python爬虫解析库学习
一、xpath库使用:
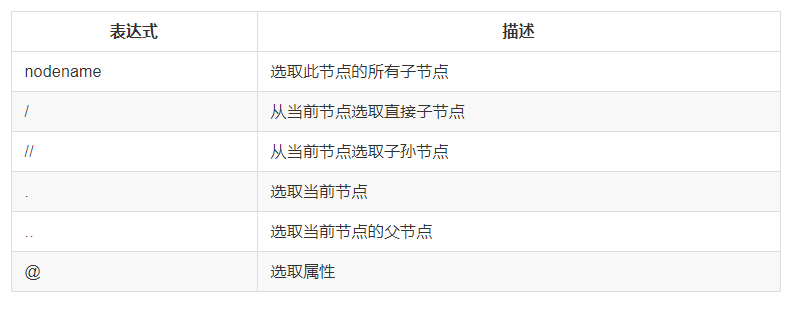
1、基本规则:
2、将文件转为HTML对象:
html = etree.parse('./test.html', etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))
3、属性多值匹配:
//a[contains(@class,'li')]
4、多属性匹配:
//a[@class="a" and @font="red"]
5、按序选择:

二、beautifulsoup库学习:
1、基本初始化:
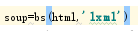
将HTML字符串用lxml格式来解析,并补全标签,创建html处理对象。
2、获取信息:
(1)获取title的name属性:
soup.title.name
(2)获取多属性:
(3)children返回孩子节点:
(4)find_all函数:查找所有的节点。
·通过节点名称来查找:
soup.find_all(name='li')
·通过属性名来查找:
soup.find_all(attrs={'id':'link1'})
··通过文本来查找:
soup.find_all(text='') 用来匹配网页节点中的文本内容。
3、css选择器:
.select() 方法。参数内容和jquery相似。
返回内容为列表,类型是tag类型。
三、pyquery库:
1、初始化:
·通过HTML字符串
·通过url
·通过文件名。需要指出文件名。
2、常用函数:
(1)find() 方法
(2)children()查找子结点
(3)查找父节点: parent()
(4)查找祖先节点:
parents()
(5)兄弟节点:
siblings() 方法
(6)对查找结果进行遍历:
.items()返回每一个节点。
(7) 获取节点信息:
·获取属性:
.attrs(‘属性名’)
python爬虫解析库学习的更多相关文章
- Python 爬虫 解析库的使用 --- XPath
一.使用XPath XPath ,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言.它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索. 所 ...
- Python 爬虫 解析库的使用 --- Beautiful Soup
知道了正则表达式的相关用法,但是一旦正则表达式写的有问题,得到的可能就不是我们想要的结果了.而且对于一个网页来说,都有一定的特殊结构和层级关系,而且有很多节点都有id或class来做区分,所以借助它们 ...
- python爬虫解析库之Beautifulsoup模块
一 介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会 ...
- python爬虫解析库之re模块
re模块 一:什么是正则? 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法.或者说:正则就是用来描述一类事物的规则.(在Python中)它内嵌在Python中, ...
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
- Python爬虫—requests库get和post方法使用
目录 Python爬虫-requests库get和post方法使用 1. 安装requests库 2.requests.get()方法使用 3.requests.post()方法使用-构造formda ...
随机推荐
- 3 Asking for more information
1 Could you tell me more about your idea? 2 Could I hear more about your idea? 3 Could you expain yo ...
- The New Villa
题目:The New Villa 题目链接:http://poj.org/problem?id=1137 题目大意: 一个人买了一个别墅,里面有很多房间,特别的是这个别墅的房间里灯的开关是乱套的,也就 ...
- display设置弹性盒布局
转自:http://blog.csdn.net/itbwy/article/details/52648711 网页布局(layout)是CSS的一个重点应用. 布局的传统解决方案,基于盒状模型,依赖 ...
- Codeforces 1154C Gourmet Cat
题目链接:http://codeforces.com/problemset/problem/1154/C 题目大意: 主人有一只猫.周一&周四&周日:吃鱼周二&周六:吃兔子周三 ...
- Excel文件读取的两种方式
1.Pandas库的读取操作 from pandas import read_excel dr=read_excel(filename,header) dr#dataframe数据 dw=DataFr ...
- python爬虫之Anaconda安装
Anaconda概述 Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存.切 ...
- 如何在cmd中集成git
1.要在cmd中集成git,要解决在cmd中输入git命令时不提示git不是内部或外部命令: 即需要将git添加到path变量中,即将D:\Git\mingw64\bin和D:\Git\mingw64 ...
- JavaScript之简易http接口测试工具网页版
简易http接口测试工具网页版,支持get.post请求,支持json格式消息体,form表单暂不支持. httpClient.html <!DOCTYPE html> <html ...
- 5G到来,数据中心如何变革?
导读 5G将要到来,除改变人们的工作生活外,其带宽.延时.连接特性也逼迫着数据中心变革,以满足5G时代需求.具体而言,5G将从形状规模.硬件组成及软件规模三面变革数据中心. 5G带来什么 高带宽.低延 ...
- mysql严格模式的开启、关闭
关于mysql严格模式的开启.关闭 由于项目中对一些默认值设置问题,以及种种原因,mysql数据库需要使用非严格模式开发(mysql最近的版本默认是开启严格模式的). linux下mysql服务下操作 ...