Windows下CRF++进行中文人名识别的初次尝试
语料来自1998年1月份人民日报语料
1 语料处理
1.1 原始语料数据格式
语料中,句子已经被分词好,并且在人名后以“/”标注了“nr”表示是人名,其他非人名的分词没有进行标注

1.2 CRF++要求语料的格式
训练语料至少应具有两列,列间由空格或制表位间隔,且所有行(空行除外)必须具有相同的列数,句子间使用空行间隔

1.3 对原始数据进行处理
CRF++可以有多个特征,举例如下图

本次实验为了熟悉采用CRF++及进行中文人名标注,故将语料中的每一个单字作为特征,并进行BIEO标注,举例如下图

采用Python将原始数据读入,并将其格式转化为标准的两个列向量的格式,举例如下

代码如下
# coding:utf-8
import codecs
fin = codecs.open("data_to_final.txt", "r", "utf-8")
f = codecs.open("data_to_final_to_crf.txt", "a", "utf-8")
row = 1
while (True):
text = fin.readline()
if (text == ""):
break
tmp = text.split(" ")
n = len(tmp)
for i in range(0, n - 1):
if 'nr' in tmp[i]:
word = tmp[i].split('/')
tmpword = word[0]
wordlist = list(tmpword)
m = len(wordlist)
if m == 1:
f.write(wordlist[0] + ' S\n')
elif m == 2:
f.write(wordlist[0] + ' B\n')
f.write(wordlist[1] + ' E\n')
else:
f.write(wordlist[0] + ' B\n')
for k in range(1, m -1):
f.write(wordlist[k] + ' I\n')
f.write(wordlist[m-1] + ' E\n')
else:
tmpword = tmp[i]
wordlist = list(tmpword)
m = len(wordlist)
for k in range(0, m):
f.write(wordlist[k] + ' O\n')
f.write('\n')
print "当前执行到第", row, "行"
row += 1
f.close()
1.4 遇到的问题及解决办法
问题:由于在处理预料的时候是以空格来取词的,但是每句话的最后由于直接是换行符号(“\n”),缺少一个空格导致每句话的最后的一个词无法被读入而使数据缺失,举例如下


解决办法:再写一个小程序对最原始的语料进行加工,具体的就是在每一行的句尾加上一个空格。再将加工后的数据用于转换格式,解决问题
代码如下
# coding:utf-8
import codecs
fin = codecs.open("data_nr.txt", "r")
f = codecs.open("data_to_final.txt", "a")
row = 1
while (True):
text = fin.readline()
if (text == ""):
break
tmp = list(text)
tmp.insert(-1 ,' ')#每行后加一个空格
f.writelines(tmp)
print "当前执行到第", row, "行"
row += 1
f.close()
2 使用CRF++进行实验
将语料数据集分成两份(8:2的比例),将大的集合定义为训练数据集,小的集合定义为测试数据集合
2.1 构建模板
新建一个名为template的文件用于构建模板,由于本实验只采用了字为特征,所以创建的模板也很简单,如下图

2.2 进行学习
采用相应的命令进行学习
crf_learn template data_nr_train_to_crf.data model
经历了几分钟,模型就已经训练好了,如下图

2.3 进行测试
将事先准备好的测试语料用于CRF++,使用相应命令进行测试,将结果保存到result文件中
crf_test -m model data_nr_test_to_crf.data > result
得到的结果格式是在原有的两列后再增加一列,是通过训练的模型对测试数据中的文字进行的标注结果,举例如下

2.4 遇到的问题及解决办法
问题:在进行第一次学习的时候,出现程序中途停止的问题,如下
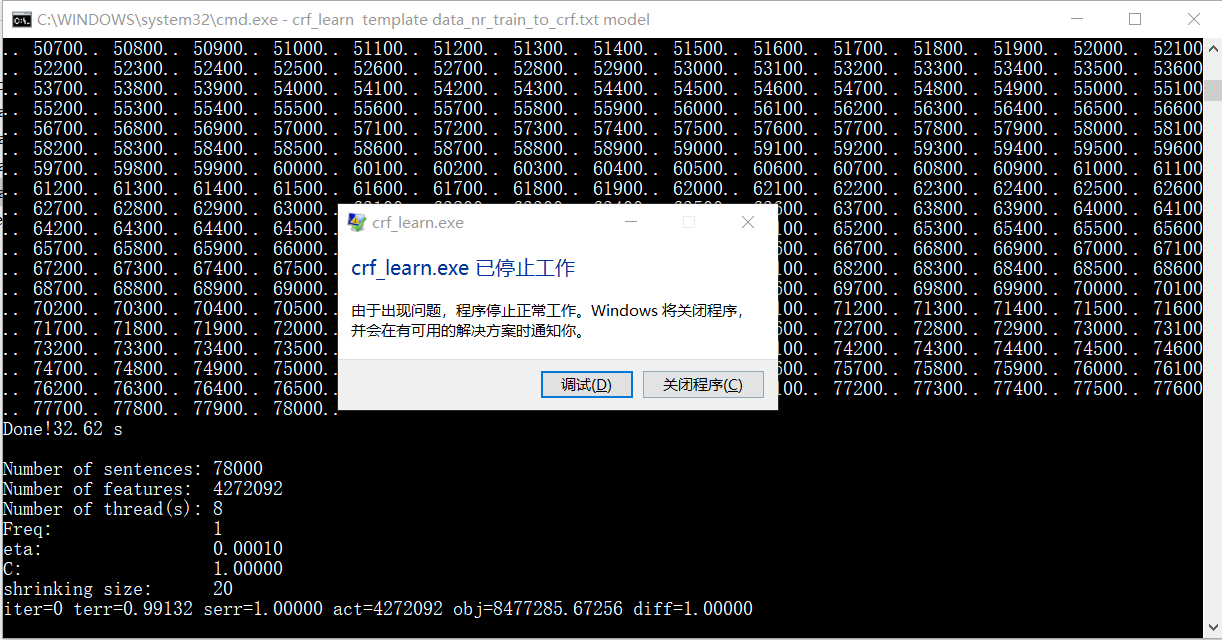
解决办法:通过查阅网络资源与进行小数据集合的实验发现导致此问题的原因应该就是,由于实验环境是在Windows的环境中进行的,数据集太大会导致程序终止。所以几次尝试后,将训练数据集减小为原来的3/4左右,再次进行学习,程序运行成功,解决问题。
3 评估
验证就是比较result文档的后两列数据,统计相同的标签个数或不同的个数,从而得到准确率、召回率、F1值。
3.1 采用conlleval.pl脚本文件进行评估
使用此文件的前提是要在机器上搭建perl环境,是在perl官方网站进行下载并安装。准备好之后,采用相关命令进行验证操作,并将结果写入evaluation中
perl conlleval.pl < result > evaluation
3.2 评估结果
打开evaluation文件,如图3-2所示,可以看到准确率为99.66%,精确率为95.12%,召回率为83.96%,F1值为89.19,导致这样的结果显然就是此次实验只用单字作为特征

3.3 遇到的问题及解决办法
问题:第一次进行评估的时候,程序运行报错,如下

解决办法:查阅相关资料,得知CRF++输出的测试结果中,相邻两行间是制表符(“\t”),而conlleval.pl要求相邻列间必须是空格,于是通过Ultraedit软件的替换功能将所有制表符替换为空格,如图3-4所示。保存文件后进行验证,解决问题。

4 总结
本次实验核心工具是CRF++,用于评估的工具采用了conlleval.pl,在语料预处理阶段采用Python编写的小程序
由于采用的单字特征,导致召回率稍低,后续可以考虑选取更多的特征(比如添加先验概率分布作为另一个特征等),来进行实验
Windows下CRF++进行中文人名识别的初次尝试的更多相关文章
- windows下git bash中文乱码解决办法
一.解决办法1:(直接上图) 1.在git bash下,右键 出现下图,选择options: 2.选择“Text” 3.将“Character set”设置为 UTF-8 转:windows下git ...
- [转]Git for windows 下vim解决中文乱码的有关问题
Git for windows 下vim解决中文乱码的问题 原文链接:Git for windows 下vim解决中文乱码的有关问题 1.右键打开Git bash: 2.cd ~ 3.vim .vim ...
- Windows下Git Bash中文乱码
文章转自:http://ideabean.iteye.com/blog/2007367 打开Git Bash 进入目录:$ cd /etc 1. 编辑 gitconfig 文件:$ vi gitcon ...
- Windows下的bat中文乱码问题
起初拿到一个bat文件,我在修改时看到编码是gb2312,我就直接将其转变为了utf8...但是在执行后的黑窗口出现中文乱码问题,最后网上获取帮助是修改编码为ANSI编码,确实不出现乱码了,ANSI是 ...
- 解决windows下FileZilla server中文乱码问题
最利用cuteftppro FTP做文件夹同步,发现中文的文件夹及文件名都出现了乱码问题, 一开始以为是cuteftppro的问题,谷哥度娘找了一堆的解决方案都没有解决乱码问题,真是头疼啊! 后来终于 ...
- 解决Windows下Tomcat控制台中文乱码
找到${CATALINA_HOME}/conf/logging.properties 添加语句:java.util.logging.ConsoleHandler.encoding = GBK 重启to ...
- VIM、GVIM在WINDOWS下中文乱码的终极解决方案
文章转自:http://www.liuhuadong.com/archives/68 vim.gvim在windows下中文乱码的终极解决方案在windows下vim的中文字体显示并不好,所以我们需要 ...
- vim、gvim 在 windows 下中文乱码的终极解决方案
vim.gvim 在 windows 下中文乱码的终极解决方案 vim ~/.vimrc 然后加入: " Gvim中文菜单乱码解决方案 " 设置文件编码格式 set encodin ...
- 基于分布式的短文本命题实体识别之----人名识别(python实现)
目前对中文分词精度影响最大的主要是两方面:未登录词的识别和歧义切分. 据统计:未登录词中中文姓人名在文本中一般只占2%左右,但这其中高达50%以上的人名会产生切分错误.在所有的分词错误中,与人名有关的 ...
随机推荐
- GROUP BY和 HAVING 及 统计函数 执行顺序等
[我理解:where是对最外层结果进行条件筛选,而having是对分组时分组中的数据进行 组内条件筛选,注意:只能进行筛选,不能进行统计或计算,所有统计或计算都要放在最外层的select 后面,无论是 ...
- 基于CMS的组件复用实践
目前前端项目大多基于Vue.React.Angular等框架来实现,这一类框架都有一个明显的特点:基于模块化以及组件化思维.所以,开发者在使用上述框架时,实际上是在写一个一个的组件,并且组件与组件之间 ...
- 初识python面向对象编程
初识python面向对象编程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.面向过程的程序设计思想 #!/usr/bin/env python #_*_coding:utf-8 ...
- eclipse启动tomcat内存溢出的解决方式
eclipse启动tomcat内存溢出的解决方式 ——IT唐伯虎 摘要:eclipse启动tomcat内存溢出的解决方式. 1.打开Run Configurations 2.在VM arguments ...
- 如何设置Ultraedit自动换行
有时候这会非常麻烦, 要让Ultraedit自动换行请按发下方法: 1. 点击菜单栏的"高级→配置",找到"编辑器→自动换行/制表符设置". 2. 然后,把&q ...
- Dubbo学习笔记10:Dubbo服务消费方启动流程源码分析
同理我们看下服务消费端启动流程时序图: 在<Dubbo整体架构分析>一文中,我们提到服务消费方需要使用ReferenceConfig API来消费服务,具体是调用代码(1)get()方法来 ...
- bzoj千题计划208:bzoj3174: [Tjoi2013]拯救小矮人
http://www.lydsy.com/JudgeOnline/problem.php?id=3174 按a+b从小到大排序,a+b小的在上面,先考虑让它逃出去 正确性不会证 感性理解一下,最后一个 ...
- 何凯文每日一句打卡||DAY6
- 【51Nod】1273 旅行计划 树上贪心
[题目]51Nod 1273 旅行计划 [题意]给定n个点的树和出发点k,要求每次选择一个目的地旅行后返回,使得路径上未访问过的点最多(相同取编号最小),旅行后路径上所有点视为访问过,求旅行方案.\( ...
- HTTP 错误 404.0 - Not Found
当网上的那些修改程序池的方法,无法解决此问题时,可以尝试修改以下的参数: 1.控制面板-->程序-->启用或关闭Windows功能--> Internet Information S ...