深度学习基础5:交叉熵损失函数、MSE、CTC损失适用于字识别语音等序列问题、Balanced L1 Loss适用于目标检测
深度学习基础5:交叉熵损失函数、MSE、CTC损失适用于字识别语音等序列问题、Balanced L1 Loss适用于目标检测
1.交叉熵损失函数
在物理学中,“熵”被用来表示热力学系统所呈现的无序程度。香农将这一概念引入信息论领域,提出了“信息熵”概念,通过对数函数来测量信息的不确定性。交叉熵(cross entropy)是信息论中的重要概念,主要用来度量两个概率分布间的差异。假定 p和 q是数据 x的两个概率分布,通过 q来表示 p的交叉熵可如下计算:
$H\left(p,q\right)=-\sum\limits_{x}p\left(x\right)\log q\left(x\right)$
交叉熵刻画了两个概率分布之间的距离,旨在描绘通过概率分布 q来表达概率分布 p的困难程度。根据公式不难理解,交叉熵越小,两个概率分布 p和 q越接近。
这里仍然以三类分类问题为例,假设数据 x属于类别 1。记数据x的类别分布概率为 y,显然 y=(1,0,0)代表数据 x的实际类别分布概率。记$\hat{y}$代表模型预测所得类别分布概率。那么对于数据 x而言,其实际类别分布概率 y和模型预测类别分布概率 $\hat{y}$的交叉熵损失函数定义为:
$cross entryy=-y\times\log(\hat{y})$
很显然,一个良好的神经网络要尽量保证对于每一个输入数据,神经网络所预测类别分布概率与实际类别分布概率之间的差距越小越好,即交叉熵越小越好。于是,可将交叉熵作为损失函数来训练神经网络。
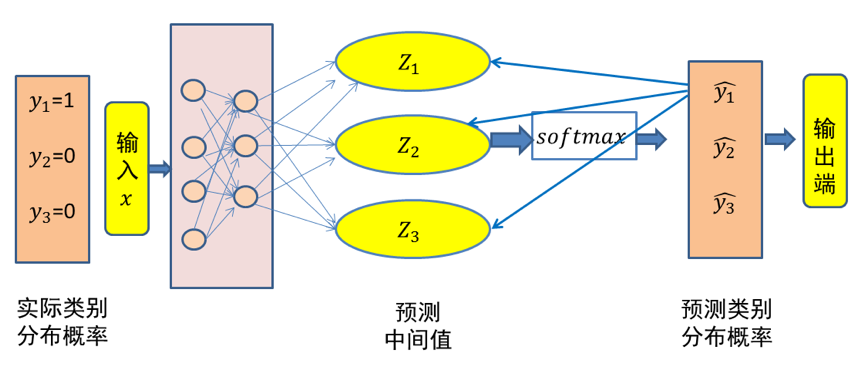
图1 三类分类问题中输入x的交叉熵损失示意图(x 属于第一类)

在上面的例子中,假设所预测中间值 (z1,z2,z3)经过 Softmax映射后所得结果为 (0.34,0.46,0.20)。由于已知输入数据 x属于第一类,显然这个输出不理想而需要对模型参数进行优化。如果选择交叉熵损失函数来优化模型,则 (z1,z2,z3)这一层的偏导值为 (0.34−1,0.46,0.20)=(−0.66,0.46,0.20)。
可以看出,$Softmax$和交叉熵损失函数相互结合,为偏导计算带来了极大便利。偏导计算使得损失误差从输出端向输入端传递,来对模型参数进行优化。在这里,交叉熵与Softmax函数结合在一起,因此也叫 $Softmax$损失(Softmax with cross-entropy loss)。
2.均方差损失(Mean Square Error,MSE)
均方误差损失又称为二次损失、L2损失,常用于回归预测任务中。均方误差函数通过计算预测值和实际值之间距离(即误差)的平方来衡量模型优劣。即预测值和真实值越接近,两者的均方差就越小。
计算方式:假设有 n个训练数据 $x_i$,每个训练数据 $x_i$ 的真实输出为 $y_i$,模型对 $x_i$的预测值为 $\hat{y_i}$。该模型在 n 个训练数据下所产生的均方误差损失可定义如下:
$MSE=\dfrac{1}{n}\sum\limits_{i=1}n\left(y_i-\hat{y}_i\right)2$
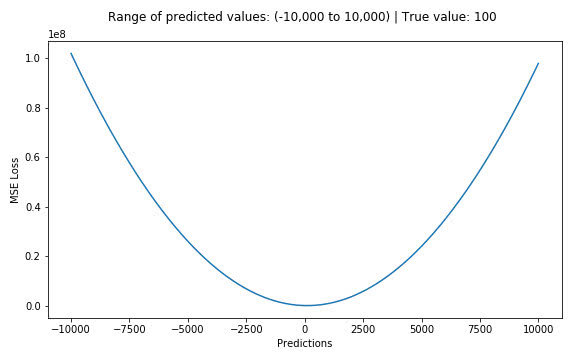
假设真实目标值为100,预测值在-10000到10000之间,我们绘制MSE函数曲线如 图1 所示。可以看到,当预测值越接近100时,MSE损失值越小。MSE损失的范围为0到∞。
3.CTC损失
3.1 CTC算法算法背景-----文字识别语音等序列问题
CTC 算法主要用来解决神经网络中标签和预测值无法对齐的情况,通常用于文字识别以及语音等序列学习领域。举例来说,在语音识别任务中,我们希望语音片段可以与对应的文本内容一一对应,这样才能方便我们后续的模型训练。但是对齐音频与文本是一件很困难的事,如 图1 所示,每个人的语速都不同,有人说话快,有人说话慢,我们很难按照时序信息将语音序列切分成一个个的字符片段。而手动对齐音频与字符又是一件非常耗时耗力的任务
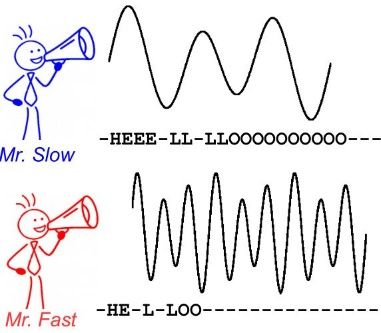
图1 语音识别任务中音频与文本无法对齐
在文本识别领域,由于字符间隔、图像变形等问题,相同的字符也会得到不同的预测结果,所以同样会会遇到标签和预测值无法对齐的情况。如 图2 所示。

图2 不同表现形式的相同字符示意图
总结来说,假设我们有个输入(如字幅图片或音频信号)X ,对应的输出是 Y,在序列学习领域,通常会碰到如下难点:
X和 Y都是变长的;
X和 Y的长度比也是变化的;
X和 Y相应的元素之间无法严格对齐。
3.2 算法概述
引入CTC主要就是要解决上述问题。这里以文本识别算法CRNN为例,分析CTC的计算方式及作用。CRNN中,整体流程如 图3 所示。
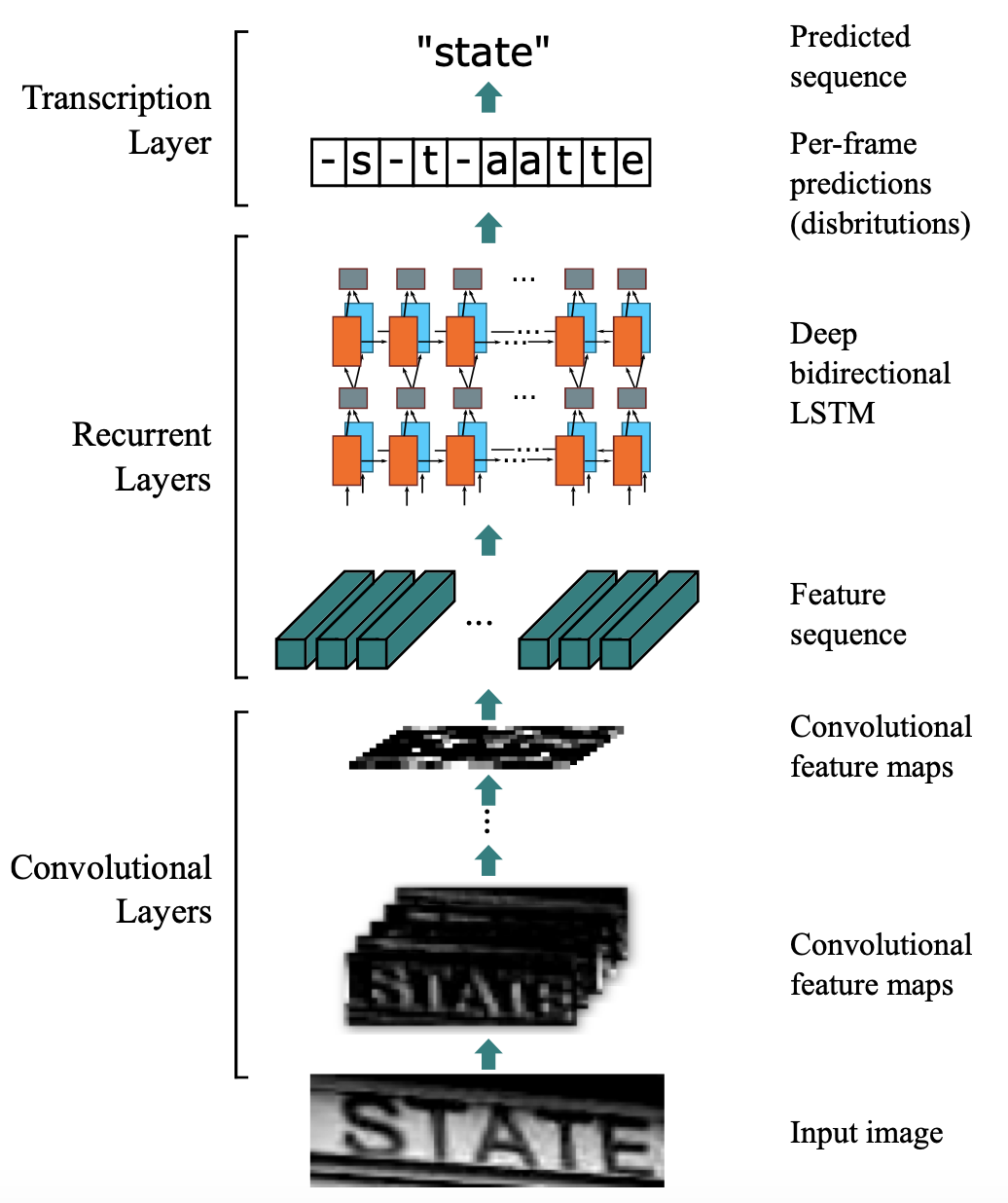
图3 CRNN整体流程
CRNN中,首先使用CNN提取图片特征,特征图的维度为$m×T$,特征图 x可以定义为:
$x=(x1,x2,...,x^T)\quad\text{}$
然后,将特征图的每一列作为一个时间片送入LSTM中。令 t为代表时间维度的值,且满足 $1<t<T$,则每个时间片可以表示为:
$xt=(x_1t,x_2t,\ldots,x_mt)$
经过LSTM的计算后,使用softmax获取概率矩阵 y,定义为:
$y=(y1,y2,\ldots,y^T)$
经过LSTM的计算后,使用softmax获取概率矩阵 $y^t$,定义为:
$yt=(y_1t,y_2t,\ldots,y_nt)$
n为字符字典的长度,由于 $y_i^t$是概率,所以$\Sigma_i y_i^t=1$ 。对每一列 $y^t$求 argmax(),就可以获取每个类别的概率。
考虑到文本区域中字符之间存在间隔,也就是有的位置是没有字符的,所以这里定义分隔符 −来表示当前列的对应位置在图像中没有出现字符。用 $L$代表原始的字符字典,则此时新的字符字典 $L′$为:
$L'=L\cup{-}$
此时,就回到了我们上文提到的问题上了,由于字符间隔、图像变形等问题,相同的字符可能会得到不同的预测结果。在CTC算法中,定义了 B变换来解决这个问题。 B变换简单来说就是将模型的预测结果去掉分割符以及重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有分割符,则表示该字符出现多次),使得不同表现形式的相同字符得到统一的结果。如 图4 所示。
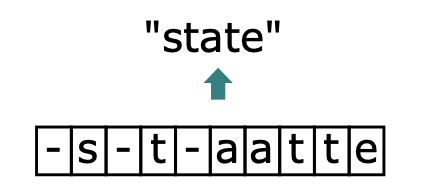
这里举几个简单的例子便于理解,这里令T为10:
$\begin{array}{c}B(-s-t-aative)=state\ \ B(ss-t-a-t-e)=state\ \ B(sstt-aat-e)=state\end{array}$
对于字符中间有分隔符的重复字符则不进行合并:
$B(-s-t-t state)=state$
当获得LSTM输出后,进行 B变换就可以得到最终结果。由于 B变换并不是一对一的映射,例如上边的3个不同的字符都可以变换为state,所以在LSTM的输入为 x的前提下,CTC的输出为 l的概率应该为:
$p(l|x)=\Sigma_{\pi\in B^{-1}(l)}p(\pi|x)$
其中, $pi$为LSTM的输出向量, $\pi\in B^{-1}(l)$代表所有能通过 B变换得到 l的 $pi$的集合。
而对于任意一个 π,又有:
$p(\pi|x)=\Pi_{t=1}^T y_{\pi_t}^t$
其中, $y_{\pi_t}^t$代表 t时刻 π为对应值的概率,这里举一个例子进行说明:
$\begin{array}{c}\pi=-s-t-aattte\ y_{\pi_t}t=y_-1y_s2*y_-3y_t4*y_-5y_a6*y_a7y_t8*y_t9*y_e^10\ \end{array}$
不难理解,使用CTC进行模型训练,本质上就是希望调整参数,使得$p(\pi\text{}|x)$ 取最大。
具体的参数调整方法,可以阅读以下论文进行了解:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
4.平衡 L1损失(Balanced L1 Loss)---目标检测
目标检测(object detection)的损失函数可以看做是一个多任务的损失函数,分为分类损失和检测框回归损失:
$L_{p,u,tu,v}=L_{cls}(p,u)+\lambda[u\geq1]L_{loc}(t^u,v)$
$L_cls$表示分类损失函数、$L_loc$表示检测框回归损失函数。在分类损失函数中,p表示预测值,u表示真实值。$t_u$表示类别u的位置回归结果,v是位置回归目标。λ用于调整多任务损失权重。定义损失大于等于1.0的样本为outliers(困难样本,hard samples),剩余样本为inliers(简单样本,easy sample)。
平衡上述损失的一个常用方法就是调整两个任务损失的权重,然而,回归目标是没有边界的,直接增加检测框回归损失的权重将使得模型对outliers更加敏感,这些hard samples产生过大的梯度,不利于训练。inliers相比outliers对整体的梯度贡献度较低,相比hard sample,平均每个easy sample对梯度的贡献为hard sample的30%,基于上述分析,提出了balanced L1 Loss(Lb)。
Balanced L1 Loss受Smooth L1损失的启发,Smooth L1损失通过设置一个拐点来分类inliers与outliers,并对outliers通过一个$max(p,1.0)$进行梯度截断。相比smooth l1 loss,Balanced l1 loss能显著提升inliers点的梯度,进而使这些准确的点能够在训练中扮演更重要的角色。设置一个拐点区分outliers和inliers,对于那些outliers,将梯度固定为1,如下图所示:
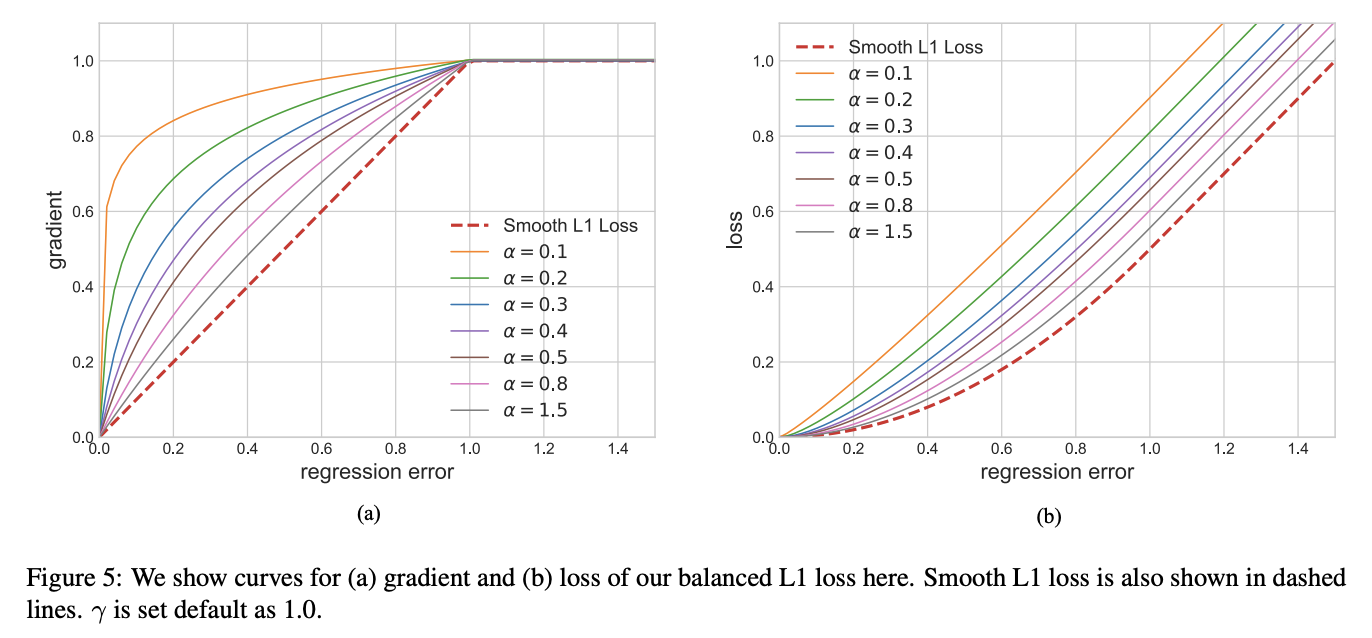
Balanced L1 Loss的核心思想是提升关键的回归梯度(来自inliers准确样本的梯度),进而平衡包含的样本及任务。从而可以在分类、整体定位及精确定位中实现更平衡的训练,Balanced L1 Loss的检测框回归损失如下:
$L_{loc}=\sum\limits_{i\in x,y,w,h}L_b(t_i^u-v_i)$
其相应的梯度公示如下:
$\dfrac{\partial L_{loc}}{\partial w}\propto\dfrac{\partial L_b}{\partial t_i^u}\propto\dfrac{\partial L_b}{\partial x}$
基于上述公式,设计了一种推广的梯度公式为:
$\dfrac{\partial L_b}{\partial x}=\begin{cases}\alpha ln(b|x|+1),if|x|<1\ \gamma,otherwise\end{cases}$
其中,$α$控制着inliers梯度的提升;一个较小的α会提升inliers的梯度同时不影响outliers的值。$γ$来调整回归误差的上界,能够使得不同任务间更加平衡。α,γ从样本和任务层面控制平衡,通过调整这两个参数,从而达到更加平衡的训练。Balanced L1 Loss公式如下:
$L_b(x)=\begin{cases}\frac ab(b|x|+1)ln(b|x|+1)-\alpha|x|,if|x|<1\ \gamma|x|+C,otherwise\end{cases}$
其中参数满足下述条件:
$\alpha ln(b|x|+1)=\gamma\quad\text{}$
默认参数设置:α = 0.5,γ=1.5
Libra R-CNN: Towards Balanced Learning for Object Detection
深度学习基础5:交叉熵损失函数、MSE、CTC损失适用于字识别语音等序列问题、Balanced L1 Loss适用于目标检测的更多相关文章
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 深度学习原理与框架-神经网络结构与原理 1.得分函数 2.SVM损失函数 3.正则化惩罚项 4.softmax交叉熵损失函数 5. 最优化问题(前向传播) 6.batch_size(批量更新权重参数) 7.反向传播
神经网络由各个部分组成 1.得分函数:在进行输出时,对于每一个类别都会输入一个得分值,使用这些得分值可以用来构造出每一个类别的概率值,也可以使用softmax构造类别的概率值,从而构造出loss值, ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 经典的损失函数:交叉熵和MSE
经典的损失函数: ①交叉熵(分类问题):判断一个输出向量和期望向量有多接近.交叉熵刻画了两个概率分布之间的距离,他是分类问题中使用比较广泛的一种损失函数.概率分布刻画了不同事件发生的概率. 熵的定义: ...
- Tensorflow2(一)深度学习基础和tf.keras
代码和其他资料在 github 一.tf.keras概述 首先利用tf.keras实现一个简单的线性回归,如 \(f(x) = ax + b\),其中 \(x\) 代表学历,\(f(x)\) 代表收入 ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- softmax交叉熵损失函数求导
来源:https://www.jianshu.com/p/c02a1fbffad6 简单易懂的softmax交叉熵损失函数求导 来写一个softmax求导的推导过程,不仅可以给自己理清思路,还可以造福 ...
- [ch03-02] 交叉熵损失函数
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 3.2 交叉熵损失函数 交叉熵(Cross Entrop ...
- 关于交叉熵损失函数Cross Entropy Loss
1.说在前面 最近在学习object detection的论文,又遇到交叉熵.高斯混合模型等之类的知识,发现自己没有搞明白这些概念,也从来没有认真总结归纳过,所以觉得自己应该沉下心,对以前的知识做一个 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
随机推荐
- webpack配置跨域proxy
首先新建一个项目: 安装vue-cli: npm i -g @vue/cli npm i -g @vue/cli-init 安装webpack: npm install webpack -g vue新 ...
- winIO介绍
WinIO程序库允许在32位的Windows应用程序中直接对I/O端口和物理内存进行存取操作.通过使用一种内核模式的设备驱动器和其它几种底层编程技巧,它绕过了Windows系统的保护机制. 因为需要加 ...
- MySQL日常维护指南
一.常用命令 1.查看数据库默认编码 show variables like 'character%'; show variables like 'collation%'; 2.启动停止数据库 /et ...
- 微信小程序 图片预览 wx.previewImage
官网地址: go官网 效果展示: list: [ 'http://img5.imgtn.bdimg.com/it/u=3300305952,1328708913&fm=26&gp=0. ...
- JSP环境搭建及入门 和 虚拟路径和虚拟主机
Jsp:是一个动态网页,而不是静态网页 html,css,js,Jquery:是静态网页 动态网页是随着,时间,地点,用户操作,而改变 静态不需要jsp 动态是需要的 BS 可以通过浏览器直接访问浏览 ...
- jenkins脚本
1.统计代码 pipeline { agent any parameters { choice( description: '你需要选择当前哪个分支进行统计 ?', name: 'branchNow' ...
- P5192 有源汇上下界最大流总结
之前听学长讲解时,只听了大体思路就跑路了,没有听到具体细节.后面在考虑出度多的点具体向虚拟源点连边还是虚拟汇点连边时,只凭直觉直接向源点连边,然后就一直WA,直到后来中午听同学讲解才反应过来,白白浪费 ...
- windows监控web程序连接数
运行: win+R->perfmon.msc 右键,添加计数器 选择webservice中的current connection选项,再选中对应实例即可~
- GDB使用详解
来源:GDB使用详解 - 知乎 (zhihu.com) 1. 概述 GDB 全称"GNU symbolic debugger",从名称上不难看出,它诞生于 GNU 计划(同时诞 ...
- 执行sql语句,查询sql版本
SELECT VERSION();