Spark Shuffle机制
Spark Shuffle
一.HashShuffle
普通机制:产生磁盘小文件的数量为:M(map task number)*R(reduce task number)
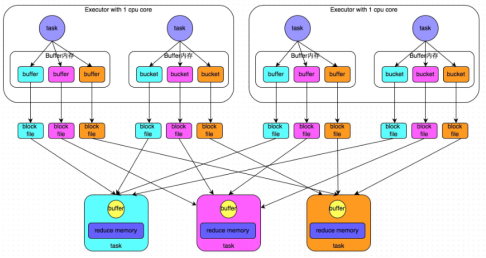
过程:
1.map task处理完数据之后,写到buffer缓冲区,buffer的大小为32k,个数与reduce task个数一致
2. 每个buffer缓存区满32k后会溢写磁盘,每个buffer最终对应一个磁盘小文件
3.reduce task拉取数据
问题:
1.shuffle write,read 频繁
2.占用内存过多,容易造成gc以及出现OOM
3.磁盘小文件多,会造成频繁I/O,效率降低
合并机制:产生磁盘小文件的数量为:C(core number)*R(reduce task number)
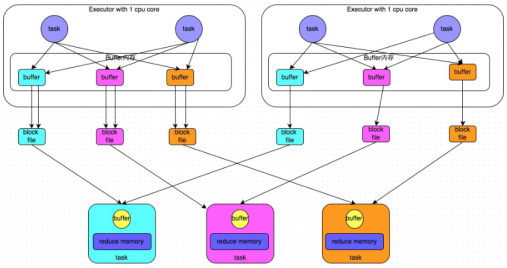
过程:
1.map task处理完数据之后,写到buffer缓冲区,buffer的大小为32k,个数与reduce task个数一致
2.Executor中每个core中的task共用一份buffer缓冲区
3.每个buffer缓存区满32k后会溢写磁盘,每个buffer最终对应一个磁盘小文件
4.reduce task拉取数据
二.SortShuffle
普通机制:产生磁盘小文件数量:2*M(map task number)
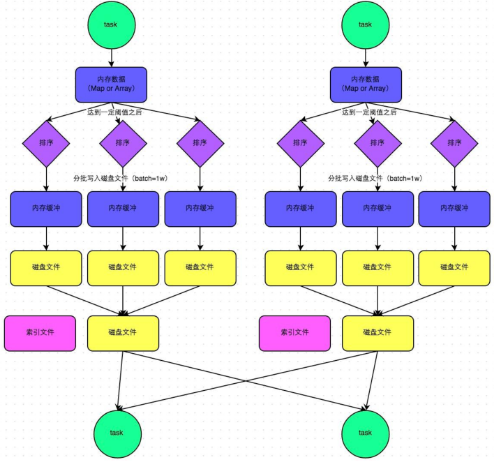
步骤:
1.map task处理完数据之后,首先写入一个5M的数据结构
2.sortShuffle有不定期估算机制,来估算这个内存结构的大小,当估算超过真实的大小,会申请内存:2*估算大小-当前大小
3.申请到内存继续写入内存数据结构,申请不到会溢写磁盘
4.溢写磁盘过程中有排序,每批1万条数据溢写,最终对应两个磁盘文件:一个索引文件,一个数据文件
5.reduce task拉取数据首先读取索引文件,再拉取数据
bypass机制:产生磁盘小文件数量:2*M(map task number)
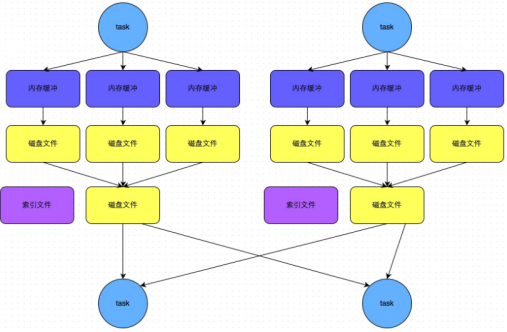
步骤:
1.map task处理完数据之后,首先写入一个5M的数据结构
2.sortShuffle有不定期估算机制,来估算这个内存结构的大小,当估算超过真实的大小,会申请内存:2*估算大小-当前大小
3.申请到内存继续写入内存数据结构,申请不到会溢写磁盘
4.溢写磁盘过程中没有排序,每批1万条数据溢写,最终对应两个磁盘文件:一个索引文件,一个数据文件
5.reduce task拉取数据首先读取索引文件,再拉取数据
Spark Shuffle机制的更多相关文章
- Spark Shuffle机制详细源码解析
Shuffle过程主要分为Shuffle write和Shuffle read两个阶段,2.0版本之后hash shuffle被删除,只保留sort shuffle,下面结合代码分析: 1.Shuff ...
- spark shuffle 机制
spark shuffle 分为两种 1.byPassSortShuffle 发生条件分区数<=200:无排序及聚合操作 主要是直接按照分区号写文件,有多少分区写多少文件 不做任何排序,简单直接 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
- 【Spark篇】---Spark中Shuffle机制,SparkShuffle和SortShuffle
一.前述 Spark中Shuffle的机制可以分为HashShuffle,SortShuffle. SparkShuffle概念 reduceByKey会将上一个RDD中的每一个key对应的所有val ...
- spark的shuffle机制
对于大数据计算框架而言,Shuffle阶段的设计优劣是决定性能好坏的关键因素之一.本文将介绍目前Spark的shuffle实现,并将之与MapReduce进行简单对比.本文的介绍顺序是:shuffle ...
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle...相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量.相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuf ...
- 【Spark学习】Apache Spark安全机制
Spark版本:1.1.1 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4135808.html 目录 W ...
- Spark工作机制简述
Spark工作机制 主要模块 调度与任务分配 I/O模块 通信控制模块 容错模块 Shuffle模块 调度层次 应用 作业 Stage Task 调度算法 FIFO FAIR(公平调度) Spark应 ...
随机推荐
- salesforce lightning零基础学习(十二) 自定义Lookup组件的实现
本篇参考:http://sfdcmonkey.com/2017/01/07/custom-lookup-lightning-component/,在参考的demo中进行了简单的改动和优化. 我们在ht ...
- Quartz使用记录总结
Quartz是一个任务调度框架,最近在项目中有用到,所以做个记录总结. 一.主要元素 Scheduler:调度器,控制任务的调度,将JobDetail和Trigger注册到Scheduler加以控制. ...
- python args kwargs 传递参数的区别
先来看个例子: def foo(*args, **kwargs): print 'args = ', args print 'kwargs = ', kwargs print '----------- ...
- SpringCloud实战9-Stream消息驱动
官方定义 Spring Cloud Stream 是一个构建消息驱动微服务的框架. 应用程序通过 inputs 或者 outputs 来与 Spring Cloud Stream 中binder 交互 ...
- 一个注意事项:内部类引用的外部变量必须是final的
之前写过一个项目,好久没更新了,最近翻起以前的代码,发现在这里报了一个错.(现在转到Intellij了,从前在Eclipse luna中是可以编译通过的,Eclipse mars也会报错,JDK版本都 ...
- 网络协议抓包分析——IP互联网协议
前言 IP协议是位于OSI模型的第三层协议,其主要目的就是使得网络间可以相互通信.在这一层上运行的协议不止IP协议,但是使用最为广泛的就是互联网协议. 什么是IP数据报 TCP/IP协议定义了一个在因 ...
- 第1章 Linux文件类基础命令
1. 关于路径和通配符 Linux中分绝对路径和相对路径,绝对路径一定是从/开始写的,相对路径不从根开始写,还可能使用路径符号. 路径展开符号: . :(一个点)表示当前目录 .. :(两个点)表示上 ...
- Perl语法的基本规则
因为是比较凌乱的用法规则收集,所以能看懂则看,不能看懂也无所谓.以后也会遇到. Perl脚本第一行使用#!.Perl的后缀名一般为".plx"或".pl",运行 ...
- Perl的比较操作符
比较操作符 perl的比较操作符和bash完全相反.数值比较采用符号,字符串比较采用字母. 数值 字符串 意义 ----------------------------- == eq 相等 != ne ...
- 【转载】C#工具类:FTP操作辅助类FTPHelper
FTP是一个8位的客户端-服务器协议,能操作任何类型的文件而不需要进一步处理,就像MIME或Unicode一样.可以通过C#中的FtpWebRequest类.NetworkCredential类.We ...