spark 2.3 导致driver OOM的一个SparkPlanGraphWrapper源码的bug
背景
长话短说,我们部门一个同事找到我,说他的spark 2.3 structured streaming程序频繁报OOM,从来没有坚持过超过三四天的,叫帮看一下。
这种事情一般我是不愿意看的,因为大部分情况下spark oom就那么几种可能:
- 数据量拉太大,executor内存爆了;
- shuffle过程中数据量太大,shuffle数太少,内存又爆了;
- 闲着蛋疼调用collect之类的方法,把数据往dirver上一聚合,driver内存爆了
- 闲着蛋疼又调用了一下persist还把结果存内存,还是爆了
这些问题基本都可以通过限制每次拉取的数据/加大内存/该分片分片解决。
但这次这个我看了一下,还真不是上面这些日常问题,值得记录一下。
过程
过了一遍程序和数据,肉眼感觉没毛病,这些地方都没问题,只好祭出大杀器:
-XX:+HeapDumpOnOutOfMemoryError
顺便还加上了printGC全家桶。
程序再次挂掉后,先看了一眼gc日志,发现老年代内存使用量持续增大,fgc前后几乎无变化,那么就不是数据太大装不下,应该是内存泄漏没跑了,再看dump文件。
拿MAT打开文件,很容易就定位到了内存泄漏点,如下图所示:
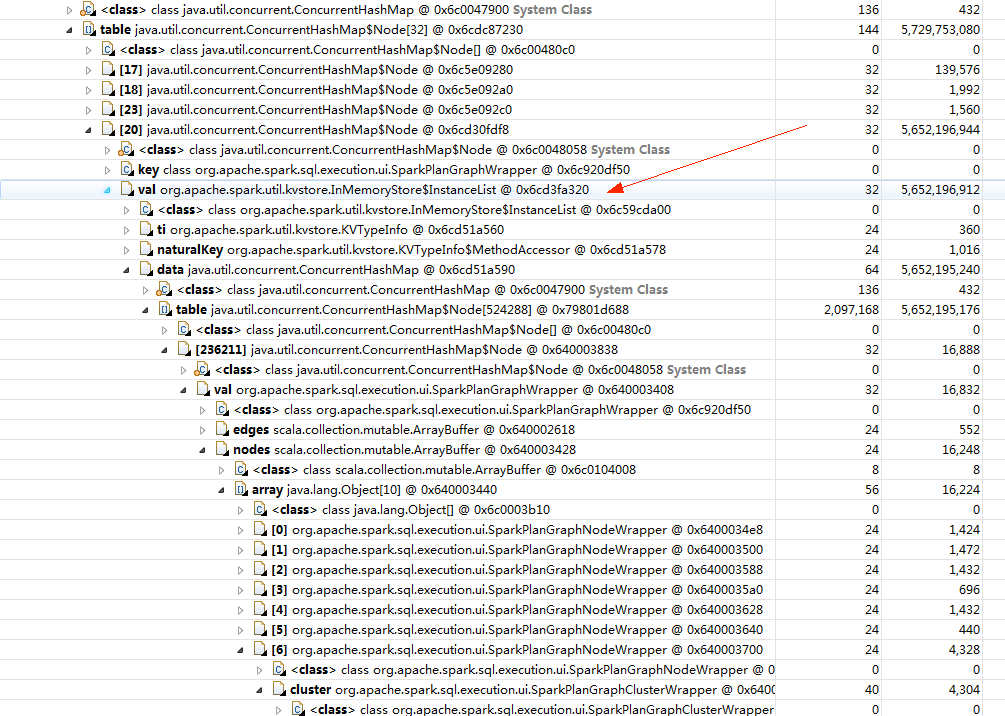
直奔源码:
public class InMemoryStore implements KVStore {
private Object metadata;
//这里就是那个5个多g大的map
private ConcurrentMap<Class<?>, InstanceList> data = new ConcurrentHashMap<>();
......
}
没毛病,能对上。所以问题应该比较清晰了,spark应该是每次执行batch时在什么地方往这个map里加了很多数据,但是又忘记了移除掉已经过期的部分,所以导致gc无效了。
那接下来要问的就是,什么地方做了put操作而又没有remove呢?我们再来看看下这个5个g的InmemoryStore的引用到底被谁持有:
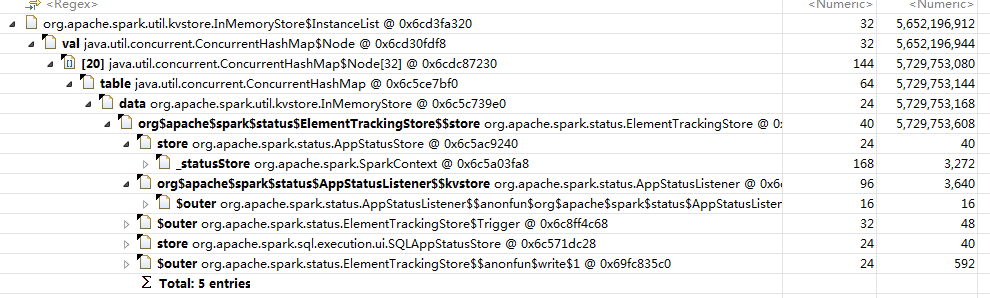
图里很明显,接下来我们要看ElementTrackingStore的实现,我顺便把这个类的说明也放在这里:
/**
* A KVStore wrapper that allows tracking the number of elements of specific types, and triggering
* actions once they reach a threshold. This allows writers, for example, to control how much data
* is stored by potentially deleting old data as new data is added.
*
* This store is used when populating data either from a live UI or an event log. On top of firing
* triggers when elements reach a certain threshold, it provides two extra bits of functionality:
*
* - a generic worker thread that can be used to run expensive tasks asynchronously; the tasks can
* be configured to run on the calling thread when more determinism is desired (e.g. unit tests).
* - a generic flush mechanism so that listeners can be notified about when they should flush
* internal state to the store (e.g. after the SHS finishes parsing an event log).
*
* The configured triggers are run on a separate thread by default; they can be forced to run on
* the calling thread by setting the `ASYNC_TRACKING_ENABLED` configuration to `false`.
*/
private[spark] class ElementTrackingStore(store: KVStore, conf: SparkConf) extends KVStore {
import config._
private val triggers = new HashMap[Class[_], Seq[Trigger[_]]]()
private val flushTriggers = new ListBuffer[() => Unit]()
private val executor = if (conf.get(ASYNC_TRACKING_ENABLED)) {
ThreadUtils.newDaemonSingleThreadExecutor("element-tracking-store-worker")
} else {
MoreExecutors.sameThreadExecutor()
}
@volatile private var stopped = false
/**
* Register a trigger that will be fired once the number of elements of a given type reaches
* the given threshold.
*
* @param klass The type to monitor.
* @param threshold The number of elements that should trigger the action.
* @param action Action to run when the threshold is reached; takes as a parameter the number
* of elements of the registered type currently known to be in the store.
*/
def addTrigger(klass: Class[_], threshold: Long)(action: Long => Unit): Unit = {
val existing = triggers.getOrElse(klass, Seq())
triggers(klass) = existing :+ Trigger(threshold, action)
}
......
}
这个类的方法里,我们需要关注的就是这个addTrigger方法,其注释也写的很明白,就是用来当保存的对象达到一定数目后触发的操作。
这时候心里就猜一下是不是什么地方的trigger写错了,所以我们再看看这个方法都在哪里使用了:
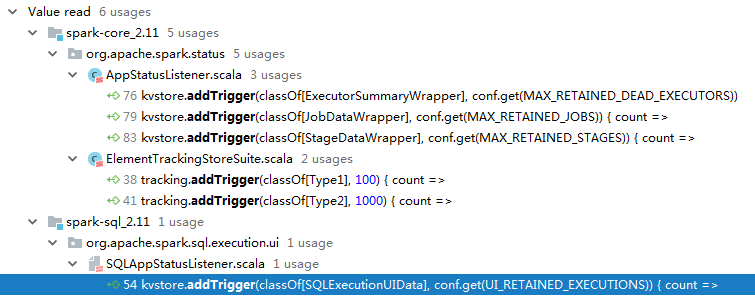
考虑到我们溢出的对象都是SparkPlanGraphNode,所以先看最下面我选中的蓝色那一行的代码:
kvstore.addTrigger(classOf[SQLExecutionUIData], conf.get(UI_RETAINED_EXECUTIONS)) { count =>
cleanupExecutions(count)
}
private def cleanupExecutions(count: Long): Unit = {
val countToDelete = count - conf.get(UI_RETAINED_EXECUTIONS)
if (countToDelete <= 0) {
return
}
val view = kvstore.view(classOf[SQLExecutionUIData]).index("completionTime").first(0L)
val toDelete = KVUtils.viewToSeq(view, countToDelete.toInt)(_.completionTime.isDefined)
//出错的就是这一行
toDelete.foreach { e => kvstore.delete(e.getClass(), e.executionId) }
}
看到了吧,这里在触发trigger的时候,压根没有删除SparkPlanGraphWrapper的相关逻辑,难怪会报oom!
结果
按理说到这里就差不多了,这个OOM的锅还真不能让同事背,的确是spark的一个bug。但是我很好奇,这么大一个问题,spark社区难道就没有动静吗?所以我就去社区搜了一下,发现了这个:
Memory leak of SparkPlanGraphWrapper in sparkUI
所以确认了,这个地方确实是spark2.3的一个隐藏bug,在2.3.1和2.4.0中被修复了,有兴趣的童鞋可以点进去看看。
全文完。
spark 2.3 导致driver OOM的一个SparkPlanGraphWrapper源码的bug的更多相关文章
- 一个lucene源码分析的博客
ITpub上的一个lucene源码分析的博客,写的比较全面:http://blog.itpub.net/28624388/cid-93356-list-1/
- Spark Job的提交与task本地化分析(源码阅读八)
我们又都知道,Spark中任务的处理也要考虑数据的本地性(locality),Spark目前支持PROCESS_LOCAL(本地进程).NODE_LOCAL(本地节点).NODE_PREF.RACK_ ...
- Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle...相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量.相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuf ...
- 6.Spark streaming技术内幕 : Job动态生成原理与源码解析
原创文章,转载请注明:转载自 周岳飞博客(http://www.cnblogs.com/zhouyf/) Spark streaming 程序的运行过程是将DStream的操作转化成RDD的操作, ...
- 最近建了一个.net源码共享群,群共享有大量网友分享的.net(C#)商业源码
.net源码共享群 324087998. 本群创建于2013/6/21: 群里都是.net(C#)程序开发人员,群共享有大量网友分享的.net(C#)商业源码.比如:DTCMS旗舰版,hishop微分 ...
- Spark Job的提交与task本地化分析(源码阅读)
Spark中任务的处理也要考虑数据的本地性(locality),Spark目前支持PROCESS_LOCAL(本地进程).NODE_LOCAL(本地节点).NODE_PREF.RACK_LOCAL(本 ...
- Spark集群任务提交流程----2.1.0源码解析
Spark的应用程序是通过spark-submit提交到Spark集群上运行的,那么spark-submit到底提交了什么,集群是怎样调度运行的,下面一一详解. 0. spark-submit提交任务 ...
- android Popupwindow 的一个demo源码
一直想用一下PopupWindow,就是苦于没有demo,自己去研究有太懒,刚好最近研究推送,下载了一个腾讯信鸽的demo,里面用到了一个PopupWindow,效果还不错,弄下来记录一下: 1.核心 ...
- 分享一个jdk源码链接
请查看下面的链接:http://hg.openjdk.java.net/jdk7u/jdk7u/jdk/file/bcba89ce0a8c/src/share/classes/,进入页面后,点击列表中 ...
随机推荐
- Spring基于注解注入的两种方式
1.@Autowried 1)默认基于类型查找容器的的Bean进行注入(注入的Bean的实现类是唯一的). 2)当实现类的Bean大于一个的时候,需结合@Qualifier,根据Bean的名称来指定需 ...
- STL之迭代器(iterator)
1 头文件 所有容器有含有其各自的迭代器型别(iterator types),所以当你使用一般的容器迭代器时,并不需要含入专门的头文件.不过有几种特别的迭代器,例如逆向迭代器,被定义于<iter ...
- AngularJS学习之旅—AngularJS 表达式(二)
1.AngularJS 表达式 AngularJS 表达式写在双大括号内:{{ expression }}. AngularJS 表达式把数据绑定到 HTML,这与 ng-bind 指令有异曲同工之妙 ...
- php中jpgraph库的使用
用Jpgraph,只要了解它的一些内置函数,可以轻松得画出折线图.柱形图.饼状图等图表. 首先要保证PHP打开了Gd2的扩展: 打开PHP.ini,定位到extension=php_gd2.dll,把 ...
- 团队作业——Alpha冲刺
团队作业--Alpha冲刺 时间安排及内容要求 时间 内容 11.1-11.16 12次 Scrum 11.16-11.20 测试报告 与 用户反馈 11.21-11.24 展示博客 11.25 课堂 ...
- vue中$router.push打开新窗口
在vue中使用 this.$router.push({ path: '/home' }) 默认是替代本窗口 如果想新开一个窗口,可以使用下面的方式: let routeData = this.$ro ...
- input accept属性限制文件上传格式
上传文件的类型:具体做法如下所示: 注意:accept属性可以限制上传格式,其有兼容性如下 <1>上传.csv格式的 <input text="file" acc ...
- vue-引入外部js文件的方法和常量
1.方法调用 a: js文件(static/js/public.js) //函数的定义 返回上一页 export function goback(laststep) { laststep } b: ...
- vue-cli3安装创建项目以及目录结构
安装脚手架cli3.0 全局安装 npm install -g @vue/cli 或 yarn global add @vue/cli 查看版本/是否安装成功 vue -V 如果你仍然需要使用旧版本的 ...
- Git 安装及用法 github 代码发布 gitlab私有仓库的搭建
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统. 这个版本控制软件,有 svn还有git,是一个工具. git是由linux的作者开发的 git是一个分布式版本控制系统 ...