MapReduce编程之wordcount
实践
MapReduce编程之wordcount
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class WordCountApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
for(String word : words){
// 通过上下文把map的处理结果输出
context.write(new Text(word),one);
}
} } /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} /**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{
//创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(WordCountApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行
hadoop jar hadoop-train-1.0-SNAPSHOT.jar WordCountApp /hdfsapi/test/b.txt /hdfsapi/test/out
MapReduce编程之Combiner
本地reduce(map端reduce)
减少Map Tasks输出的数据量及数据网络传输量
combiner案例开发
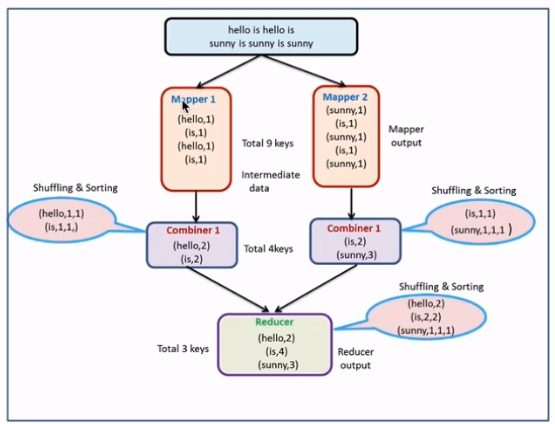
使用场景:求和、求次数
代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class CombinerApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
for(String word : words){
// 通过上下文把map的处理结果输出
context.write(new Text(word),one);
}
} } /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} /**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{ //创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(CombinerApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//通过job的设置combiner处理类,其实逻辑上和我们的reduce是一模一样的
job.setCombinerClass(MyReduce.class);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 执行命令
hadoop jar hadoop-train-1.0-SNAPSHOT.jar WordCountApp /hdfsapi/test/b.txt /hdfsapi/test/out
MapReduce编程之Partitioner
partitioner决定MapTask输出的数据交由哪个ReduceTask处理
默认实现:分发的key的hash值对ReduceTask个数取模
partitioner案例开发
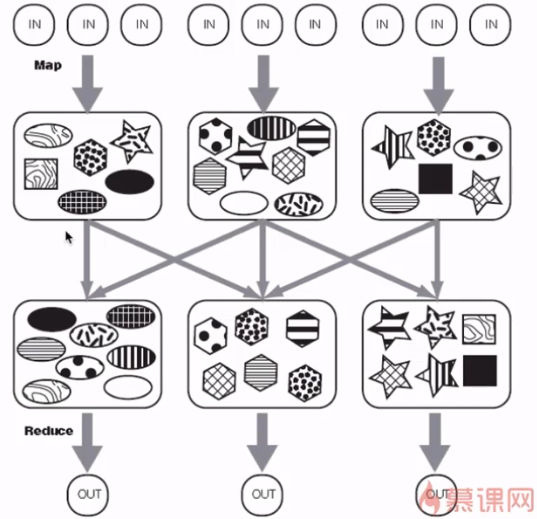
- 代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* 使用MapReduce开发WordCount的应用程序
*/
public class PartitionerApp { /**
* Map:读取输入的文件
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{ LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 接收到的每一行数据
String line = value.toString();
//按照指定分隔符进行拆分
String[] words = line.split(" ");
context.write(new Text(words[0]),new LongWritable(Long.parseLong(words[1])));
}
} /**
* 归并操作
*/
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for(LongWritable value : values){
//求key出现的次数和
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
} public static class MyPartitioner extends Partitioner<Text,LongWritable>{
@Override
public int getPartition(Text key, LongWritable longWritable, int i) {
if(key.toString().equals("xiaomi")){
return 0;
}
if(key.toString().equals("huawei")){
return 1;
}
if(key.toString().equals("iphone")){
return 2;
}
return 3;
}
}
/**
* 定义Driver:封装lMapReduce作业的所有信息
* @param args
*/
public static void main(String[] args) throws Exception{ //创建configuration
Configuration configuration = new Configuration();
//准备清理已存在的输出目录
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("out file exists,but is has deleted!");
}
//创建job
Job job = Job.getInstance(configuration,"WordCount");
//设置job的处理类
job.setJarByClass(PartitionerApp.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
//设置map相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//通过job的设置partition
job.setPartitionerClass(MyPartitioner.class);
//设置4个reduce,每个分区一个
job.setNumReduceTasks(4);
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job , new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 执行命令
hadoop jar hadoop-train-1.0-SNAPSHOT.jar PartitionerApp /hdfsapi/test/partitioner /hdfsapi/test/outpartitioner
MapReduce编程之wordcount的更多相关文章
- mapReduce编程之auto complete
1 n-gram模型与auto complete n-gram模型是假设文本中一个词出现的概率只与它前面的N-1个词相关.auto complete的原理就是,根据用户输入的词,将后续出现概率较大的词 ...
- mapReduce编程之Recommender System
1 协同过滤算法 协同过滤算法是现在推荐系统的一种常用算法.分为user-CF和item-CF. 本文的电影推荐系统使用的是item-CF,主要是由于用户数远远大于电影数,构建矩阵的代价更小:另外,电 ...
- mapReduce编程之google pageRank
1 pagerank算法介绍 1.1 pagerank的假设 数量假设:每个网页都会给它的链接网页投票,假设这个网页有n个链接,则该网页给每个链接平分投1/n票. 质量假设:一个网页的pagerank ...
- MapReduce编程之Reduce Join多种应用场景与使用
在关系型数据库中 Join 是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求, 例如在数据分析时需要连接从不同的数据源中获取到数据.不同于传统的单机模式 ...
- MapReduce编程之Semi Join多种应用场景与使用
Map Join 实现方式一 ● 使用场景:一个大表(整张表内存放不下,但表中的key内存放得下),一个超大表 ● 实现方式:分布式缓存 ● 用法: SemiJoin就是所谓的半连接,其实仔细一看就是 ...
- MapReduce编程之Map Join多种应用场景与使用
Map Join 实现方式一:分布式缓存 ● 使用场景:一张表十分小.一张表很大. ● 用法: 在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeC ...
- Hadoop基础-Map端链式编程之MapReduce统计TopN示例
Hadoop基础-Map端链式编程之MapReduce统计TopN示例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 对“temp.txt”中的数据进行分析,统计出各 ...
- 网络编程之socket
网络编程之socket socket:在网络编程中的一个基本组件,也称套接字. 一个套接字就是socket模块中的socket类的一个实例. 套接字包括两个: 服务器套接字和客户机套接字 套接字的实例 ...
- C++混合编程之idlcpp教程Python篇(9)
上一篇在这 C++混合编程之idlcpp教程Python篇(8) 第一篇在这 C++混合编程之idlcpp教程(一) 与前面的工程相比,工程PythonTutorial7中除了四个文件PythonTu ...
随机推荐
- DtCMS 在IIS7.0 下之伪静态
1)首先新建一个应用程序池,名称任意,比如:nettest,托管管道模式先暂时设置为集成模式,等下面的一系列设置完成之后再设置成经典模式: 2)部署好站点,并将此站点的应用程序池设置为nettest; ...
- 初学者的分布式Python爬虫教程
下面是一个超级计算机的排行榜,如果我们能拥有其中任意一个,那么我们就不需要搞什么分布式系统.可是我们买不起,即使买得起,也交不起电费,所以我们只好费脑子搞分布式. 分布式的本质就如上期提到的一个概念: ...
- Fedora : multilib version problems found
摘自:https://smjrifle.net/fedora-fix-multilib-version-problems/ This error was due to duplicate packag ...
- Python Json模块中dumps、loads、dump、load函数介绍
1.json.dumps() json.dumps()用于将dict类型的数据转成str,因为如果直接将dict类型的数据写入json文件中会发生报错,因此在将数据写入时需要用到该函数. import ...
- mysql5.6改进子查询实测试
表t1,t2 各自生成100万条记录. 表引擎 myiasm ,查询语句 select * from t1 where id2 in (select id2 from t2 ) 查询速度 2.x秒 ...
- JDK 规范目录
JDK 规范目录 1.1 Java 异常处理 2.1 JDK 之 NIO 2 WatchService.WatchKey(监控文件变化) https://mp.weixin.qq.com/s/NIn2 ...
- jmeter多用户并发
1.需要参数化 2.单用户需要在请求头里面传入cookie
- PDO beginTransaction (),exec(),commit ()
$dsn = 'sqlsrv:server=.\SQLExpress;Database=thinkphp'; $user = 'admin'; $password = 'pass1234'; try ...
- canvas 实现时钟效果
var clock = document.getElementById('clock'); var cxt = clock.getContext('2d'); function drawClock() ...
- Python之内置函数一
一:绝对值,abs i = abs(-123) print(i) # 打印结果 123 二:判断真假,all,与any 对于all # 每个元素都为真,才是True # 假,0,None," ...