数据特征分析:1.基础分析概述& 分布分析
基础分析概述
几个基础分析思路:

分布分析

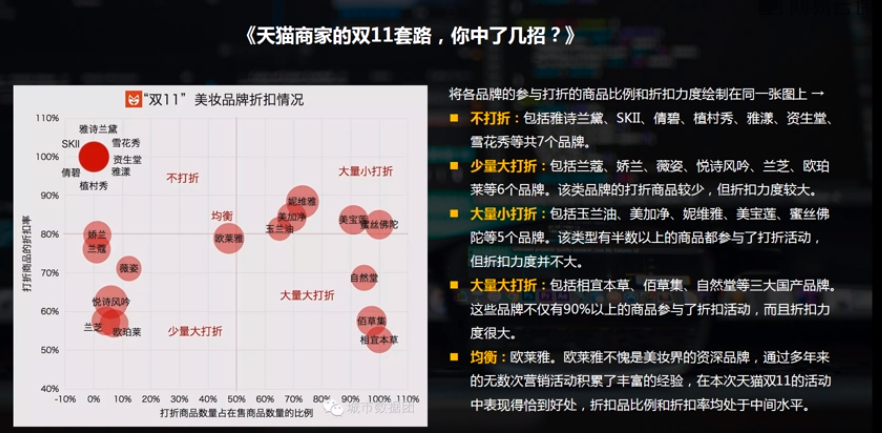
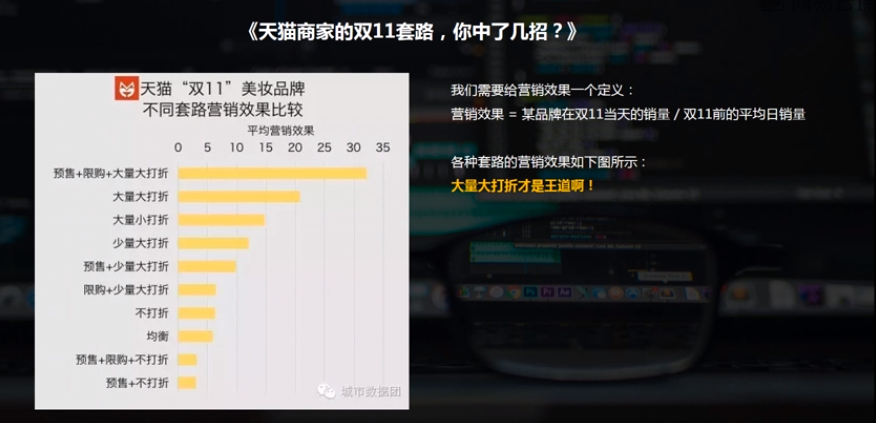
分布分析是研究数据的分布特征和分布类型,分定量数据、定性数据区分基本统计量。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
#读取数据
data = pd.read_csv(r'C:\Users\Administrator\Desktop\python数据分析\深圳罗湖二手房信息.csv',
engine = 'python')
data.head()

plt.scatter()散点图
plt.scatter(data['经度'], data['纬度'], #做个简单的三角图,按照经纬度作为它的X Y轴
s = data['房屋单价']/500, #按照房屋的单价来控制图形的大小
c = data['参考总价'], cmap = 'Reds',#按照参考总价来显示颜色
alpha = 0.4) #########plt.scatter()散点图
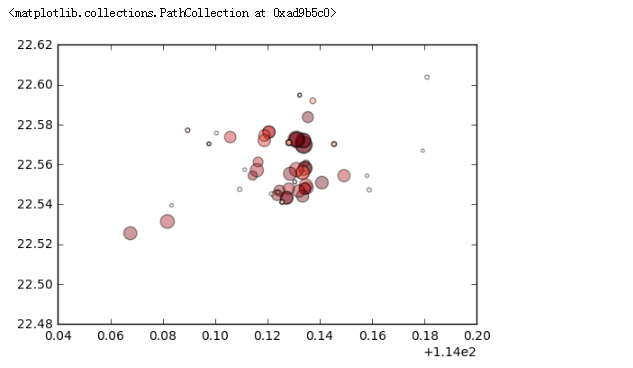
plt.scatter() 散点图
如果有底图就可以把它的位置给分布出来;点越大代表房屋的单价越高,颜色越深代表总价越高;
通过数据可见,一共8个字段
定量字段:房屋单价,参考首付,参考总价,*经度,*纬度,*房屋编码
定性字段:小区,朝向
1.极差
#极差
def d_range(df, *cols):
krange = [] #空列表,为了保持它的值
for col in cols:
crange = df[col].max() - df[col].min()
krange.append(crange)
return (krange) ##创建函数求极差
key1 = "参考总价"
key2 = "参考首付"
dr = d_range(data, key1, key2)
print("%s极差为:%f \n%s极差为:%f"% ( key1, dr[0], key2, dr[1])) #求出数据对应列的极差
参考总价极差为:175.000000
参考首付极差为:52.500000
从极差中看到销售的稳定程度
2. 频率分布情况:定量字段
(① 通过直方图直接判断分组组数)
.hist(bins = 8) 直方图
#频率分布情况(通过直方图直接判断分组组数)
data[key1].hist(bins = 8) #参考总价 简单查看数据分组,确定分组组数 --->>一般8-16组,这里按照8组为参考

可以看出主要集中在160万以上,60万以下。
频率分布的划分方式:直方图可以快速的看到它的排列情况,把它拆分:分组划分
(②求出分组区间)
pd.cut(data[key1], 10, right = False).value_count(sort=True) sort=True <-等价-> ascending=True
#频率分布情况,分组区间 ;对参考总价进行分组。
gcut = pd.cut(data[key1], 10, right = False) #分成10份,是否包含末端值选False
gcut #type(gcut)-->>Series
gcut_count = gcut.value_counts(sort = False) #做一个统计,不排序
gcut_count
# pd.cut(x, bins, right):按照组数对x分组,且返回一个和x同样长度的分组dataframe,right → 是否右边包含,默认True
# 通过groupby查看不同组的数据频率分布

data['%s分组区间'% key1] = gcut.values
data.head()

(③ 求出目标字段下频率分布的其他统计量 --->>> 频数,频率,累计频率)
分组情况,做累计频率的分组情况
r_zj = pd.DataFrame(gcut_count)
r_zj
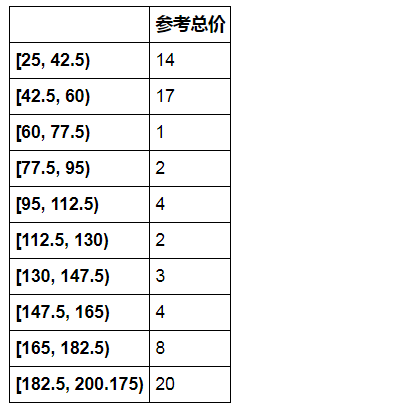
.apply(lambda x:"%.2f%%"% (x*100)) 以百分比显示
.style.bar(subset = ['频率', '累计频率']) 在格子中的条形图
#区间出现频率
r_zj = pd.DataFrame(gcut_count)
r_zj.rename(columns = {gcut_count.name:'频数'}, inplace = True) #重命名下,修改频数字段名
r_zj['频率'] = r_zj['频数']/r_zj['频数'].sum() #计算频率
r_zj['累计频率'] = r_zj['频率'].cumsum() #计算累计频率
r_zj['频率%'] = r_zj['频率'].apply(lambda x:"%.2f%%"% (x*100)) #以百分比显示频率
r_zj['累计频率%'] = r_zj['累计频率'].apply(lambda x:"%.2f%%"% (x*100)) #以百分比显示累计频率
r_zj.style.bar(subset = ['频率', '累计频率']) #可视化显示

(④ 绘制频率直方图)
r_zj['频率'].plot(kind = 'bar',figsize = (12, 2),grid = True,color = 'k',alpha = 0.4 ) 直方图
for i, j, k in zip(range(x), y, m): plt.text(i - 0.1, j + 0.01, '%i'% k, color = 'k')
#直方图
r_zj['频率'].plot(kind = 'bar',
figsize = (12, 2),
grid = True,
color = 'k',
alpha = 0.4 ) #plt.title('参考总价分布频率直方图')
x = len(r_zj)
y = r_zj['频率']
m = r_zj['频数'] for i, j, k in zip(range(x), y, m):
plt.text(i - 0.1, j + 0.01, '%i'% k, color = 'k') #-0.1 、+0.01是调整它的位置的
#添加频率标签

频率分布情况 - 定性字段
( ① 通过计数统计判断不同类别的频率)
# 频率分布情况 - 定性字段 -->> ① 通过计数统计判断不同类别的频率
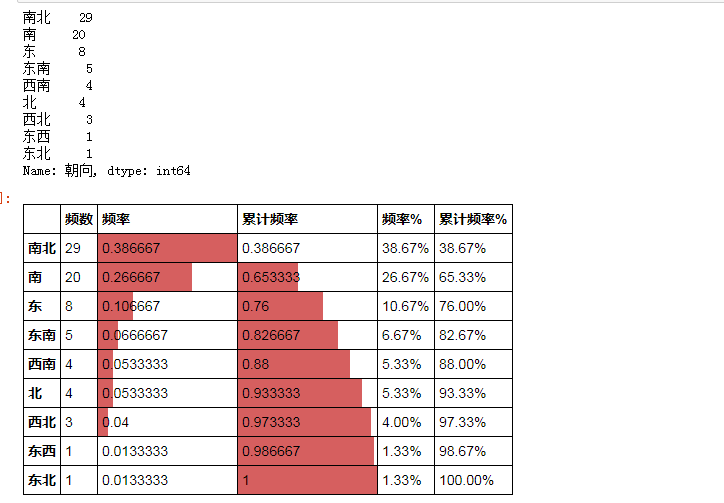
cx_g = data['朝向'].value_counts(sort = True)
print(cx_g)
# 可视化显示
r_cx = pd.DataFrame(cx_g)
r_cx.rename(columns ={cx_g.name:'频数'}, inplace = True) # 修改频数字段名
r_cx['频率'] = r_cx / r_cx['频数'].sum() # 计算频率
r_cx['累计频率'] = r_cx['频率'].cumsum() # 计算累计频率
r_cx['频率%'] = r_cx['频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示频率
r_cx['累计频率%'] = r_cx['累计频率'].apply(lambda x: "%.2f%%" % (x*100)) # 以百分比显示累计频率
r_cx.style.bar(subset=['频率','累计频率'], color='#d65f5f',width=100)
( ② 绘制频率直方图、饼图)
.plot 由Series、DataFrame直接绘制图表; plt.pie() 绘制饼图
# 频率分布情况 - 定量字段
# ② 绘制频率直方图、饼图 plt.figure(num = 1,figsize = (12,2))
r_cx['频率'].plot(kind = 'bar',
width = 0.8,
rot = 0,
color = 'k',
grid = True,
alpha = 0.5)
plt.title('参考总价分布频率直方图')
# 绘制直方图 plt.figure(num = 2)
plt.pie(r_cx['频数'],
labels = r_cx.index,
autopct='%.2f%%',
shadow = True)
plt.axis('equal') #调整它的形状
# 绘制饼图

数据特征分析:1.基础分析概述& 分布分析的更多相关文章
- R语言|数据特征分析
对数据进行质量分析以后,接下来可通过绘制图表.计算某些特征量等手段进行数据的特征分析. 主要通过分布分析.对比分析.统计量分析.周期性分析.贡献度分析.相关性分析等角度进行展开. 2.1 分布分析 分 ...
- .NET 并行(多核)编程系列之七 共享数据问题和解决概述
原文:.NET 并行(多核)编程系列之七 共享数据问题和解决概述 .NET 并行(多核)编程系列之七 共享数据问题和解决概述 前言:之前的文章介绍了了并行编程的一些基础的知识,从本篇开始,将会讲述并行 ...
- 判断数据是否服从某一分布(二)——简单易用fitdistrplus包
一.对数据的分布进行初步判断 1.1 原理 对于不同的分布,有特定的偏度(skewness)和峰度(kurtosis),正态分布.均匀分布.逻辑斯谛分布.指数分布的偏度和峰度都是特定的值,在偏 ...
- SQL SERVER大话存储结构(1)_数据页类型及页面指令分析
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! SQLServer的数据页大 ...
- 数据分析与展示——Pandas数据特征分析
Pandas数据特征分析 数据的排序 将一组数据通过摘要(有损地提取数据特征的过程)的方式,可以获得基本统计(含排序).分布/累计统计.数据特征(相关性.周期性等).数据挖掘(形成知识). .sort ...
- 基于TILE-GX实现快速数据包处理框架-netlib实现分析【转】
最近在研究suricata源码,在匹配模式的时候,有tilegx mpipe mode,转载下文,了解一下. 原文地址:http://blog.csdn.net/lhl_blog/article/de ...
- 开源大数据引擎:Greenplum 数据库架构分析
Greenplum 数据库是最先进的分布式开源数据库技术,主要用来处理大规模的数据分析任务,包括数据仓库.商务智能(OLAP)和数据挖掘等.自2015年10月正式开源以来,受到国内外业内人士的广泛关注 ...
- Python学习笔记三:数据特征分析
完成数据清理后,下面通过图表展开对数据的分析. 1.前期初判(分布分析): 1)判断分组区间: # a.散点图:plt.scatter(data[字段1],data['字段2'], s = data[ ...
- 数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)的区别是什么? 数据科学(data science)和商业分析(business analytics)之间有什么关系?
本来我以为不需要解释这个问题的,到底数据挖掘(data mining),机器学习(machine learning),和人工智能(AI)有什么区别,但是前几天因为有个学弟问我,我想了想发现我竟然也回答 ...
随机推荐
- Django 笔记(五)自定义标签 ~ 映射mysql
创建简单标签: 1-3 或者 2-3 创建包含标签: 1-2或1-3或1-4(推荐) 包含标签使用: 2 和 4对应上面的使用方法 在虚拟环境中安装: pip install pymysql 在set ...
- 详解 HTTPS、TLS、SSL、HTTP区别和关系
一.什么是HTTPS.TLS.SSL HTTP也称作HTTP over TLS.TLS的前身是SSL,TLS 1.0通常被标示为SSL 3.1,TLS 1.1为SSL 3.2,TLS 1.2为SSL ...
- 洛谷P3345 [ZJOI2015]幻想乡战略游戏 [动态点分治]
传送门 调了两个小时,终于过了-- 凭啥人家代码80行我180行啊!!! 谁叫你大括号换行 谁叫你写缺省源 思路 显然,补给点所在的位置就是这棵树的带权重心. 考虑size已知时如何找重心:一开始设答 ...
- OracleAES加密
OracleAES加密 (2012-04-29 21:52:15)转载▼标签: oracle aes 加密 it 分类: 开发-- 加密函数CREATE OR REPLACE FUNCTION FUN ...
- iOS 高德地图轨迹回放的 思路, 及方法
// 开始,公司要求制作一段跑步轨迹 在地图上的 动画回放, 传入一段经纬度, 开始一想,这不是很简单吗, 高德地图有可以把经纬度转换成坐标点的方法 /** * @brief 将经纬度转换为指定vie ...
- iframe与主框架跨域相互访问方法
iframe 与主框架相互访问方法 http://blog.csdn.net/fdipzone/article/details/17619673/ 1.同域相互访问 假设A.html 与 b.htm ...
- mongo数据库的各种查询语句示例
左边是mongodb查询语句,右边是sql语句.对照着用,挺方便. db.users.find() select * from users db.users.find({"age" ...
- redis-4.0.8 配置文件解读
# Redis configuration file example.## Note that in order to read the configuration file, Redis must ...
- LeetCode(108):将有序数组转换为二叉搜索树
Easy! 题目描述: 将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树. 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1. 示例: 给定有序数组 ...
- 调皮的HR
如图:笔试题 # -*- coding: utf- -*- """ Created on Thu Apr :: @author: weilong "" ...