spring-boot-learning 缓存之redis
什么是BSD协议:
BSD是"Berkeley Software Distribution"的缩写,意思是"伯克利软件发行版"。
BSD开源协议是一个给于使用者很大自由的协议。可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布
Redis 是基于内存的,所以运行速度很快,大约是关系数据库几倍到几十倍的速度
为什么需要redis
在现实中,查询数据要远远多于更新数据, 一般一个正常的网站查询和更新的比例大约是1 : 9到3:7 , 在查询比例
较大的网站使用Redis 可以数倍地提升网站的性能。 例如, 当一个会员登录网站,我们就把其常用数据从数据库一次性查询出来存放在Redis 中,那么之后大部分的查询
只需要基于Redis 完成便可以了,这样将很大程度上提升网站的性能。 除此之外, Redis 还提供了简单的事务机制,通过事务机制可以有效保证在高井发的场景下数据的一致性。 Redis 在2.6 版本之后开始增加Lua 语言的支持,这样Redis 的运算能力就大大提高了,而且在Redis 中
Lua 语言的执行是原子性的
也就是在Redis 执行Lua 时, 不会被其他命令所打断,这样就能够保证在高并发场景下的一致性
springboot中的redis
Sprin g Boot 也会为其提供stat er ,然后允许我们通过配置文件applic atio n .properti es 进行配置,这样就能够以最快的速度配置并且使用Redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency> <!-- 因为默认情况下springboot会依赖lettuce的redist客户端驱动-->
<!-- 而我们实际过程中,会使用Jedis驱动,所以上面去除了依赖-->
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
在默认的情况下, spring-boot-starter- data-redis( 版本2.x ) 会依赖Lettuce 的Red is 客户端驱动,
而在一般的项目中,我们会使用Jedis ,
所以在代码中使用了<exclusions>元素将其依赖排除了,与此同时引入了Jedis 的依赖
springboot-redis设计内容:
java中与Redis连接的驱动有很多种,用的比较多的是jdeis
spring提供一个RedisConnectionFactory接口,他可以生产一个RedisConnection接口对象。
接口对象是对Redis底层接口的封装,:
jedis驱动,那么Spring就会根据RedisConnection接口实现类----JedisConnection去封装原有的Jedis对象。

Spring 中是通过RedisConnection 接口操作Red is 的,而RedisConnection
则对原生的Jedis 进行封装。要获取RedisConnection 接口对象, 是通过RedisConnectionFactory 接口
去生成的,所以第一步要配置的便是这个工厂了,而配置这个工厂主要是配置Redis 的连接池,对于
连接池可以限定其最大连接数、超时时间等属性

虽然我们可以使用自己的配置,去RedisConnectionFactory工厂获取,然后使用完之后还要自己关闭,
Spring为了进一步简化开发,提供了RedisTemplate
RedisTemplate
RedisTemplate
是一个强大的类,首先它会自动从Red i sConnectionFactory 工厂中获取连接,然后执行对应的Red is
命令,在最后还会关闭Redis 的连接。
关于获取关闭都已经在RedisTemplate中被封装了,不需要我去关注redis连接和闭合的问题
前提我们需要知道:
首先需要清楚的是, Redis是一种基于字符串存储的NoSQL , 而Java 是基于对
象的语言,对象是无法存储到Redis 中的,不过Java提供了序列化机制,只要类实现了java .io.Serializable 接口, 就代表类的对象能够进行序列化,通过将类对象进行序列化就能够得到二进制字符串,这样Redis 就可以将这些类对象以字符串进行存储。
同时;Java 也可以将那些二进制字符串通过反序列化转为对象
Spring提供了序列号器的机制,并且实现了几个关于redis序列化器

Spring 提供了RedisSeri alizer 接口,它有两个方法。这两个方法:
一个是serialize , 它能把那些可以序列化的对象转换为二进制字符串;
一个是deserialize,它能够通过反序列化把二进制字符串转换为Java 对象 JdkSerializationRedisSerializer 是RedisTemplate 默认的序列化器
注意:JacksonJsonRedisSerializer已经不再使用
序列化的原理如图:

RedisTemplate中序列化器属性

它会默认使用JdkSerial izationRedisSerializer 对对象进行序列化和反序列化,这样子我们的key字符串也会变成二进制,
难以查看数据
我们希望可以将Redis的Key以普通字符串保存,
提供了一个StringRedisTemplate类,这个类继承RedisTemplate ,只是提供了字符串的操作而己,
Spring对redis数据类型操作的封装
Redis 能够支持7 种类型的数据结构,这7 种类型是字符串、散列、列表(链表) 、集合、有序
集合、基数和地理位置。为此Spring 针对每一种数据结构的操作都提供了对应的操作接口

上面的接口都可以使用ReidsTemplate得到

以通过各类的操作接口来操作不同的数据类型,
如果我们需要对某一个键值对做连续的操作,spring提供了对应的BoundXXXOperations 接口

原理就是,相对操作对象进行绑定,之后救可以进行多次操作了

SessionCallack 和RedisCallback接口
它们的作用是让RedisTemplate 进行回调,通过它们可以在同一条连接下执行多个Redis 命令
SessionCa!lback
提供了良好的封装,对于开发者比较友好,因此在实际的开发中应该优先选择使用它
springboot配置和使用Redis
spring配置redis
#配置redis连接池属性
#默认是8
spring.redis.jedis.pool.max-idle= 10
#默认是8
spring.redis.jedis.pool.max-active= 10
#默认是0
spring.redis.jedis.pool.min-idle= 5
#是-1ms就是没限制
spring.redis.jedis.pool.max-wait= 2000
#redis服务器属性
spring.redis.port= 6379
spring.redis.host= 127.0.0.1
#Redis连接超时时间,单位为毫秒
spring.redis.timeout= 1000
配置了连接池和服务器的属性,用以连接Red is 服务器
Spring Boot 的自动装配机制就会读取这些配置来生成有关Redis 的操作对象, 这里它会自动生成
RedisConnectionFactory 、RedisTemplate 、StringRedisTemplate 等常用的Red is 对象。
RedisTemplate 会默认使用JdkSerial izati onRedisSerial izer 进行序列化键值,这样便能够存储到Red is 服务器中。
如果这样, Redis服务器存入的便是一个经过序列化后的特殊字符串,我们很难去跟踪。
Redis 只是使用字符串,那么使用其自动生成的StringRedisTemplate 即可,但是这样就只能支持字符串
了,并不能支持Java 对象的存储。
所以!!!!
可以通过设置RedisTemplate 的序列化器来处理。
修改RedisTemplate序列化器
@SpringBootApplication
public class RedisApplication { public static void main(String[] args) {
SpringApplication.run(RedisApplication.class, args);
} @Autowired
RedisTemplate redisTemplate; //定义自定义后初始化方法
@PostConstruct
public void init(){ }
//因为默认的redis序列化器是jdkSerializationRedisSerializer,java对象会被初始化为奇怪的字符串
//修改默认的序列化器为StringSerializer
private void initRedisTemplate(){
RedisSerializer stringserializer = redisTemplate.getStringSerializer();
redisTemplate.setKeySerializer(stringserializer);
redisTemplate.setHashKeySerializer(stringserializer);
} }
通过@Autowired 注入由Spring Boot 根据配置生成的RedisTemplate 对象,然后利用Spring Bean 生命周期的
特性使用注解@PostConstruct 自定义后初始化方法。 在这个方法里,把RedisTemplate中的键序列化器修改为StringRedisSerializer 。RedisTemplate会默认定义
一个StringRedisSerializer 对像。我们这里直接获取救可以了 把RedisTemplate 关于键和其散列数据类型的filed 都修改为了使用StringRedisSerializer 进行序列化,
这样我们在Red is 服务器上得到的键和散列的field 就都以宇符串存储了。
操作Reids字符串和散列数据类型
@RestController
@RequestMapping("/redis")
public class RedisController {
@Autowired
private RedisTemplate redisTemplate = null; @Autowired
private StringRedisTemplate stringRedisTemplate = null; @RequestMapping("/done")
public Map<String,Object> doneRedis(){
redisTemplate.opsForValue().set("key1","value1"); redisTemplate.opsForValue().set("int_key","1");
//上面的两个redisTemplate使用是jdk的序列号器,所以redis保存时不是整数,是一个乱的字符串 stringRedisTemplate.opsForValue().set("int","1");
//使用运算,增加1
stringRedisTemplate.opsForValue().increment("int");
//获取底层的Jedis连接
Jedis jedis = (Jedis)stringRedisTemplate.getConnectionFactory().getConnection().getNativeConnection();
//这个减一的操作,redisTemplate是不支持的,所以我们要获取底层Jedis连接去实现功能
jedis.decr("int"); //建立一个散列数据类型
Map<String,String> hashm = new HashMap<>();
hashm.put("f1","v1");
hashm.put("f2","v2");
//存储散列数据类型,并且指定key名字为hashm
stringRedisTemplate.opsForHash().putAll("hashm",hashm);
//新增一个字段
stringRedisTemplate.opsForHash().put("hashm","f3","v3");
//绑定散列操作的key,可以连续对同一个散列数据类型进行操作
BoundHashOperations hashops = stringRedisTemplate.boundHashOps("hashm");
//删除一个字段
hashops.delete("f2","v2");
//新增一个字段
hashops.put("f4","v4"); Map<String,Object> map = new HashMap<>();
map.put("done",true);
return map;
} }
@Autowired 注入了Spring Boot 为我们自动初始化Red i sTemplate 和StringRedisTemplate对象。
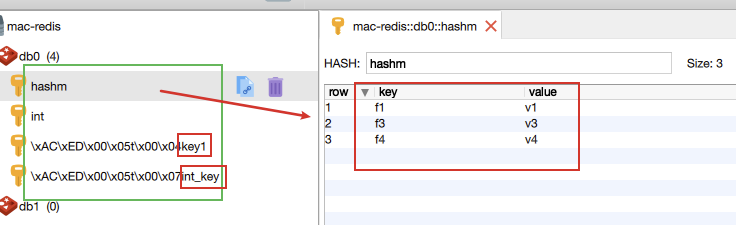
首先是存入了一个“ keyl ”的数据,然后是“ int_key ”。但是请注意这个“ int_ key ”存入到Redis 服务器中,
因为采用了JDK 序列化器,所以在Red is 服务器中它不是整数, 而是一个被JDK 序列化器序列化后的二进制字符串,
是没有办法使用Redis 命令进行运算的 使用Strin gRedisTemplate 对象保存了一个键为“ int ”的整数, 这样就能够运算了。因为RedisTemplate 并
不能支持底层所有的Redis 命令,所以这里先获取了原始的Redis 连接的Jedis 对象,用它来做减一运算。 操作散列数据类型,
在插入多个散列的field 时可以采用Map , 然后为了方便对同一个数据操作,这里代码还获取了BoundHashOperations
对象进行操作, 这样对同一个数据操作就方便
结果:

操作列表(链表)
@RequestMapping("/list")
@RestController
public class RedisListController {
@Autowired
private RedisTemplate redisTemplate = null;
@Autowired
private StringRedisTemplate stringRedisTemplate = null;
@RequestMapping("/done")
public Map<String ,Object> testList(){
//从左到右的顺序是, v4 v3 v2 v1
stringRedisTemplate.opsForList().leftPushAll("l1","v1","v2","v3","v4");
//从左到右的顺序是 v1 v2 v3 v4
stringRedisTemplate.opsForList().rightPushAll("l2","v1","v2","v3","v4");
//绑定List操作对象,
BoundListOperations listOps = stringRedisTemplate.boundListOps("l2");
//v1 v2 v3 v4 右边剔除一个所以v4是没有了
Object re1 = listOps.rightPop();
//查看位置为2的元素是什么,redis也是从0开始的。
Object re2 = listOps.index(2);
//v1 v2 v3,左边加入vv ===》 vv v1 v2 v3
listOps.leftPush("vv");
//获取列表的长度
Long size = listOps.size();
//获取列表指定范围的长度
List elements = listOps.range(0,size-2);
Map<String,Object> map = new HashMap<>();
map.put("success",true);
map.put("size",size);
map.put("listsize",elements);
map.put("re2",re2);
map.put("re1rightpop",re1);
return map;
}
}
操作是基于StringRedisTemplate 的,所以保存到Red is 服务器的都是字符串类型
注意:
列表元素的顺序问题,是从左到右还是从右到左
下标问题,在Red is 中是以0 开始的,这与Java 中的数组类似。

redis:

操作集合
集合:
对于集合, 在Redis 中是不允许成员重复的,它在数据结构上是一个散列表的结
构,所以对于它而言是无序的,对于两个或者以上的集合, Red is 还提供了交集、并集和差集的运算。
@RestController
@RequestMapping("/set")
public class RedisSetController {
@Autowired
private StringRedisTemplate stringRedisTemplate = null; @RequestMapping("/done")
public Map<String ,Object> testSet(){
//加入连个集合类型的keyvalue
stringRedisTemplate.opsForSet().add("s1","v1","v1","v2","v3","v4","v5");
stringRedisTemplate.opsForSet().add("s2","v1","v3","v5","v8");
//绑定操作集合
BoundSetOperations setOps = stringRedisTemplate.boundSetOps("s1");
//加入两个元素
setOps.add("v6","v7");
//删除两个元素
setOps.remove("v1","v2");
//获取所有的集合元素
Set set1 = setOps.members();
//获取集合长度
Long size = setOps.size();
//交集
Set inter = setOps.intersect("s2");
//交集并新建一个集合去存储
setOps.intersectAndStore("s2","s1s2iner"); Set diff = setOps.diff("s2");
setOps.diffAndStore("s2","diffset"); Set union = setOps.union("s2"); setOps.unionAndStore("s2","unionSet"); Map<String ,Object> map = new HashMap<>();
map.put("set1",set1);
map.put("inter",inter);
map.put("diff",diff);
map.put("union",union);
return map;
}
}



操作有序集合
在一些网站中,经常会有排名,如最热门的商品或者最大的购买买家,都是常常见到的场景。对于这类排名,刷新往往需要
及时,也涉及较大的统计,如果使用数据库会太慢。为了支持集合的排序, Red is 还提供了有序集合( zset )。
有序集合与集合的差异并不大,它也是一种散列表存储的方式,同时它的有序性只是靠它在数据结构中增加一个属性--score
(分数)得以支持。
所以Spring提供了TypedTupl e 接口,它定义了两个方法,并且S pring 还提供了其默认的实现类DefaultTypedTuple

value 是保存有序集合的值, score 则是保存分数, Red is 是使用分数来完成集合的排序的,这样如果把买家作为
一个有序集合,而买家花的钱作为分数,就可以使用Red is 进行快速排序了
@RequestMapping("/zset")
@RestController
public class RedisZSetController {
@Autowired
private StringRedisTemplate stringRedisTemplate = null;
@RequestMapping("/done")
public Map<String ,Object> testZSet(){
Set<TypedTuple<String >> typedTupleSet = new HashSet<>();
for(int i = 1;i<=9;i++){
double score = i*0.1;
TypedTuple<String> typedTuple = new DefaultTypedTuple<>("value"+i,score);
typedTupleSet.add(typedTuple);
}
stringRedisTemplate.opsForZSet().add("zset1",typedTupleSet);
BoundZSetOperations zsops = stringRedisTemplate.boundZSetOps("zset1");
zsops.add("value10",0.22);
Set<String> setrange = zsops.range(1,6);
//按照分数阶段去获取有序集合
Set<String> setscore = zsops.rangeByScore(0.2,0.6);
//定义范围,
RedisZSetCommands.Range range = new RedisZSetCommands.Range();
range.gt("value3");//大于value3
// range.gte("value3");//大于等于value3
range.lt("value8");//小于等于
//按照字符串排序的,有序集合里面的value的值,再上面那个范围内进行排序
Set<String> setLex = zsops.rangeByLex(range);
System.out.println(setLex);//[value3, value4, value5, value6, value7]
//删除元素
zsops.remove("value9","value2");
//获取分数,
Double score = zsops.score("value8");
System.out.println(score);//0.8
//按照位置排序对指定区间取值和分数
Set<TypedTuple<String>> rangeSet = zsops.rangeWithScores(1,6);
rangeSet.forEach(v -> System.out.println(v.getValue()+"=="+v.getScore()));
System.out.println("###############");
//按照分数排序对指定区间取值和分数
Set<TypedTuple<String>> scoreSet = zsops.rangeByScoreWithScores(0.1,0.6);
scoreSet.forEach(v -> System.out.println(v.getValue()+"==="+v.getScore()));
System.out.println("###############");
//虫小到大排序
Set<String> reverSet = zsops.reverseRange(2,8);
System.out.println(reverSet);//[value6, value5, value4, value3, value10, value1]
Map<String,Object> map = new HashMap<>();
map.put("suceess",true);
return map;
}
}
使用了TypedTup l e 保存有序集合的元素,在默认的情况下,有序集合是从小到大地排序
按下标、分数和值进行排序获取有序集合的元素
或者连同分数一起返回,有时候还可以进行从大到小的排序
在使用值排序时,我们可以使用Spring 为我们创建的Range 类,它可以定义
值的范围,还有大于、等于、大于等于、小于等于等范围定义,方便我们筛选对应的元素。

Redis的其他用法:
Red is 除了操作那些数据类型的功能外, j巫能支持事务、流水线、发布订阅和Lua i吾等功能, 这
些也是Red is 常用的功能。在高并发的场景中, 往往我们需要保证数据的一致性, 这时考虑使用Redis
事务或者利用Redis 执行Lua 的原子性来达到数据一致性的目的,
Redis的事务
Redis 是支持一定事务能力的NoSQL ,
通常的命令组合是watch...multi .. . exec,也就是要在一个Redis 连接中执行多个命令,这时我们可以考虑使用S巳ssionCallback 接口来达到这个目的
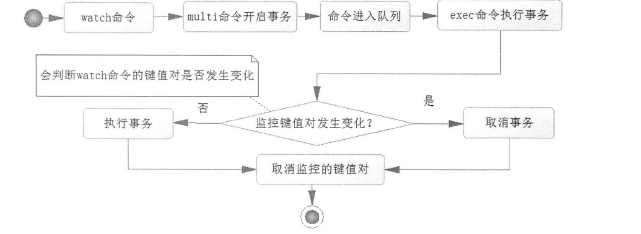
watch 命令是可以监控Redis 的一些键:
multi 命令是开始事务,
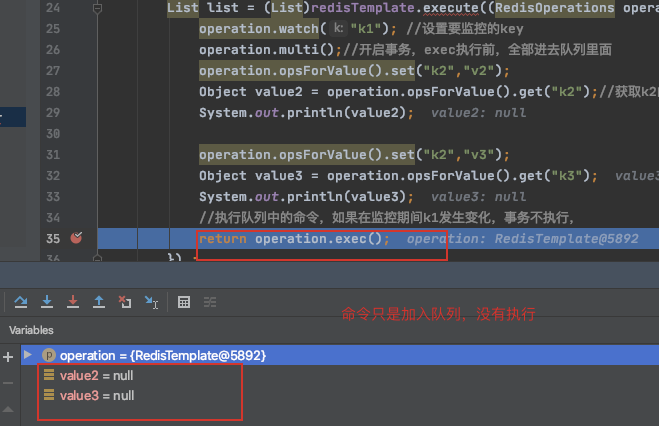
注意:开始事务后, 该客户端的命令不会马上被执行,而是存放在一个队列里,所以这时候去查询什么的,返回都是null
exec 命令的意义在于执行事务,只是它在队列命令执行前会判断被watch 监控的Redis 的键的数据是否发生过变化
( 即使赋予与之前相同的值也会被认为是变化过〉 如果它认为发生了变化,那么Redis 就会取消事务, 否则就会执行事务, Redis 在执行事务时,要么全部执行, 要么全部不执行,而且不会被其他客户端打断
流程图:
@RequestMapping("/transaction")
@RestController
public class RedisTransactionController {
@Autowired
private RedisTemplate redisTemplate;
@RequestMapping("/done")
public Map<String ,Object> testTransaction(){
redisTemplate.opsForValue().set("k1","v1");
List list = (List)redisTemplate.execute((RedisOperations operation) ->{
operation.watch("k1"); //设置要监控的key
operation.multi();//开启事务,exec执行前,全部进去队列里面
operation.opsForValue().set("k2","v2");
Object value2 = operation.opsForValue().get("k2");//获取k2的值,肯定为null,事务没执行
System.out.println(value2);
operation.opsForValue().set("k3","v3");//获取k2的值,肯定为null,事务没执行
Object value3 = operation.opsForValue().get("k3");
System.out.println(value3);
//执行队列中的命令,如果在监控期间k1发生变化,事务不执行,
return operation.exec();
}) ;
//上面事务执行则有值,不执行为null
System.out.println(redisTemplate.opsForValue().get("k2"));
System.out.println(list);
Map<String,Object> map = new HashMap<>();
map.put("suceess",true);
return map;
}
}
自己设置调试进行查看就行
这时候去修改一下key1的值:
这时候让程序运行到尾部:

不修改的话:

redis流水线:
默认的情况下, Red is 客户端是一条条命令发送给Redis 服务器的,这样显然性能不高。
关系数据库中我们可以使用批量,一次性发送所有的SQL去执行。这样性能提高了不少
对于Redis 也是可以的,这便是流水线( pipline )技术,在很多情况下并不是Redis 性能不佳,而是
网络传输的速度造成瓶颈,使用流水线后就可以大幅度地在需要执行很多命令时提升Redis 的性能。
可以测试一下性能,10w次读写功能
@RestController
@RequestMapping("/pipline")
public class RedisPiplineController {
@Autowired
private RedisTemplate redisTemplate; @RequestMapping("/done")
public Map<String ,Object> testPipline(){ Long startT = System.currentTimeMillis();//系统现在的时间
List list = (List)redisTemplate.executePipelined((RedisOperations operations) ->{
for (int i=1;i<=100000;i++){
operations.opsForValue().set("pipline_"+i,"value_"+i);
String v =(String) operations.opsForValue().get("pipline_"+i);
if (i == 10000){
System.out.println("进入队列,没有执行");
} }
return null;
}); Long endT = System.currentTimeMillis();
System.out.println("用时:"+(endT- startT)+"ms"); Map<String,Object> map = new HashMap<>();
map.put("suceess",true);
return map; } }
return null的时候就已经执行了

注意:
在运行如此多的命令时,需要考虑的另外一个问题是内存空间的消耗,因为对于程序而言,它最终会返回一个List 对象,
如果过多的命令执行返回的结果都保存到这个List 中,显然会造成内存消耗过大,尤其在那些高并发的网站中就很容易
造成JVM 内存溢出的异常, 这个时候应该考虑使用迭代的方法执行Redis 命令
与事务一样,使用流水线的过程中, 所有的命令也只是进入队列而没有执行,所以执行的命
令返回值也为空
Redis的发布与订阅:
发布订阅是消息的一种常用模式
场景:
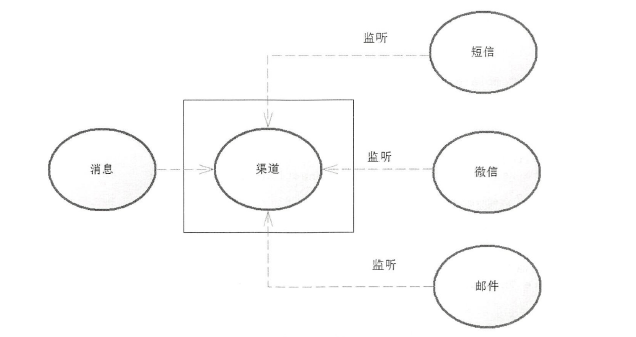
在企业分配任务之后,可以通过邮件、短信或者微信
通知到相关的责任人,这就是一种典型的发布订阅模式。 首先是Redis 提供一个渠道,让消息能够发送到这个渠道上,而多个系统可以监听这个渠道, 如短信、微信和邮件系统
都可以监昕这个渠道,当一条消息发送到渠道,渠道就会通知它的监昕者,这样短信、微信和邮件系统就能够得到这个渠道
给它们的消息了,这些监听者会根据自己的需要去处理这个消息,于是我们就可以得到各种各样的通知了。
11定义一个实现消息监听的类;
@Component
public class RedisListener implements MessageListener { @Override
public void onMessage(Message message, byte[] bytes) {
String body = new String(message.getBody());//获取消息体
String topic = new String(bytes);//获取消息渠道
System.out.println("来自主题为"+topic+"的消息: "+body);
}
}
onMessage 方法是得到消息后的处理方法, 其中message 参数代表Redis 发送过来的消息,
patten是渠道名称,。且也onMessage方法里打印了它们的内容。这里因为标注了@Component 注解,所以
在S pring Boot 扫描后, 会把它自动装配到IoC 容器中。
222创建任务池,开启线程等待处理Redis消息:
//设置任务池
@Configuration
public class ThreadPoolTaskSchedulerConfig { private ThreadPoolTaskScheduler threadPoolTaskScheduler = null; @Bean
public ThreadPoolTaskScheduler initThreadPoolTaskScheduler(){
if (threadPoolTaskScheduler != null){
return threadPoolTaskScheduler;
}
threadPoolTaskScheduler = new ThreadPoolTaskScheduler();
threadPoolTaskScheduler.setPoolSize(20);
return threadPoolTaskScheduler;
}
}
333定义redis的监听容器:
//设置监听容器
@Configuration
public class RedisMessageListenerContainerConfig {
@Autowired
private RedisConnectionFactory connectionFactory; @Qualifier("initThreadPoolTaskScheduler")
@Autowired
private ThreadPoolTaskScheduler threadPoolTaskScheduler; @Autowired
private MessageListener messageListener; @Bean
public RedisMessageListenerContainer initRedisContainer(){
RedisMessageListenerContainer listenerContainer = new RedisMessageListenerContainer();
listenerContainer.setConnectionFactory(connectionFactory);
listenerContainer.setTaskExecutor(threadPoolTaskScheduler); Topic topic = new ChannelTopic("topic1");
listenerContainer.addMessageListener(messageListener,topic);
return listenerContainer;
}
}
444创建测试类,发送消息:
@SpringBootTest
class RedisApplicationTests { @Autowired
private RedisTemplate redisTemplate; @Test
void redisSendMessage() {
int i = 0;
while (true){
redisTemplate.convertAndSend("topic1","你好呀"+i);
i++;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} } }

5555使用Lua脚本
Redis 提供的计算能力还是比较有限的。为了增强Redis的计算能力, Red is 在2.6 版本后提供了Lua 脚本的支持,
执行Lua 脚本在Redis 中还具备原子性,所以在需要保证数据一致性的高并发环境中, 我们也可以
使用Redis 的Lua 语言来保证数据的一致性
Lua 脚本具备更加强大的运算功能, 在高并发需要保证数据一致性时lua脚本的方案比redis自身的事务方案要好一些
Redis两种运行Lua的方法
一种是直接发送Lua 到Redis 服务器去执行
一种是先把Lua 发送给Redis, Redis 会对Lua 脚本进行缓存,然后返回一个SHA l 的32 位编码回来,之后只
需要发送SHAl 和相关参数给Redis便可以执行了
32位编码:
如果Lua 脚本很长, 那么就需要通过网络传递脚本给Redis 去执行了,而现实的情况是网络的传递速度往往跟不上Red is
的执行速度,所以网络就会成为Red is 执行的瓶颈。如果只是传递3 2位编码和参数,那么需要传递的消息就少了许多,
这样就可以极大地减少网络传输的内容,从而提高系统的性能。
为了支持Redis 的Lua 脚本, Spring 提供了RedisScript 接口,与此同时也有一个DefaultRedisScript
实现类。
源码如下:

Spring 会将Lua脚本发送到Redis 服务器进行缓存,而此时Redis 服务器会返回一个3 2 位的SHAl 编码, 通过getShal 方法就可以得到Redis 返回的这个编码了;
getResultType 方法是获取Lua 脚本返回的Java 类型:
getScriptAsString 是返回脚本的字符串
@RestController
@RequestMapping("/lua")
public class RedisLuaController {
@Autowired
RedisTemplate redisTemplate; @RequestMapping("done")
public Map<String,Object> testLua(){
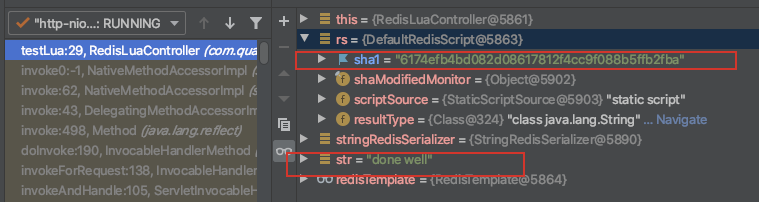
DefaultRedisScript<String> rs = new DefaultRedisScript<>();
//设置脚本
rs.setScriptText("return 'done well'");
rs.setResultType(String.class);//设置返回值类型,不设置,不返回 RedisSerializer<String> stringRedisSerializer = redisTemplate.getStringSerializer();
//执行Lua脚本
String str = (String)redisTemplate.execute(rs,stringRedisSerializer,stringRedisSerializer,null); Map<String,Object> map = new HashMap<>();
map.put("suceess",true);
return map;
} }
上面代码中Lua 只是定义了一个简单的字符串,然后就返回了,而返回类型则定义为宇
符串。这里必须定义返回类型, 否则对于S pring 不会把脚本执行的结果返回。
接着获取了由RedisTemplate 自动创建的字符串序列化器,而后使用RedisTemplate 的execute 方法执行了脚本
RedisTemplate中,execute方法执行脚本的方法以下两种:

script 就是我们定义的RedisScript 接口对象,
keys代表Redis 的键,
args 是这段脚本的参数 两个方法最大区别是一个存在序列化器的参数, 另外一个不存在。 于不存在序列化参数的方法, Spring 将采用RedisTemplate 提供的valueSeri al i zer 序列化器对传递的键
和参数进行序列化。 这里我们采用了第二个方法调度脚本, 并且设置为字符串序列化
器,其中第一个序列化器是键的序列化器, 第二个是参数序列化器,这样键和参数就在字符串序列化器下被序列化了。
端点测试
使用Spring缓存注解操作Redis
Spring 在使用缓存注解前,需要配置缓存管理器,缓存管理器将提供一些重要的信息,如缓
存类型、超时时间等。Spring 可以支持多种缓存的使用,因此它存在多种缓存处理器, 并提供了缓
存处理器的接口CacheManager 和与之相关的类。
redis 主要使用的类RedisCacheManager为主
在Spring Boot 的starter 机制中,允许我们通过配置文件生成缓存管理器,

加粗是比较重要的
配置Redis缓存管理器
缓存注解+myabtis结合
spring.cache.cache-names=redisCache
spring.cache.type=redis
spring.cache.type 配置的是缓存类型,为Redis , SpringBoot 会自动生成RedisCacheManager 对象,
而spring.cache . cache-names 则是配置缓存名称,多个名称可以使用逗号分隔,以便于缓存注解的引用。
为了使用缓存管理器,需要在S pring Boot 的配置文件中加入驱动缓存的注解@EnableCaching,
这样就可以驱动Spring 缓存机制工作了,
注解+Mybatis
11先配置我们的配置文件,包括cache,数据源,mybatis的配置
#注解cache
spring.cache.cache-names=redisCache
spring.cache.type=redis
###数据源
spring.datasource.url=jdbc:mysql://localhost:3306/springboot
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=1997
###mybatis
mybatis.mapper-locations=classpath:mapper/*.xml
mybatis.type-aliases-package=com.quan.annotationredis.entity
#redis
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.password=
spring.redis.jedis.pool.max-wait=2000
spring.redis.jedis.pool.min-idle=5
spring.redis.jedis.pool.max-active=10
spring.redis.jedis.pool.max-idle=10
#
server.port=8012
#######自定义缓存器的配置,配置不多的时候,可以采用默认的缓存管理器
spring.cache.redis.cache-null-values=true
spring.cache.redis.key-prefix=
spring.cache.redis.use-key-prefix=false
#设置十分钟超时,不能从redis缓存里面获取数据,刷新数据
spring.cache.redis.time-to-live=600000
22建立与数据库对应表的实体类:
import org.apache.ibatis.type.Alias; import java.io.Serializable;
//在写mapper.xml的时候,如果需要指定返回值的时候不用使用全限定类名
//直接使用别名user就可以了。
@Alias("user")
public class User implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String userName;
private String note; public Long getId() {
return id;
} public void setId(Long id) {
this.id = id;
} public String getUserName() {
return userName;
} public void setUserName(String userName) {
this.userName = userName;
} public String getNote() {
return note;
} public void setNote(String note) {
this.note = note;
} @Override
public String toString() {
return "User{" +
"id=" + id +
", userName='" + userName + '\'' +
", note='" + note + '\'' +
'}';
}
}
注解@Alias 定义了别名,因为我们在application.properties 文件中定义了这个包作为别名
的扫描,所以它能够被MyBatis 机制扫描,并且将“ user”作为这个类的别名载入到MyBatis 的体系
中。这个类还实现了Serial izable 接口,说明它可以进行序列化。
33操作实体类的mybatis持久层接口UserDao
@Repository
public interface UserDao {
User getUser(Long id);
int insertUser(User user);
int updateUser(User user);
int deleteUser(Long id); List<User> findUsers(@Param("userName") String userName,@Param("note") String note);
}
注解@Repository ,它是Spring 用来标识DAO 层的注解,在MyBatis 体系中则是使
用注解@Mapper 来标识,这里无论使用哪种注解都是允许的,只是我偏爱@Repository 而己,将来我
们可以定义扫描来使得这个接口被扫描为S pring 的Bean 装配到IoC 容器中
44建立持久层接口对应的mapper映射文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.quan.annotationredis.dao.UserDao">
<select id="getUser" resultType="user" parameterType="long">
select id,user_name as userName ,note from user where id = #{id}
</select> <insert id="insertUser" parameterType="user" useGeneratedKeys="true" keyProperty="id">
insert into user (user_name,note) values(#{userName},#{note})
</insert> <update id="updateUser" >
update user
<set>
<if test="userName != null">user_name =#{userName},</if>
<if test="note != note>"> note = #{note},</if>
</set>
where id = #{id}
</update> <select id="findUsers" resultType="user">
select id ,user_name as userName ,note from user
<where>
<if test="userName != null">and user_name =#{userName}</if>
<if test="note != note>">and note = #{note},</if>
</where>
</select> <delete id="deleteUser" parameterType="long">
delete from user where id = #{id}
</delete>
</mapper>
注意文件的位置和配置文件当中的位置应该一致:
src/main/resources/mapper/UserDaoMapper.xml
属性useGeneratedK.eys 设置为位ue ,代表将通过数据库生成主键,而将keyPrope 即设置为POJO 的id 属性,
My Bati s 就会将数据库生成的主键回填到POJO的id 属性中。
55建立service层接口:
public interface UserService {
User getUser(Long id);
int insertUser(User user);
User updateUser(Long id ,String userName);
int deleteUser(Long id);
List<User> findUsers( String userName, String note);
}
66接口对应的实现类:
@Service
public class UserServiceImpl implements UserService { @Autowired
UserDao userDao = null; @Override
@Transactional
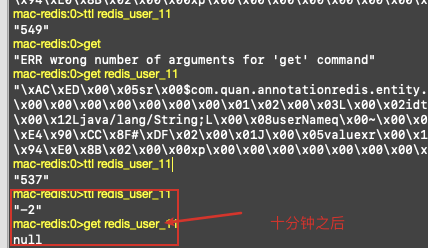
@Cacheable(value = "redisCache",key = "'redis_user_'+#id")
public User getUser(Long id) {
return userDao.getUser(id);
} @Override
@Transactional
@CachePut(value = "redisCache",key = "'redis_user_'+#result.id")
public int insertUser(User user) {
return userDao.insertUser(user);
} @Override
@Transactional
@CachePut(value = "redisCache",condition = "#result != 'null'",key = "'redis_user_'+#id")
public User updateUser(Long id ,String userName) {
User user = this.getUser(id);//自调用
if (user == null){
return null;
}
user.setUserName(userName);//更新缓存,
userDao.updateUser(user);
return user;
} //移除缓存
@Override
@Transactional
@CacheEvict(value = "redisCache",key = "'redis_user_'+#id",beforeInvocation = false)
public int deleteUser(Long id) {
return userDao.deleteUser(id);
} @Override
public List<User> findUsers(String userName, String note) {
return userDao.findUsers(userName,note);
}
}
上面加入了缓存注解,
@CachePut 表示将方法结果返回存放到缓存中。 @Cacheable 表示先从缓存中通过定义的键查询,如果可以查询到数据,则返回,否则执行该方法,返回数据,
并且将返回结果保存到缓存中。 @CacheEvict 通过定义的键移除缓存,它有一个Boolean 类型的配置项beforelnvocation ,表示在方法之前
或者之后移除缓存。因为其默认值为也lfalse ,所以默认为方法之后将缓存移除
缓存中都配置了value =”redisCache”,因为我们在S pring Boot 中配置了对应的缓存名称为“ redisCache ”,
这样它就能够引用到对应的缓存了


redis获取大概在1ms里面
数据库查询3ms
自定义以个缓存管理器;
不改变spring'boot自带的缓存管理器:
通过配置修改:
#######自定义缓存器的配置,配置不多的时候,可以采用默认的缓存管理器
spring.cache.redis.cache-null-values=true
spring.cache.redis.key-prefix=
spring.cache.redis.use-key-prefix=false
#设置十分钟超时,不能从redis缓存里面获取数据,刷新数据
spring.cache.redis.time-to-live=600000
通过代码:
// 自定义缓存管理器:
@Autowired
private RedisConnectionFactory redisConnectionFactory; @Bean(name = "redisCacheManager")
public RedisCacheManager initRedisCacheManager(){
//枷锁的写入器
RedisCacheWriter writer = RedisCacheWriter.lockingRedisCacheWriter(redisConnectionFactory);
//启动redis缓存的默认设置
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
//设置JDK默认序列化器
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer( new
JdkSerializationRedisSerializer()));
//不使用前缀
config = config.disableKeyPrefix();
//有效时间
config = config.entryTtl(Duration.ofMinutes(10));
RedisCacheManager redisCacheManager = new RedisCacheManager(writer,config);
return redisCacheManager;
} }
spring-boot-learning 缓存之redis的更多相关文章
- Spring Boot 2.x整合Redis
最近在学习Spring Boot 2.x整合Redis,在这里和大家分享一下,希望对大家有帮助. Redis是什么 Redis 是开源免费高性能的key-value数据库.有以下的优势(源于Redis ...
- Spring boot配置多个Redis数据源操作实例
原文:https://www.jianshu.com/p/c79b65b253fa Spring boot配置多个Redis数据源操作实例 在SpringBoot是项目中整合了两个Redis的操作实例 ...
- 7、Spring Boot 2.x 集成 Redis
1.7 Spring Boot 2.x 集成 Redis 简介 继续上篇的MyBatis操作,详细介绍在Spring Boot中使用RedisCacheManager作为缓存管理器,集成业务于一体. ...
- Spring Boot 2.x 整合 Redis最佳实践
一.前言 在前面的几篇文章中简单的总结了一下Redis相关的知识.本章主要讲解一下 Spring Boot 2.0 整合 Redis.Jedis 和 Lettuce 是 Java 操作 Redis 的 ...
- Spring Boot 多站点利用 Redis 实现 Session 共享
如何在不同站点(web服务进程)之间共享会话 Session 呢,原理很简单,就是把这个 Session 独立存储在一个地方,所有的站点都从这个地方读取 Session. 通常我们使用 Redis 来 ...
- Spring Boot 如何快速集成 Redis 哨兵?
上一篇:Spring Boot 如何快速集成 Redis? 前面的分享栈长介绍了如何使用 Spring Boot 快速集成 Redis,上一篇是单机版,也有粉丝留言说有没有 Redis Sentine ...
- spring boot 2.0.4 Redis缓存配置
spring boot 2 使用RedisTemplate操作redis存取对象时,需要先进行序列化操作 import org.springframework.cache.CacheManager; ...
- 搞懂分布式技术14:Spring Boot使用注解集成Redis缓存
本文内容参考网络,侵删 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutor ...
- Spring Boot 学习笔记--整合Redis
1.新建Spring Boot项目 添加spring-boot-starter-data-redis依赖 <dependency> <groupId>org.springfra ...
- Spring Boot(十一)Redis集成从Docker安装到分布式Session共享
一.简介 Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API,Redis也是技术领域使用最为广泛的存储中间件,它是 ...
随机推荐
- 力扣第二题 大数相加 ,链表在python到底该怎么写?
但问题在于链表的表示 如何创建一个L3呢 如何用next将他们连接起来呢? 原来是采用 制作链表的形式 l3_pointer.next = ListNode(l1_pointer.val + l2_ ...
- 网络测试技术——802.1X_MD5认证(下篇)
上篇我们讲到802.1X_MD5的简介.认证过程.测试组网以及测试环境准备,本期我们将为大家带来测试的详细步骤: 六.测试仪配置 1.占用端口 端口功能 (1)端口1用来模拟DOT1X和发送流量 (2 ...
- Smartbi:利用好excel分析工具,数据分析都是小case!
数据分析听起来好像很高端的样子,但是实际上在一些IT高手的眼里,只需要掌握以下几个excel数据分析小工具的使用,你也能够成为别人眼中的数据大神! 1.excel数据分析工具--条件格式 快速找出符合 ...
- 【C# 程序集】把自己的程序集添加|卸载 到GAC 全局程序集缓存中
添加全局程序集缓存 Global Assembly Cache Tool (Gacutil.exe) 操作环境windows10+vs2019 cmd.exe位置在 C:\Windows\System ...
- cannot send list of active checks to "127.0.0.1": host [Zabbix server] not monitored
查看错误日志: /etc/log/zabbix/zabbix_server.log 3148:20210404:233938.363 cannot send list of active check ...
- idea教程--Maven 骨架介绍
简单的说,Archetype是Maven工程的模板工具包.一个Archetype定义了要做的相同类型事情的初始样式或模型.这个名称给我们提供来了一个一致的生成Maven工程的方式.Archetype会 ...
- node-java的使用及源码分析
上篇文章简单提了下node调用java的方法但也只属于基本提了下怎么输出helloworld的层度,这次将提供一些案例和源码分析让我们更好地了解如何使用node-java库. 前置知识: 1.桥接模式 ...
- python面试_总结03_列表练习题
1.列表练习题 完成下列列表相关的编程题,先运行下列的test函数,在完成每道题之后,都可以通过调用test函数检测所写函数对错. def test(got, expected): if got == ...
- java面向对象(三)
java面向对象(三) 1.四种权限修饰符 public > protected > (default) > private 注意:(default)并不是关键字default,而是 ...
- JavaWeb-数据库基础
数据库基础 推荐阅读: 数据库:https://www.cnblogs.com/zwtblog/tag/数据库/ 数据库是学习JavaWeb的一个前置,只有了解了数据库的操作和使用,我们才能更好地组织 ...