Java基础系列篇:JAVA多线程 并发编程
一:为什么要用多线程:
我相信所有的东西都是以实际使用价值而去学习的,没有实际价值的学习,学了没用,没用就不会学的好。
多线程也是一样,以前学习java并没有觉得多线程有多了不起,不用多线程我一样可以开发,但是做的久了你就会发现,一些东西必须用多线程去解决。
明白并发编程是通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。
多线程安全问题原因是在cpu执行多线程时,在执行的过程中可能随时切换到其他的线程上执行。
二:创建线程的方式
(1)继承Thread类
用户的线程类只须继承Thread类并重写其run()方法即可,通过调用用户线程类的start()方法即可启动用户线程
1 class MyThread extends Thread{
2 public void run(){
3
4 }
5 }
6
7 public class TestThread{
8 public static void main(String[] args){
9 MyThread thread = new MyThread();//创建用户线程对象
10 thread.start();//启动用户线程
11 thread.run();//主线程调用用户线程对象的run()方法
12 }
13 }
(2)实现Runnable接口
当使用Thread(Runnable thread)方式创建线程对象时,须为该方法传递一个实现了Runnable接口的对象,这样创建的线程将调用实现Runnable接口的对象的run()方法
1 public class TestThread{
2 public static void main(String[] args){
3 Mythread mt = new Mythread();
4 Thread t = new Thread(mt);//创建用户线程
5 t.start();//启动用户线程
6 }
7 }
8 class Mythread implements Runnable{
9 public void run(){
10
11 }
12 }
至于哪个好,不用说肯定是后者好,因为实现接口的方式比继承类的方式更灵活,也能减少程序之间的耦合度,面向接口编程也是设计模式6大原则的核心。
三:线程的生命周期
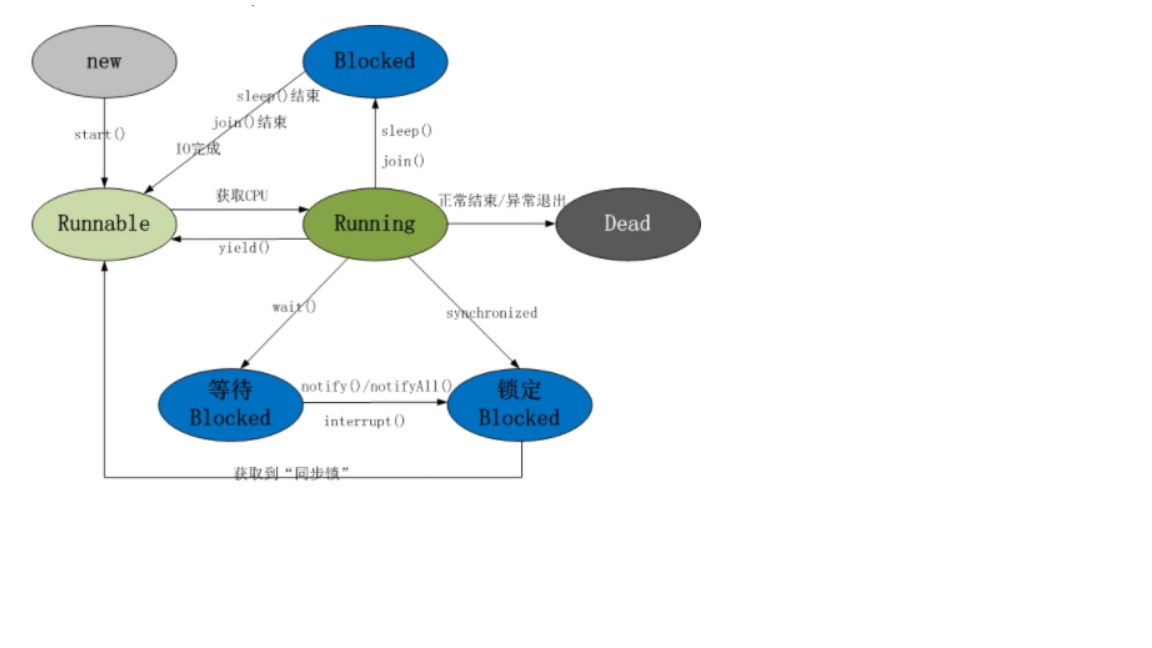
四:线程安全
指在并发的情况之下,该代码经过多线程使用,线程的调度顺序不影响任何结果。
线程安全也是有几个级别的:
(1)不可变
像String、Integer、Long这些,都是final类型的类,任何一个线程都改变不了它们的值,要改变除非新创建一个,因此这些不可变对象不需要任何同步手段就可以直接在多线程环境下使用
(2)绝对线程安全
不管运行时环境如何,调用者都不需要额外的同步措施。要做到这一点通常需要付出许多额外的代价,Java中标注自己是线程安全的类,实际上绝大多数都不是线程安全的,不过绝对线程安全的类,Java中也有,比方说CopyOnWriteArrayList、CopyOnWriteArraySet
(3)相对线程安全
相对线程安全也就是我们通常意义上所说的线程安全,像Vector这种,add、remove方法都是原子操作,不会被打断,但也仅限于此,如果有个线程在遍历某个Vector、有个线程同时在add这个Vector,99%的情况下都会出现ConcurrentModificationException,也就是fail-fast机制。
(4)线程非安全
这个就没什么好说的了,ArrayList、LinkedList、HashMap等都是线程非安全的类
五:锁
(1)死锁:学习操作系统时给的定义:死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处 于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
(2)乐观锁:就像它的名字一样,对于并发间操作产生的线程安全问题持乐观状态,乐观锁认为竞争不总是会发生,因此它不需要持有锁,将比较-设置这两个动作作为一个原子操作尝试去修改内存中的变量,如果失败则表示发生冲突,那么就应该有相应的重试逻辑。
(3)悲观锁:还是像它的名字一样,对于并发间操作产生的线程安全问题持悲观状态,悲观锁认为竞争总是会发生,因此每次对某资源进行操作时,都会持有一个独占的锁,就像synchronized,不管三七二十一,直接上了锁就操作资源了。
百度百科的举例,很好理解
如一个金融系统,当某个操作员读取用户的数据,并在读出的用户数据的基础上进行修改时(如更改用户帐户余额),如果采用悲观锁机制,也就意味着整个操作过 程中(从操作员读出数据、开始修改直至提交修改结果的全过程,甚至还包括操作 员中途去煮咖啡的时间),数据库记录始终处于加锁状态,可以想见,如果面对几百上千个并发,这样的情况将导致怎样的后果。
乐观锁机制在一定程度上解决了这个问题。乐观锁,大多是基于数据版本 ( Version )记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个 “version” 字段来实现。
读取出数据时,将此版本号一同读出,之后更新时,对此版本号加一。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。
对于上面修改用户帐户信息的例子而言,假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
1 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
2 在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
3 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
4 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
(4)读写锁:ReadWriteLock
ReadWriteLock管理一组锁,一个是只读的锁,一个是写锁。读锁可以在没有写锁的时候被多个线程同时持有,写锁是独占的。 所有读写锁的实现必须确保写操作对读操作的内存影响。换句话说,一个获得了读锁的线程必须能看到前一个释放的写锁所更新的内容。ReadWriteLock是一个读写锁接口,ReentrantReadWriteLock是ReadWriteLock接口的一个具体实现,实现了读写的分离,读锁是共享的,写锁是独占的,读和读之间不会互斥,读和写、写和读、写和写之间才会互斥,提升了读写的性能。
六:线程间操作
(1)线程间的通信:
多个线程处理同一个资源,需要线程间通信解决线程对资源的占用,避免对同一资源争夺。及引入等待唤醒机制(wait(),notify())
(a)wait()方法:线程调用wait()方法,释放它对锁的拥有权,然后等待另外的线程来通知它(通知的方式是notify()或者notifyAll()方法),这样它才能重新获得锁的拥有权和恢复执行。
要确保调用wait()方法的时候拥有锁,即,wait()方法的调用必须放在synchronized方法或synchronized块中。
(b)notify()方法:notify()方法会唤醒一个等待当前对象的锁的线程。唤醒在此对象监视器上等待的单个线程。
(c)notifAll()方法:notifyAll()方法会唤醒在此对象监视器上等待的所有线程。
(2)两个线程之间共享数据:网上给出的两种方式
方式一:当每个线程执行的代码相同时,可以使用同一个Runnable对象
public class MultiThreadShareData {
public static void main(String[] args) {
ShareData task = new ShareData(); //一个类实现了Runnable接口
for(int i = 0; i < 4; i ++) { //四个线程来卖票
new Thread(task).start();
}
}
}
class ShareData implements Runnable {
private int data = 100;
@Override
public void run() { //卖票,每次一个线程进来,先判断票数是否大于0
// while(data > 0) {
synchronized(this) {
if(data > 0) {
System.out.println(Thread.currentThread().getName() + ": " + data);
data--;
}
}
// }
}
}
方式二:若每个线程执行任务不同,可以将两个任务方法放到一个类中,然后将data也放在这个类中,然后传到不同的Runnable中,即可完成数据的共享
public class MultiThreadShareData {
public static void main(String[] args) {
ShareData task = new ShareData(); //公共数据和任务放在task中
for(int i = 0; i < 2; i ++) { //开启两个线程增加data
new Thread(new Runnable() {
@Override
public void run() {
task.increment();
}
}).start();
}
for(int i = 0; i < 2; i ++) { //开启两个线程减少data
new Thread(new Runnable() {
@Override
public void run() {
task.decrement();
}
}).start();
}
}
}
class ShareData /*implements Runnable*/ {
private int data = 0;
public synchronized void increment() { //增加data
System.out.println(Thread.currentThread().getName() + ": before : " + data);
data++;
System.out.println(Thread.currentThread().getName() + ": after : " + data);
}
public synchronized void decrement() { //减少data
System.out.println(Thread.currentThread().getName() + ": before : " + data);
data--;
System.out.println(Thread.currentThread().getName() + ": after : " + data);
}
}
本地线程:ThreadLocal
七:线程池
作用:避免频繁地创建和销毁线程,达到线程对象的重用。另外,使用线程池还可以根据项目灵活地控制并发的数目。
1:ThreadPoolExecutor类
(1)ThreadPoolExecutor类是线程池中最核心的一个类,它提供了四个构造方法。
public class ThreadPoolExecutor extends AbstractExecutorService {
/**
*corePoolSize:核心池的大小
*maximumPoolSize:线程池最大线程数
*keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止
*unit:参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性
* TimeUnit.DAYS; //天
* TimeUnit.HOURS; //小时
* TimeUnit.MINUTES; //分钟
* TimeUnit.SECONDS; //秒
* TimeUnit.MILLISECONDS; //毫秒
* TimeUnit.MICROSECONDS; //微妙
* TimeUnit.NANOSECONDS; //纳秒
*workQueue:一个阻塞队列,用来存储等待执行的任务
* ArrayBlockingQueue;
* LinkedBlockingQueue;
* SynchronousQueue;
*threadFactory:线程工厂,主要用来创建线程
*handler:表示当拒绝处理任务时的策略,有以下四种取值
* ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
* ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
* ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
* ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
*/
.....
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
...
}
(2)ThreadPoolExecutor的其他方法
a) execute()方法实际上是Executor中声明的方法,在ThreadPoolExecutor进行了具体的实现,这个方法是ThreadPoolExecutor的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。
b) submit()方法是在ExecutorService中声明的方法,在AbstractExecutorService就已经有了具体的实现,在ThreadPoolExecutor中并没有对其进行重写,这个方法也是用来向线程池提交任务的,但是它和execute()方法不同,它能够返回任务执行的结果,去看submit()方法的实现,会发现它实际上还是调用的execute()方法,只不过它利用了Future来获取任务执行结果
c) shutdown()和shutdownNow()是用来关闭线程池的。
d) 还有很多其他的方法:比如:getQueue() 、getPoolSize() 、getActiveCount()、getCompletedTaskCount()等获取与线程池相关属性的方法,有兴趣的朋友可以自行查阅API。
2:使用示例
使用时,并不提倡直接使用ThreadPoolExcutor,而是使用Executors类中的几个静态方法来创建线程池,即
Executors.newCachedThreadPool(int Integer.MAX_VALUE ); //创建一个缓冲池,缓冲池容量大小为
Executors.newSingleThreadExecutor(); //创建容量为1的缓冲池
Executors.newFixedThreadPool(); //创建固定容量大小的缓冲池
使用示例:
public class ThreadPoolTest{
public static void main(String[] args){
// 创建一个容量为5的线程池
ExecutorService executorService = Executors.newFixedThreadPool(5);
// 向线程池提交一个任务(其实就是通过线程池来启动一个线程)
for( int i = 0;i<15;i++){
executorService.execute(new TestRunnable());
system.out.println("******************");
}
executorService.shotdown();
}
}
class TestRunnable extends Thread{
@override
public void run(){
try{
Thread.sleep(1000*6);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
3 其他问题
(1)如果你提交任务时,线程池队列已满,这时会发生什么
如果你使用的LinkedBlockingQueue,也就是无界队列的话,没关系,继续添加任务到阻塞队列中等待执行,因为LinkedBlockingQueue可以近乎认为是一个无穷大的队列,可以无限存放任务;如果你使用的是有界队列比方说ArrayBlockingQueue的话,任务首先会被添加到ArrayBlockingQueue中,ArrayBlockingQueue满了,则会使用拒绝策略RejectedExecutionHandler处理满了的任务,默认是AbortPolicy。
(2)高并发、任务执行时间短的业务怎样使用线程池?并发不高、任务执行时间长的业务怎样使用线程池?并发高、业务执行时间长的业务怎样使用线程池?这是我在并发编程网上看到的一个问题:
1)高并发、任务执行时间短的业务,线程池线程数可以设置为CPU核数+1,减少线程上下文的切换
2)并发不高、任务执行时间长的业务要区分开看:
a)假如是业务时间长集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占用CPU,所以不要让所有的CPU闲下来,可以加大线程池中的线程数目,让CPU处理更多的业务
b)假如是业务时间长集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(1)一样吧,线程池中的线程数设置得少一些,减少线程上下文的切换
3)并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,设置参考 2)。最后,业务执行时间长的问题,也可能需要分析一下,看看能不能使用中间件对任务进行拆分和解耦。
多线程的实现和启动
callable 与 runable 区别
syncrhoized ,reentrantLock 各自特点和比对
线程池
future 异步方式获取执行结果
concurrent 包
lock
线程协作:
1,CountDownLatch
这个类是为了帮助猿友们方便的实现一个这样的场景,就是某一个线程需要等待其它若干个线程完成某件事以后才能继续进行
2,CyclicBarrier
这个类是为了帮助猿友们方便的实现多个线程一起启动的场景,就像赛跑一样,只要大家都准备好了,那就开始一起冲。比如下面这个程序,所有的线程都准备好了,才会一起开始执行。
3,Semaphore
这个类是为了帮助猿友们方便的实现控制数量的场景,可以是线程数量或者任务数量等等。来看看下面这段简单的代码。
4,Exchanger
这个类是为了帮助猿友们方便的实现两个线程交换数据的场景,使用起来非常简单,看看下面这段代码。
Java基础系列篇:JAVA多线程 并发编程的更多相关文章
- Java基础系列3:多线程超详细总结
该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架. 1.线程概述 几乎所 ...
- 【Java基础系列】Java IO系统
前言 创建好的输入/输出系统不仅要考虑三种不同种类的IO系统(文件,控制台,网络连接)还需要通过大量不同的方式与他们通信(顺序,随机访问,二进制,字符,按行,按字等等). 一.输入和输出 Java的I ...
- Java 多线程并发编程一览笔录
Java 多线程并发编程一览笔录 知识体系图: 1.线程是什么? 线程是进程中独立运行的子任务. 2.创建线程的方式 方式一:将类声明为 Thread 的子类.该子类应重写 Thread 类的 run ...
- 夯实Java基础系列1:Java面向对象三大特性(基础篇)
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 [https://github.com/h2pl/Java-Tutorial](https: ...
- Java工程师学习指南第1部分:夯实Java基础系列
点击关注上方"Java技术江湖",设为"置顶或星标",第一时间送达技术干货. 本文整理了微信公众号[Java技术江湖]发表和转载过的Java优质文章,想看到更多 ...
- Java基础系列--HashMap(JDK1.8)
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/10022092.html Java基础系列-HashMap 1.8 概述 HashMap是 ...
- 夯实Java基础系列3:一文搞懂String常见面试题,从基础到实战,更有原理分析和源码解析!
目录 目录 string基础 Java String 类 创建字符串 StringDemo.java 文件代码: String基本用法 创建String对象的常用方法 String中常用的方法,用法如 ...
- 夯实Java基础系列4:一文了解final关键字的特性、使用方法,以及实现原理
目录 final使用 final变量 final修饰基本数据类型变量和引用 final类 final关键字的知识点 final关键字的最佳实践 final的用法 关于空白final final内存分配 ...
- 夯实Java基础系列5:Java文件和Java包结构
目录 Java中的包概念 包的作用 package 的目录结构 设置 CLASSPATH 系统变量 常用jar包 java软件包的类型 dt.jar rt.jar *.java文件的奥秘 *.Java ...
随机推荐
- (转)预处器的对比——Sass、LESS和Stylus
英文原文:http://net.tutsplus.com/tutorials/html-css-techniques/sass-vs-less-vs-stylus-a-preprocessor-sho ...
- chrome浏览器使用chrome://inspect调试app 网页,打开空白的问题
使用chrome浏览器,输入chrome://inspect可以调试android app里面的网页,如果inspect的时候,是空白, 问题截图: 那就在C:\Windows\System32\dr ...
- Java实现后缀表达式建立表达式树
概述 表达式树的特点:叶节点是操作数,其他节点为操作符.由于一般的操作符都是二元的,所以表达式树一般都是二叉树. 根据后缀表达式"ab+cde+**"建立一颗树 文字描述: 如同后 ...
- 数组、ArrayList、链表、LinkedList
数组 数组 数组类型 不可重复 无序(线性查找) 可重复(找到第一个即可) 无序(线性查找) 不可重复 有序(二分查找) 可重复(找到第一个即可) 有序(二分查找) 插入 O(N) O(1) O( ...
- LeetCode题解之Sort List
1.题目描述 2.问题分析 使用sort算法 3.代码 ListNode* sortList(ListNode* head) { if( head == NULL || head->next = ...
- Oracle EBS INV创建保留
CREATE or REPPLACE PROCEDURE CreateReservation AS -- Common Declarations l_api_version NUMBER := 1.0 ...
- IE 出现stack overflow 报错的原因归纳
1. 重定义了系统的触发事件名称作为自定义函数名如: onclick / onsubmit ... 都是系统保留的事件名称,不允许作为重定义函数名称: 2. IE缓存满了,无法写入.解决办法:清空 ...
- linux开机步骤
linux开机启动步骤: 1.bios自检 2.MBR引导 3.引导系统,进入grub菜单 4.加载内核kernel 5.运行第一个进程init 6.读取/etc/inittab 读取运行级别 7.读 ...
- css基础内容
css基础内容 CSS 指层叠样式表 (Cascading Style Sheets)样式定义如何显示 HTML 元素样式通常存储在样式表中把样式添加到 HTML 4.0 中,是为了解决内容与表现分离 ...
- Win7下设置护眼的电脑豆沙绿界面
控制面板\所有控制面板项\个性化\窗口颜色和外观 "色调"(Hue)设为85,"饱和度"(Sat)设为90,"亮度" (Lum)设为205. ...