TensorFlow中的Placement启发式算法模块——Placer
背景
[作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor]
受限于单个Device的计算能力和存储大小,许多深度学习模型都有着使用模型分片或相关策略的需求。模型分片的本质是将模型和相关的计算切分到不同的Device,这样做不但可以解决单个Device放不下大模型的问题,还有可能有计算加速的收益。在深度学习框架方面,显然TensorFlow比Caffe具有更高的灵活性,这主要得益于TensorFlow的Placement机制。Placement是TensorFlow引入的特有概念,它是指某个Op被放在了哪一个Device上,因此模型分片问题实际上就是该模型上每个Op的Placement设置问题。在Python层面,一共存在两个API与Placement相关的接口,它们不但广泛存在与框架代码中,还可以被用户拿来直接使用。但是用户指定Placement信息存在一定的不可靠性,它与Op的实际情况往往存在一定的矛盾,而TensorFlow中的Placer就是解决这个问题的模块。
Placer功能描述
首先看一下NodeDef的结构,有两个地方和Placement相关。一个是device属性,它显示指定了这个Node应该被放在何种Device上,另一个是字符串标记loc:@xxxx,这是placement的约束条件,隐式指明该Node的Placement应该和哪些Node保持一致。准确地说,该Node应该和组名为xxxx内的所有Node的Placement保持一致,这两个信息有时候会出现矛盾的情形。
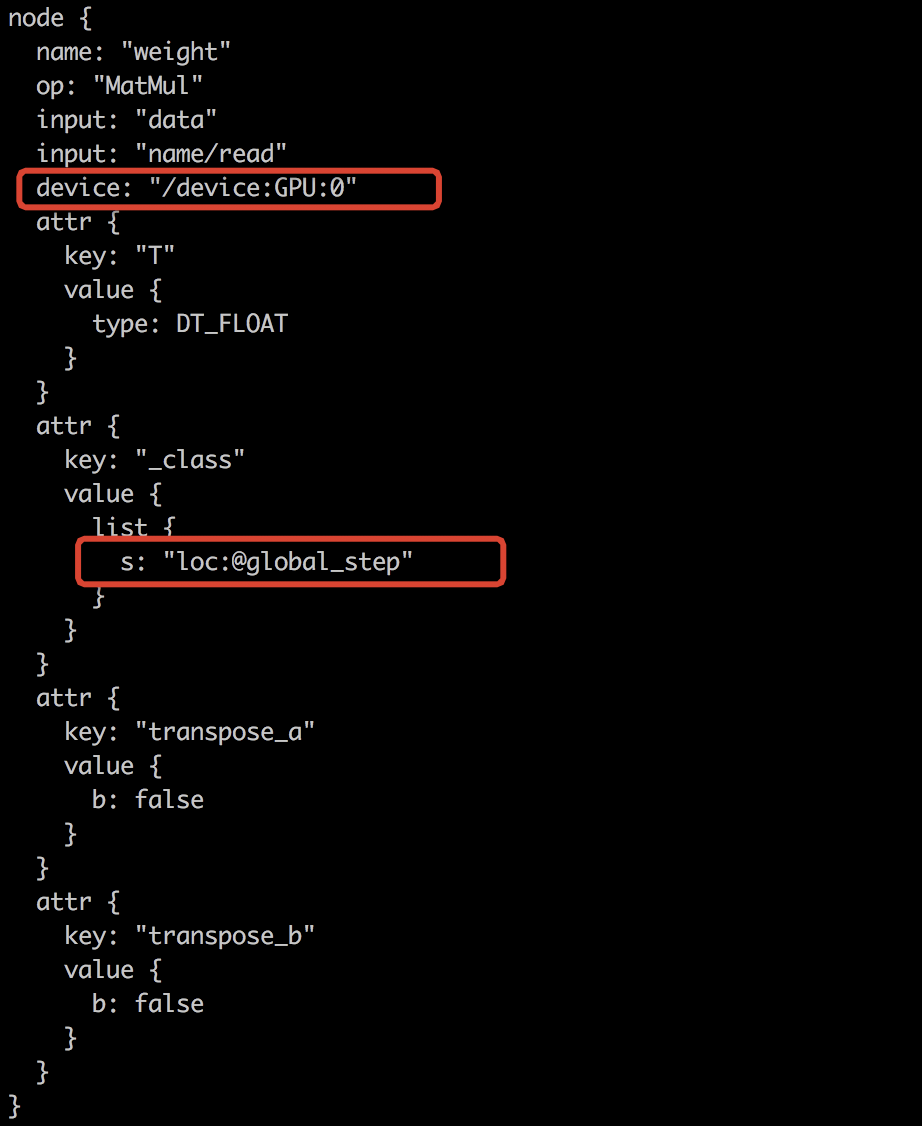
Placer不但要处理二者的矛盾,还要通过一些规则尽可能避免因Placement不当带来的性能问题。每个Node在经过Placer处理后都会得到最终的Placement信息,它将重新覆盖NodeDef中的device属性内容。所以,通俗地讲,Placer的功能就是计算并填入所有NodeDef的device属性。
前驱内容
阅读代码时难免会碰到一些为解决这个问题专门设立的名词和经典的算法,所以建议在阅读Placer模块相关内容之前先确认已经弄清楚下面的东西,避免走一些弯路。
重要概念
Placement:每个Op的属性信息,它显式地指明了某个Op应该被放置在哪一个Device上计算
Colocation Group:这也是每个Op的Placement相关的属性信息,从NodeDef上看就是字符串为loc:@xxxx字样的内容。它是若干Node的集合,在算法中又被称为约束(Constraint)条件。属于同一个Colocation Group中的所有Node被约束为必须要具有相同的Placement信息。这是Placement信息的隐式表达,它和Placement可以同时被指定,因此存在矛盾的情况。如果发生冲突,则直接报错
相关算法
Find-Union算法:并查集算法,TensorFlow通过FInd-Union算法高效地处理了Node的Colocation问题。这里只讲一下概述,具体请参考这篇博客。“并”和“查”是两个问题,“并”指的是多个具有属性的Element合并到某个Group,并对Group的属性做修改的过程。“查”指的是查询某个Element所在的Group的属性过程。当发生“并”时,由于新元素的添加,势必会引起Group属性的修改,如何设计较好的数据结构高效的解决这两个问题是并查集算法的核心。
Placer决策基本原则
Placer会根据会对Graph进行一定程度的分析,并结合用户的要求对每个Node的Placement进行微调,微调的原则可以概括为下面四点
1. 尽可能满足用户要求(User Requirement First):每个Node的placement会尽量满足用户的要求
2. 尽可能使用计算更快的设备 (High Performance Device):若某个Node的Placement没有被用户指定,则优先分配计算更快的设备
3. 保证程序可运行(Runable):若某个Node不存在用户要求的Placement相关实现版本,会退而求其次选择其它实现版本,保障程序可以用
4. 尽可能考虑近邻特性(Near When Possible):在做Placement的微调时考虑节点的近邻特性,尽可能减少无意义的拷贝
尽可能满足用户要求(User Requirement First)
用户要求分为两种,一种是显示指定,表现为在Node中设置的device信息;另一种是隐式指定,表现为loc:@xxxx属性,即Colocation Group。Placer会根据用户这两方面的要求并结合实际情况做Placement信息补全和微调。文章开头的截图展示了某个Node的NodeDef信息,它表明类型为MatMul的Op被用户显示指定放到'/device:GPU:0'上,同时希望放入名为global_step的Colocation Group中。NodeDef中的device属性和loc:@xxxx属性分别由下面两个python级别的API引入,它们都由用户来控制,有些被用在高层API内部封装中。
# device attributes
@tf_export("device")
def device(device_name_or_function): # colocation attributes
@tf_export("colocate_with")
def colocate_with(op, ignore_existing=False):
尽可能使用更快的计算设备(High Performance Device)
如果某个Node的device属性中不含device_type(即GPU或CPU),那么Placer必须决定使用何种Device。每种Device注册到TensorFlow中时都带有优先级,通常高优先级的Device具有更好的计算性能。当某个Op具有多种Device实现时,Placer将选取优先级最高的Device实现版本,通过设置device_type为所有实现版本中最高优先级的Device来实现这种选取。
保证程序可运行(Runable)
这是通过Soft Placement机制保证的。如果某个Node被显示指定精确放在某Device上,但系统中却没有该Device上的实现版本,那么为了保证程序可用,Soft Placement将发挥作用。它将忽略device type,在系统中按照Device优先级选取另一个可用的实现版本重新改写Placement。举例而言,假设某Node的op是SparseToDense,device_type被指定为GPU,但目前SparseToDense在TensorFlow中只有CPU的实现,那么Soft Placement将改写该Node的device_type为CPU。
尽可能考虑近邻特性(Near When Possible)
在Placer中使用以下三种启发式规则来实现这一原则。
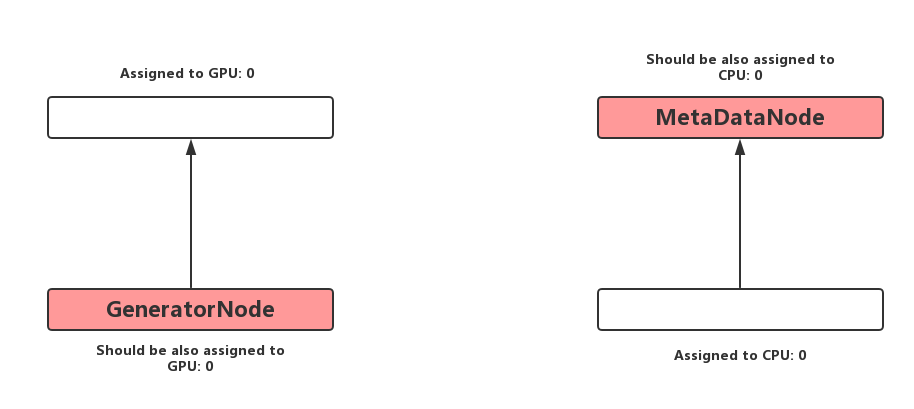
a. 若某个Node是GeneratorNode(0-indegree,1-outdegree,且输出非reference type),将其与Consumer具有相同的Placement可以防止无意义的跨Device拷贝。这一步在算法中被称之为启发式规则A。
b. 若某个Node是MetaDataNode(直接在Tensor的元数据MetaData上操作,比如Reshape),将其与Producer具有相同的Placemen可以防止无意义的跨Device拷贝。这一步在算法中被称为启发式规则B。
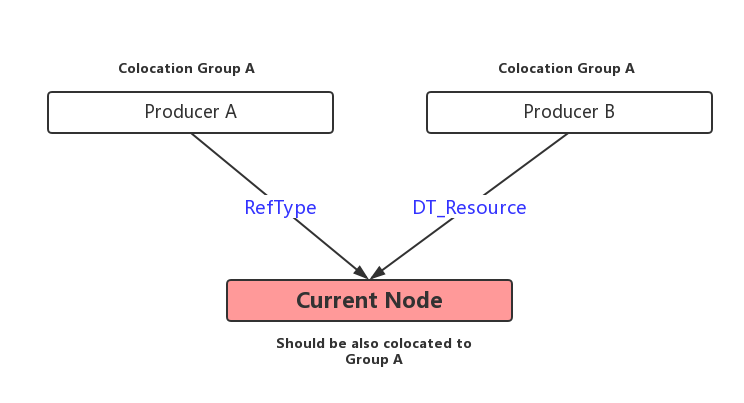
c. 若某个Node的输入是Reference type或者是Reource type,那么尽量将其与输入放在同一个Colocation Group中。算法中没有为这个步骤起名字,为了方便我们称之为启发式规则C。
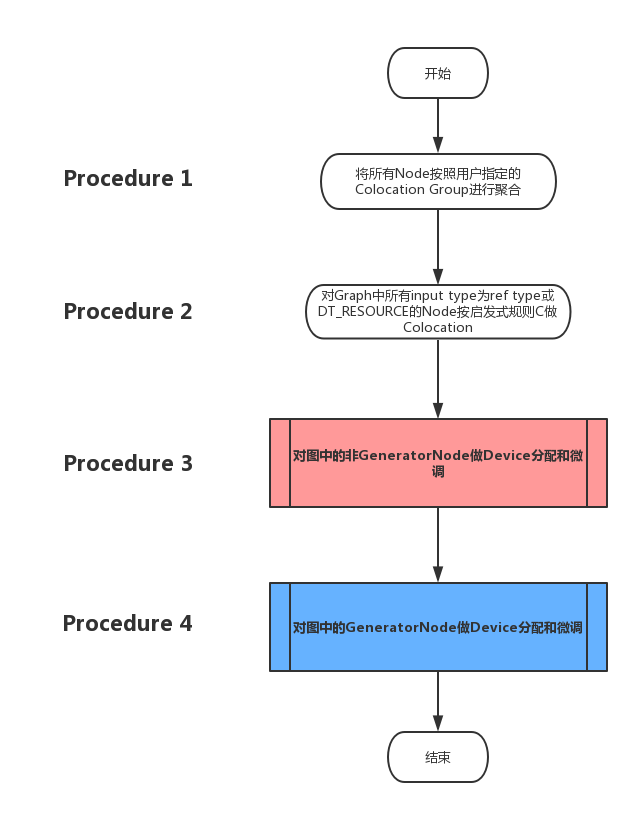
Placer决策算法总体流程
总体流程分为四个步骤,下图展示了宏观层面的流程图。其中最后两个步骤相对较为复杂,下一小节中将会细化其流程图。
Placer算法决策分步详解与关键代码对照
第一步——根据用户指定做Colocation Group
一般情况下,没有被用户指定Colocation Group信息的Node会被单独放入一个Group中作为唯一的成员,并以该Node的Name作为Group的名字,所以Graph中每个Node都会有自己的Colocation Group。从逻辑上来说,合并多个Group是非常简单的问题,但是这个场景中的Group不仅是Node的集合,还包含若干属性,比如某个Group的possible device表示这个Group可用的所有Device集合。因此我们需要一种数据结构和算法,帮助我们在合并两个Group时很方便地生成新Group及相关属性(方便Union),并且能够根据某个Node快速查看所属Group的所有属性(快速Find),这就是Find-Union的优势所在。Find-Union算法原理将不在这里描述,这里只给出代码中Find-Union用到的基本数据结构——Member,它用来描述Group的基本信息。在阅读下段代码注释前,需要对Find-Union中的树形结构含义有基本的理解。
// Represents a node in the disjoint node set forest, and the
// accumulated constraints on the device used by that node.
struct Member {
Member() = default;
// The id of the node that is the parent of this one, or its own
// id if it is a root. parent <= 0 indicates that this member is invalid.
int parent = -; // A proxy for the depth of the tree that is used to prefer
// connecting smaller trees to larger trees when merging disjoint
// sets.
int rank = ; // The intersection of all device types supported by this node,
// and those of all of its children, in priority order
// of the preferred device.
DeviceTypeVector supported_device_types; // The merged form of the device requested for this node, with
// those of all of its children.
DeviceNameUtils::ParsedName device_name; // If this node is a root, stores a list of Devices to which this node
// and all of its children have been assigned, or nullptr if this
// has not yet been computed.
std::vector<Device*> possible_devices;
};
下面的代码是处理这一步骤的核心代码。首先创建ColocationGraph对象,这是一个处理Colocation Group的工具类,里面使用了Find-Union算法对Group进行聚合。在调用InitiailizeMembers对Find-Union算法的基本数据结构进行初始化之后,就直接调用ColocationAllNodes根据用户指定的所有colocation信息进行聚合。
ColocationGraph colocation_graph(
graph_, devices_,
options_ == nullptr || options_->config.allow_soft_placement(),
default_device_); TF_RETURN_IF_ERROR(colocation_graph.InitializeMembers()); // 1. First add all of the nodes. Note that steps (1) and (2)
// requires two passes over the nodes because the graph (and hence
// the constraints) may not be acyclic.
TF_RETURN_IF_ERROR(colocation_graph.ColocateAllNodes());
第二步——启发式规则C的运用
这一步将对Colocation Group进行调整。在遍历Graph的每个Node时,需要根据Node input来决定是否将该Node所在的Group与Source Node所在的Group合并。如果Node的input是ref_type或者DT_RESOURCE(关于DT_RESOURCE一般会在使用ResourceVariable时才会碰到。ResourceVariable与Variable相比具有很多新特性,这些特性是TF2.0中主推的内容。关于它的优势我们不在这里展开,只对其Op的类型做一个说明。Variable在C++层面的Op类型是VariableV2,而ResourceVariable在C++层面的Op类型为VarHandleOp。后者产生的Tensor就是一种DT_RESOURCE),那么就尝试做合并。在合并之前需要做必要的可行性检查,适当地主动报错。比如在合并时除了要考虑这一对节点的连接以外,还需要考虑这个Node的其他输入是否属于ref_type或者DT_RESOURCE。这一部分的代码比较长,但相对比较简单,这里不再展示。
第三步——启发式规则B的运用
从这一步开始,Placer才开始真正的为每个Node分配Device,下面的流程图中展示了这一步骤。
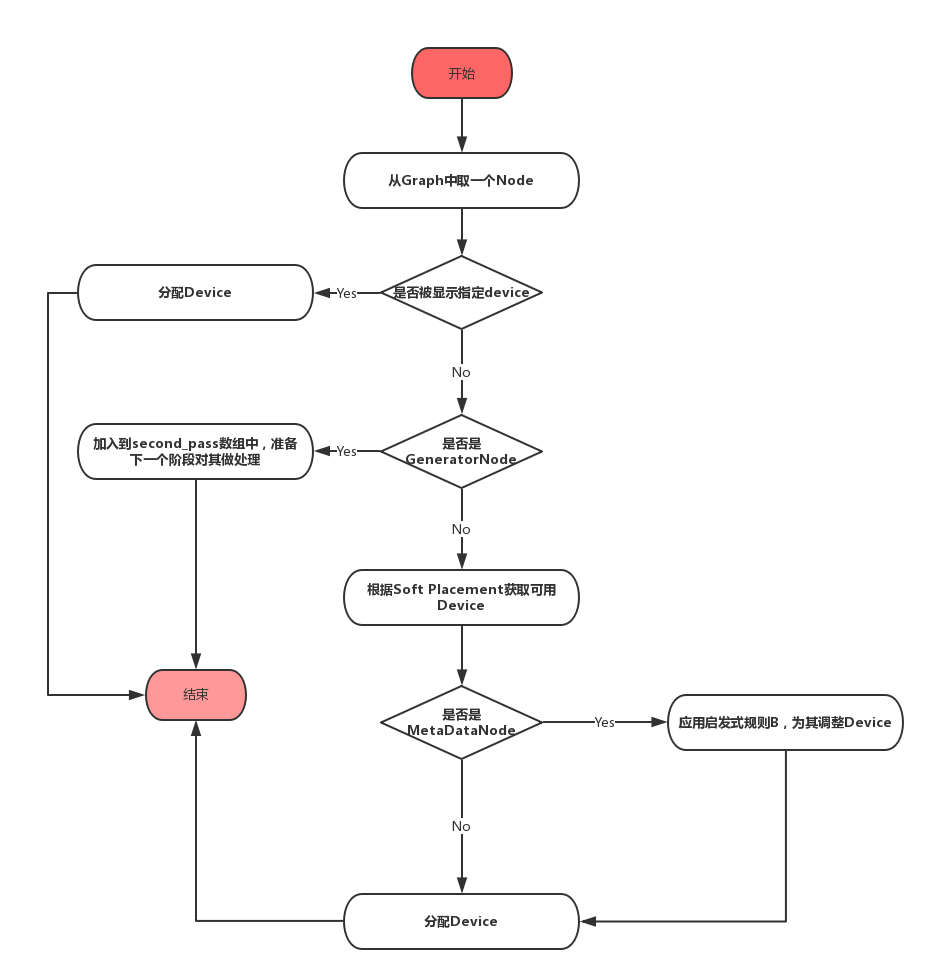
1. 如果当前的Node的device属性中已经有值,那么Placer将不再对其做重复的assign操作,直接跳过这个Node。
2. 如果当前Node是GeneratorNode,先将其放入一个名为second_pass的vector中。
3. 如果不是以上两种情况,那么该Node正是这一步骤需要处理的对象。先从该Node所在的Colocation Group中获取可用的Devices(获取会受到Soft Placement的影响)作为候选。如果该node是MetaData node,那么会尝试应用启发式规则B,否则,将分配候选集中优先级最高的Device。
下面的代码展示了对MetaDataNode的处理逻辑,这就是启发式规则B的代码。
int assigned_device = -;
// Heuristic B: If the node only operates on metadata, not data,
// then it is desirable to place that metadata node with its
// input.
if (IsMetadata(node)) {
// Make sure that the input device type is in the list of supported
// device types for this node.
const Node* input = (*node->in_edges().begin())->src();
// TODO(vrv): if the input is empty, consider postponing this
// node's assignment to the second pass, so that we handle the
// case where a metadata node's input comes from a backedge
// of a loop.
if (CanAssignToDevice(input->assigned_device_name(), *devices)) {
assigned_device = input->assigned_device_name_index();
}
}
// Provide the default, if necessary.
if (assigned_device == -) {
assigned_device = graph_->InternDeviceName((*devices)[]->name());
}
AssignAndLog(assigned_device, node);
第四步——启发式规则A的运用
这一步将对second_pass数组中的所有的Node分配Device,下面的流程图中展示了这一步骤。
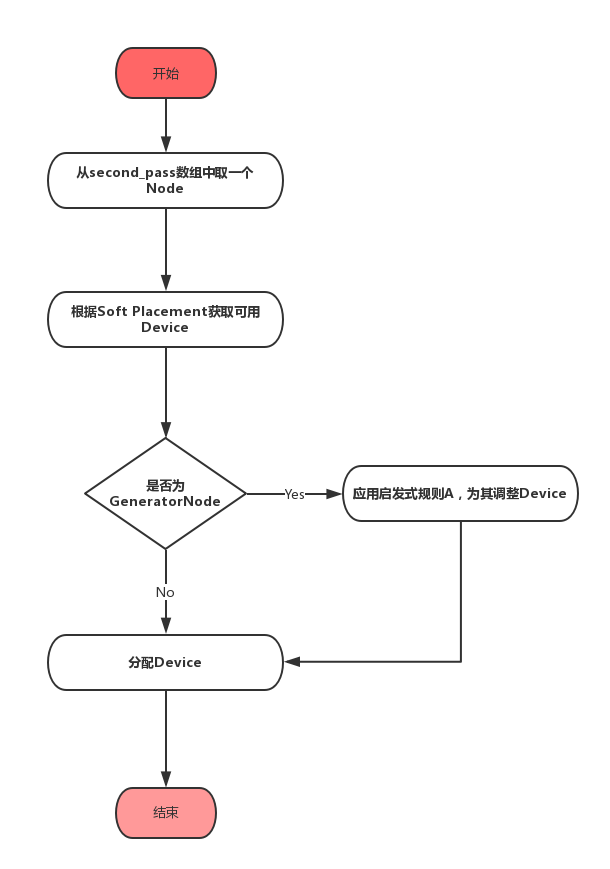
放在second_pass中的代码全部是GeneratorNode,所以只需要应用启发式规则A即可,和步骤3一样,启发式规则A的应用也是尝试性的,如果实在不能满足,会直接分配候选Device中优先级最高的Device,下面是启发式规则A的应用部分代码。
int assigned_device = -;
// Heuristic A application.
if (IsGeneratorNode(node)) {
const Node* output = (*node->out_edges().begin())->dst();
int output_device_name = output->assigned_device_name_index();
const bool consumers_on_same_device = std::all_of(
node->out_edges().begin(), node->out_edges().end(),
[output_device_name](const Edge* e) {
return e->dst()->assigned_device_name_index() == output_device_name;
});
if (consumers_on_same_device &&
CanAssignToDevice(output->assigned_device_name(), *devices)) {
assigned_device = output_device_name;
}
}
// Provide the default, if necessary.
if (assigned_device == -) {
assigned_device = graph_->InternDeviceName((*devices)[]->name());
}
AssignAndLog(assigned_device, node);
至此,所有Node的Placement信息都已经分配并微调完毕。
总结
经过Placer处理的GraphDef保证了计算图在Placement层面已经不存在任何冲突,因此它被认为是解决Placement冲突的最后一道防线。在Placer之后,GraphDef将被送入GraphPartitioner模块中根据每个Node的device做子图切分,并插入Send,Recv以及必要的ControlFlow节点。从上面的梳理中我们也可以看出Placer模块的核心是应用多种启发式规则对Placement进行微调,但这些启发式规则还相对较为简单,并没有完全解决性能问题。如果在Placement方面去挖掘性能方面的优化空间,我们马上可以想到,在分布式模式下,粗糙的Placement方案会让作业性能变得非常差,因为它会引入计算之外的通信开销。TensorFlow为了高度灵活性,将Placement策略的负担丢给了用户,这也是为什么有些用户写出的TensorFlow分布式程序性能非常差的原因之一。从TensorFlow框架的功能角度来说,它应该能够解放用户的编写程序负担,让用户能够完全专注在模型算法层面的研究中。但是自动搜索Placement最佳策略的难度非常大,因为它要考虑集群通信的带宽,以及每个Op的计算量,是一个与硬件和环境高度联系的复杂问题。不仅如此,通常深度学习模型含有成千上万个Node,这使得方案的搜索空间巨大无比。对于这个问题,Google曾经提出过强化学习搜索最佳模型分片策略的方法,有兴趣地同学可以参考这篇ICML论文: Device Placement Optimization with Reinforcement Learning。
TensorFlow中的Placement启发式算法模块——Placer的更多相关文章
- tensorflow中slim模块api介绍
tensorflow中slim模块api介绍 翻译 2017年08月29日 20:13:35 http://blog.csdn.net/guvcolie/article/details/77686 ...
- CNN中的卷积核及TensorFlow中卷积的各种实现
声明: 1. 我和每一个应该看这篇博文的人一样,都是初学者,都是小菜鸟,我发布博文只是希望加深学习印象并与大家讨论. 2. 我不确定的地方用了"应该"二字 首先,通俗说一下,CNN ...
- TensorFlow中的通信机制——Rendezvous(二)gRPC传输
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 本篇是TensorFlow通信机制系列的第二篇文章,主要梳理使用gRPC网络传 ...
- TensorFlow中的通信机制——Rendezvous(一)本地传输
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 在TensorFlow源码中我们经常能看到一个奇怪的词——Rendezvous ...
- TensorFlow中的并行执行引擎——StreamExecutor框架
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 在前一篇文章中,我们梳理了TensorFlow中各种异构Device的添加和注 ...
- TensorFlow中的设备管理——Device的创建与注册机制
背景 [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 作为一款优秀的异构深度学习算法框架,TensorFlow可以在多种设备上运行算 ...
- 第二十二节,TensorFlow中的图片分类模型库slim的使用、数据集处理
Google在TensorFlow1.0,之后推出了一个叫slim的库,TF-slim是TensorFlow的一个新的轻量级的高级API接口.这个模块是在16年新推出的,其主要目的是来做所谓的“代码瘦 ...
- 第十八节,TensorFlow中使用批量归一化(BN)
在深度学习章节里,已经介绍了批量归一化的概念,详情请点击这里:第九节,改善深层神经网络:超参数调试.正则化以优化(下) 神经网络在进行训练时,主要是用来学习数据的分布规律,如果数据的训练部分和测试部分 ...
- TensorFlow中的卷积函数
前言 最近尝试看TensorFlow中Slim模块的代码,看的比较郁闷,所以试着写点小的代码,动手验证相关的操作,以增加直观性. 卷积函数 slim模块的conv2d函数,是二维卷积接口,顺着源代码可 ...
随机推荐
- java模板设计模式
1.概述 模板设计模式定义:定义一个操作中的算法骨架,将步骤延迟到子类中. 模板设计模式是一种行为设计模式,一般是准备一个抽象类,将部分逻辑以具体方法或者具体的构造函数实现,然后声明一些抽象方法,这样 ...
- SVN客户端操作
版权声明:本文为博主原创文章,转载请注明原文出处. https://blog.csdn.net/zzfenglin/article/details/50937119 下面我们来了解一下SVN客户端 ...
- POJ - 3278 Catch That Cow bfs 线性
#include<stdio.h> #include<string.h> #include<algorithm> #include<queue> usi ...
- C++代码审查---审查孙晓宁马踏棋盘谜题程序
与孙晓宁同学结对审查,其代码地址如下:https://github.com/brunnhilder/-1/blob/master/%E9%A9%AC%E8%B8%8F%E6%A3%8B%E7%9B%9 ...
- flask-cookie & session
Cookie @app.route('/') def hello_world(): name=request.cookies.get('Name') # 获取cookie resp = Respon ...
- 用不到 50 行的 Python 代码构建最小的区块链
引用 译者注:随着比特币的不断发展,它的底层技术区块链也逐步走进公众视野,引起大众注意.本文用不到50行的Python代码构建最小的数据区块链,简单介绍了区块链去中心化的结构与其实现原理. 尽管一些人 ...
- 虚拟机找不到/mnt/hgfs挂载目录——debian与 vmware
如果在安装好 VMware Tools 并在设置里面设定好共享目录之后仍然找不到 /mnt/hgfs 默认挂载目录,那么尝试以下步骤: 1. 确认VMware Tools 和共享目录设定已经完成: 2 ...
- 分布式文件系统 / MQ / 鉴权(轮廓)
FastDFS的轮廓 / RabbitMQ的轮廓 / JWT和RSA非对称加密的轮廓
- JSON Web Token(JWT)使用步骤说明
在JSON Web Token(JWT)原理和用法介绍中,我们了解了JSON Web Token的原理和用法的基本介绍.本文我们着重讲一下其使用的步骤: 一.JWT基本使用 Gradle下依赖 : c ...
- Javascript高级编程学习笔记(83)—— 富文本选区(3)
富文本选区 在富文本编辑器中使用 iframe 的 getSelection() 方法可以获取选中的文本 该方法是 window 对象和 document 对象的属性,调用后会返回一个当前选选择文本的 ...