大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
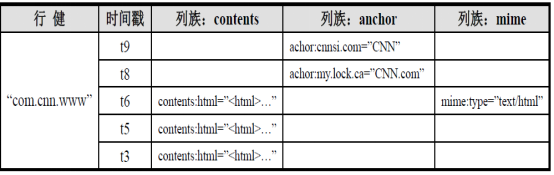
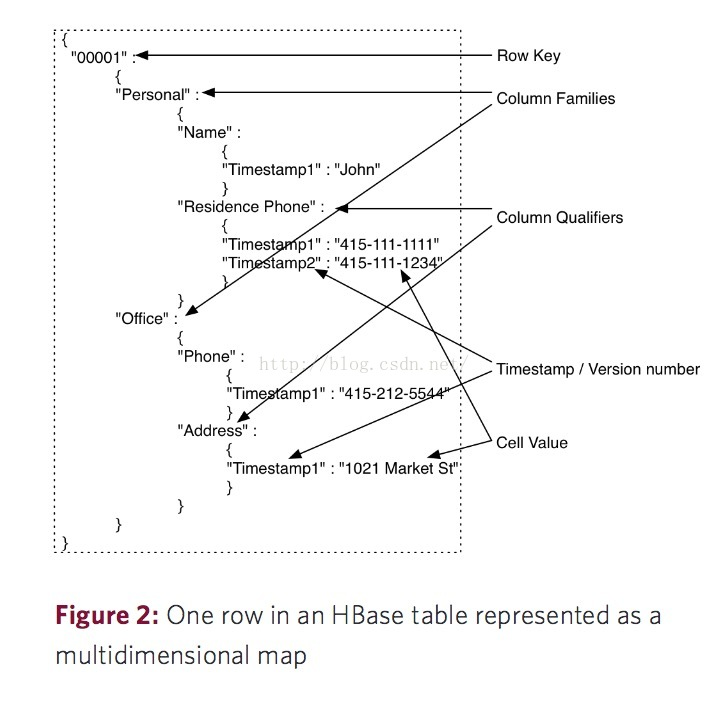
一、hbase数据模型
完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html
1.rowkey
与nosql数据库们一样,row key是用来检索记录的主键。访问HBASE table中的行,只有三种方式:
1.通过单个row key访问
2.通过row key的range(正则)
3.全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度 是 64KB,实际应用中长度一般为 10-100bytes),在HBASE内部,row key保存为字节数组。存储时,数据按照Row key的字典序(byte order)排序存储(字典序)(例如 1,10,2,3...)。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
2. Columns Family
列簇 :HBASE表中的每个列,都归属于某个列族。列族是表的schema的一部 分(而列不是),必须在使用表之前定义。
列名都以列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族。
3. Cell
由{row key, columnFamily, version} 唯一确定的单元。cell中 的数据是没有类型的,全部是字节码形式存贮。
关键字:无类型、字节码
4. Time Stamp
HBASE 中通过rowkey和columns确定的为一个存贮单元称为cell。每个 cell都保存 着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBASE(在数据写入时自动 )赋值,此时时间戳是精确到毫秒 的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版 本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE提供 了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段 时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
以上概念不是很好理解的话,参考博文的解释:http://blog.csdn.net/ymh198816/article/details/51244911
二、hbase命令
1.进入与退出
hbase shell
>quit
2.命令
常用命令参考:http://blog.csdn.net/baidu_26185625/article/details/49949527
需要注意表名等需要加引号!还有hbase的shell无法直接使用删除键删除错误字符,这里我们使用Ctrl+删除进行删除即可(其他方法不列举)
创建表
create '表名', '列族名1','列族名2','列族名N'
hbase(main)::> create 'user','id','name','age'
描述表
describe ‘表名’
hbase(main)::> describe 'user'
查看所有表
list
hbase(main)::> list
判断表存在
exists '表名'
删除表
(disable,drop)
hbase(main)::> disable 'test'
row(s) in 2.2100 seconds hbase(main)::> drop 'test'
row(s) in 1.2350 seconds
判断启用/禁用表
is_enabled '表名'
is_disabled ‘表名’
添加记录
put ‘表名’, ‘rowKey’, ‘列族 : 列‘ , '值'
hbase(main)::> put 'user','','id:info1',''
查看所有记录
scan '表名'
hbase(main)::> scan 'user'
查看rowkey下所有数据
get '表名' , 'rowKey'
hbase(main)::> get 'user',''
获取某个列族
get '表名','rowkey','列族'
hbase(main)::> get 'user','','id'
获取某个列族的某个列
get '表名','rowkey','列族:列'
hbase(main)::> get 'user','','id:info1'
删除一列
delete ‘表名’ ,‘行名’ , ‘列族:列'
hbase(main)::> delete 'user','','id:info1'
删除整行
deleteall '表名','rowkey'
清空表
truncate '表名'
三、hbase依赖zookeeper
1、 保存Hmaster的地址和backup-master地址
hmaster:
a) 管理HregionServer
b) 做增删改查表的节点
c) 管理HregionServer中的表分配
*所以hbase不像hdfs一样,namdnode需要管理元数据,它只是单纯的做管理(表的信息在zk上,连接的是zk的api,由它来创建表)
2、 保存表-ROOT-的地址
hbase默认的根表,检索表。
3、 HRegionServer列表
表的增删改查数据。
和hdfs交互,存取数据。
四、hbase开发——javaAPI操作
1.创建工程,引入依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.6</version>
</dependency>
//如果不采用maven,则引入压缩包里面的lib包下全部Jar即可!
2.JavaAPI相关解释
| Java API | 作用 |
|---|---|
| HBaseAdmin | HBase 客户端,用来操作HBase |
| Configuration | 配置对象 |
| Connection | 连接对象 |
| TableName | HBase 中的表名 |
| HTableDescriptor | HBase 表描述信息对象 |
| HColumnDescriptor | HBase 列族描述对象 |
| Table | HBase 表对象 |
| Put | 用于插入数据 |
| Get | 用于查询单条记录 |
| Delete | 删除数据对象 |
| Scan | 全表扫描对象,查询所有记录 |
| ResultScanner | 查询数据返回结果集 |
| Result | 查询返回的单条记录结果 |
| Cell | 对应HBase中的列 |
| SingleColumnValueFilter | 列值过滤器(过滤列植的相等、不等、范围等) |
| ColumnPrefixFilter | 列名前缀过滤器(过滤指定前缀的列名) |
| multipleColumnPrefixFilter | 多个列名前缀过滤器(过滤多个指定前缀的列名) |
| RowFilter | rowKey过滤器(通过正则,过滤rowKey值) |
3.API操作
官网的example,参考:https://hbase.apache.org/book.html#hbase_apis
package com.bigdata.study.hbase; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test; import java.util.ArrayList;
import java.util.List; /**
* HBase Java API 操作
* 一般我们使用Java API 主要操作的是数据即DML操作,DDL的操作较少
*/
public class HBaseTest { static Configuration conf = null;
private Connection conn = null;
private HBaseAdmin admin = null;
private TableName tableName = null;
private Table table = null; // 初始化配置
@Before
public void init() throws Exception {
conf = HBaseConfiguration.create();
// 如果不设置zookeeper地址,可以将hbase-site.xml文件复制到resource目录下
conf.set("hbase.zookeeper.quorum","node3,node4,node5");// zookeeper 地址
// conf.set("hbase.zookeeper.property.clientPort","2188");// zookeeper 客户端端口,默认为2188,可以不用设置
conn = ConnectionFactory.createConnection(conf);// 创建连接 // admin = new HBaseAdmin(conf); // 已弃用,不推荐使用
admin = (HBaseAdmin) conn.getAdmin(); // hbase 表管理类 tableName = TableName.valueOf("students"); // 表名 table = conn.getTable(tableName);// 表对象
} // --------------------DDL 操作 Start------------------
// 创建表 HTableDescriptor、HColumnDescriptor、addFamily()、createTable()
@Test
public void createTable() throws Exception {
// 创建表描述类
HTableDescriptor desc = new HTableDescriptor(tableName); // 添加列族info
HColumnDescriptor family_info = new HColumnDescriptor("info");
desc.addFamily(family_info); // 添加列族address
HColumnDescriptor family_address = new HColumnDescriptor("address");
desc.addFamily(family_address); // 创建表
admin.createTable(desc);
} // 删除表 先弃用表disableTable(表名),再删除表 deleteTable(表名)
@Test
public void deleteTable() throws Exception {
admin.disableTable(tableName);
admin.deleteTable(tableName);
} // 添加列族 addColumn(表名,列族)
@Test
public void addFamily() throws Exception {
admin.addColumn(tableName, new HColumnDescriptor("hobbies"));
} // 删除列族 deleteColumn(表名,列族)
@Test
public void deleteFamily() throws Exception {
admin.deleteColumn(tableName, Bytes.toBytes("hobbies"));
} // --------------------DDL 操作 End--------------------- // ----------------------DML 操作 Start-----------------
// 添加数据 Put(列族,列,列值)(HBase 中没有修改,插入时rowkey相同,数据会覆盖)
@Test
public void insertData() throws Exception {
// 添加一条记录
// Put put = new Put(Bytes.toBytes("1001"));
// put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("San-Qiang Zhang"));
// put.addColumn(Bytes.toBytes("address"), Bytes.toBytes("province"), Bytes.toBytes("Hebei"));
// put.addColumn(Bytes.toBytes("address"), Bytes.toBytes("city"), Bytes.toBytes("Shijiazhuang"));
// table.put(put); // 添加多条记录(批量插入)
List<Put> putList = new ArrayList<Put>();
Put put1 = new Put(Bytes.toBytes("1002"));
put1.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("Lisi"));
put1.addColumn(Bytes.toBytes("info"), Bytes.toBytes("sex"), Bytes.toBytes("1"));
put1.addColumn(Bytes.toBytes("address"), Bytes.toBytes("city"), Bytes.toBytes("Shanghai"));
Put put2 = new Put(Bytes.toBytes("1003"));
put2.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("Lili"));
put2.addColumn(Bytes.toBytes("info"), Bytes.toBytes("sex"), Bytes.toBytes("0"));
put2.addColumn(Bytes.toBytes("address"), Bytes.toBytes("city"), Bytes.toBytes("Beijing"));
Put put3 = new Put(Bytes.toBytes("1004"));
put3.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name_a"), Bytes.toBytes("Zhaosi"));
Put put4 = new Put(Bytes.toBytes("1004"));
put4.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name_b"), Bytes.toBytes("Wangwu"));
putList.add(put1);
putList.add(put2);
putList.add(put3);
putList.add(put4);
table.put(putList);
} // 删除数据 Delete
@Test
public void deleteData() throws Exception {
// 删除一条数据(行健为1002)
// Delete delete = new Delete(Bytes.toBytes("1002"));
// table.delete(delete); // 删除行健为1003,列族为info的数据
// Delete delete = new Delete(Bytes.toBytes("1003"));
// delete.addFamily(Bytes.toBytes("info"));
// table.delete(delete); // 删除行健为1,列族为address,列为city的数据
Delete delete = new Delete(Bytes.toBytes("1001"));
delete.addColumn(Bytes.toBytes("address"), Bytes.toBytes("city"));
table.delete(delete);
} // 单条查询 Get
@Test
public void getData() throws Exception {
Get get = new Get(Bytes.toBytes("1001"));
// get.addFamily(Bytes.toBytes("info")); //指定获取某个列族
// get.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name")); //指定获取某个列族中的某个列
Result result = table.get(get); System.out.println("行健:" + Bytes.toString(result.getRow()));
byte[] name = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
byte[] sex = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex"));
byte[] city = result.getValue(Bytes.toBytes("address"), Bytes.toBytes("city"));
byte[] province = result.getValue(Bytes.toBytes("address"), Bytes.toBytes("province"));
if (name != null) System.out.println("姓名:" + Bytes.toString( name));
if (sex != null) System.out.println("性别:" + Bytes.toString( sex));
if (province != null) System.out.println("省份:" + Bytes.toString(province));
if (city != null) System.out.println("城市:" + Bytes.toString(city));
} // 全表扫描 Scan
@Test
public void scanData() throws Exception {
Scan scan = new Scan(); // Scan 全表扫描对象
// 行健是以字典序排序,可以使用scan.setStartRow(),scan.setStopRow()设置行健的字典序
// scan.addFamily(Bytes.toBytes("info")); // 只查询列族info
//scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name")); // 只查询列name
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
} // 全表扫描:列值过滤器(过滤列植的相等、不等、范围等) SingleColumnValueFilter
@Test
public void singleColumnValueFilter() throws Exception {
/**
* CompareOp 是一个枚举,有如下几个值
* LESS 小于
* LESS_OR_EQUAL 小于或等于
* EQUAL 等于
* NOT_EQUAL 不等于
* GREATER_OR_EQUAL 大于或等于
* GREATER 大于
* NO_OP 无操作
*/
// 查询列名大于San-Qiang Zhang的数据
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
Bytes.toBytes("info"), Bytes.toBytes("name"),
CompareFilter.CompareOp.EQUAL, Bytes.toBytes("San-Qiang Zhang"));
Scan scan = new Scan();
scan.setFilter(singleColumnValueFilter);
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
} // 全表扫描:列名前缀过滤器(过滤指定前缀的列名) ColumnPrefixFilter
@Test
public void columnPrefixFilter() throws Exception {
// 查询列以name_开头的数据
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("name_"));
Scan scan = new Scan();
scan.setFilter(columnPrefixFilter);
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
} // 全表扫描:多个列名前缀过滤器(过滤多个指定前缀的列名) MultipleColumnPrefixFilter
@Test
public void multipleColumnPrefixFilter() throws Exception {
// 查询列以name_或c开头的数据
byte[][] bytes = new byte[][]{Bytes.toBytes("name_"), Bytes.toBytes("c")};
MultipleColumnPrefixFilter multipleColumnPrefixFilter = new MultipleColumnPrefixFilter(bytes);
Scan scan = new Scan();
scan.setFilter(multipleColumnPrefixFilter);
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
} // rowKey过滤器(通过正则,过滤rowKey值) RowFilter
@Test
public void rowFilter() throws Exception {
// 匹配rowkey以100开头的数据
// Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^100"));
// 匹配rowkey以2结尾的数据
RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("2$"));
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
printResult1(scanner);
} // 多个过滤器一起使用
@Test
public void multiFilterTest() throws Exception {
/**
* Operator 为枚举类型,有两个值 MUST_PASS_ALL 表示 and,MUST_PASS_ONE 表示 or
*/
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
// 查询性别为0(nv)且 行健以10开头的数据
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
Bytes.toBytes("info"), Bytes.toBytes("sex"),
CompareFilter.CompareOp.EQUAL, Bytes.toBytes("0"));
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^10"));
filterList.addFilter(singleColumnValueFilter);
filterList.addFilter(rowFilter);
Scan scan = new Scan();
scan.setFilter(rowFilter);
ResultScanner scanner = table.getScanner(scan);
// printResult1(scanner);
printResult2(scanner);
} // --------------------DML 操作 End-------------------
/** 打印查询结果:方法一 */
public void printResult1(ResultScanner scanner) throws Exception {
for (Result result: scanner) {
System.out.println("行健:" + Bytes.toString(result.getRow()));
byte[] name = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"));
byte[] sex = result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex"));
byte[] city = result.getValue(Bytes.toBytes("address"), Bytes.toBytes("city"));
byte[] province = result.getValue(Bytes.toBytes("address"), Bytes.toBytes("province"));
if (name != null) System.out.println("姓名:" + Bytes.toString( name));
if (sex != null) System.out.println("性别:" + Bytes.toString( sex));
if (province != null) System.out.println("省份:" + Bytes.toString(province));
if (city != null) System.out.println("城市:" + Bytes.toString(city));
System.out.println("------------------------------");
}
} /** 打印查询结果:方法二 */
public void printResult2(ResultScanner scanner) throws Exception {
for (Result result: scanner) {
System.out.println("-----------------------");
// 遍历所有的列及列值
for (Cell cell : result.listCells()) {
System.out.print(Bytes.toString(CellUtil.cloneQualifier(cell)) + ":");
System.out.print(Bytes.toString(CellUtil.cloneValue(cell)) + "\t");
}
System.out.println();
System.out.println("-----------------------");
}
} // 释放资源
@After
public void destory() throws Exception {
admin.close();
}
}
hbaseAPI操作
这里的删除的时候不需要disable了,直接delete即可!
参考链接:http://blog.csdn.net/sinat_39409672/article/details/78403015
package cn.itcast_01_hbase; import java.util.ArrayList; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.filter.ColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.FilterList.Operator;
import org.apache.hadoop.hbase.filter.RegexStringComparator;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test; public class HbaseTest { /**
* 配置ss
*/
static Configuration config = null;
private Connection connection = null;
private Table table = null; @Before
public void init() throws Exception {
config = HBaseConfiguration.create();// 配置
config.set("hbase.zookeeper.quorum", "master,work1,work2");// zookeeper地址
config.set("hbase.zookeeper.property.clientPort", "2181");// zookeeper端口
connection = ConnectionFactory.createConnection(config);
table = connection.getTable(TableName.valueOf("user"));
} /**
* 创建一个表
*
* @throws Exception
*/
@Test
public void createTable() throws Exception {
// 创建表管理类
HBaseAdmin admin = new HBaseAdmin(config); // hbase表管理
// 创建表描述类
TableName tableName = TableName.valueOf("test3"); // 表名称
HTableDescriptor desc = new HTableDescriptor(tableName);
// 创建列族的描述类
HColumnDescriptor family = new HColumnDescriptor("info"); // 列族
// 将列族添加到表中
desc.addFamily(family);
HColumnDescriptor family2 = new HColumnDescriptor("info2"); // 列族
// 将列族添加到表中
desc.addFamily(family2);
// 创建表
admin.createTable(desc); // 创建表
} @Test
@SuppressWarnings("deprecation")
public void deleteTable() throws MasterNotRunningException,
ZooKeeperConnectionException, Exception {
HBaseAdmin admin = new HBaseAdmin(config);
admin.disableTable("test3");
admin.deleteTable("test3");
admin.close();
} /**
* 向hbase中增加数据
*
* @throws Exception
*/
@SuppressWarnings({ "deprecation", "resource" })
@Test
public void insertData() throws Exception {
table.setAutoFlushTo(false);
table.setWriteBufferSize(534534534);
ArrayList<Put> arrayList = new ArrayList<Put>();
for (int i = 21; i < 50; i++) {
Put put = new Put(Bytes.toBytes("1234"+i));
put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("wangwu"+i));
put.add(Bytes.toBytes("info"), Bytes.toBytes("password"), Bytes.toBytes(1234+i));
arrayList.add(put);
} //插入数据
table.put(arrayList);
//提交
table.flushCommits();
} /**
* 修改数据
*
* @throws Exception
*/
@Test
public void uodateData() throws Exception {
Put put = new Put(Bytes.toBytes("1234"));
put.add(Bytes.toBytes("info"), Bytes.toBytes("namessss"), Bytes.toBytes("lisi1234"));
put.add(Bytes.toBytes("info"), Bytes.toBytes("password"), Bytes.toBytes(1234));
//插入数据
table.put(put);
//提交
table.flushCommits();
} /**
* 删除数据
*
* @throws Exception
*/
@Test
public void deleteDate() throws Exception {
Delete delete = new Delete(Bytes.toBytes("1234"));
table.delete(delete);
table.flushCommits();
} /**
* 单条查询
*
* @throws Exception
*/
@Test
public void queryData() throws Exception {
Get get = new Get(Bytes.toBytes("1234"));
Result result = table.get(get);
System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password"))));
System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("namessss"))));
System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex"))));
} /**
* 全表扫描
*
* @throws Exception
*/
@Test
public void scanData() throws Exception {
Scan scan = new Scan();
//scan.addFamily(Bytes.toBytes("info"));
//scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("password"));
scan.setStartRow(Bytes.toBytes("wangsf_0"));
scan.setStopRow(Bytes.toBytes("wangwu"));
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password"))));
System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"))));
//System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("password"))));
//System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name"))));
}
} /**
* 全表扫描的过滤器
* 列值过滤器
*
* @throws Exception
*/
@Test
public void scanDataByFilter1() throws Exception { // 创建全表扫描的scan
Scan scan = new Scan();
//过滤器:列值过滤器
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("info"),
Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL,
Bytes.toBytes("zhangsan2"));
// 设置过滤器
scan.setFilter(filter); // 打印结果集
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password"))));
System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"))));
//System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("password"))));
//System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name"))));
} }
/**
* rowkey过滤器
* @throws Exception
*/
@Test
public void scanDataByFilter2() throws Exception { // 创建全表扫描的scan
Scan scan = new Scan();
//匹配rowkey以wangsenfeng开头的
RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^12341"));
// 设置过滤器
scan.setFilter(filter);
// 打印结果集
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("password"))));
System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name"))));
//System.out.println(Bytes.toInt(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("password"))));
//System.out.println(Bytes.toString(result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name"))));
} } /**
* 匹配列名前缀
* @throws Exception
*/
@Test
public void scanDataByFilter3() throws Exception { // 创建全表扫描的scan
Scan scan = new Scan();
//匹配rowkey以wangsenfeng开头的
ColumnPrefixFilter filter = new ColumnPrefixFilter(Bytes.toBytes("na"));
// 设置过滤器
scan.setFilter(filter);
// 打印结果集
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
System.out.println("rowkey:" + Bytes.toString(result.getRow()));
System.out.println("info:name:"
+ Bytes.toString(result.getValue(Bytes.toBytes("info"),
Bytes.toBytes("name"))));
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")) != null) {
System.out.println("info:age:"
+ Bytes.toInt(result.getValue(Bytes.toBytes("info"),
Bytes.toBytes("age"))));
}
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex")) != null) {
System.out.println("infi:sex:"
+ Bytes.toInt(result.getValue(Bytes.toBytes("info"),
Bytes.toBytes("sex"))));
}
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name")) != null) {
System.out
.println("info2:name:"
+ Bytes.toString(result.getValue(
Bytes.toBytes("info2"),
Bytes.toBytes("name"))));
}
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("age")) != null) {
System.out.println("info2:age:"
+ Bytes.toInt(result.getValue(Bytes.toBytes("info2"),
Bytes.toBytes("age"))));
}
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("sex")) != null) {
System.out.println("info2:sex:"
+ Bytes.toInt(result.getValue(Bytes.toBytes("info2"),
Bytes.toBytes("sex"))));
}
} }
/**
* 过滤器集合
* @throws Exception
*/
@Test
public void scanDataByFilter4() throws Exception { // 创建全表扫描的scan
Scan scan = new Scan();
//过滤器集合:MUST_PASS_ALL(and),MUST_PASS_ONE(or)
FilterList filterList = new FilterList(Operator.MUST_PASS_ONE);
//匹配rowkey以wangsenfeng开头的
RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator("^wangsenfeng"));
//匹配name的值等于wangsenfeng
SingleColumnValueFilter filter2 = new SingleColumnValueFilter(Bytes.toBytes("info"),
Bytes.toBytes("name"), CompareFilter.CompareOp.EQUAL,
Bytes.toBytes("zhangsan"));
filterList.addFilter(filter);
filterList.addFilter(filter2);
// 设置过滤器
scan.setFilter(filterList);
// 打印结果集
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
System.out.println("rowkey:" + Bytes.toString(result.getRow()));
System.out.println("info:name:"
+ Bytes.toString(result.getValue(Bytes.toBytes("info"),
Bytes.toBytes("name"))));
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info"), Bytes.toBytes("age")) != null) {
System.out.println("info:age:"
+ Bytes.toInt(result.getValue(Bytes.toBytes("info"),
Bytes.toBytes("age"))));
}
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info"), Bytes.toBytes("sex")) != null) {
System.out.println("infi:sex:"
+ Bytes.toInt(result.getValue(Bytes.toBytes("info"),
Bytes.toBytes("sex"))));
}
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("name")) != null) {
System.out
.println("info2:name:"
+ Bytes.toString(result.getValue(
Bytes.toBytes("info2"),
Bytes.toBytes("name"))));
}
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("age")) != null) {
System.out.println("info2:age:"
+ Bytes.toInt(result.getValue(Bytes.toBytes("info2"),
Bytes.toBytes("age"))));
}
// 判断取出来的值是否为空
if (result.getValue(Bytes.toBytes("info2"), Bytes.toBytes("sex")) != null) {
System.out.println("info2:sex:"
+ Bytes.toInt(result.getValue(Bytes.toBytes("info2"),
Bytes.toBytes("sex"))));
}
} } @After
public void close() throws Exception {
table.close();
connection.close();
}
}
javaAPI操作
五、使用hive操作hbase
参考:http://blog.csdn.net/aaronhadoop/article/details/28398157
大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI的更多相关文章
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据入门第十五天——HBase整合:云笔记项目
一.功能简述 1.笔记本管理(增删改) 2.笔记管理 3.共享笔记查询功能 4.回收站 效果预览: 二.库表设计 1.设计理念 将云笔记信息分别存储在redis和hbase中. redis(缓存):存 ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 大数据笔记(十四)——HBase的过滤器与Mapreduce
一. HBase过滤器 1.列值过滤器 2.列名前缀过滤器 3.多个列名前缀过滤器 4.行键过滤器5.组合过滤器 package demo; import javax.swing.RowFilter; ...
随机推荐
- JS 解决 IOS 中拍照图片预览旋转 90度 BUG
上篇博文[ Js利用Canvas实现图片压缩 ]中做了图片压缩上传,但是在IOS真机测试的时候,发现图片预览的时候自动逆时针旋转了90度.对于这个bug,我完全不知道问题出在哪里,接下来就是面向百度编 ...
- 树莓派 MPG视频硬件解码破解 Raspberry Pi Patch for MPEG-2, VC-1 license
Enable the Pi's hardware decoding of MPEG-2 and VC-1 MPEG2 patents have expired If you have start.e ...
- 学习笔记(5)——实验室集群LVS监控Web界面配置
症状:通过虚拟IP能访问到监控页面:http://192.168.253.110/ipvsadm.php,但是却无法读出LVS任务分发及集群负载信息. 打开ipvsadm.php页面,源码如下: &l ...
- 修改Sql Server 数据库文件默认存放目录
-- 更改数据文件存放目录 EXEC xp_instance_regwrite @rootkey='HKEY_LOCAL_MACHINE', @key='Software\Micr ...
- 破解 jar 包之直接修改 .class 文件方式
一.常规 JAVA 软件破解流程 先讲一下常规jar包的破解流程. 1. 快速定位. 1) 通过procmon监控相关软件,查看程序都访问了些啥. 2) 用jd-gu ...
- guider – 全系统Linux性能分析器
Guider是一个免费且开源的,功能强大的全系统性能分析工具,主要以Python for Linux 操作系统编写. 它旨在衡量系统资源使用量并跟踪系统行为,从而使其可以有效分析系统性能问题或进行性能 ...
- InfoPath读取数据库
public void LoadBtn_Clicked(object sender, ClickedEventArgs e) { // 配置连接字符串 using (SqlConnection con ...
- November 14th, 2017 Week 46th Tuesday
Eternity is said not to be an extension of time but an absence of time. 永恒不是时间的无限延伸,而是没有时间. What is ...
- python3: 数字日期和时间(1)
---恢复内容开始--- 1. 数字的四舍五入 Q: 你想对浮点数执行指定精度的舍入运算 A: 简单的使用内置的round(value, ndigits)函数即可. >>> roun ...
- FZU Monthly-201901 获奖名单
FZU Monthly-201901 获奖名单 冠军: S031702338 郑学贵 一等奖: S031702524 罗继鸿 S031702647 黄海东 二等奖: S031702413 韩洪威 S0 ...