C++初阶(stack+queue)
stack
stack介绍
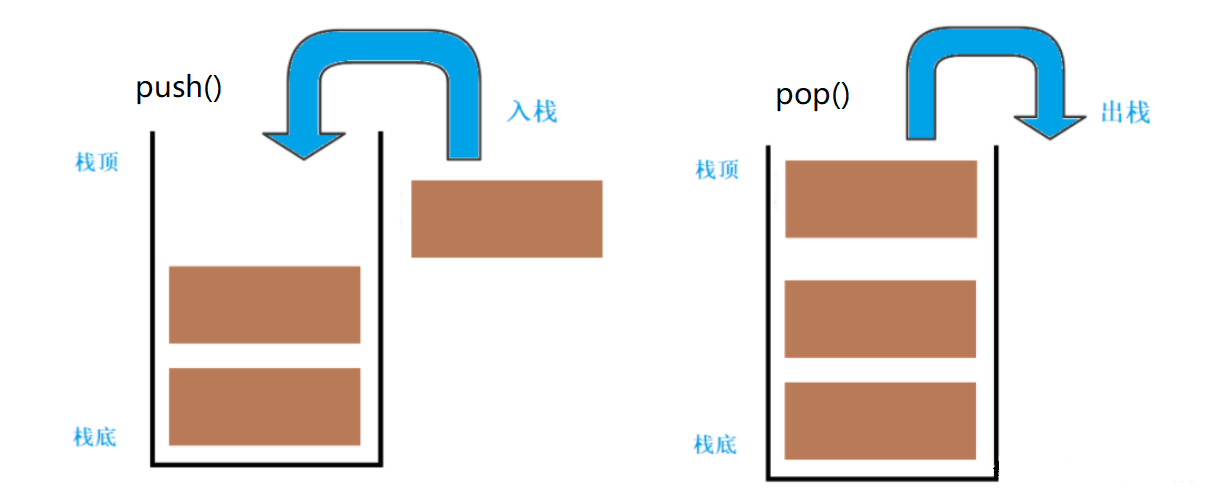
stack是一种先进后出的数据结构,只有一个出口,类似于栈。stack容器哦允许新增元素,移除元素,取得栈顶元素,但是除了最顶端之后,没有任何其他办法可以存取stack的其他元素,换句话说,stack不允许有遍历的行为。
元素推入栈的操作称为:push 元素推出栈的操作称为:pop
概述
- 数据结构:连续的存储空间,只有一个出口,先进后出的特性
- 迭代器:没有迭代器
- 常用的API
- 构造函数
- 赋值
- 数据存取
- 容量大小操作
总结:
- stack是一种容器适配器,专门用在具有后进先出 (last-in first-out)操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
- stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
- stack的底层容器可以是任何标准容器,这些容器需要满足push_back,pop_back,back和empty几个接口的操作。
- 标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器,默认情况下使用deque。
stack常用的接口
//构造函数stack<T> stkT;//stack采用模板类实现,stack对象的默认构造形式stack(const stack &stk);//拷贝构造函数//赋值操作stack&operator=(const stack &stk)//重载等号操作符//数据存取操作push(elem);//向栈顶添加元素pop();//从栈顶移除一个元素top();//返回栈顶元素//容量大小操作empty();//判断堆栈是否为空size();//返回堆栈的大小
queue
queue介绍
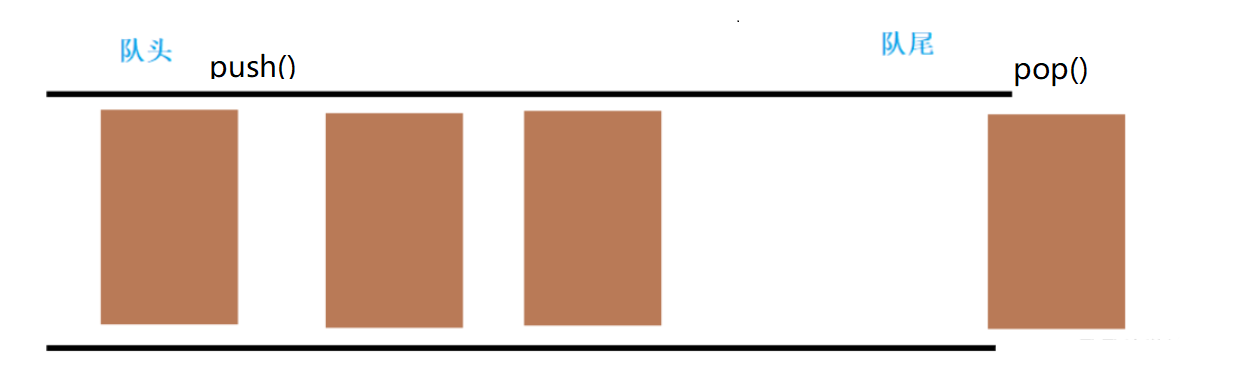
queue是一种先进后出的数据结构(队列),它有两个出口,queue容器允许从一端新增元素,另一端移除元素
概述
- 数据结构:连续的存储空间,有两个口,一个是进入数据,一个是出数据,有先进先出的特性
- 迭代器:没有迭代器
- 常用API
- 构造函数
- 存取、插入和删除
- 赋值
- 大小操作
总结:
- 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。
- 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
- 和stack一样,它的底层容器可以是任何标准容器,但这些容器必满足push_back,pop_back,back和empty几个接口的操作。
- 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque。
queue常用的接口
//构造函数queue<T> queT;//queue采用模板类实现,queue对象的默认构造函数queue(const queue &que);//拷贝构造函数//存取、插入和删除操作push(elem);//往队尾添加元素pop();//从对头移除第一个元素back();//返回最后一个元素front();//返回第一个元素//赋值操作queue&operator=(const queue &que);//重载等号操作符//容量大小操作empty();//判断队列是否为空size();//返回队列的大小
容器适配器
适配器: 一种设计模式,该种模式是将一个类的接口转换成客户希望的另外一个接口。

可以看出的是,这两个容器相比我们之间见过的容器多了一个模板参数,也就是容器类的模板参数,他们在STL中并没有将其划分在容器的行列,而是将其称为容器适配器,它们的底层是其他容器,对其他容器的接口进行了包装,它们的默认是使用deque(双端队列)
deque
vector容器时单向开口的连续内存空间,deque则是一种双向开口的连续线性空间。双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
deque底层结构
它并不是一段连续的空间,而是由多个连续的小空间拼接而成,相当于一个动态的二维数组。
Deque容器是连续的空间,至少逻辑上看来如此,连续现行空间总是令我们联想到 array和vector,array无法成长,vector虽可成长,却只能向尾端成长,而且其成长其实 是一个假象,事实上(1)申请更大空间(2)原数据复制新空间(3)释放原空间三步骤,如果不是vector每次配置新的空间时都留有余裕,其成长假象所带来的代价是非常昂贵的。Deque是由一段一段的定量的连续空间构成。一旦有必要在前端或者尾端增加新的空间,便配置一段连续定量的空间,串接在deque的头端或者尾端。Deque最大的工作就是维护这些分段连续的内存空间的整体性的假象并提供随机存取的接口,避开了重新配置空间,复制,释放的轮回,代价就是复杂的迭代器架构。 既然deque是分段连续内存空间,那么就必须有中央控制,维持整体连续的假象数据结构的设计及迭代器的前进后退操作颇为繁琐。Deque代码的实现远比vector或list都多得多。

Deque采取一块所谓的map作为主控,这里所谓的map是一小块连续的内存空间,其中每一个元素(此时成为一个结点)都是一个指针,指向另一段连续的内存空间,称作缓冲区,缓冲区才是deque的存储空间的主体。
deque的迭代器:

deque的优点:
- 相比于vector,deque可以进行头插和头删,且时间复杂度是O(1),扩容是也不需要大量挪动数据,因此效率是比vector高的。
- 相比于list,deque底层是连续的空间,空间利用率高,,也支持随机访问,但没有vector那么高。
- 总的来说,deque是一种同时具有vector和list两个容器的优点的容器,有一种替代二者的作用,但不是完全替代。
deque的缺点:
- 不适合遍历,因为在遍历是,deque的迭代器要频繁地去检测是否运动到其某段小空间的边界,所以导致效率低下。
- deque的随机访问的效率是比vector低很多的,实际中,线性结构大多数先考虑vector和list。
deque可以作为stack和queue底层默认容器的原因:
- stack和queue并不需要随机访问,也就是说没有触及到deque的缺点,只是对头和尾进行操作。
- 在stack增容时,deque的效率比vector高,queue增容时,deque效率不仅高,而且内存使用率也高。
stack和queue的模拟实现
template<class T, class Container = deque<T>>class stack{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}T top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};template<class T, class Container = deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}T& front(){return _con.front();}T& back(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;};
priority_queue(优先级队列)
template <typename T, typename Container=std::vector<T>, typename Compare=std::less<T>>class priority_queue
priority_queue 实例默认有一个 vector 容器。函数对象类型 less 是一个默认的排序断言,定义在头文件 function 中,决定了容器中最大的元素会排在队列前面。fonction 中定义了 greater,用来作为模板的最后一个参数对元素排序,最小元素会排在队列前面。当然,如果指定模板的最后一个参数,就必须提供另外的两个模板类型参数。
总结几点:
- 优先级队列也是一种容器适配器,它的第一个元素总是最大的。
- 类似于堆,且默认是大堆,在堆中可以插入元素,并且只能检索最大元素。
- 底层容器可以任何标准容器类模板,也可以是其他特定容器类封装作为器底层容器类,需要支持push_back,pop_back,front和empty几个接口的操作。
priority_queue常用的接口
push(const T& obj);//将obj的副本放到容器的适当位置,这通常会包含一个排序操作。push(T&& obj);//将obj放到容器的适当位置,这通常会包含一个排序操作。emplace(T constructor a rgs...);//通过调用传入参数的构造函数,在序列的适当位置构造一个T对象。为了维持优先顺序,通常需要一个排序操作。top();//返回优先级队列中第一个元素的引用。pop();//移除第一个元素。size();//返回队列中元素的个数。empty();//如果队列为空的话,返回true。swap(priority_queue<T>& other);//和参数的元素进行交换,所包含对象的类型必须相同。
void test_priority_queue(){priority_queue<int, vector<int>> pq;pq.push(5);pq.push(7);pq.push(4);pq.push(2);pq.push(6);while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;}
priority_queue的模拟实现
priority_queue的框架
其中模板中有三个参数,最后一个参数是仿函数,也就是指明优先级队列是按照升序还是降序来存数据的
template<class T, class Container = vector<T>, class Compare = less<T>>// 默认是小于class priority_queue{public:private:Container _con;Compare _com;};
仿函数
仿函数(functor),就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了。
// 仿函数 就是一个类重载了一个(),operator(),可以像函数一样使用template<class T>struct greater{bool operator()(const T& a, const T& b){return a > b;}};template<class T>struct less{bool operator()(const T& a, const T& b){return a < b;}};
可以看出,仿函数就是用一个类封装一个成员函数operator(),使得这个类的对象可以像函数一样去调用。
实例演示:
template<class T>struct IsEqual{bool operator()(const T& a, const T& b){return a == b;}};void test(){IsEqual<int> ie;cout << ie(2, 3) << endl;// 该类实例化出的对象可以具有函数行为}
堆的向上调整和向下调整的实现
向上调整: 从最后一个数往上调整
void AdjustUp(int child){int parent = (child - 1) / 2;while (child > 0){if (_con[child] > _con[parent])//< 建小堆 > 建大堆{swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}
向下调整: 从第一个往下调整
void AdjustDown(int parent){int child = parent * 2 + 1;while (child < (int)size()){if (child + 1 < (int)size() && _con[child + 1] > _con[child]){++child;}if (_con[child] > _con[parent])// 建小堆{swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}
这两个函数用仿函数实现后如下:
void AdjustUp(int child){int parent = (child - 1) / 2;while (child > 0){if (_com(_con[parent], _con[child]))// _con[child] > _con[parent]{swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}}void AdjustDown(int parent){int child = parent * 2 + 1;while (child < (int)size()){if (child + 1 < (int)size() && _com(_con[child], _con[child + 1]))// _con[child + 1] > _con[child]{++child;}if (_com(_con[parent], _con[child]))// _con[child] > _con[parent]{swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}
priority_queue的插入和删除
push 先在队尾插入数据,然后用向上调整算法使得堆是大堆或小堆
void push(const T& x){_con.push_back(x);AdjustUp((int)size() - 1);}
pop 先将堆顶的元素和队尾的元素交换,再删去队尾元素(而不是直接删去堆顶元素,这样会破坏堆的结构,然后又要建堆),然后再使用向下调整算法使得堆是大堆或小堆
void pop(){assert(!empty());swap(_con[0], _con[(int)size() - 1]);_con.pop_back();AdjustDown(0);}
priority_queue的存取与大小
//top 返回堆顶元素T& top(){assert(!empty());return _con[0];}//size 返回优先级队列元素个数size_t size(){return _con.size();}//empty 判断优先级队列是否为空bool empty(){return size() == 0;}
C++初阶(stack+queue)的更多相关文章
- 平衡树初阶——AVL平衡二叉查找树+三大平衡树(Treap + Splay + SBT)模板【超详解】
平衡树初阶——AVL平衡二叉查找树 一.什么是二叉树 1. 什么是树. 计算机科学里面的树本质是一个树状图.树首先是一个有向无环图,由根节点指向子结点.但是不严格的说,我们也研究无向树.所谓无向树就是 ...
- Nodejs初阶之express
PS: 2014/09/24 更新<Express 4.X 启航指南>,欢迎阅读和评论:) 老规矩,开头部分都是些自娱自乐的随想,想到哪写到哪... 到今天俺已经在俺厂工作俩年零几天了 ...
- R语言实战(一)介绍、数据集与图形初阶
本文对应<R语言实战>前3章,因为里面大部分内容已经比较熟悉,所以在这里只是起一个索引的作用. 第1章 R语言介绍 获取帮助函数 help(), ? 查看函数帮助 exampl ...
- STL容器适配器 stack, queue
stack是一种后进先出(last in first out)的数据结构.它只有一个出口,如图所示.stack允许新增元素,删除元素,取得最顶端元素.但除了最顶端外,没有其他任何地方可以存储stack ...
- STL容器用法速查表:list,vector,stack,queue,deque,priority_queue,set,map
list vector deque stack queue priority_queue set [unordered_set] map [unordered_map] multimap [uno ...
- Stack&&Queue
特殊的容器:容器适配器 stack queue priority_queue:vector+堆算法---->优先级队列 stack: 1.栈的概念:特殊的线性结构,只允许 ...
- 重温ASP.NET WebAPI(一)初阶
重温ASP.NET WebAPI(一)初阶 前言 本文为个人对WebApi的回顾无参考价值.主要简单介绍WEB api和webapi项目的基本结构,并创建简单地webaapi项目实现CRUD操作. ...
- 数据结构设计 Stack Queue
之前在简书上初步总结过几个有关栈和队列的数据结构设计的题目.http://www.jianshu.com/p/d43f93661631 1.线性数据结构 Array Stack Queue Hash ...
- programming review (c++): (1)vector, linked list, stack, queue, map, string, bit manipulation
编程题常用知识点的review. most important: 想好(1)详尽步骤(2)边界特例,再开始写代码. I.vector #include <iostream> //0.头文件 ...
- js in depth: event loop & micro-task, macro-task & stack, queue, heap & thread, process
js in depth: event loop & micro-task, macro-task & stack, queue, heap & thread, process ...
随机推荐
- GIN and RUM 索引性能比较
gin索引字段entry构造的TREE,在末端posting tree|list 里面存储的是entry对应的行号. 别无其他信息.rum索引,与GIN类似,但是在posting list|tree的 ...
- rpm,docker,k8s三种方式安装部署GitLab服务
rpm方式 源地址:https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/ wget https://mirrors.tuna.tsinghua ...
- 小白入行安全圈内必须知道的top10
OWASP Top10 前言 每年的Top10都在更新,但是一般不会有太大的改变,这里说明的是 2021年的Top10排行榜. A01:访问控制失效(Broken Access Control) 攻击 ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
- 关于IDEA中Tomcat中文乱码的解决方案
进入Tomcat/config文件夹下,打开编辑logging.properties 然后查看该文件内是否存在java.util.logging.ConsoleHandler.encoding = U ...
- 利用FastReport传递图片参数,在报表上展示签名信息
在一个项目中,客户要求对报表中的签名进行仿手写的签名处理,因此我们原先只是显示相关人员的姓名的地方,需要采用手写方式签名,我们的报表是利用FastReport处理的,在利用楷体处理的时候,开发展示倒是 ...
- 4.MongoDB系列之索引(一)
1. 执行计划查看 db.getCollection('users').find({'username': 'shenjian'}).explain('executionStats') 结果查看,先大 ...
- 删除数组里含有a的元素,并且将null值放在后面
想去掉里面含有a的元素,并将null放在后面.放在后面就是往后移,其他值往左移 1 public static void main(String[] args) { 2 //自定义的一个数组 3 St ...
- 解决springboot+vue+mybatis中,将后台数据分页显示在前台,并且根据页码自动跳转对应页码信息
文章目录 先看效果 1.要考虑的问题,对数据进行分页查询 2.前端和后台的交互 先看效果 1.要考虑的问题,对数据进行分页查询 mapper文件这样写 从每次开始查询的位置,到每页展示的条数, < ...
- 8.gitlab服务器搭建(基于centos7)
gitlab服务硬件要求 建议服务器最低配置:2核 2G以上内存(不包含2GB,2GB内存运行的时候内存直接爆掉) 官网给出的推荐配置:4核 4GB内存 支持500个用户,8核 8GB内存 支持100 ...