TiDB与MySQL的SQL差异及执行计划简析
作者:京东零售 肖勇
一、 前言导读
TiDB作为NewSQL,其在对MySQL(SQL92协议)的兼容上做了很多,MySQL作为当下使用较广的事务型数据库,在IT界尤其是互联网间使用广泛,那么对于开发人员来说,1)两个数据库产品在SQL开发及调优的过程中,都有哪些差异?在系统迁移前需要提前做哪些准备? 2)TiDB的执行计划如何查看,如何SQL调优? 本文做了一个简要归纳,欢迎查阅交流。
二、 建表SQL语法差异&优化建议
| 分类 | MySQL写法 | TiDB写法 | 注意事项 |
| 建表 | alter table A add column phone bigint(20),add column address varchar(100); | alter table A add column phone bigint(20); alter table A add column address varchar(100); | 1.一个DDL脚本仅支持一个字段修改 2.新建表时,尽量提前规划好相应字段 |
| 建表 | create table A(`id` bigint(20) NOT NULL AUTO_INCREMEN) | create table A(`id` bigint(20) NOT NULL AUTO_INCREMEN) | TiDB自增主键全局唯一,但不严格递增(仅各Server内部连续) 需要严格连续自增主键时,业务系统自己生成写入 |
| 建表 | create table A as select * from B | 不支持 | |
| 建表 | create temporary table A | 不支持 | 不支持临时表 |
| SQL DML提交前,建议结合explain和explain analyze命令和业务场景,确认执行计划 |
三、 查询SQL语法差异&优化建议
| 分类 | MySQL写法 | TiDB写法 | 注意事项 |
| 查询 (结果条数统计) | select * from A select count() from A | select name,age,address from A select count(age) from A | 1.避免全量字段查询,节省网络带宽 2.当开启TiFlash统计行数据时,TiDB会使用列模式提升查询性能 |
| 查询 (闭区间查询) | select name,age from A where age>10 | select name,age from A where age>10 and id<99 | TiDB针对限定数据范围的闭区间查询,能减少全表扫描概率 |
| 查询 (时间排序) | select name,age from A order by id(主键) | select name,age from A order by create_time(时间索引) | 分布式数据库主键不再连续,需要时间顺序排序时,可新增时间字段 |
| 查询 (结果字段分堆) | select name,age from A group by name | select name,age from A group by name,age | 需要分堆的所有字段,在SQL中必须显示标识 |
| 查询 (结果字段排序) | select name,age from A order by name | select name,age from A order by name,age | 需要排序的所有字段,在SQL中必须显示标识 |
| 查询 (索引优化) | select name,age from A where name=‘张三’ and age>110 and cityName!='北京' | 尽可能的将使用频率高的,经常被点查使用的列排在前面,将经常进行范围查询的列排在后面 |
| 查询 (显示优化规则) DBA不建议 | select name,age from A where name='张三' | select name,age from A where name='张三' use index(name_age) | 显示通知TiDB优化器,使用name_age索引 |
| 查询 (覆盖索引) | select name,age from A where name='张三' order by age | ORDER BY,GROUP BY,DISTINCT 的字段需要添加在索引的后面,形成覆盖索引 |
| 查询 (显示优化规则) DBA不建议 | select name,age from A where name='张三' | select /+ read_from_storage(tiflash[A]) */ name,age from A where name='张三' | 显示通知TiDB优化器,使用TiFlash提升性能 |
| MySQL常见SQL优化规则(如not in,like ‘abc%’,减少查询返回列,避免在索引列使用函数),对于TiDB同样适用 |
四、 SQL执行计划差异&优化建议
| 分类 | MySQL写法 | TiDB写法 | 注意事项 |
| 执行计划 | explain select count() from A | explain select count() from A explain analyze select count(*) from A | 1.TiDB提供explain和explain analyze两种查询计划分析,前者不会执行,后者会实际执行 2.explain参考:https://docs.pingcap.com/zh/tidb/stable/explain-walkthrough 3.explain analyze参考:https://docs.pingcap.com/zh/tidb/stable/sql-statement-explain-analyze/ |
| 查询 (结果分析优化) | operator中包含stats:pseudo | SQL对应表统计信息已失真,执行analyze tableName修复即可(注:关注数据期间卡表修复对业务的影响) |
| 查询 (类型优化) | select name,age from A where zip=0 (其中zip为bit类型) | select name,age from A where zip=0 (修改zip为int类型) | TiDB字段尽量使用常见mysql类型 |
| 注意:analyze tableName对TiDB集群的影响较大,执行前千万与DBA做好沟通评估,临时情况可通过显示指定索引(USE INDEX)绕开流量高峰期 |
五、 TiDB执行计划分析简介
1. 在开始实际案例分析前,我们先看下执行计划中每列的含义:
| 属性名 | 含义 |
| id | 算子的 ID,是算子在整个执行计划中唯一的标识。在 TiDB 2.1 中,ID 会格式化地显示算子的树状结构。数据从孩子结点流向父亲结点,每个算子的父亲结点有且仅有一个。 |
| estRows | 算子预计将会输出的数据条数,基于统计信息以及算子的执行逻辑估算而来。 |
| actRows | 算子实际输出的数据条数 |
| task | 算子属于的 task 种类。目前的执行计划分成为两种 task,一种叫 root task,在 tidb-server 上执行,一种叫 cop task,在 TiKV 或者 TiFlash 上并行执行。当前的执行计划在 task 级别的拓扑关系是一个 root task 后面可以跟许多 cop task,root task 使用 cop task 的输出结果作为输入。cop task 中执行的也即是 TiDB 下推到 TiKV 或者 TiFlash 上的任务,每个 cop task 分散在 TiKV 或者 TiFlash 集群中,由多个进程共同执行。 |
| access object | 算子所访问的数据项信息。包括表 table,表分区 partition 以及使用的索引 index(如果有)。只有直接访问数据的算子才拥有这些信息。 |
| execution info | 算子的实际执行信息。time 表示从进入算子到离开算子的全部 wall time,包括所有子算子操作的全部执行时间。如果该算子被父算子多次调用 (loops),这个时间就是累积的时间。loops 是当前算子被父算子调用的次数。 |
| operator info | 算子的其它信息。各个算子的 operator info 各有不同,可参考下面的示例解读。 |
| memory | 算子占用内存空间的大小 |
| disk | 算子占用磁盘空间的大小 |
2. 执行计划优化的几个关键点:
1) 重点观察算子类型,尽量控制优化器选择性能较优的算子,读取磁盘记录的几个算子性能:TableFullScan>TableRangeScan>TableRowIDScan,IndexFullScan>IndexRangeScan
2) 尽量减小root层执行动作,下放至tikv或tiflash执行,执行计划中task属性包括root task和cop task,其中root标识动作由tidb聚合层执行(此操作除了需要等待各分片结果外,一般部署结构中tidb资源也较tikv或tiflash少),cop标识动作下放至tikv或tiflash各分片单独执行
3) 保证表分析数据完整性,避免大批量数据短时间内新增/删除,estRows为执行引擎根据情况返回的预估记录条数,特别注意:若operator info出现stats:pseudo,则标识表基本信息不完善(无法提供准确执行计划评估),后续可通过analyze表重新收集分析数据,或显示use index对sql显示优化
4) 根据实际业务(如:列模式数据统计),增加tiflash模块,通过空间换时间,提升结构化查询和实时分析能力
3. 实际场景分析
下面我们通过2个实际SQL说说TiDB的执行计划:
l SQL1
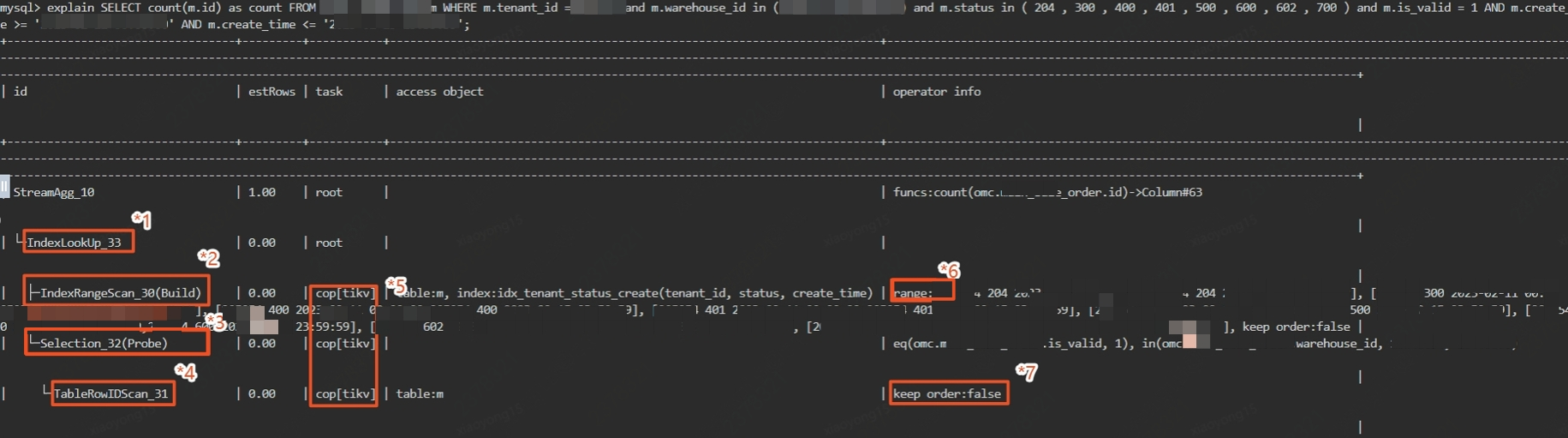
*1:IndexLookUp算子:根据索引获取结果记录
*2 & *3:Build算子总是优先于Probe算子执行,*2 算子根据条件从索引中获取数据,*3算子在结果中匹配结果
*4:TableRowIdScan:通过 *3 算子结果中的表主键id从TiKV获取行记录
*5:cop【tikv】标识将计算逻辑从tidb下放到tikv执行,同理还会有cop【tiflash】
*6:tikv通过范围索引扫描出对应记录
*7:根据id获取行记录后直接返回上层,无需排序
------------------------------------------------------------------------------------------------------------------------------
l SQL2
优化前,两表直接join:
explain analyze SELECT m.id AS id, m.order_id AS orderId, s.status AS status,m.sendpay_map as sendPayMap FROM tableA m LEFT JOIN tableB s on m.order_id = s.order_id WHERE m.id >= 100 AND m.id <= 100000000 and m.warehouse_id in (111,222) and s.status in (100, 200, 300, 400) and m.is_valid = 1 order by m.id desc limit 20,20;
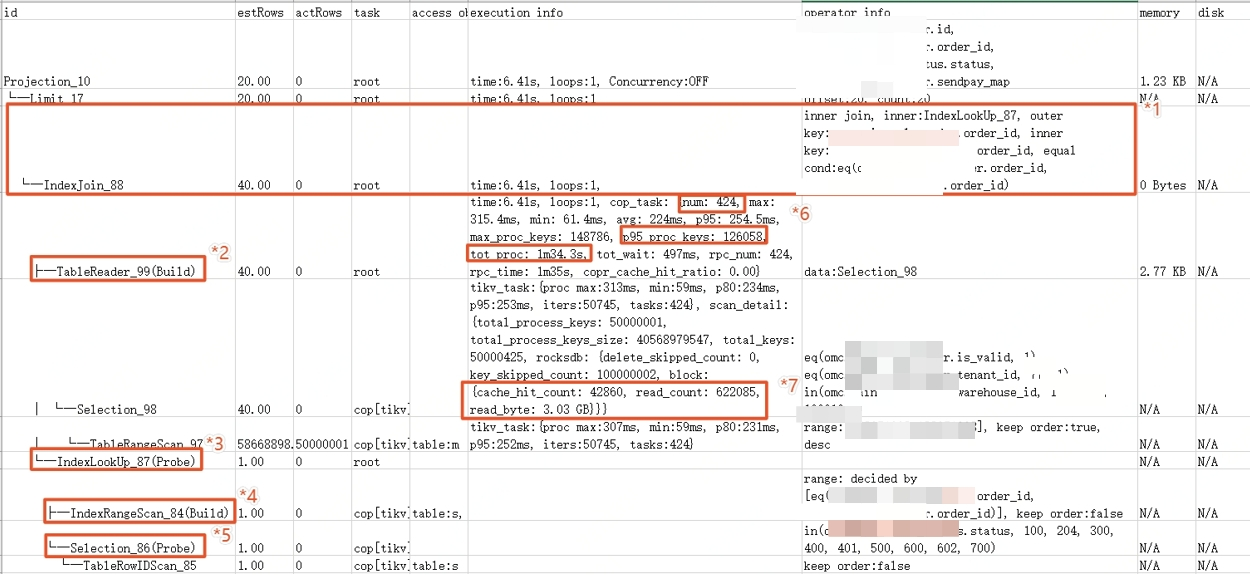
*1:IndexJoin算子:根据表s索引,与表m关联起来
*2 & *3:Build算子总是优先于Probe算子执行,*2 算子从表m匹配相关记录,*3算子通过表s索引获取join管理数据
*4 & *5:基于*3算子join后的结果,筛选匹配s表条件的记录
*6 & *7:可以看到此处表记录查询使用了TableReader,耗时6.41s(其中cop_task共424个,且使用了大量索引proc_keys),Selection_98根据索引回表查询更是读取了3.03GB记录
总结:整体sql因为是先join在limit,tidb无法将limit操作下推,导致主表大量回表查询,影响性能
优化后,先子查询再join:
explain analyze select * from (SELECT m.id AS id, m.order_id AS orderId,m.sendpay_map as sendPayMap FROM tableA m WHERE m.id >= 100 AND m.id <= 100000000 and m.warehouse_id in (111 ,222) and m.is_valid = 1 order by m.id desc limit 20,20) t LEFT JOIN tableB s on t.orderId = s.order_id WHERE s.status in (100 ,200, 300, 400)
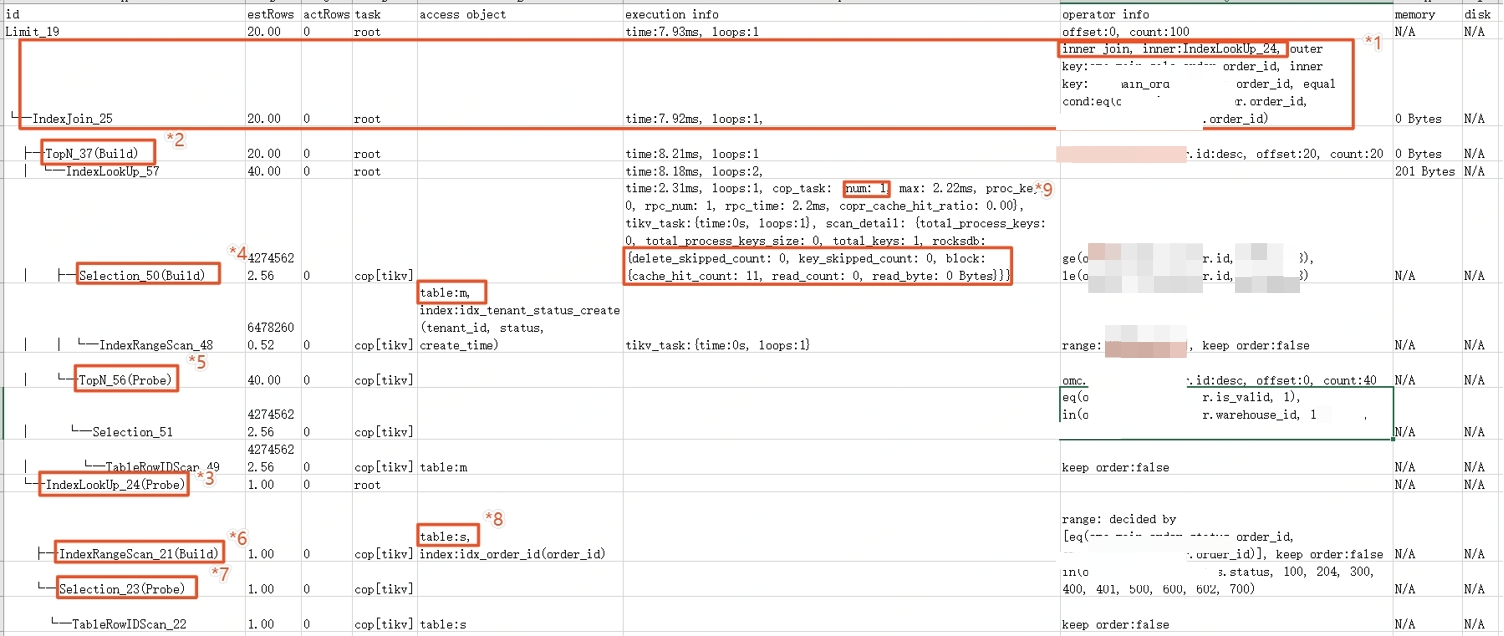
*1:IndexJoin算子:根据表s索引,与表m关联起来
*2:从m表结果中获取前20条记录
*3:通过表s索引获取join管理数据
*4:根据条件,从表m的索引中获取记录
*5:从*4算子结果中获取40条记录(tikv3副本,从2个分片各获取20条,共40条)
*6 & *7:基于*3算子join后的结果,筛选匹配s表条件的记录
*9:可以看到,此处是直接从IndexLookUp_57索引中查询数据,cop_task=1,且rocksdb中命中了缓存cache_hit_count=11
总结:整体sql因为是先limit再join,tidb将limit下推至tikv,大大较少了主表的回表查询数据量,提升性能
六、 小结
本文旨在通过TiDB和MySQl在SQL层面的差异性讲解,帮助读者在DB迁移和评估前,清楚了解双方的差异,避免遗漏。同时,针对TiDB的执行计划,通过简介和2个案例,帮助大家快速分析SQL执行情况,以便针对性优化。
TiDB与MySQL的SQL差异及执行计划简析的更多相关文章
- mysql体系结构和sql查询执行过程简析
一: mysql体系结构 1)Connectors 不同语言与 SQL 的交互 2)Management Serveices & Utilities 系统管理和控制工具 备份和恢复的安全性,复 ...
- SQL Server 优化-执行计划
对于SQL Server的优化来说,优化查询可能是很常见的事情.由于数据库的优化,本身也是一个涉及面比较的广的话题, 因此本文只谈优化查询时如何看懂SQL Server查询计划.毕竟我对SQL Ser ...
- mysql之优化器、执行计划、简单优化
mysql之优化器.执行计划.简单优化 2018-12-12 15:11 烟雨楼人 阅读(794) 评论(0) 编辑 收藏 引用连接: https://blog.csdn.net/DrDanger/a ...
- MySQL源码解析之执行计划
MySQL源码解析之执行计划 MySQL执行计划介绍 MySQL执行计划代码概览 MySQL执行计划总结 一.MySQL执行计划介绍 在MySQL中,执行计划的实现是基于JOIN和QEP_TAB这两个 ...
- 了解Sql Server的执行计划
前一篇总结了Sql Server Profiler,它主要用来监控数据库,并跟踪生成的sql语句.但是只拿到生成的sql语句没有什么用,我们可以利用这些sql语句,然后结合执行计划来分析sql语句的性 ...
- 【MS SQL】通过执行计划来分析SQL性能
原文:[MS SQL]通过执行计划来分析SQL性能 如何知道一句SQL语句的执行效率呢,只知道下面3种: 1.通过SQL语句执行时磁盘的活动量(IO)信息来分析:SET STATISTICS IO O ...
- SQL Server实际执行计划COST"欺骗"案例
有个系统,昨天Support人员发布了相关升级脚本后,今天发现系统中有个功能不能正常使用了,直接报超时了(Timeout expired)的错误.定位到相关相关存储过程后,然后在优化分析的过程中,又遇 ...
- 官方文档:11G新特性SQL PLAN BASLINE 执行计划基线
什么是SQL执行计划管理? SQL计划管理(SQL plan management)是一咱预防机制,记录和评估SQL语句的执行计划.SQL plan management的主要功能是sql plan ...
- oracle中查看sql语句的执行计划
1.在pl/sql中打开cmd命令容器 2.在cmd命令窗口中输入:explain plan for select * from t; 3.查看sql语句的执行计划:select * from tab ...
- NETGEAR 系列路由器命令执行漏洞简析
NETGEAR 系列路由器命令执行漏洞简析 2016年12月7日,国外网站exploit-db上爆出一个关于NETGEAR R7000路由器的命令注入漏洞.一时间,各路人马开始忙碌起来.厂商忙于声明和 ...
随机推荐
- springmvc拦截器的简单创建
找到前端控制器配置文件: 配置拦截器: 实现接口,定义自己的规则:
- ubuntu安装matplotlib失败:Can't rollback pillow, nothing uninstalled.
今天在ubuntu1804上面使用pip安装matplotlib,安装失败,报错如下: ---------------------------------------- Can't rollback ...
- OO_Lab0总结博客
OO_Lab0 问题描述 对表达式结构进行建模,将表达式中非必要的括号进行展开并化简. 设定的形式化表述(仅写出部分): 表达式 \(\rightarrow\) 空白项 [加减 空白项] 项 空白项 ...
- 艾思软件app开发公司帮您分析:开发一个APP多少钱?
首先你要知道你所要开发的APP, 是不是已经成熟的相同的产品, 如果有的话那还是建议直接购买, 这种已经能满足你需求的成品APP价格会很便宜, 总成本一般也就1到2万的级别. 如果没有那就需要定制开发 ...
- 2020/513-笔记:怎么知道Oracle数据库一个中文汉字占几个字节
1. 执行语句: select userenv('language') from dual; 如果显示如下: SIMPLIFIED CHINESE_CH ...
- Spring AOP的动态代理原理和XML与注解配置
AOP 实现底层就是对上面的动态代理的代码进行了封装,封装后我们只需要对需要关注的部分进行代码编写,并通过配置的方式完成指定目标的方法增强. 相关术语: Target(目标对象):代理的目标对象 Pr ...
- nginx配置https安全访问
1.使用wosigncode生成CSR https://bbs.wosign.com/forum.php?mod=viewthread&tid=3526#lastpost 2.配置,选择第7小 ...
- 3DMAX2018安装
1.下载3DMAX2018安装包并解压 2.打开解压后的文件点击Setup 选择语言和安装位置点击下一步 安装完成后点击enter a serial number 输入序列号066-66666666, ...
- 使用redis分布式锁重复执行采坑
事件:生产环境部署两台,每天凌晨1点,定时任务同步更新(先删除,后全部插入)账号表,使用了redis分布式锁,发现定时任务还是执行了两次,导致数据重复,影响对应业务. 原因分析:定时任务执行的逻辑是调 ...
- Trino Master OOM 排查记录
背景 最近线上的 trino 集群 master 节点老是因为 OOM crash,我们注意到 trino crash 前集群正在运行的查询数量正常,不太像是因为并发查询数据太多导致的 OOM.遂配置 ...