RocketMQ 详解系列
什么是RocketMQ
RocketMQ作为一款纯java、分布式、队列模型的开源消息中间件,支持事务消息、顺序消息、批量消息、定时消息、消息回溯等。主要功能是异步解耦和流量削峰:。
常见的MQ主要有:ActiveMQ、RabbitMQ、Kafka、RocketMQ
四种消息中间件的基本介绍:
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比RocketMQ和Kafka第一个级别 | 同ActiveMQ | 10万级,支撑高吞吐 | 10万级,高吞吐,一般配合大数据类的系统进行实时数据计算、日志采集等场景 |
| topic数量对吞吐量的影响 | topic可以达到几百/几千级别,吞吐量会有较小幅度的下降,这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic | topic从几十到几百时,吞吐量会大幅度下降,在同等机器下,kafka尽量保证topic数量不要过多,如果要支撑大规模的topic,需要增加更多的机器资源 | ||
| 时效性 | ms级 | 微秒级别,RabbitMQ的特性,延迟最低 | ms级别 | 延迟在ms级别以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同ActiveMQ | 非常高,分布式架构 | 非常高,分布式一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到0丢失 | 经过参数优化配置,可以做到0丢失 |
| 功能支持 | MQ领域的功能机器完备 | 基于erlang开发,并发能力很强,性能极好,延时很低 | MQ功能较为完善,基本分布式,扩展性好 | 功能较简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用 |
| 其他 | Apache开发,起步早,没有经过高吞吐场景验证,社区不活跃 | 开源、稳定、社区活跃度高 | 阿里开源,交给Apache,社区活跃度低 | Apache开发,开源、高吞吐量、社区活跃度高 |
消息中间件的使用场景:
异步与解耦:
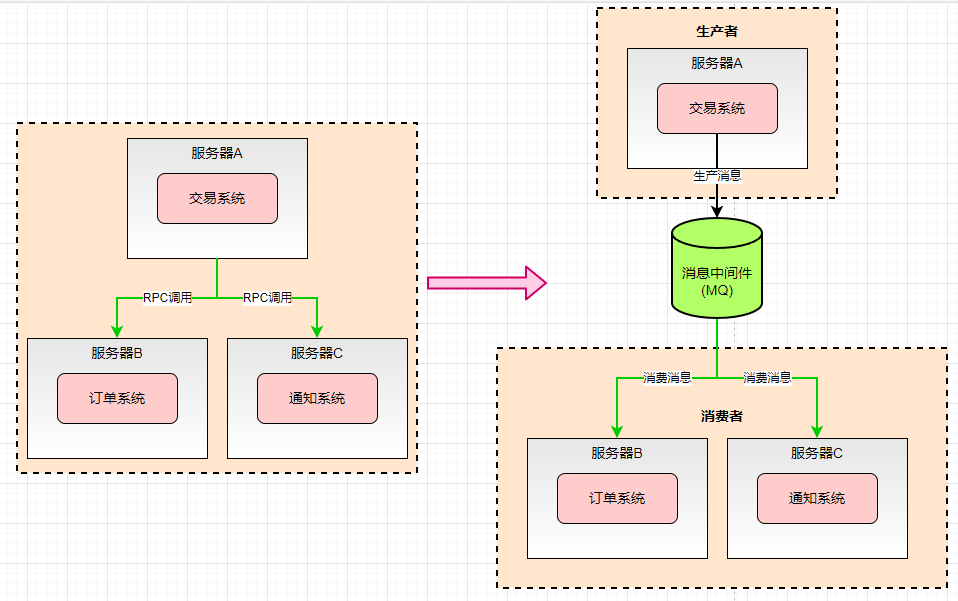
当我们下了一个订单之后,订单系统会进行RPC同步调用 支付系统、库存系统、物流系统等,那么系统之间就会有耦合性,耦合性越高的话,容错性就越低,比如我们的支付系统如果宕机了,就会导致我们整个交易的异常,从而影响用户的体验。
如果我们中间加入了消息中间件,不管是支付还是库存等系统,都是通过异步的方式进行调用的,如果其中一个系统宕机了,不会影响我们用户下单的使用。
本质上MQ第一步完成了 异步 ,第二步完成了 解耦 。那么系统的容错性就越高。
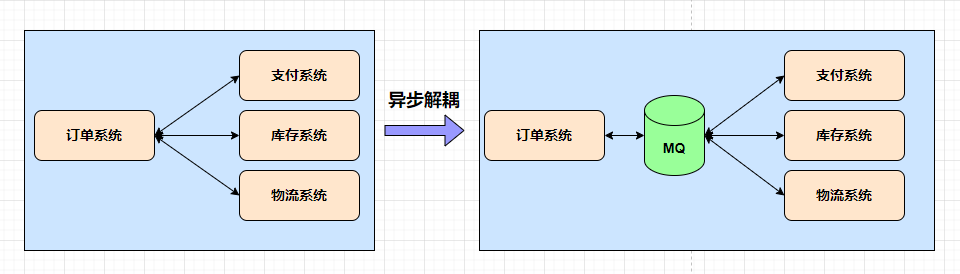
流量削峰:
流量削峰也可以叫削峰填谷,比如一些互联网公司大促场景,双十一、店庆或者秒杀活动,都会使用到消息中间件。
如果在不使用消息中间件或者没有流量削峰,每秒是很高的并发,这个时候如果我们的A系统,如果要将数据写入到我们的MYSQL中,受限于MYSQL本身服务的上限,最大我们只能每秒处理200请求,这个时候会有大量的消息进行堆积,从而导致A系统的奔溃。
这个时候我们可以将用户的请求消息通过MQ进行写入,因为消息中间件本身是对数据量处理比较高的一个系统,所以对于每秒2000请求,消息中间件可以处理,然后A系统作为消息中间件的一个消费者,以固定的速度从MQ中拉取200个消息,完成我们的业务操作,用时间换空间 从而确保我们A系统的稳定性。
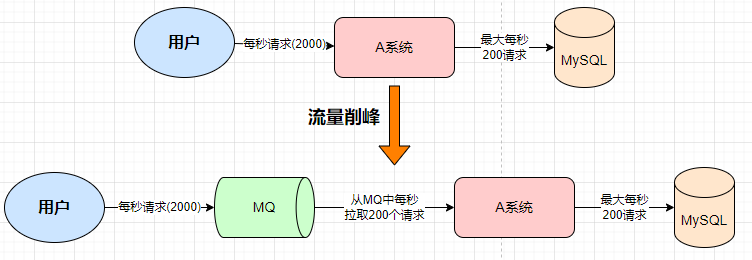
数据分发:
如果S系统,在对系统进行开发的时候,需要对接多个(A、B、C、D)系统,使用传统的接口调用,中间有改动就需要修改我们的代码,当新增了A系统,我们需要去修改代码去调用A系统来完成对应的业务逻辑,如果我们当中的D系统需要移除, 同样也需要修改代码删除对应的接口调用。
如果S系统使用了消息中间件,我们S系统只要将消息交给MQ,剩下的不论是新增还是移除,还是原有的,他们都只是消息中间件的一个消费者,这个时候我们就便于数据的分发。
比如我们新增一个系统,我们只需要新增一个MQ的消费者,直接从MQ里面拿消息就可以,当我们需要移除一个系统的时候,只需要取消对MQ消息的监听即可。对于我们原有的S系统不需要进行额外的修改。如果使用MQ作为数据分发,减少数据的修改,提高开发的效率。
RocketMQ 基本概念
RocketMQ主要有四大核心组成部分:NameServer、Broker、Producer以及Consumer四部分。这些角色通常以集群的方式存在,RocketMQ 基于纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。
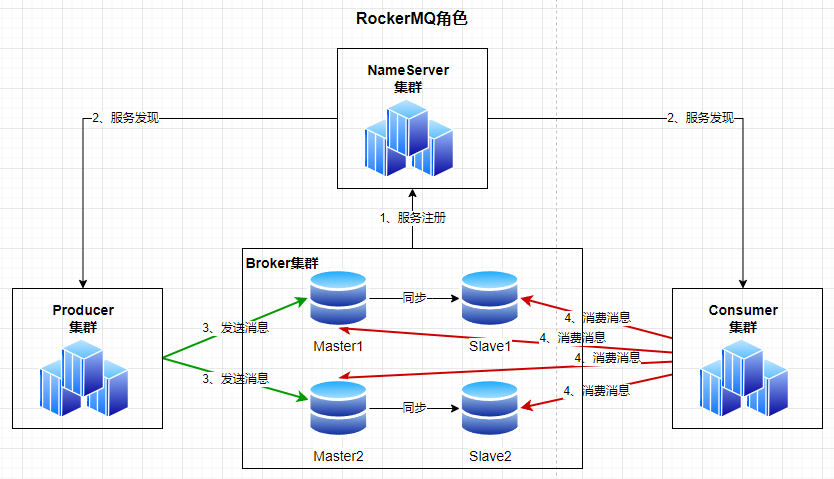
对于 RockerMQ 而言,我们想要启动,必须首先启动 NameServer,在启动 Brober 主机, Brober 会向 NameServer 注册对应的路由和服务(Broker 地址、主体和),Producer会进行路由的发现,向NameServer请求Broker路由信息,进行消息的发送。
作为Consumer要连通NameServer,获取到相关的路由信息,方便我们进行消息的订阅。
Broker 也是一个很重要的角色,主要负责消息的存储,不管是生产消息还是订阅消息,消息的来源都是 Broker,一般来说消息的发送(Producer)只会发到主节点,然后Broker会进行消息的同步,同步到从节点,作为消费者(Consumer)也只会优先从Master节点,获取消息,进行消费,除非主节点不可用或者非常繁忙,才会从从节点进行消费,Broker除了消息的中转,还负责消息的持久化以及主从数据之间的复制
NameServer:
NameServer 是一个服务与注册的发现中心。也是整个 RocketMQ 的“大脑”,所以 RocketMQ 需要先启动 NameServer 再启动 RocketMQ 中的 Broker
NameServer 是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。NameServer底层由 Netty 实现,是内存式存储,所以 NameServer 中的 broker、topic不会持久化。
NameServer 其角色类似Dubbo和zookeeper,主要负责Broker的动态注册与发现。为什么不使用zookeeper?rocketmq主要是在分布式情况下使用追求性能,因为zookeeper最求最终一致性,所以在性能上会有所折扣。
Broker:
消息服务器(Broker)是消息存储中心,主要作用是接收来自 Producer 的消息并存储,Consumer 从这里取得消息。存储与消息相关的元数据,包括用户组、消费进度偏移量、队列信息等。从部署结构图中可以看出 Broker 有 Master 和 Slave 两种类型, Master 既可以写又可以读,Slave 不可以写只可以读。
Producer:
Producer 也称为消息发布者(生产者),负责生产并发送消息至 Topic。生产者向 broker 发送由业务应用程序系统生成的消息。RocketMQ 提供了发送:同步、异步和单向(one-way)的多种范例。
Consumer:
也称为消息订阅者,负责从 Topic 接收并消费消息。消费者从 brokers 那里拉取信息并将其输入应用程序。从Master拿到消息,执行完成后,会发送一个消息给Broker进行确认,这个就是ACK确认
RocketMQ 基本概念
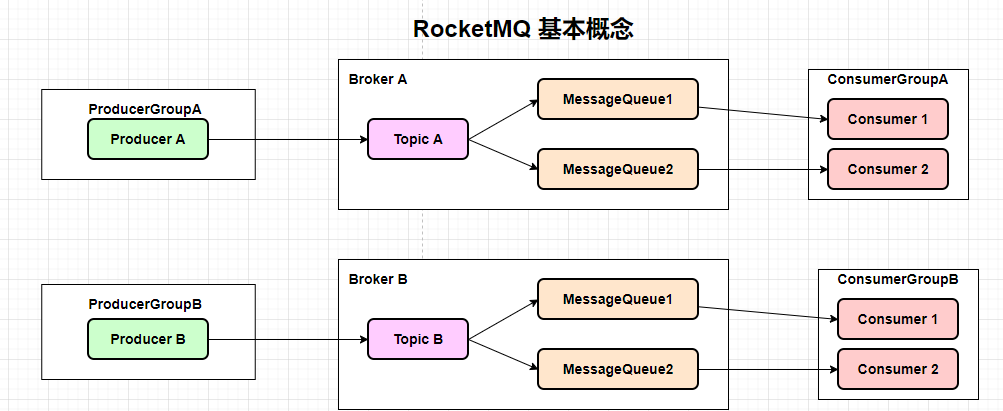
分组(Group)
Group 分为两个部分 生产者和消费者
生产者: 表示发送同一类消息的 Producer,通常情况下发送逻辑是一致的。发送普通消息时,用于标识使用,没有特别的用处。
主要用来作用于事务消息,当事务消息中某条消息一直处于等待状态并超时,Broker会回查同一个Group下的其他producer,确定该消息是 commit 还是 rollback
消费者: 消费者的分组就非常有意义了,消费者是标识一类
Consumer的集合名称,这类Consumer通常消费一类消息,且消费逻辑一致。同一个Consumer Group下的各个实例将共同消费 topic 的消息,起到负载均衡的作用。消费进度以
Consumer Group为粒度管理,不同Consumer Group之间消费进度彼此不受影响,即消息 A 被Consumer Group1消费过,也会再给Consumer Group2消费。
主体(Topic)
用来区分消息的种类,表示一类消息的逻辑名字,消息的逻辑管理单位,无论生产还是消费消息,都需要执行Topic。
一个发送者可以发送消息给一个或者多个Topic;
一个消息接受者可以订阅一个或多个Topic消息;
消息队列(Message Queue)
消息队列 简称 Queue ,消息物理管理单位。用来并行发送和接收消息,相当于是Topic的分区。
一个Topic会有若干个Queue,消息的生产一般会比消息消费的速度要快,消息进行消费的时会有对应的业务逻辑进行处理,这个时候就会降低消息消费的速度。所有一般Topic会有若干个Queue。主要用来解决生产很快,消费很慢。
如果同一个Topic创建在不同的Broker,那么不同的Broker有不同的Queue,将物理存储在不同的Broker节点之上,具有水平扩展的能力。无论是生产者还是消费者,实际的操作都是针对Queue级别。
标签(Tag)
RocketMQ 支持在发送时给 topic 的消息设置 tag,用于同一主题下区分不同类型的消息。
来自同一业务单元的消息,可以根据不同业务目的在同一主题下设置不同标签。比如有一个 Topic 消息为水果,那么水果可以有其他的标签 可以是 香蕉、西瓜、草莓等等,我们可以把对应的消息,打上对应的标签(Tag),这个就是方便我们在消费的时候做对应的筛选。
标签能够有效地保持代码的清晰度和连贯性,并优化 RocketMQ 提供的查询系统。消费者可以根据Tag实现对不同子主题的不同消费逻辑,实现更好的扩展性。
偏移量(Offset)
在 RocketMQ 中,有很多 offset 的概念。一般我们只关心暴露到客户端的 offset。不指定的话,一般指的是消费者消息的偏移量(ConsumerOffset)
Message queue 是无限长的数组。一条消息进来下标就会涨 1,而这个数组的下标就是 offset。
Message queue 中的 max offset 表示消息的最大 offset,Consumer offset 可以理解为标记 Consumer Group 在一条逻辑 Message Queue 上,消息消费到哪里即消费进度。
RocketMQ 下载安装
下载地址:https://rocketmq.apache.org/dowloading/releases/

环境要求:
- Windows/Linux 64位系统
- JDK1.8(64位)
- 源码安装需要安装Maven 3.2.x
这里我们用 rocketmq-4.9.2 来做演示案例。
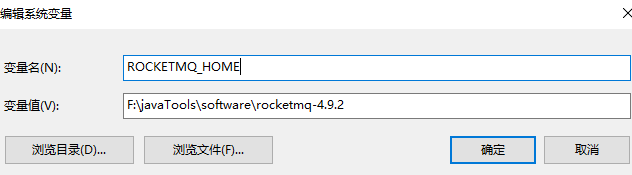
设置环境变量:
变量名: ROCKETMQ_HOME
变量值: MQ解压路径\MQ文件夹名
启动
在rocketmq-4.9.2\bin目录下,打开cmd窗口
先启动 nameServer,启动命令:start mqnamesrv.cmd
然后在启动 Broker,启动命令:start mqbroker.cmd -n 127.0.0.1:7906 autoCreateTopicEnable=true
管理端插件安装:
老版本地址下载:https://codeload.github.com/apache/rocketmq-externals/zip/master
新版本地址:https://github.com/apache/rocketmq-dashboard
启动完成之后,浏览器中输入‘127.0.0.1:8089’,成功后即可进行管理端查看。
消息发送
RocketMQ提供的原生客户端的API,当然除了原生客户端外,SpringBoot、SpringCloudStream也进行了集成,但本质上这些也是基于原生API的封装,所以只需掌握原生API,其他的也会水到渠成。
导入MQ客户端依赖
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.9.2</version>
</dependency>
消息发送:
/**
* 同步发送
*/
public class SyncProducer {
public static void main(String[] args) throws Exception{
// 实例化消息生产者Producer
DefaultMQProducer producer = new DefaultMQProducer("group_test");
// 设置NameServer的地址
producer.setNamesrvAddr("127.0.0.1:9876");
//producer.setSendLatencyFaultEnable(true);
// 启动Producer实例
producer.start();
for (int i = 0; i < 10; i++) {
// 创建消息,并指定Topic,Tag和消息体
Message msg = new Message("TopicTest" /* Topic */,
"TagA" /* Tag */,
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */
);
// 发送消息到一个Broker
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
//如果不再发送消息,关闭Producer实例。
producer.shutdown();
}
}
总结
这篇主要是带大家了解RocketMQ的基本原理和介绍,在后面的章节中,会带大家深入了解和使用RocketMQ,如果觉得文章有帮助的,记得点赞关注,您的支持是我创作的最大动力。
怕什么真理无穷,进一步有进一步的欢喜,大家加油!
RocketMQ 详解系列的更多相关文章
- RocketMQ详解(一)原理概览
专题目录 RocketMQ详解(一)原理概览 RocketMQ详解(二)安装使用详解 RocketMQ详解(三)启动运行原理 RocketMQ详解(四)核心设计原理 RocketMQ详解(五)总结提高 ...
- RocketMQ详解(四)核心设计原理
专题目录 RocketMQ详解(一)原理概览 RocketMQ详解(二)安装使用详解 RocketMQ详解(三)启动运行原理 RocketMQ详解(四)核心设计原理 RocketMQ详解(五)总结提高 ...
- JDBC详解系列(二)之加载驱动
---[来自我的CSDN博客](http://blog.csdn.net/weixin_37139197/article/details/78838091)--- 在JDBC详解系列(一)之流程中 ...
- JDBC详解系列(三)之建立连接(DriverManager.getConnection)
在JDBC详解系列(一)之流程中,我将数据库的连接分解成了六个步骤. JDBC流程: 第一步:加载Driver类,注册数据库驱动: 第二步:通过DriverManager,使用url,用户名和密码 ...
- Android高效率编码-第三方SDK详解系列(三)——JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送
Android高效率编码-第三方SDK详解系列(三)--JPush推送牵扯出来的江湖恩怨,XMPP实现推送,自定义客户端推送 很久没有更新第三方SDK这个系列了,所以更新一下这几天工作中使用到的推送, ...
- Android高效率编码-第三方SDK详解系列(二)——Bmob后端云开发,实现登录注册,更改资料,修改密码,邮箱验证,上传,下载,推送消息,缩略图加载等功能
Android高效率编码-第三方SDK详解系列(二)--Bmob后端云开发,实现登录注册,更改资料,修改密码,邮箱验证,上传,下载,推送消息,缩略图加载等功能 我的本意是第二篇写Mob的shareSD ...
- Android高效率编码-第三方SDK详解系列(一)——百度地图,绘制,覆盖物,导航,定位,细腻分解!
Android高效率编码-第三方SDK详解系列(一)--百度地图,绘制,覆盖物,导航,定位,细腻分解! 这是一个系列,但是我也不确定具体会更新多少期,最近很忙,主要还是效率的问题,所以一些有效的东西还 ...
- Android中的动画详解系列【4】——Activity之间切换动画
前面介绍了Android中的逐帧动画和补间动画,并实现了简单的自定义动画,这一篇我们来看看如何将Android中的动画运用到实际开发中的一个场景--Activity之间跳转动画. 一.定义动画资源 如 ...
- 源码详解系列(六) ------ 全面讲解druid的使用和源码
简介 druid是用于创建和管理连接,利用"池"的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制.连接可靠性测试.连接泄露控制.缓存语句等功能,另外,druid还扩展 ...
随机推荐
- MySQL - 数据库的隔离级别
MySQL - 数据库的隔离级别 隔离级别 脏读(Dirty Read) 不可重复读(NonRepeatable Read) 幻读(Phantom Read) 未提交读(Read uncommitte ...
- Markdown常见基本语法
标题 -方式一:使用警号 几个警号就是几级标题,eg: # 一级标题 -方式二: 使用快捷键 ctrl+数字 几级标题就选其对应的数字, eg: ctrl+2(二级标题) 子标题 -方式一: 使用星号 ...
- BUUCTF-你竟然赶我走
你竟然赶我走 首先看到这个图片没啥感觉,直接用16进制打开了.拖到最下面果然有flag flag{stego_is_s0_bor1ing}
- SAP SD-Invoice 销售发票
针对销售订单的发票流程: 1. 事务码:VF01(个别生成系统发票) 创建开票凭证(发票)/ VF04 开具系统发票(可把多个item 合并成一张系统发票) 2. 事务码:VF02 修改发票, 释放 ...
- Volcano成Spark默认batch调度器
摘要:对于Spark用户而言,借助Volcano提供的批量调度.细粒度资源管理等功能,可以更便捷的从Hadoop迁移到Kubernetes,同时大幅提升大规模数据分析业务的性能. 2022年6月16日 ...
- 高精度10m/30米NPP净初级生产力分布数据
数据下载链接:百度云下载链接 引言 第一性生产力是绿色植物呼吸后所剩下的单位面积单位时间内所固定的能量或所生产的有机物质,即是总第一性生产量减去植物呼吸作用所剩下的能量或有机物质.多种卫星遥感数据反 ...
- 文件的下载,HttpMessageConverter原理
HttpMessageConverter<T> 1) HttpMessageConverter<T> 是 Spring3.0 新添加的一个接口,负责将请求信息转换为一个对象(类 ...
- 在项目中导入lombok依赖自动生成有参,无参 空参 方法的注解
导入依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok< ...
- 方法的调用和JDK9的JShell简单使用
方法在定义完毕后,方法不会自己运行,必须被调用才能执行,我们可以在主方法main中来调用我们自己定义好的方法.在主方法中,直接写要调用的方法名字就可以调用了 public static void ma ...
- 什么是好的 API 设计?【eolink翻译】
对于试图完善其 API 策略的团队来说,良好的 API 设计是一个经常出现的话题. API 设计的重要性相信不需要赘述,精心设计的 API 的好处包括:更好开发人员体验.更快的文档编制以及更高的 AP ...