Kudu原理-kudu的底层数据模型

Kudu自身的架构,部分借鉴了Bigtable/HBase/Spanner的设计思想。论文的作者列表中,有几位是HBase社区的Committer/PBC成员,因此,在论文中也能很深刻的感受到HBase对Kudu设计的一些影响
Kudu的底层数据文件的存储,未采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统。这套实现基于如下的几个设计目标:
• 可提供快速的列式查询。
• 可支持快速的随机更新
• 可提供更为稳定的查询性能保障。
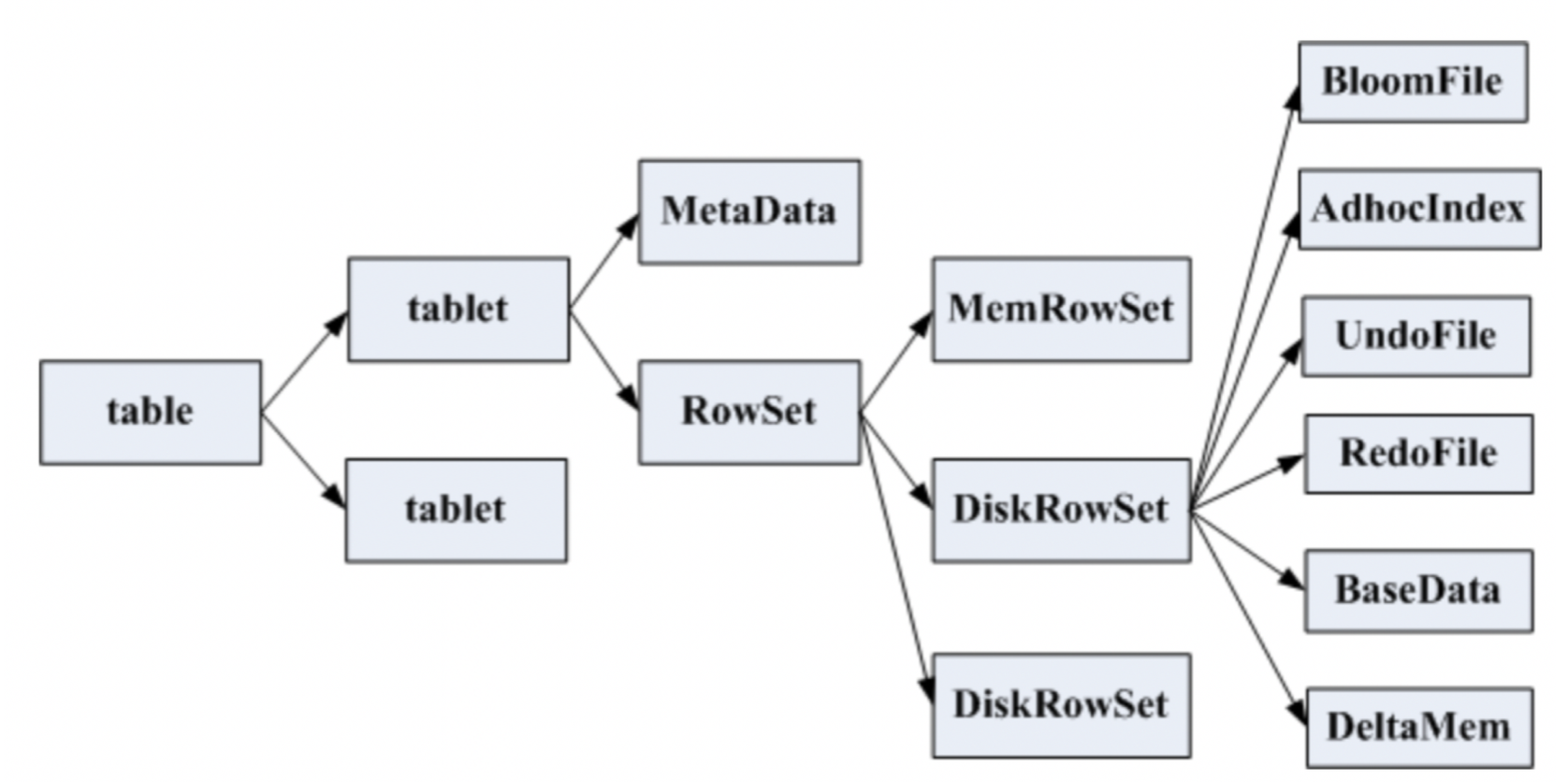
一张表会分成若干个tablet,每个tablet包括MetaData元信息及若干个RowSet,RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、Ad_hoc Index、BaseData、DeltaMem及若干个RedoFile和UndoFile(UndoFile一般情况下只有一个)。
MemRowSet:用于新数据insert及已在MemRowSet中的数据的更新,一个MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。(默认是1G或者或者120S) DiskRowSet用于老数据的变更(mutation),后台定期对DiskRowSet做compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。 BloomFile根据一个DiskRowSet中的key生成一个bloom filter,用于快速模糊定位某个key是否在DiskRowSet中存在。 Ad_hocIndex是主键的索引,用于定位key在DiskRowSet中的具体哪个偏移位置。 BaseData是MemRowSet flush下来的数据,按列存储,按主键有序。 UndoFile是基于BaseData之前时间的历史数据,通过在BaseData上apply UndoFile中的记录,可以获得历史数据。 RedoFile是基于BaseData之后时间的变更(mutation)记录,通过在BaseData上apply RedoFile中的记录,可获得较新的数据。 DeltaMem用于DiskRowSet中数据的变更mutation,先写到内存中,写满后flush到磁盘形成RedoFile
为了实现如上目标,Kudu参考了一种类似于Fractured Mirrors的混合列存储架构。Tablet在底层被进一步细分成了一个称之为RowSets的单元:
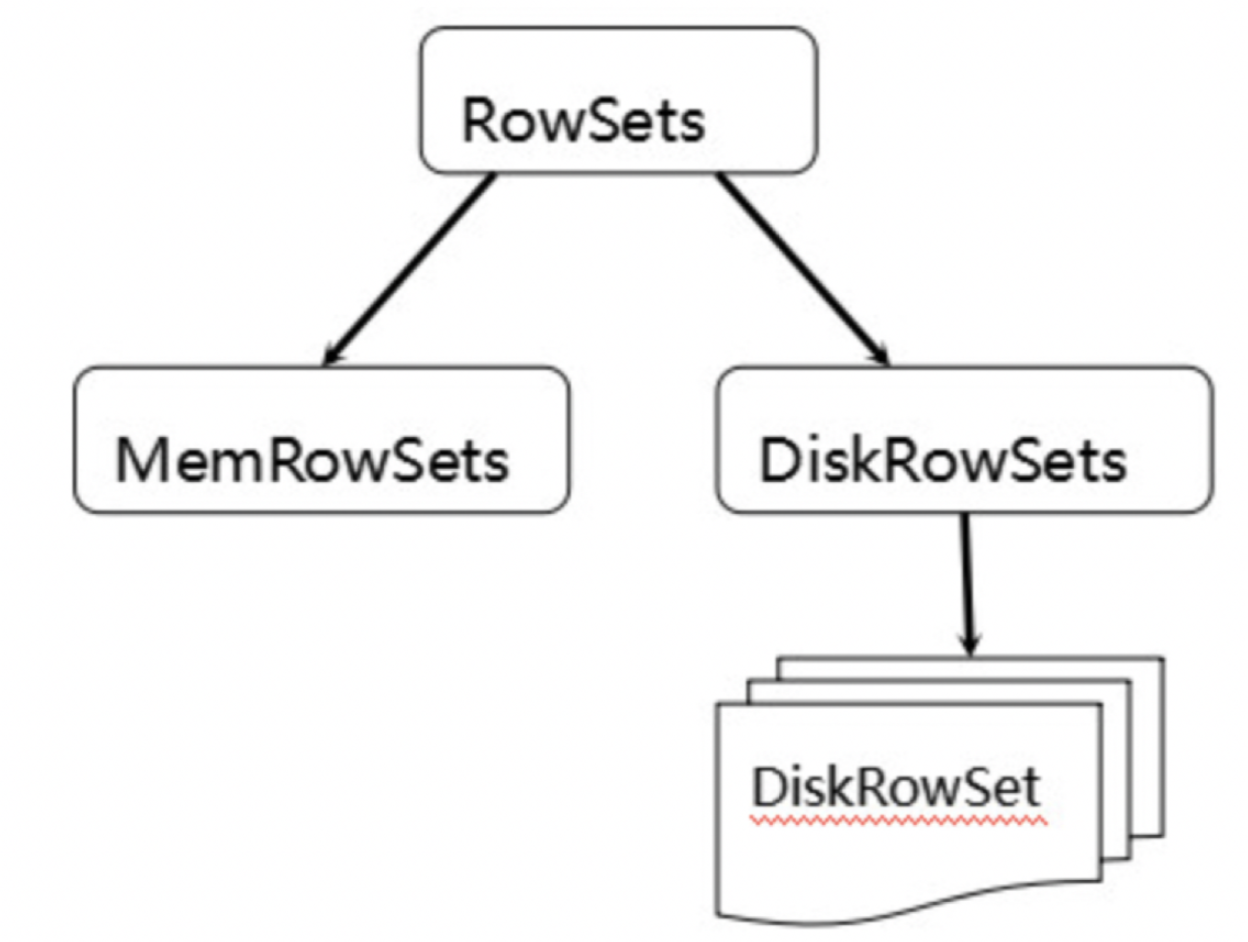
MemRowSets可以对比理解成HBase中的MemStore, 而DiskRowSets可理解成HBase中的HFile。MemRowSets中的数据按照行试图进行存储,数据结构为B-Tree。 MemRowSets中的数据被Flush到磁盘之后,形成DiskRowSets。 DisRowSets中的数据,按照32MB大小为单位,按序划分为一个个的DiskRowSet。
DiskRowSet中的数据按照Column进行组织,与Parquet类似。 这是Kudu可支持一些分析性查询的基础。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,与HBase File中的Block类似,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。
既然可对Column Page可采用Encoding以及Compression算法,那么,对单条记录的更改就会比较困难了。 前面提到了Kudu可支持单条记录级别的更新/删除,是如何做到的? 与HBase类似,也是通过增加一条新的记录来描述这次更新/删除操作的。一个DiskRowSet包含两部分数据:基础数据(Base Data),以及变更数据(Delta Stores)。更新/删除操作所生成的数据记录,被保存在变更数据部分。
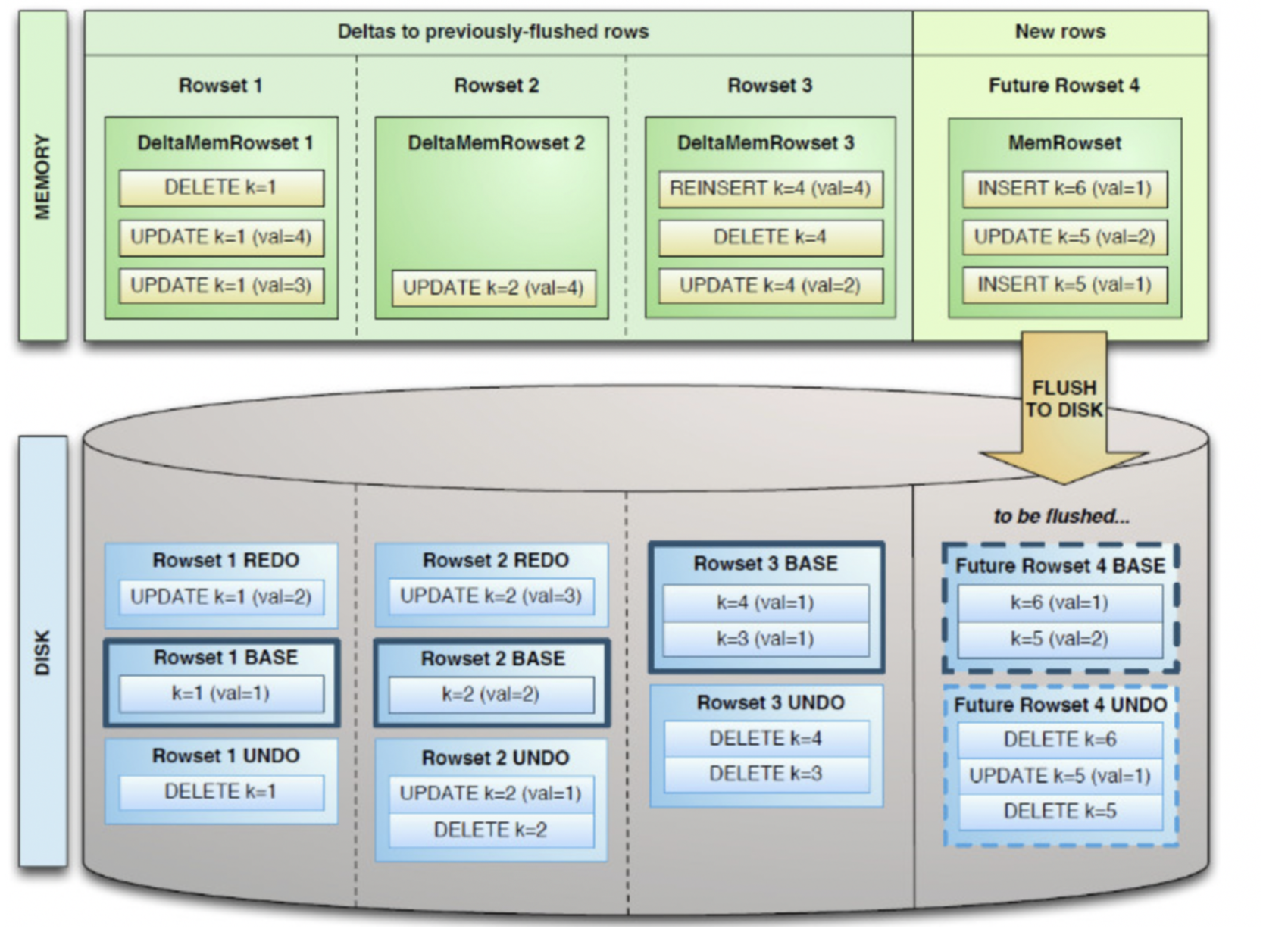
从上图(源自Kudu的源工程文件)来看:
Delta数据部分应该包含REDO与UNDO两部分,这里的REDO与UNDO与关系型数据库中的REDO与UNDO日志类似(在关系型数据库中,REDO日志记录了更新后的数据,可以用来恢复尚未写入Data File的已成功事务更新的数据。
而UNDO日志用来记录事务更新之前的数据,可以用来在事务失败时进行回滚),但也存在一些细节上的差异:
• REDO Delta Files包含了Base Data自上一次被Flush/Compaction之后的变更值。REDO Delta Files按照Timestamp顺序排列。 • UNDO Delta Files包含了Base Data自上一次Flush/Compaction之前的变更值。这样才可以保障基于一个旧Timestamp的查询能够看到一个一致性视图。UNDO按照Timestamp倒序排列。
Kudu原理-kudu的底层数据模型的更多相关文章
- Kudu系列: Kudu主键选择策略
每个Kudu 表必须设置Pimary Key(unique), 另外Kudu表不能设置secondary index, 经过实际性能测试, 本文给出了选择Kudu主键的几个策略, 测试结果纠正了我之前 ...
- kudu记录-kudu原理
1.kudu是什么? 2.kudu基本概念 特点: High availability(高可用性).Tablet server 和 Master 使用 Raft Consensus Algorith ...
- 【Web应用-Kudu】Kudu 管理和诊断 azure web 应用
Azure Kudu是 GitHub 上的一个开源项目,Kudu 站点 (也称为网站控制管理 SCM) 提供了一系列的在线工具,可以帮助用户查看 web 应用的设置,诊断 web 应用,以及安装 w ...
- List、Set集合系列之剖析HashSet存储原理(HashMap底层)
目录 List接口 1.1 List接口介绍 1.2 List接口中常用方法 List的子类 2.1 ArrayList集合 2.2 LinkedList集合 Set接口 3.1 Set接口介绍 Se ...
- 2 weekend110的zookeeper的原理、特性、数据模型、节点、角色、顺序号、读写机制、保证、API接口、ACL、选举、 + 应用场景:统一命名服务、配置管理、集群管理、共享锁、队列管理
在hadoop生态圈里,很多地方都需zookeeper. 启动的时候,都是普通的server,但在启动过程中,通过一个特定的选举机制,选出一个leader. 只运行在一台服务器上,适合测试环境:Zoo ...
- HBase 架构与工作原理1 - HBase 的数据模型
本文系转载,如有侵权,请联系我:likui0913@gmail.com 一.应用场景 HBase 与 Google 的 BigTable 极为相似,可以说 HBase 就是根据 BigTable 设计 ...
- 破败之王杀人戒bug原理剖析(从底层存储来解释)
今儿看到了破败之王的bug,一级团杀了人变成了对面,然后送塔,戒指就变成了很夸张的层数. 视频如下: https://www.bilibili.com/video/BV1yr4y1A7Mo 一开始我也 ...
- Redis核心设计原理(深入底层C源码)
Redis 基本特性 1. 非关系型的键值对数据库,可以根据键以O(1) 的时间复杂度取出或插入关联值 2. Redis 的数据是存在内存中的 3. 键值对中键的类型可以是字符串,整型,浮点型等,且键 ...
- kudu基础入门
1.kudu介绍 1.1 背景介绍 在KUDU之前,大数据主要以两种方式存储: (1)静态数据: 以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景.这类存储的局限性是数据无法进行随机 ...
随机推荐
- ffmpeg 版本升级到 4.0 增加 libaom 库 [AOMedia 的 AV1 视频编码格式]
win10 中交叉编译 libaom 时 注意事项 libaom 源代码 下载 git -c "http.proxy=ip:port" clone https://aomedia. ...
- 029_shell编写工作常用工具类总结
一.检查命令的执行结果 function check_result() { result=$? flag=$1 if [[ "$result"x == "0"x ...
- UML教程
1.前言 1.1 前言 本资料对UML1.5各种模型图的构成和功能进行说明,通过本资料的学习达到可以读懂UML模型图的目的.本资料不涉及模型图作成的要点等相关知识. 1.2 UML概述 1.2.1 ...
- Swap交换分区概念
什么是Linux swap space呢?我们先来看看下面两段关于Linux swap space的英文介绍资料: Linux divides its physical RAM (random acc ...
- PID控制器开发笔记之一:PID算法原理及基本实现
在自动控制中,PID及其衍生出来的算法是应用最广的算法之一.各个做自动控制的厂家基本都有会实现这一经典算法.我们在做项目的过程中,也时常会遇到类似的需求,所以就想实现这一算法以适用于更多的应用场景. ...
- ctrl + alt + T无法启动终端
kill -9 -1重新进入即可
- vue.js的计算机属性学习
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- usrp使用
首先打开linux 输入uhd_find_divice gqrx
- easyUI详解
1.EasyUI 是前端框架,封装大量 css和封装大量 JS 2.使用前端框架时,给标签定义class 属性,就会有样式和脚本功能了 3.data-options 属性是定义 easyui 属性的, ...
- LeetCode(68):文本左右对齐
Hard! 题目描述: 给定一个单词数组和一个长度 maxWidth,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本. 你应该使用“贪心算法”来放置给定的单词:也就是 ...