Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
1、window操作系统的eclipse运行wordcount程序出现如下所示的错误:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:)
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:)
at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at org.apache.hadoop.mapreduce.Job$.run(Job.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:)
at com.bie.hadoop.wordcount.WordCountRunner2.run(WordCountRunner2.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at com.bie.hadoop.wordcount.WordCountRunner2.main(WordCountRunner2.java:)
暂时解决方法如下所示:
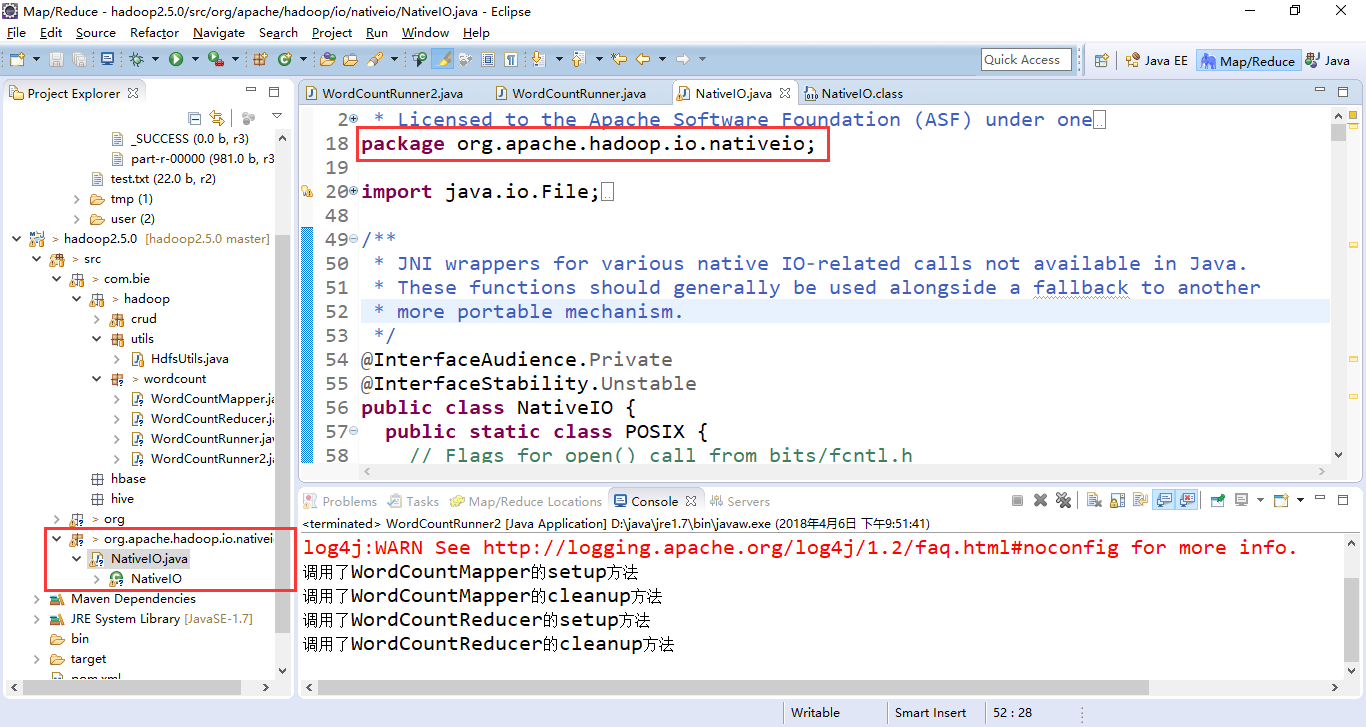
Windows的唯一方法用于检查当前进程的请求,在给定的路径的访问权限,所以我们先给以能进行访问,我们自己先修改源代码,return true 时允许访问。我们下载对应hadoop源代码,hadoop-2.6.0-src.tar.gz解压,D:\biexiansheng\hadoop\hadoop-2.5.0-cdh5.3.6-src\hadoop-2.5.0-cdh5.3.6\hadoop-common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeio下NativeIO.java 复制到对应的Eclipse的project,然后修改557行为return true如图所示:
注意:包的路径必须这样,不能变:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z的更多相关文章
- java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
在 windows 上运行 MapReduce 时报如下异常 Exception in thread "main" java.lang.UnsatisfiedLinkError: ...
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io .nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
首先,遇到这个问题的一个原因是windows环境中没有配置hadoophome.配置之后加入winutils工具 第二个原因,pom中执行的hadoop的版本与window环境中的hadoop的版本不 ...
- MapReduce wordcount 输入路径为目录 java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;)Lorg/apache/hadoop/io/nativeio/NativeIO$POSIX$Stat;
之前windows下执行wordcount都正常,今天执行的时候指定的输入路径是文件夹,然后就报了如题的错误,把输入路径改成文件后是正常的,也就是说目前的wordcount无法对多个文件操作 报的异常 ...
- 本地spark报:java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createFileWithMode0(Ljava/lang/String;JJJI)Ljava/io/FileDescriptor;
我是在运行rdd.saveAsTextFile(fileName)的时候报的错,找了很多说法……最终是跑到hadoop/bin文件夹下删除了hadoop.dll后成功.之前某些说法甚至和这个解决方法自 ...
- java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
环境: Spark2.1.0 .Hadoop-2.7.5 代码运行系统:Win 7在运行Spark程序写出文件(savaAsTextFile)的时候,我遇到了这个错误: // :: ERROR U ...
- [解决]Hadoop 2.4.1 UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0
问题:UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0 我的系统 win7 64位 Hadoop ...
- dbca:Exception in thread "main" java.lang.UnsatisfiedLinkError: get
在64位的操作系统安装oracle10g 软件安装完成后,使用dbca建库的时候报下面的错: $ dbcaUnsatisfiedLinkError exception loading native l ...
- Java中调用c/c++语言出现Exception in thread "main" java.lang.UnsatisfiedLinkError: Test.testPrint(Ljava/lang/String;)V...错误
错误: Exception in thread "main" java.lang.UnsatisfiedLinkError: Test.testPrint(Ljava/lang/S ...
- Exception in thread "main" java.lang.UnsatisfiedLinkError:
[oracle@landor database]$ ./runInstaller 正在启动 Oracle Universal Installer... 检查临时空间: 必须大于 MB. 实际为 MB ...
随机推荐
- ajax跨域请求 Uncaught SyntaxError: Unexpected token :
最近使用前后端分离开发项目比较多,经常碰到的一个问题就是,前端静态页面请求,后端api获取数据,很多时候,前端和后端都不是在同一个域下的(协议,域名,端口). 这里使用的是ajax请求,因为浏览器的同 ...
- linux服务器上配置多个svn仓库
linux服务器上配置多个svn仓库 1.在指定目录建立仓库保存总目录,本文示例目录设定为:/usr/local/svn/svnrepos # mkdir -p /usr/local/svn/svnr ...
- springcloud-4:服务注册(hello-service)
服务端 请见 http://www.cnblogs.com/huiy/p/8668005.html 客户端: 主启动类 import org.springframework.boot.SpringAp ...
- Light OJ 1102
题意: 给你一个数 N , 求分成 K 个数 (可以为 0 ) 的种数: 思路: 类似 在K个抽屉放入 N 个苹果, 不为0, 就是 在 n-1 个空隙中选 m-1个: 为 0, 就可以先在 K 个抽 ...
- 前端 ----jQuery的属性操作
04-jQuery的属性操作 jquery的属性操作模块分为四个部分:html属性操作,dom属性操作,类样式操作和值操作 html属性操作:是对html文档中的属性进行读取,设置和移除操作.比如 ...
- 解决定位工具报错Error while parsing UI hierarchy XML file: Invalid ui automator hierarchy file.
在微信自动化测试中,偶尔会出现某个页面一直无法读取到页面元素的情况,原因是页面未加载完成 解决方式:1.重启APP 2.建议上下滑动当前页面,如朋友圈,会出现滑动到某个地方,出现可以读取到的情况 参考 ...
- Java并发编程的4个同步辅助类(CountDownLatch、CyclicBarrier、Semaphore、Phaser)
我在<JDK1.5引入的concurrent包>中,曾经介绍过CountDownLatch.CyclicBarrier两个类,还给出了CountDownLatch的演示案例.这里再系统总结 ...
- Hystrix浅谈
Hystrix如何使用很多说明,看了很多博客,却发现能说明一些简单概念的文章就没有. 所以本文不太回去说如何使用 Hystrix ,但是会简明的说一下 一些概念 super(Setter.withGr ...
- 点9图 Android设计中如何切图.9.png
转载自:http://blog.csdn.net/buaaroid/article/details/51499516 本文主要介绍如何制作 切图.9.png(点9图),另一篇姊妹篇文章Android屏 ...
- Oracle 高水位说明和释放表空间,加快表的查询速度
高水位的介绍 数据库运行了一段时间,经过一些列的删除.插入.更改操作有些表的高水位线就有可能和实际的表存储数据的情况相差特别多,为了提高检索该表的效率,建议对这些表进行收缩: 查找高水位线的表 查找表 ...