hibernate框架学习之二级缓存
缓存的意义
l应用程序中使用的数据均保存在永久性存储介质之上,当应用程序需要使用数据时,从永久介质上进行获取。缓存是介于应用程序与永久性存储介质之间的一块数据存储区域。利用缓存,应用程序可以将使用的数据临时放入缓存,需要再次使用时从缓存中获取,降低应用程序与永久性介质之间数据交换的频率,提升应用程序的运行性能。
l缓存中的数据都来源于永久性存储介质之上,缓存仅仅是一个辅助性的区域,不是数据的最终存放位置。通常缓存区域会选取比永久性存储介质访问速度稍快的空间,例如内存中。
二级缓存
l二级缓存是一种名称的定义,指在已有缓存的基础上,再增设一种缓存。
l二级缓存弥补一级缓存的不足。一级缓存的数据是针对单次操作而设计,服务于一次请求操作。由于单次操作的数据量不会涉及很多数据,因此一级缓存存储数据量较小,生命周期较短。并且单次数据操作完毕后,下一次请求的数据将无法使用上一次缓存的数据。二级缓存有效弥补一级缓存的缺陷,在现有一级缓存基础上,在多次请求操作间进行数据共享,有效减少访问永久介质的次数。
Hibernate支持的缓存
lHibernate支持两种缓存
•一级缓存
•也称作Session级别的缓存,该缓存无法卸载,属于Hibernate内置的缓存,绑定每次连接数据库的Session对象。
•二级缓存
•也称作SessionFactory级别的缓存,该缓存是通过外部技术实现的,通过使用不同的缓存供应商提供的缓存技术,为Hibernate加开一级缓存,可以根据需要进行安装或卸载。
•目前Hibernate支持的二级缓存主要有4种
•ehcache
•OpenSymphony
•SwarmCache
•JBossCache
缓存结构图
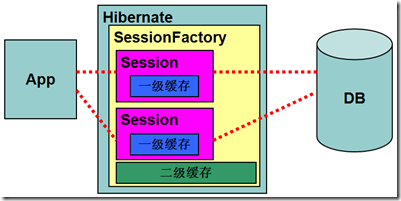
缓存结构图(按OID查询数据)
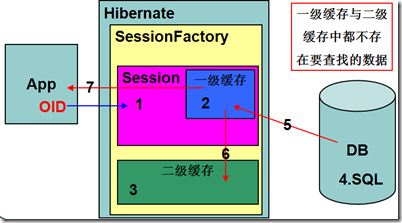
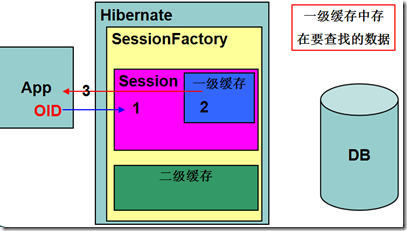
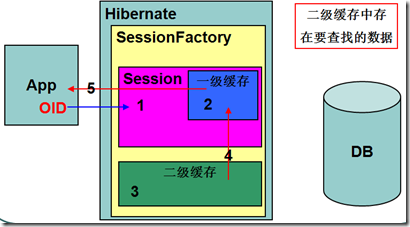
二级缓存工作流程
l二级缓存开启后的数据操作
•查询数据
•如果按OID查找数据,检查一级缓存中是否存在查找数据,如果存在返回给客户端
•如果按OID查找数据,一级缓存中不存在要查找的数据,检查二级缓存中是否存在查找数据,如果存在将二级缓存数据加载入一级缓存,然后返回给客户端
•如果一级缓存和二级缓存中都不存在要查找的数据,到数据库中执行对应的SQL语句查询出对应的数据,将数据加载一级缓存和二级缓存中,供下次按OID查找数据使用
缓存结构图(使用SQL查询数据)
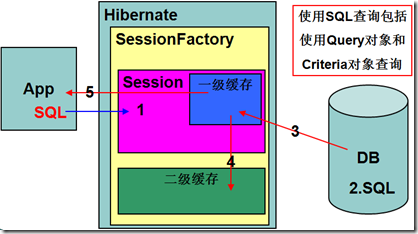
二级缓存工作流程
l二级缓存开启后的数据操作
•使用SQL查询的数据(不做缓存数据存在性检测)
•执行SQL语句获取要查询的数据
•将查询的数据更新到一级缓存中
•将查询的数据更新到二级缓存中
•将查询的数据返回给客户端
缓存结构图(添加数据)
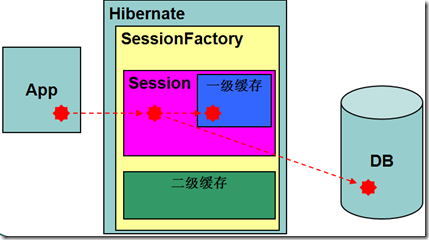
缓存结构图(删除修改数据)
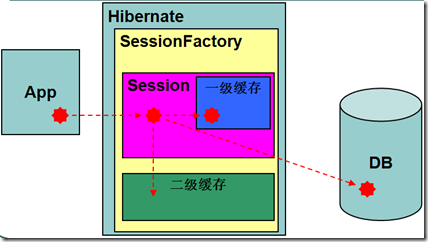
二级缓存工作流程
l二级缓存开启后的数据操作
•添加数据
•更新所在一级缓存的数据
•更新数据库对应数据
•删除、修改数据
•更新所在一级缓存的数据
•更新所在二级缓存的数据
•更新数据库对应数据
获取二级缓存数据注意事项
l二级缓存的加入可以使用户减少与数据库间进行数据交互的次数,但是并不是所有操作的数据都可以从二级缓存中获取
•查询所有姓“李”的教师信息时,如果二级缓存中加载有一定量的数据,但是不确定是不是所有数据,此时数据获取如果从二级缓存中进行,将出现问题。
•二级缓存不是数据库的克隆版,不可能将整个数据库信息装入二级缓存,从设计上也是不允许的
•二级缓存对数据的识别采用OID的形式进行,只有仅按照OID的形式获取数据,才能从二级缓存中获取
•所有从数据库查询得到的数据都将加入二级缓存,为后期查询提高查询速度
二级缓存中的数据要求
l二级缓存的目的主要是为了提高查询速度,因此放入二级缓存的数据有严格的要求
•适合加入二级缓存的数据
•很少被修改的数据
•不是很重要的数据,允许出现偶尔并发的数据
•不会被并发访问的数据
•参考数据
•不适合加入二级缓存的数据
•经常被修改的数据
•财务数据,绝对不允许出现并发
•与其他应用共享的数据
二级缓存的使用
l二级缓存的出现有效的提高了信息查询的速度,但是并不是配置二级缓存后将所有数据放入二级缓存一定能加快速度,不合理的使用会降低整体应用的性能
l在实际开发过程中,前期一定要对数据进行合理的分析,有选择将数据放入二级缓存,而不能盲目的开启使用二级缓存
•教务系统——课程数据、教师数据、学生数据、成绩数据
•办公自动化系统——会议室使用记录、用车记录、工资数据
•淘宝网站——商品数据、用户数据、订单数据、地址数据
•政府网站——公示信息、办公流程数据、人员数据
Hibernate二级缓存配置方式
lHibernate配置二级缓存
•加入二级缓存供应商jar包
•为项目添加ehcache对应的jar包
•系统配置文件中开启二级缓存(hibernate.cfg.xml)
•
•系统配置文件中配置二级缓存供应商(hibernate.cfg.xml)
•
•添加二级缓存配置信息
•src目录下创建ehcache.xml文件
•具体配置信息参考ehcache对应的jar包中配置文件
l配置加入二级缓存的数据
•方式一:在映射文件hbm.xml文件中添加配置

•方式二:在系统配置文件cfg.xml文件中添加配置
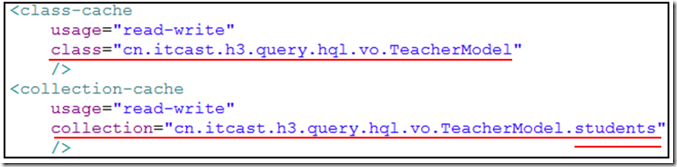
•使用class-cache定义类对象缓存
•使用collection-cache定义集合对象缓存,注意这里定义的是关联关系中的集合对象名,而不是关联模型类,更不是集合
•usage定义了缓存的种类:读写缓存、只读缓存等
读取二级缓存数据
l二级缓存的数据必须先加载才可以使用,如果二级缓存中没有要查找的数据,在进行了对应的查找操作后,该数据立即进入二级缓存
l二级缓存的数据获取必须按照OID进行,因此查询方法中不是按照OID进行的查询将不能从二级缓存获取
•Query对应的操作
•Criteria对应的操作
•关于Query与Criteria对象执行查询时生成的SQL语句的识别
ehcache二级缓存配置详解
<diskStore path=“java.io.tmpdir”/>
<defaultCache
maxElementsInMemory="10"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
maxElementsOnDisk="10000000"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
/>

ehcache自定义二级缓存配置详解
l在ehcache.xml中添加自定义缓存设定,指定不同的缓存策略
•<cache name=“my” 其他配置/>
针对不同的缓存内容,设定使用不同的cache策略

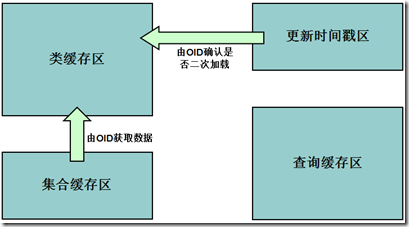
二级缓存数据存储区域
l二级缓存中的存储区域共分为4个
•类对象缓存区域
•关联关系集合对象缓存区域
•更新标识时间戳区域
•查询缓存区域
二级缓存——类对象缓存区
l类缓存区存储了类级别对象的缓存数据,包括以下四种数据
•普通类
•一对多、多对多关联关系中的主数据和从数据
•一对一关联关系中的主数据和从数据
•一对一关联中的主关联数据和从关联数据
l上述数据均是单一对象的格式
l二级缓存中存储的数据不是Java对象的格式,而是原始数据的散装数据,简言之就是将原始对象的数据分散存储,便于管理,获取时重新组装成对象
二级缓存——关联关系集合对象缓存区
l集合缓存区存储了类级别对象的缓存数据,包括以下四种数据
•一对多关联关系中的主关联数据
•多对一关联关系中的从关联数据
•多对多关联关系中的主关联数据和从关联数据
l上述数据均是集合对象的格式
l二级缓存中的集合数据仅保存对应对象在类对象缓存区保存数据的OID,集合中不存在任何OID之外的属性数据,因此集合数据如果没有设定对应的类对象缓冲区将失去缓存的意义
二级缓存——更新时间戳区与更新标识
l二级缓存中保存的数据与数据库对应,当客户端执行不使用一级缓存提供的更新操作时,此更新无法通知二级缓存进行数据同步,造成数据不同步
l为避免该问题,二级缓存始终监控被缓存数据对应的所有DML语言,如果发现对应数据进行了更新,无论是否进行了对应的真实数据更改,再次获取二级缓存中的数据时,强制重新加载数据,与数据库中的数据进行同步。
l实现方式:
•时间戳:为二级缓存数据追加加载时间与修改时间标识
•标志位:为二级缓存数据追加修改状态标识
二级缓存数据存储形式
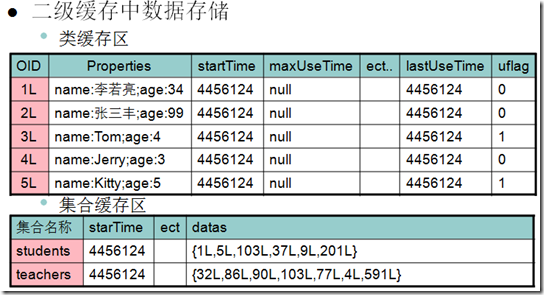
二级缓存——查询缓存区
l二级缓存只能依赖仅使用OID进行查询,这一设定将对二级缓存的实用性大打折扣
l查询缓存可以有效解决上述问题
•查询缓存使用查询的最终SQL语句作为Key
•查询缓存使用查询的结果作为Value

二级缓存——查询缓存使用方式
l查询缓存使用步骤(基于二级缓存)
•设置开启查询缓存功能
•
•对要进行查询缓存的操作开始使用查询缓存设置
•
•setCacheable(true)操作表明本次查询设定缓存区域为查询缓存区域,而不是二级缓存的常规区域
l注意:查询缓存的数据只能从查询缓存中获取,与二级缓存中其他区域的数据没有关系,因此每次都要设定使用查询缓存
二级缓存数据存储区
hibernate框架学习之二级缓存的更多相关文章
- hibernate框架学习之二级缓存(测试用例)
HqlDemoApp.java package cn.itcast.h3.query.hql; import java.io.Serializable; import org.hibernate.Qu ...
- hibernate框架学习之一级缓存
l缓存是存储数据的临时空间,减少从数据库中查询数据的次数 lHibernate中提供有两种缓存机制 •一级缓存(Hibernate自身携带) •二级缓存(使用外部技术) lHibernate的一级缓存 ...
- Hibernate框架(四)缓存策略+lazy
Hibernate作为和数据库数据打交道的框架,自然会设计到操作数据的效率问题,而对于一些频繁操作的数据,缓存策略就是提高其性能一种重要手段,而Hibernate框架是支持缓存的,而且支持一级和二级两 ...
- Hibernate的查询,二级缓存,连接池
Hibernate的查询,二级缓存,连接池 1.Hibernate查询数据 Hibernate中的查询方法有5中: 1.1.Get/Load主键查询 使用get或者load方法来查询,两者之间的区别在 ...
- Hibernate框架学习笔记
Hibernate 是一个 JDO( Java Data Objects)工具.它的工作原理是通过文件把值对象(Java对象)和 数据库表之间建立起一个映射关系,还提供数据查询和获取数据的方法. ...
- hibernate框架学习第六天:QBC、分页查询、投影、数据加载策略、二级缓存
QBC查询 1.简单查询 Criteria c = s.createCriteria(TeacherModel.class); 2.获取查询结果 多条:list 单挑:uniqueResult 3.分 ...
- Hibernate学习之二级缓存
© 版权声明:本文为博主原创文章,转载请注明出处 二级缓存 - 二级缓存又称“全局缓存”.“应用级缓存” - 二级缓存中的数据可适用范围是当前应用的所有会话 - 二级缓存是可插拔式缓存,默认是EHCa ...
- hibernate框架学习第三天:对象状态、一级缓存、快照等
对象的状态 瞬时状态: 瞬时对象(TO) 应用程序创建出来的对象,不受H3控制 注意:TO对象不具有OID,一旦为TO赋值OID,那么此时就不是TO 持久化状态:持久化对象(PO) 受H3控制的对象, ...
- [ SSH框架 ] Hibernate框架学习之二
一.Hibernate持久化类的编写规范 1.什么是持久化类 Hibernate是持久层的ORM影射框架,专注于数据的持久化工作.所谓持久化,就是将内存中的数据永久存储到关系型数据库中.那么知道了什么 ...
随机推荐
- java语音转文字
用到的百度提供的api 需要把wav音频文件转成16k的频率,必须转,不转百度api解析不出来.显示音频文件不清晰错误.想要转化还必须要有ffmpeg程序,这个自己百度去下载.然后拿转好的文件扔到百度 ...
- CentOS7用Mono和MonoDevelop写C#程序
MonoDevelop 是个Linux平台上的开放源代码集成开发环境,主要用来开发Mono与.NET Framework软件. MonoDevelop 整合了很多Eclipse与Microsoft V ...
- JAVA入门教程 - idea 新建maven spring MVC项目
用的是Idea2017版本.其他大同小异 1.新建项目 2.勾选Create from archetype 选中maven-archetype-webapp 3.输入项目名字. 4.下一步 5.点Fi ...
- [Android] Android 使用Greendao gradle 出现 Error:Unable to find method 'org.gradle.api.tasks.TaskInputs.file(Ljava/lang/Object;)
Android 使用Greendao gradle 出现 Error:Unable to find method 'org.gradle.api.tasks.TaskInputs.file(Ljava ...
- 梯度下降算法对比(批量下降/随机下降/mini-batch)
大规模机器学习: 线性回归的梯度下降算法:Batch gradient descent(每次更新使用全部的训练样本) 批量梯度下降算法(Batch gradient descent): 每计算一次梯度 ...
- Ubuntu中安装python3.6(转)
因为TensorFlow只支持到python3.6,所以安装python3.6版本 Python3.6的使用越来越普遍.Ubuntu16.04的版本中默认胸自带python2和python3.5的版本 ...
- Docker 容器启动 查看容器状态 - 四
1.容器两种方式进行启动 一种是基于创建一个容器并启动 docker create docker start 另一种 使用 run 创建自动启动:是状态下的停止 启动 docker start ngi ...
- EcustOJ P109跳一跳(离散化+dp)
题目链接 感觉这道题我看了很多天,胡思乱想啊,一开始觉得记忆化搜索会可能T啊,,可能出题人的数据卡的好就稳T了的感觉..后来想了想,好像离散化一下,记一下位置之后再记忆化搜索就应该稳了吧..(好像直接 ...
- mybatis批量更新报错
批量更新sql <update id="updateAutoAppraiseInfo" parameterType="Object"> <fo ...
- 2017-2018-2 165X 『Java程序设计』课程 团队项目备选题目
2017-2018-2 165X 『Java程序设计』课程 团队项目备选题目 结合本课程时间安排,以及同学们的专业和课程内容,制定了以下六个题目供各小组选择.如有其他项目方案设想,可自行与老师沟通.老 ...