使用concurrent.futures模块中的线程池与进程池
使用concurrent.futures模块中的线程池与进程池
线程池与进程池
以线程池举例,系统使用多线程方式运行时,会产生大量的线程创建与销毁,创建与销毁必定会带来一定的消耗,甚至导致系统资源的崩溃,这时使用线程池就是一个很好的解决方式。
“池”就说明了这里边维护了不止一个线程,线程池会提前创建好规定数量的线程,把需要使用多线程的任务提交给线程池,线程池会自己选择空闲的线程来执行提交的任务,任务完成后,线程并不会在池子中销毁,而是继续存在并等待完成下一个分配的任务。当线程池以满的时候,提交的线程会等待,也就是说线程池会有一个最大数量的运行线程限制。
进程池同样也是这个道理。
concurrent.futures模块为我们提供了ThreadPoolExecutor与ProcessPoolExecutor来使用线程进程池
ThreadPoolExecutor
下面是一个简单的例子
from concurrent.futures import ThreadPoolExecutor
import requests,time
url_list = ['https://www.cnblogs.com/', 'https://www.csdn.net/', 'https://github.com/']
def get_url(url):
content = requests.get(url).content.decode()
print(url+'已获取')
pool = ThreadPoolExecutor(max_workers=3)
start = time.time()
for url in url_list:
future = pool.submit(get_url,url)
# print(future)
end = time.time()
print(end-start)
输出的结果为:
0.0016434192657470703
https://www.cnblogs.com/已获取
https://www.csdn.net/已获取
https://github.com/已获取
例子中max_workers为指定线程个数,pool.submit为提交任务到线程执行,get_url为方法,url为参数
并且通过输出顺序可以看到线程池的执行并不会阻塞主线程的运行
print(future)被打了注释,现在我们取消注释运行一下:
Future at 0x7ff6cfaa8860 state=running
Future at 0x7ff6ce965860 state=running
Future at 0x7ff6ce96e278 state=running
0.006175518035888672
https://www.cnblogs.com/已获取
https://www.csdn.net/已获取
https://github.com/已获取
每提交一个任务后都会返回一个future对象,通过它可以查看任务运行的状态,state=running表示正在运行
future对象还有许多方法:
future.done()
from concurrent.futures import ThreadPoolExecutor
import requests,time
url_list = ['https://www.cnblogs.com/', 'https://www.csdn.net/', 'https://github.com/']
def get_url(url):
content = requests.get(url).content.decode()
print(url+'已获取')
pool = ThreadPoolExecutor(max_workers=3)
future_list = []
start = time.time()
for url in url_list:
future = pool.submit(get_url,url)
print(future.done())
future_list.append(future)
end = time.time()
print(end-start)
time.sleep(5)
for future in future_list:
print(future.done())
这里添加了future_list,为了显示效果中间添加sleep,最后结果为:
False
False
False
0.001546621322631836
https://www.cnblogs.com/已获取
https://www.csdn.net/已获取
https://github.com/已获取
True
True
True
future.done()可以显示当前允许状态
future.result()
from concurrent.futures import ThreadPoolExecutor
import requests,time
url_list = ['https://www.cnblogs.com/', 'https://www.csdn.net/', 'https://github.com/']
def get_url(url):
content = requests.get(url).content.decode()
print(url+'已获取')
return url
pool = ThreadPoolExecutor(max_workers=3)
future_list = []
start = time.time()
for url in url_list:
future = pool.submit(get_url,url)
print(future.result())
future_list.append(future)
end = time.time()
print(end-start)
for future in future_list:
print(future.result())
结果为:
https://www.cnblogs.com/已获取
https://www.cnblogs.com/
https://www.csdn.net/已获取
https://www.csdn.net/
https://github.com/已获取
https://github.com/
2.0975613594055176
https://www.cnblogs.com/
https://www.csdn.net/
https://github.com/
可见result()方法可以得到任务的返回值,但会阻塞,因为不运行完怎么会得到返回值呢?
除此之外还有很多方法:
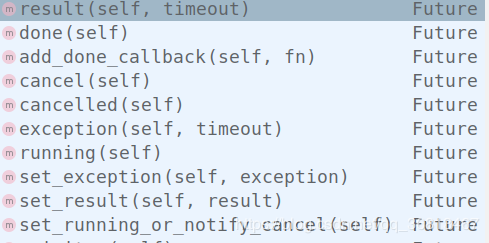
使用map方法
from concurrent.futures import ThreadPoolExecutor
import requests,time
url_list = ['https://www.cnblogs.com/', 'https://www.csdn.net/', 'https://github.com/']
def get_url(url):
content = requests.get(url).content.decode()
print(url+'已获取')
return url
pool = ThreadPoolExecutor(max_workers=3)
pool.map(get_url,url_list)
与内建函数用法类似
使用wait方法
from concurrent.futures import ThreadPoolExecutor,wait
import requests,time
url_list = ['https://www.cnblogs.com/', 'https://www.csdn.net/', 'https://github.com/']
def get_url(url):
content = requests.get(url).content.decode()
print(url+'已获取')
return url
pool = ThreadPoolExecutor(max_workers=3)
future_list = []
start = time.time()
for url in url_list:
future = pool.submit(get_url,url)
future_list.append(future)
print(wait(future_list))
end = time.time()
print(end-start)
https://www.cnblogs.com/已获取
https://www.csdn.net/已获取
https://github.com/已获取
DoneAndNotDoneFutures(done={Future at 0x7f7506447da0 state=finished returned str, Future at 0x7f75074c9828 state=finished returned str, Future at 0x7f75064477f0 state=finished returned str}, not_done=set())6.678021430969238
wait返回值是一个元组,元组里是已完成和未完成的两个集合,它的return_when参数接受3个选项FIRST_COMPLETED, FIRST_EXCEPTION 和ALL_COMPLETE,默认是ALL_COMPLETE,意味着所有都完成,FIRST_COMPLETED意味着有一个完成了就可以了, FIRST_EXCEPTION是第一个出现异常就会停止wait
例如:
from concurrent.futures import ThreadPoolExecutor,wait
import requests,time
url_list = ['https://www.cnblogs.com/', 'https://www.csdn.net/', 'https://github.com/']
def get_url(url):
content = requests.get(url).content.decode()
print(url+'已获取')
return url
def error(url):
gg
pool = ThreadPoolExecutor(max_workers=4)
future_list = []
start = time.time()
future_list.append(pool.submit(error,'https://www.cnblogs.com/'))
for url in url_list:
future = pool.submit(get_url,url)
future_list.append(future)
print(wait(future_list,return_when='FIRST_EXCEPTION'))
end = time.time()
print(end-start)
DoneAndNotDoneFutures(done={Future at 0x7fd1a5b95320 state=finished raised NameError}, not_done={Future at 0x7fd1a4b11a90 state=running, Future at 0x7fd1a4b11a20 state=running, Future at 0x7fd1a4c897f0 state=running})
0.001996755599975586
https://www.cnblogs.com/已获取
https://www.csdn.net/已获取
https://github.com/已获取
ProcessPoolExecutor
进程池与线程池的使用方式基本相同,套用即可
使用concurrent.futures模块中的线程池与进程池的更多相关文章
- concurrent.futures模块(进程池&线程池)
1.线程池的概念 由于python中的GIL导致每个进程一次只能运行一个线程,在I/O密集型的操作中可以开启多线程,但是在使用多线程处理任务时候,不是线程越多越好,因为在线程切换的时候,需要切换上下文 ...
- 线程与进程 concurrent.futures模块
https://docs.python.org/3/library/concurrent.futures.html 17.4.1 Executor Objects class concurrent.f ...
- 线程池、进程池(concurrent.futures模块)和协程
一.线程池 1.concurrent.futures模块 介绍 concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 Pro ...
- concurrent.futures模块(进程池/线程池)
需要注意一下不能无限的开进程,不能无限的开线程最常用的就是开进程池,开线程池.其中回调函数非常重要回调函数其实可以作为一种编程思想,谁好了谁就去掉 只要你用并发,就会有锁的问题,但是你不能一直去自己加 ...
- Python并发编程之线程池/进程池--concurrent.futures模块
一.关于concurrent.futures模块 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/ ...
- python3 线程池-threadpool模块与concurrent.futures模块
多种方法实现 python 线程池 一. 既然多线程可以缩短程序运行时间,那么,是不是线程数量越多越好呢? 显然,并不是,每一个线程的从生成到消亡也是需要时间和资源的,太多的线程会占用过多的系统资源( ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- 使用concurrent.futures模块并发,实现进程池、线程池
Python标准库为我们提供了threading和multiprocessing模块编写相应的异步多线程/多进程代码 从Python3.2开始,标准库为我们提供了concurrent.futures模 ...
- Python之路(第四十六篇)多种方法实现python线程池(threadpool模块\multiprocessing.dummy模块\concurrent.futures模块)
一.线程池 很久(python2.6)之前python没有官方的线程池模块,只有第三方的threadpool模块, 之后再python2.6加入了multiprocessing.dummy 作为可以使 ...
随机推荐
- Django 系列博客(六)
Django 系列博客(六) 前言 本篇博客介绍 Django 中的路由控制部分,一个网络请求首先到达的就是路由这部分,经过路由与视图层的映射关系再执行相应的代码逻辑并将结果返回给客户端. Djang ...
- [译]如何在.NET Core中使用System.Drawing?
你大概知道System.Drawing,它是一个执行图形相关任务的流行的API,同时它也不属于.NET Core的一部分.最初是把.NET Core作为云端框架设计的,它不包含非云端相关API.另一方 ...
- 【转载】 C#工具类:Csv文件转换类
CSV是逗号分隔值格式的文件,其文件以纯文本形式存储表格数据(数字和文本).CSV文件由任意数目的记录组成,记录间以某种换行符分隔:每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号 ...
- 解码 id_token
简介 id_token是一个特殊的token,在Microsoft Graph的认证和授权过程中颁发,它包含了已认证用户的一些信息.本文将介绍如何通过实例理解id_token,并且演示了如何解码. 准 ...
- mybatis笔记01
目录 1. Mybatis的介绍 2. 使用JDBC编码的分析 2.1 准备 2.3 程序代码 2.4 JDBC问题 3. Mybatis架构 4. Mybatis入门程序 4.1 mybatis下载 ...
- Maven(八)Eclipse创建Web项目(复杂方式)
1. 生成标准的Web工程结构 2. 勾选结尾为webapp的包 3. 生成的文件结构如下 3.1 生成的目录结构若存在错误,缺少servlet.api 3.1.1 添加步骤如下 4.生成后存在的缺点 ...
- Python3 系列之 可变参数和关键字参数
刚开始接触 python 的时候,对 python 中的 *wargs (可变参数) 和 **kwargs (关键字参数)的理解不是很透彻,看了一下 <Explore Python>一书, ...
- IntelliJ IDEA生成live template(代码模板)
IntelliJ IDEA生成live template(代码模板) 一.进入live template模板 快捷键:Ctrl+Shift+A进入Find Action,输入live template ...
- php生成xml数据
1.php生成xml数据一般有2种方式, 一个是组装字符串,另一个就是使用php内置的系统类 2.使用php内置类生成xml数据 3.拼装字符串生成xml数据 public function stat ...
- Linux下Python安装完成后如何使用pip命令
一.很多读者Python安装完成之后,想要下载相关的包,例如:numpy.pandas等Python中这些基础的包,但是,发现pip根本用不了,主要表现在一下几种情况: 二.出现这种情况其实并不意外, ...