库:把同个表的数据按照一定规则分到不同的数据库中,数据库在不同的服务器上
- 好处: 多个数据库,降低了系统的IO和CPU压力
- 原则
- 选择合适的分片键和分片策略,和业务场景配合
- 避免数据热点和访问不均衡、避免二次扩容难度大
- 水平分表:同个数据库内,把一个表的数据按照一定规则拆分到多个表中,对数据进行拆分,不影响表结构
- 单个表的数据量少了,业务SQL执行效率高,降低了系统的IO和CPU压力
- 原则
- 选择合适的分片键和分片策略,和业务场景配合
- 避免数据热点和访问不均衡、避免二次扩容难度大
- 水平分库:把同个表的数据按照一定规则分到不同的数据库中,数据库在不同的服务器上
2.1垂直分表
也就是“大表拆小表”,基于列字段进行的
拆分原则一般是表中的字段较多,将不常用的或者数据较大,长度较长的拆分到“扩展表 如text类型字段
访问频次低、字段大的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中
垂直拆分原则
把不常用的字段单独放在一张表;
把text,blob等大字段拆分出来放在附表中;
业务经常组合查询的列放在一张表中
2.2垂直分库
- 垂直分库针对的是一个系统中的不同业务进行拆分, 数据库的连接资源比较宝贵且单机处理能力也有限
- 没拆分之前全部都是落到单一的库上的,单库处理能力成为瓶颈,还有磁盘空间,内存,tps等限制
- 拆分之后,避免不同库竞争同一个物理机的CPU、内存、网络IO、磁盘,所以在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈
- 垂直分库可以更好解决业务层面的耦合,业务清晰,且方便管理和维护
- 一般从单体项目升级改造为微服务项目,就是垂直分库
2.3水平分表
把一个表的数据分到一个数据库的多张表中,每个表只有这个表的部分数据
核心是把一个大表,分割N个小表,每个表的结构是一样的,数据不一样,全部表的数据合起来就是全部数据
针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去
但是这些表还是在同一个库中,所以单数据库操作还是有IO瓶颈,主要是解决单表数据量过大的问题
减少锁表时间,没分表前,如果是DDL(create/alter/add等)语句,当需要添加一列的时候mysql会锁表,期间所有的读写操作只能等待
2.4水平分库
- 把同个表的数据按照一定规则分到不同的数据库中,数据库在不同的服务器上
- 水平分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构
- 每个库的结构都一样,但每个库的数据都不一样,没有交集,所有库的并集就是全量数据
- 水平分库的粒度,比水平分表更大
三、水平分库分表常见策略
3.1 Range
范围角度思考问题 (范围的话更多是水平分表)
数字
- 自增id范围
时间
- 年、月、日范围
- 比如按照月份生成 库或表 pay_log_2022_01、pay_log_2022_02
空间
地理位置:省份、区域(华东、华北、华南)
比如按照 省份 生成 库或表
例如:自增id,根据ID范围进行分表(左闭右开)
- 规则案例
- 1~1,000,000 是 table_1
- 1,000,000 ~2,000,000 是 table_2
- 2,000,000~3,000,000 是 table_3
- ...更多
- 优点
- id是自增长,可以无限增长
- 扩容不用迁移数据,容易理解和维护
- 缺点
- 大部分读和写都访会问新的数据,有IO瓶颈,整体资源利用率低
- 数据倾斜严重,热点数据过于集中,部分节点有瓶颈
基于Range范围分库分表业务场景
- 微博发送记录、微信消息记录、日志记录,id增长/时间分区都行
- 水平分表为主,水平分库则容易造成资源的浪费
- 网站签到等活动流水数据时间分区最好
- 水平分表为主,水平分库则容易造成资源的浪费
- 大区划分(一二线城市和五六线城市活跃度不一样,如果能避免热点问题,即可选择)
- saas业务水平分库(华东、华南、华北等)
3.2Hash取模
hash取模(Hash分库分表是最普遍的方案)
如果取模的字段不是整数型要先hash,统一规则就行
案例规则
- 用户ID是整数型的,要分2库,每个库表数量4表,一共8张表
- 用户ID取模后,值是0到7的要平均分配到每张表
A库ID = userId % 库数量 2
表ID = userId / 库数量 2 % 表数量4
- 优点
- 保证数据较均匀的分散落在不同的库、表中,可以有效的避免热点数据集中问题,
- 缺点
- 扩容不是很方便,需要数据迁移
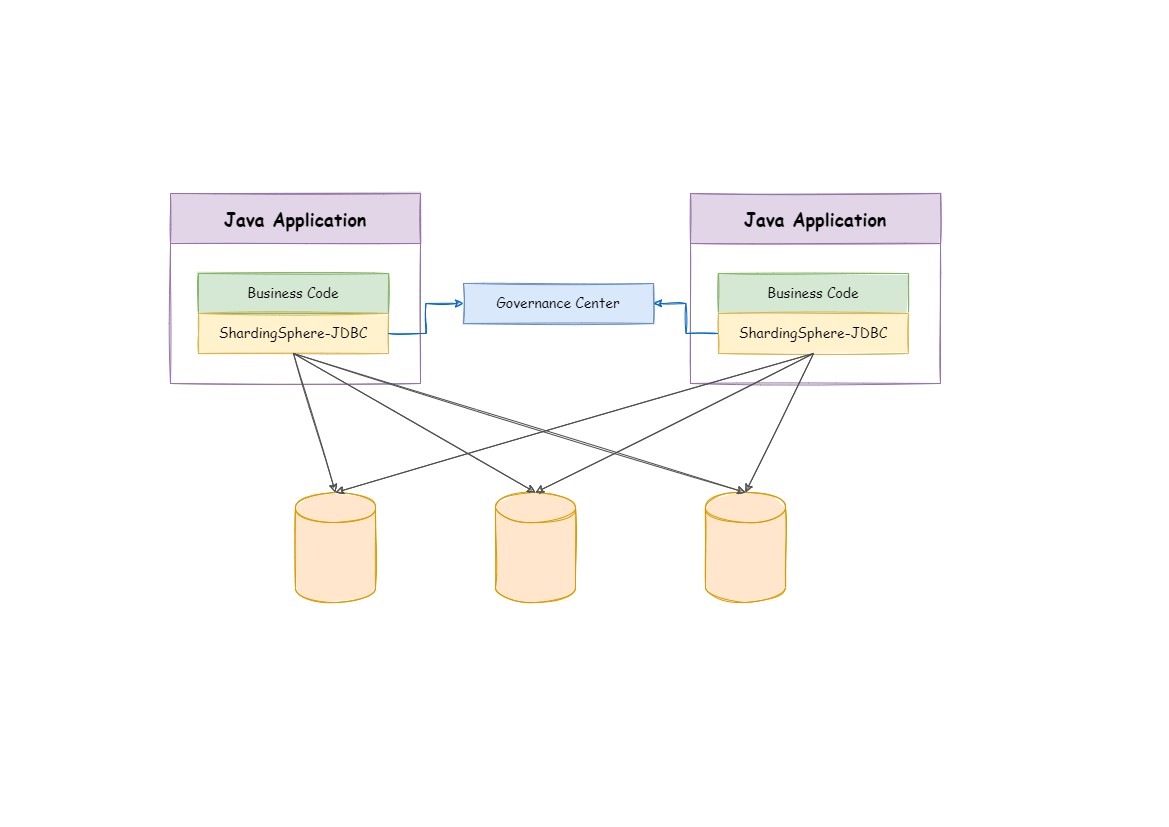
四、实现方案ShardingSphere-JDBC
Sharding-JDBC
基于jdbc驱动,不用额外的proxy,支持任意实现 JDBC 规范的数据库
它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖
可理解为加强版的 JDBC 驱动,兼容 JDBC 和各类 ORM 框架
它使用客户端直连数据库,以 jar 包形式提供服务
无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架
适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis,或直接使用 JDBC
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库
采用无中心化架构,与应用程序共享资源,适用于 Java 开发的高性能的轻量级 OLTP 应用
4.1常见概念术语讲解
- 数据节点Node
- 数据分片的最小单元,由数据源名称和数据表组成
- 比如:ds_0.product_order_0
- 真实表
- 在分片的数据库中真实存在的物理表
- 比如订单表 product_order_0、product_order_1、product_order_2
- 逻辑表
- 水平拆分的数据库(表)的相同逻辑和数据结构表的总称
- 比如订单表 product_order_0、product_order_1、product_order_2,逻辑表就是product_order
- 绑定表
- 指分片规则一致的主表和子表
- 比如product_order表和product_order_item表,均按照order_id分片,则此两张表互为绑定表关系
- 绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
- 广播表
- 指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致
- 适用于数据量不大且需要与海量数据的表进行关联查询的场景
- 例如:字典表、配置表
4.2常见分片算法讲解
分片算法包括两部分:包含分片键和分片策略
分片键 (PartitionKey)
- 用于分片的数据库字段,是将数据库(表)水平拆分的关键字段
- 比如prouduct_order订单表,根据订单号 out_trade_no做哈希取模,则out_trade_no是分片键
- 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片
分片策略
行表达式分片策略 InlineShardingStrategy(必备)
只支持【单分片键】使用Groovy的表达式,提供对SQL语句中的 =和IN 的分片操作支持
可以通过简单的配置使用,无需自定义分片算法,从而避免繁琐的Java代码开发
prouduct_order_$->{user_id % 8}` 表示订单表根据user_id模8,而分成8张表,表名称为`prouduct_order_0`到`prouduct_order_7
标准分片策略StandardShardingStrategy(需了解)
- 只支持【单分片键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法
- PreciseShardingAlgorithm 精准分片 是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm 范围分配 是可选的,用于处理BETWEEN AND分片
- 如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降
复合分片策略ComplexShardingStrategy(需了解)
- 支持【多分片键】,多分片键之间的关系复杂,由开发者自己实现,提供最大的灵活度
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
Hint分片策略HintShardingStrategy(需了解)
这种分片策略无需配置分片健,分片健值也不再从 SQL中解析,外部手动指定分片健或分片库,让 SQL在指定的分库、分表中执行
用于处理使用Hint行分片的场景,通过Hint而非SQL解析的方式分片的策略
Hint策略会绕过SQL解析的,对于这些比较复杂的需要分片的查询,Hint分片策略性能可能会更好
不分片策略 NoneShardingStrategy(需了解)
- 不分片的策略。
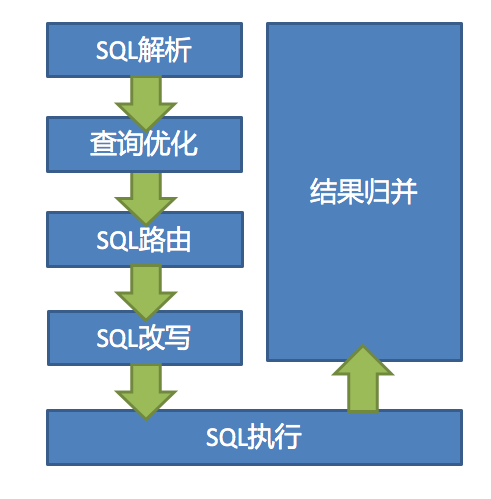
4.3执行流程原理
执行过程为:SQL解析 -> SQL优化 -> SQL路由 -> SQL改写 -> SQL执行 -> 结果归并 ->返回结果
分库分表ShardingSphere-JDBC笔记整理的更多相关文章
- mysql 分库分表 ~ ShardingSphere生态圈
一 简介 Apache ShardingSphere是一款开源的分布式数据库中间件组成的生态圈二 成员包含 Sharding-JDBC是一款轻量级的Java框架,在JDBC层提供上述核心功能 ...
- spring boot:用shardingjdbc实现多数据源的分库分表(shardingsphere 4.1.1/spring boot 2.3.1)
一,shardingjdbc的用途 1,官方站介绍: Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈, 它由 JDBC.Proxy 和 Sidecar( ...
- 基于ShardingJDBC的分库分表及读写分离整理
ShardingJDBC的核心流程主要分成六个步骤,分别是:SQL解析->SQL优化->SQL路由->SQL改写->SQL执行->结果归并,流程图如下: sharding ...
- 分库分表利器——sharding-sphere
背景 得不到的东西让你彻夜难眠,没有尝试过的技术让我跃跃欲试. 本着杀鸡焉用牛刀的准则,我们倡导够用就行,不跟风,不盲从. 所以,结果就是我们一直没有真正使用分库分表.曾经好几次,感觉没有分库分表(起 ...
- 分库分表(3) ---SpringBoot + ShardingSphere 实现读写分离
分库分表(3)---ShardingSphere实现读写分离 有关ShardingSphere概念前面写了两篇博客: 1.分库分表(1) --- 理论 2. 分库分表(2) --- ShardingS ...
- 分库分表(4) ---SpringBoot + ShardingSphere 实现分表
分库分表(4)--- ShardingSphere实现分表 有关分库分表前面写了三篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3.分库 ...
- 分库分表(5) ---SpringBoot + ShardingSphere 实现分库分表
分库分表(5)--- ShardingSphere实现分库分表 有关分库分表前面写了四篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3. ...
- 分库分表(6)--- SpringBoot+ShardingSphere实现分表+ 读写分离
分库分表(6)--- ShardingSphere实现分表+ 读写分离 有关分库分表前面写了五篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论 ...
- Springboot2.x + ShardingSphere 实现分库分表
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程. 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用. 在拆分之前 ...
随机推荐
- 论文阅读 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks
6 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks link:https://arxiv.org/ab ...
- 【网站】windows phpstudy v8.1搭建https
这两天在搭建微擎,使用了官方推荐的一键安装环境,在搭建完站点后,想开启https. 发现如下图所示,无论关闭网站,还是关闭nginx.都无法建立https.网上也找不到相关流程,后来试着关闭nginx ...
- 从单例谈double-check必要性,多种单例各取所需
theme: fancy 前言 前面铺掉了那么多都是在讲原则,讲图例.很多同学可能都觉得和设计模式不是很搭边.虽说设计模式也是理论的东西,但是设计原则可能对我们理解而言更加的抽象.不过好在原则东西不是 ...
- 高度灵活可定制的PC布局:头部按钮、左边栏、右边栏、状态栏
什么是自适应布局 CabloyJS提供了一套布局管理器,实现自适应布局 关于自适应布局的概念,强烈建议先阅读以下两篇文章: 自适应布局:pc = mobile + pad 自适应布局:视图尺寸 什么是 ...
- 代码调用Rally的接口介绍
1. 支持的语言 2. 创建APIKey 3. GetRequest 4. QueryRequest 5. CreateRequest 6. 参考资料 本文链接: https://www.cnblog ...
- 聊聊 C# 和 C++ 中的 泛型模板 底层玩法
最近在看 C++ 的方法和类模板,我就在想 C# 中也是有这个概念的,不过叫法不一样,人家叫模板,我们叫泛型,哈哈,有点意思,这一篇我们来聊聊它们底层是怎么玩的? 一:C++ 中的模板玩法 毕竟 C+ ...
- .Net Core 企业微信更新模版卡片消息
1.搭建回调服务器 可参考:https://www.cnblogs.com/zspwf/p/16381643.html进行搭建 2.编写代码 2.1接口定义 应用可以发送模板卡片消息,发送之后可再通过 ...
- Xshell缺失mfc110u.dll文件解决方案(有下载链接)
解决方案 把下面两个文件都下载安装就可以了. 1.vcredist_x86.exe链接: https://pan.baidu.com/s/1njbNHdjqH6x34GQvj4BTBg提取码: pwq ...
- SAP -熟练使用T-Code SHD0
SHD0 业务顾问和开发顾问都非常熟悉的一个T-Code, 如果能合理使用它,可以省去许多增强和程序修改工作. 当我需要时,我在这里找不到任何相关文档,这就是为什么我想借此机会向我们自己的SCN提供内 ...
- Elasticsearch学习系列四(聚合搜索)
聚合分析 聚合分析是数据库中重要的功能特性,完成对一个查询的集中数据的聚合计算.如:最大值.最小值.求和.平均值等等.对一个数据集求和,算最大最小值等等,在ES中称为指标聚合,而对数据做类似关系型数据 ...