sqoop安装及使用
简介:
sqoop是一款用于hadoop和关系型数据库之间数据导入导出的工具。你可以通过sqoop把数据从数据库(比如mysql,oracle)导入到hdfs中;也可以把数据从hdfs中导出到关系型数据库中。通过将sqoop的操作命令转化为Hadoop的MapReduce作业进行导入导出,(通常只涉及到Map任务)即sqoop生成的Job主要是并发运行MapTask实现数据并行传输以提升数据传送速度和效率,如果使用Shell脚本来实现多线程数据传送则存在很大的难度Sqoop2(sqoop1.99.7)需要在Hadoop安装目录下的配置文件中设置代理,属于重量级嵌入安装,文中我们使用qoop1(Sqoop1.4.6)。
前提:(若不知道如何安装请看我前面写的hadoop分类的文章)
CloudDeskTop上安装了: hadoop-2.7.3 jdk1.7.0_79 mysql-5.5.32 sqoop-1.4.6 hive-1.2.2
master01和master02安装了: hadoop-2.7.3 jdk1.7.0_79
slave01、slave02、slave03安装了: hadoop-2.7.3 jdk1.7.0_79 zookeeper-3.4.10
一、安装:
1、上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到/install/目录下
2、解压:
[hadoop@CloudDeskTop install]$ tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /software/
3、配置环境:
[hadoop@CloudDeskTop software]$ su -lc "vi /etc/profile"
JAVA_HOME=/software/jdk1.7.0_79
HADOOP_HOME=/software/hadoop-2.7.3
SQOOP_HOME=/software/sqoop-1.4.6
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SQOOP_HOME/bin
export PATH JAVA_HOME HADOOP_HOME SQOOP_HOME
4、配置完环境后,执行如下语句,立即生效配置文件:
[hadoop@CloudDeskTop software]$ source /etc/profile
5、进入/software/sqoop-1.4.6/lib/目录,上传mysql-connector-java-5.1.43-bin.jar包
这个地方的数据库驱动包必须选择该版本(5.1.43),因为Sqoop需要对接MySql数据库,如果选择的数据库驱动包不是这个版本,很容易出错。
6、配置sqoop
[hadoop@CloudDeskTop software]$ cd /software/sqoop-1.4.6/bin/
[hadoop@CloudDeskTop bin]$ vi configure-sqoop
注释掉如下代码:用这个符号“:<<COMMENT”作为起始符,“COMMENT”作为结束符;
127 :<<COMMENT
128 ## Moved to be a runtime check in sqoop.
129 if [ ! -d "${HBASE_HOME}" ]; then
130 echo "Warning: $HBASE_HOME does not exist! HBase imports will fail."
131 echo 'Please set $HBASE_HOME to the root of your HBase installation.'
132 fi
133
134 ## Moved to be a runtime check in sqoop.
135 if [ ! -d "${HCAT_HOME}" ]; then
136 echo "Warning: $HCAT_HOME does not exist! HCatalog jobs will fail."
137 echo 'Please set $HCAT_HOME to the root of your HCatalog installation.'
138 fi
139
140 if [ ! -d "${ACCUMULO_HOME}" ]; then
141 echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail."
142 echo 'Please set $ACCUMULO_HOME to the root of your Accumulo installation.'
143 fi
144 if [ ! -d "${ZOOKEEPER_HOME}" ]; then
145 echo "Warning: $ZOOKEEPER_HOME does not exist! Accumulo imports will fail."
146 echo 'Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.'
147 fi
148 COMMENT
二、启动(没说明的都默认是在hadoop用户下操作)
【0、在CloudDeskTop的root用户下启动mysql】
[root@CloudDeskTop ~]# cd /software/mysql-5.5.32/sbin/ && ./mysqld start && lsof -i:3306 && cd -
【1、在slave节点启动zookeeper集群(小弟中选个leader和follower)】
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh start && cd - && jps
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh status && cd -
【2、master01启动HDFS集群】cd /software/ && start-dfs.sh && jps
【3、master01启动YARN集群】cd /software/ && start-yarn.sh && jps
【YARN集群启动时,不会把另外一个备用主节点的YARN集群拉起来启动,所以在master02执行语句:】
cd /software/ && yarn-daemon.sh start resourcemanager && jps
【4、查看进程】
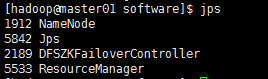
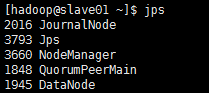
【6、查询sqoop版本来判断sqoop是否安装成功】
[hadoop@CloudDeskTop software]$ sqoop version

三、测试
说明:导入与导出操作的方向是以HDFS集群为基准参考点来定义的,如果数据从HDFS集群流出则表示导出,如果数据流入HDFS集群则表示导入Hive表中的数据实际上是存储到HDFS集群中的,因此对Hive表的导入与导出实际上都是在操作HDFS集群中的文件。
首先,在本地创建数据:
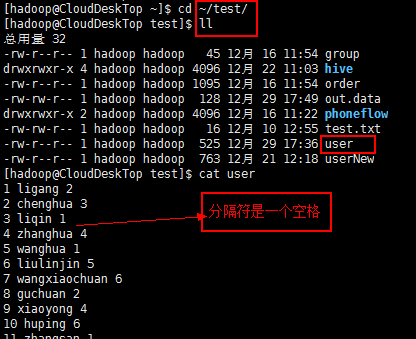
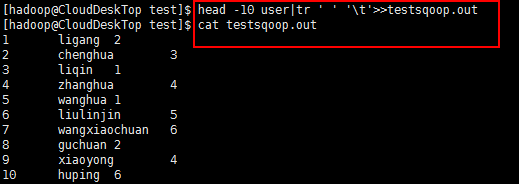
在hive数据库建表后上传到集群中表存放数据的路径下:

[hadoop@CloudDeskTop test]$ hdfs dfs -put testsqoop.out /user/hive/warehouse/mmzs.db/testsqoop
目标一、将hdfs集群的数据导入到mysql数据库中
1、在hive数据库mmzs中创建表,并导入数据
[hadoop@CloudDeskTop software]$ cd /software/hive-1.2.2/bin/
[hadoop@CloudDeskTop bin]$ ./hive
hive> show databases;
OK
default
mmzs
mmzsmysql
Time taken: 0.373 seconds, Fetched: 3 row(s)
hive> create table if not exists mmzs.testsqoop(id int,name string,age int) row format delimited fields terminated by '\t';
OK
Time taken: 0.126 seconds
hive> select * from mmzs.testsqoop;
OK
1 ligang 2
2 chenghua 3
3 liqin 1
4 zhanghua 4
5 wanghua 1
6 liulinjin 5
7 wangxiaochuan 6
8 guchuan 2
9 xiaoyong 4
10 huping 6
Time taken: 0.824 seconds, Fetched: 10 row(s)
2、在mysql数据库中创建相同字段的表
[root@CloudDeskTop bin]# cd ~
[root@CloudDeskTop ~]# cd /software/mysql-5.5.32/bin/
[root@CloudDeskTop bin]# ./mysql -uroot -p123456 -P3306 -h192.168.154.134 -e "create database mmzs character set utf8"
[root@CloudDeskTop bin]# ./mysql -uroot -p123456 -h192.168.154.134 -P3306 -Dmmzs
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 12
Server version: 5.5.32 Source distribution Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show tables;
Empty set (0.00 sec) mysql> create table if not exists testsqoop(uid int(11),uname varchar(30),age int)engine=innodb charset=utf8
-> ;
Query OK, 0 rows affected (0.06 sec) mysql> desc testsqoop;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| uid | int(11) | YES | | NULL | |
| uname | varchar(30) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec) mysql> select * from testsqoop;
Empty set (0.01 sec)
3、使用Sqoop将Hive表中的数据导出到MySql数据库中(整个HDFS文件导出)
[hadoop@CloudDeskTop software]$ sqoop-export --help
17/12/30 21:54:38 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
usage: sqoop export [GENERIC-ARGS] [TOOL-ARGS] Common arguments:
--connect <jdbc-uri> Specify JDBC connect
string
--connection-manager <class-name> Specify connection manager
class name
--connection-param-file <properties-file> Specify connection
parameters file
--driver <class-name> Manually specify JDBC
driver class to use
--hadoop-home <hdir> Override
$HADOOP_MAPRED_HOME_ARG
--hadoop-mapred-home <dir> Override
$HADOOP_MAPRED_HOME_ARG
--help Print usage instructions
-P Read password from console
--password <password> Set authentication
password
--password-alias <password-alias> Credential provider
password alias
--password-file <password-file> Set authentication
password file path
--relaxed-isolation Use read-uncommitted
isolation for imports
--skip-dist-cache Skip copying jars to
distributed cache
--username <username> Set authentication
username
--verbose Print more information
while working Export control arguments:
--batch Indicates
underlying
statements
to be
executed in
batch mode
--call <arg> Populate the
table using
this stored
procedure
(one call
per row)
--clear-staging-table Indicates
that any
data in
staging
table can be
deleted
--columns <col,col,col...> Columns to
export to
table
--direct Use direct
export fast
path
--export-dir <dir> HDFS source
path for the
export
-m,--num-mappers <n> Use 'n' map
tasks to
export in
parallel
--mapreduce-job-name <name> Set name for
generated
mapreduce
job
--staging-table <table-name> Intermediate
staging
table
--table <table-name> Table to
populate
--update-key <key> Update
records by
specified
key column
--update-mode <mode> Specifies
how updates
are
performed
when new
rows are
found with
non-matching
keys in
database
--validate Validate the
copy using
the
configured
validator
--validation-failurehandler <validation-failurehandler> Fully
qualified
class name
for
ValidationFa
ilureHandler
--validation-threshold <validation-threshold> Fully
qualified
class name
for
ValidationTh
reshold
--validator <validator> Fully
qualified
class name
for the
Validator Input parsing arguments:
--input-enclosed-by <char> Sets a required field encloser
--input-escaped-by <char> Sets the input escape
character
--input-fields-terminated-by <char> Sets the input field separator
--input-lines-terminated-by <char> Sets the input end-of-line
char
--input-optionally-enclosed-by <char> Sets a field enclosing
character Output line formatting arguments:
--enclosed-by <char> Sets a required field enclosing
character
--escaped-by <char> Sets the escape character
--fields-terminated-by <char> Sets the field separator character
--lines-terminated-by <char> Sets the end-of-line character
--mysql-delimiters Uses MySQL's default delimiter set:
fields: , lines: \n escaped-by: \
optionally-enclosed-by: '
--optionally-enclosed-by <char> Sets a field enclosing character Code generation arguments:
--bindir <dir> Output directory for compiled
objects
--class-name <name> Sets the generated class name.
This overrides --package-name.
When combined with --jar-file,
sets the input class.
--input-null-non-string <null-str> Input null non-string
representation
--input-null-string <null-str> Input null string representation
--jar-file <file> Disable code generation; use
specified jar
--map-column-java <arg> Override mapping for specific
columns to java types
--null-non-string <null-str> Null non-string representation
--null-string <null-str> Null string representation
--outdir <dir> Output directory for generated
code
--package-name <name> Put auto-generated classes in
this package HCatalog arguments:
--hcatalog-database <arg> HCatalog database name
--hcatalog-home <hdir> Override $HCAT_HOME
--hcatalog-partition-keys <partition-key> Sets the partition
keys to use when
importing to hive
--hcatalog-partition-values <partition-value> Sets the partition
values to use when
importing to hive
--hcatalog-table <arg> HCatalog table name
--hive-home <dir> Override $HIVE_HOME
--hive-partition-key <partition-key> Sets the partition key
to use when importing
to hive
--hive-partition-value <partition-value> Sets the partition
value to use when
importing to hive
--map-column-hive <arg> Override mapping for
specific column to
hive types. Generic Hadoop command-line arguments:
(must preceed any tool-specific arguments)
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions] At minimum, you must specify --connect, --export-dir, and --table
#-m是指定map任务的个数
[hadoop@CloudDeskTop software]$ sqoop-export --export-dir '/user/hive/warehouse/mmzs.db/testsqoop' --fields-terminated-by '\t' --lines-terminated-by '\n' --connect 'jdbc:mysql://192.168.154.134:3306/mmzs' --username 'root' --password '123456' --table 'testsqoop' -m 2
[hadoop@CloudDeskTop software]$ sqoop-export --export-dir '/user/hive/warehouse/mmzs.db/testsqoop' --fields-terminated-by '\t' --lines-terminated-by '\n' --connect 'jdbc:mysql://192.168.154.134:3306/mmzs' --username 'root' --password '123456' --table 'testsqoop' -m 2
17/12/30 22:02:04 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/12/30 22:02:04 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/12/30 22:02:04 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/12/30 22:02:04 INFO tool.CodeGenTool: Beginning code generation
17/12/30 22:02:05 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `testsqoop` AS t LIMIT 1
17/12/30 22:02:05 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `testsqoop` AS t LIMIT 1
17/12/30 22:02:05 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /software/hadoop-2.7.3
注: /tmp/sqoop-hadoop/compile/e2b7e669ef4d8d43016e44ce1cddb620/testsqoop.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
17/12/30 22:02:11 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/e2b7e669ef4d8d43016e44ce1cddb620/testsqoop.jar
17/12/30 22:02:11 INFO mapreduce.ExportJobBase: Beginning export of testsqoop
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/software/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/software/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
17/12/30 22:02:11 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/12/30 22:02:13 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
17/12/30 22:02:13 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
17/12/30 22:02:13 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/12/30 22:02:22 INFO input.FileInputFormat: Total input paths to process : 1
17/12/30 22:02:22 INFO input.FileInputFormat: Total input paths to process : 1
17/12/30 22:02:23 INFO mapreduce.JobSubmitter: number of splits:2
17/12/30 22:02:23 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
17/12/30 22:02:24 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1514638990227_0001
17/12/30 22:02:25 INFO impl.YarnClientImpl: Submitted application application_1514638990227_0001
17/12/30 22:02:25 INFO mapreduce.Job: The url to track the job: http://master01:8088/proxy/application_1514638990227_0001/
17/12/30 22:02:25 INFO mapreduce.Job: Running job: job_1514638990227_0001
17/12/30 22:03:13 INFO mapreduce.Job: Job job_1514638990227_0001 running in uber mode : false
17/12/30 22:03:13 INFO mapreduce.Job: map 0% reduce 0%
17/12/30 22:03:58 INFO mapreduce.Job: map 100% reduce 0%
17/12/30 22:03:59 INFO mapreduce.Job: Job job_1514638990227_0001 completed successfully
17/12/30 22:03:59 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=277282
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=484
HDFS: Number of bytes written=0
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
Job Counters
Launched map tasks=2
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=79918
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=79918
Total vcore-milliseconds taken by all map tasks=79918
Total megabyte-milliseconds taken by all map tasks=81836032
Map-Reduce Framework
Map input records=10
Map output records=10
Input split bytes=286
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=386
CPU time spent (ms)=4950
Physical memory (bytes) snapshot=216600576
Virtual memory (bytes) snapshot=1697566720
Total committed heap usage (bytes)=32874496
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
17/12/30 22:03:59 INFO mapreduce.ExportJobBase: Transferred 484 bytes in 105.965 seconds (4.5675 bytes/sec)
17/12/30 22:03:59 INFO mapreduce.ExportJobBase: Exported 10 records.
运行截图
小结:从运行过程可以看出只有Map任务,没有Reduce任务。
4、在mysql数据库再次查询结果
mysql> select * from testsqoop;
+------+---------------+------+
| uid | uname | age |
+------+---------------+------+
| 1 | ligang | 2 |
| 2 | chenghua | 3 |
| 3 | liqin | 1 |
| 4 | zhanghua | 4 |
| 5 | wanghua | 1 |
| 6 | liulinjin | 5 |
| 7 | wangxiaochuan | 6 |
| 8 | guchuan | 2 |
| 9 | xiaoyong | 4 |
| 10 | huping | 6 |
+------+---------------+------+
10 rows in set (0.00 sec)
从结果可以证明数据导出到mysql数据库成功。
目标二、将mysql的数据导入到hdfs集群中
1、删除hive中mmzs数据库的testsqoop表的数据

确认真的删除了:

2、将mysql中的数据导入到hdfs群
A、指定部分查询数据导入到集群众
[hadoop@CloudDeskTop software]$ sqoop-import --append --connect 'jdbc:mysql://192.168.154.134:3306/mmzs' --username 'root' --password '123456' --query 'select * from mmzs.testsqoop where uid>3 and $CONDITIONS' -m 1 --target-dir '/user/hive/warehouse/mmzs.db/testsqoop' --fields-terminated-by '\t' --lines-terminated-by '\n'
[hadoop@CloudDeskTop software]$ sqoop-import --append --connect 'jdbc:mysql://192.168.154.134:3306/mmzs' --username 'root' --password '123456' --query 'select * from mmzs.testsqoop where uid>3 and $CONDITIONS' -m 1 --target-dir '/user/hive/warehouse/mmzs.db/testsqoop' --fields-terminated-by '\t' --lines-terminated-by '\n'
17/12/30 22:40:54 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/12/30 22:40:54 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/12/30 22:40:55 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/12/30 22:40:55 INFO tool.CodeGenTool: Beginning code generation
17/12/30 22:40:55 INFO manager.SqlManager: Executing SQL statement: select * from mmzs.testsqoop where uid>3 and (1 = 0)
17/12/30 22:40:55 INFO manager.SqlManager: Executing SQL statement: select * from mmzs.testsqoop where uid>3 and (1 = 0)
17/12/30 22:40:55 INFO manager.SqlManager: Executing SQL statement: select * from mmzs.testsqoop where uid>3 and (1 = 0)
17/12/30 22:40:55 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /software/hadoop-2.7.3
注: /tmp/sqoop-hadoop/compile/cd00e059648175875074eed7f4189e0b/QueryResult.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
17/12/30 22:40:58 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/cd00e059648175875074eed7f4189e0b/QueryResult.jar
17/12/30 22:40:58 INFO mapreduce.ImportJobBase: Beginning query import.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/software/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/software/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
17/12/30 22:40:59 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/12/30 22:41:01 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/12/30 22:41:08 INFO db.DBInputFormat: Using read commited transaction isolation
17/12/30 22:41:09 INFO mapreduce.JobSubmitter: number of splits:1
17/12/30 22:41:09 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1514638990227_0003
17/12/30 22:41:10 INFO impl.YarnClientImpl: Submitted application application_1514638990227_0003
17/12/30 22:41:10 INFO mapreduce.Job: The url to track the job: http://master01:8088/proxy/application_1514638990227_0003/
17/12/30 22:41:10 INFO mapreduce.Job: Running job: job_1514638990227_0003
17/12/30 22:41:54 INFO mapreduce.Job: Job job_1514638990227_0003 running in uber mode : false
17/12/30 22:41:54 INFO mapreduce.Job: map 0% reduce 0%
17/12/30 22:42:29 INFO mapreduce.Job: map 100% reduce 0%
17/12/30 22:42:31 INFO mapreduce.Job: Job job_1514638990227_0003 completed successfully
17/12/30 22:42:32 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=138692
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=94
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=32275
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=32275
Total vcore-milliseconds taken by all map tasks=32275
Total megabyte-milliseconds taken by all map tasks=33049600
Map-Reduce Framework
Map input records=7
Map output records=7
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=170
CPU time spent (ms)=2020
Physical memory (bytes) snapshot=109428736
Virtual memory (bytes) snapshot=851021824
Total committed heap usage (bytes)=19091456
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=94
17/12/30 22:42:32 INFO mapreduce.ImportJobBase: Transferred 94 bytes in 91.0632 seconds (1.0322 bytes/sec)
17/12/30 22:42:32 INFO mapreduce.ImportJobBase: Retrieved 7 records.
17/12/30 22:42:32 INFO util.AppendUtils: Appending to directory testsqoop
在集群中查询是否真的导入了数据:

在hive数据库中中查询是否真的导入了数据:
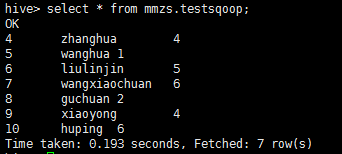
从结果可以证明数据导入到hdfs集群成功。
删除集群数据,方便下次导入操作:
[hadoop@master01 software]$ hdfs dfs -rm -r /user/hive/warehouse/mmzs.db/testsqoop/part-m-00000
B、指定一张表,整个表的数据一起导入到集群中
sqoop-import --append --connect 'jdbc:mysql://192.168.154.134:3306/mmzs' --username 'root' --password '123456' --table testsqoop -m 1 --target-dir '/user/hive/warehouse/mmzs.db/testsqoop/' --fields-terminated-by '\t' --lines-terminated-by '\n'
[hadoop@CloudDeskTop software]$ sqoop-import --append --connect 'jdbc:mysql://192.168.154.134:3306/mmzs' --username 'root' --password '123456' --table testsqoop -m 1 --target-dir '/user/hive/warehouse/mmzs.db/testsqoop/' --fields-terminated-by '\t' --lines-terminated-by '\n'
17/12/30 22:28:31 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
17/12/30 22:28:31 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
17/12/30 22:28:32 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
17/12/30 22:28:32 INFO tool.CodeGenTool: Beginning code generation
17/12/30 22:28:33 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `testsqoop` AS t LIMIT 1
17/12/30 22:28:33 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `testsqoop` AS t LIMIT 1
17/12/30 22:28:33 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /software/hadoop-2.7.3
注: /tmp/sqoop-hadoop/compile/d427f3a0d1a3328c5dc9ae1bd6cbd988/testsqoop.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
17/12/30 22:28:36 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/d427f3a0d1a3328c5dc9ae1bd6cbd988/testsqoop.jar
17/12/30 22:28:36 WARN manager.MySQLManager: It looks like you are importing from mysql.
17/12/30 22:28:36 WARN manager.MySQLManager: This transfer can be faster! Use the --direct
17/12/30 22:28:36 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
17/12/30 22:28:36 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)
17/12/30 22:28:36 INFO mapreduce.ImportJobBase: Beginning import of testsqoop
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/software/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/software/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
17/12/30 22:28:36 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
17/12/30 22:28:38 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
17/12/30 22:28:45 INFO db.DBInputFormat: Using read commited transaction isolation
17/12/30 22:28:45 INFO mapreduce.JobSubmitter: number of splits:1
17/12/30 22:28:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1514638990227_0002
17/12/30 22:28:46 INFO impl.YarnClientImpl: Submitted application application_1514638990227_0002
17/12/30 22:28:47 INFO mapreduce.Job: The url to track the job: http://master01:8088/proxy/application_1514638990227_0002/
17/12/30 22:28:47 INFO mapreduce.Job: Running job: job_1514638990227_0002
17/12/30 22:29:29 INFO mapreduce.Job: Job job_1514638990227_0002 running in uber mode : false
17/12/30 22:29:29 INFO mapreduce.Job: map 0% reduce 0%
17/12/30 22:30:06 INFO mapreduce.Job: map 100% reduce 0%
17/12/30 22:30:07 INFO mapreduce.Job: Job job_1514638990227_0002 completed successfully
17/12/30 22:30:08 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=138842
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=87
HDFS: Number of bytes written=128
HDFS: Number of read operations=4
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=33630
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=33630
Total vcore-milliseconds taken by all map tasks=33630
Total megabyte-milliseconds taken by all map tasks=34437120
Map-Reduce Framework
Map input records=10
Map output records=10
Input split bytes=87
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=177
CPU time spent (ms)=2490
Physical memory (bytes) snapshot=109060096
Virtual memory (bytes) snapshot=850882560
Total committed heap usage (bytes)=18972672
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=128
17/12/30 22:30:08 INFO mapreduce.ImportJobBase: Transferred 128 bytes in 89.4828 seconds (1.4304 bytes/sec)
17/12/30 22:30:08 INFO mapreduce.ImportJobBase: Retrieved 10 records.
17/12/30 22:30:08 INFO util.AppendUtils: Appending to directory testsqoop
运行结果
在集群中查询是否真的导入了数据:

在hive数据库中中查询是否真的导入了数据:
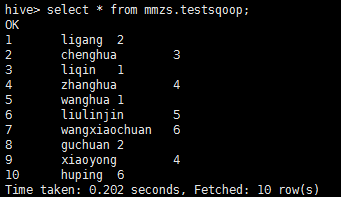
从结果可以证明数据导入到hdfs集群成功。
sqoop安装及使用的更多相关文章
- 如何将mysql数据导入Hadoop之Sqoop安装
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
- Sqoop安装与应用过程
1. 参考说明 参考文档: http://sqoop.apache.org/ http://sqoop.apache.org/docs/1.99.7/admin/Installation.html ...
- sqoop安装部署(笔记)
sqoop是一个把关系型数据库数据抽向hadoop的工具.同时,也支持将hive.pig等查询的结果导入关系型数据库中存储.由于,笔者部署的hadoop版本是2.2.0,所以sqoop的版本是:sqo ...
- sqoop安装与简单实用
一,sqoop安装 1.解压源码包 2.配置环境变量 3.在bin目录下的 /bin/configsqoop 注释掉check报错信息 4.配置conf目录下 /conf/sqoop-env.sh 配 ...
- cdh版本的sqoop安装以及配置
sqoop安装需要提前安装好sqoop依赖:hadoop .hive.hbase.zookeeper hadoop安装步骤请访问:http://www.cnblogs.com/xningge/arti ...
- [Hadoop] Sqoop安装过程详解
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可 ...
- hadoop(八) - sqoop安装与使用
一. sqoop安装: 安装在一台节点上就能够了. 1. 使用winscp上传sqoop 2. 安装和配置 加入sqoop到环境变量 将数据库连接驱动mysql-connector-5.1.8.jar ...
- sqoop 安装
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
- Sqoop 安装部署
1. 上传并解压 Sqoop 安装文件 将 sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 安装包上传到 node-01 的 /root/ 目录下并将其解压 [root@no ...
- Sqoop安装及操作
一.集群环境: Hostname IP Hadoop版本 Hadoop 功能 系统 node1 192.168.1.151 0.20.0 namenode hive+sqoop rhel5.4X86 ...
随机推荐
- Docker优势以及与传统虚拟机对比(1)
docker优势 1.更快速地交付和部署: 2.更高的虚拟化(不需要额外的hypervisor支持,是内核级的虚拟化,实现更高的性能呢和效率): 3.更轻松的迁移和扩展: 4.更简单的管理 与传统的 ...
- Spring Boot中使用Spring Security进行安全控制转载来自翟永超
我们在编写Web应用时,经常需要对页面做一些安全控制,比如:对于没有访问权限的用户需要转到登录表单页面.要实现访问控制的方法多种多样,可以通过Aop.拦截器实现,也可以通过框架实现(比如:Apache ...
- 用python实现文件自动上传
一.简介 用python实现文件自动上传,主要源于在测试项目中想实现自动化上传文件功能,无须手工输入.比如从windows到Linux,或从Linux到windows,或从Linux到Linux. 主 ...
- Debian 8下手工安装 Eclipse CDT neon.2
从 http://www.eclipse.org/downloads/packages/eclipse-ide-cc-developers/neon2 下载 eclipse-cpp-neon-2-li ...
- lua 使用中遇到的坑总结
前言 竹子是 java 程序员一枚,最近在做一个登录的改造,用 lua 实现,现在基本算是告一段落,然后在此分享下在过程中遇到的坑吧. 一定要注意使用 lua 的版本,版本不同,可能有的函数就没有了, ...
- Eclipse项目里面看源码和文档
Eclipse项目里面看源码 1.新建项目列表 2.进入struts2-core-2.3.20.jar,双击之后,看不到源码 3.右键struts2-core-2.3.20.jar,选择propert ...
- Shader_ShaderForge_NGUI_流光&波纹&消融
Shader篇 总结:总算解决了NGUI中Shader不能实时更改的问题,原来NGUI中的Texture组件提供了OnRender代码示例如下 /*************************** ...
- Ajax获取Json多个集合并同时遍历
Ajax获取Json多个集合并同时遍历: 方法一.:将多个集合放入MAP集合. 后台:Servlet @Override protected void doPost(HttpServletReques ...
- [ARCH] 1、virtualbox中安装archlinux+i3桌面,并做简单美化
星期六, 28. 七月 2018 02:42上午 - beautifulzzzz 1.安装ArchLinux系统 安装Arch主要看其wiki,比较详细- 中文的我主要参考:一步步教你如何安装 Arc ...
- 手工检测SQL注入漏洞
SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令,具体来说,它是利用现有应用程序将(恶意的)SQL命令注入到后台数据库引擎执 ...