python进行爬虫
使用python进行网络爬虫
非结构画数据 转为 结构化数据。需要借助ETL(数据抽取,转换,存储)进行。
非结构化数据蕴含着丰富的价值。需要借助ETL进行转换成结构化数据,才能变成有价值的数据。比如下边的网页,信息是非结构化的,我们需要把他们转为结构化的数据,才会变成有价值的信息。

再例如搜索引擎,就是利用网络爬虫技术,去各个网站爬虫数据,然后做成索引,然后供我们查找。为什么今天的爬虫技术这么热呢?因为我们需要的数据好多都不在自己的数据库上,所以只能通过网络爬虫的技术去网络上爬取。
一 网络爬虫架构
一般网络爬虫架构如下:
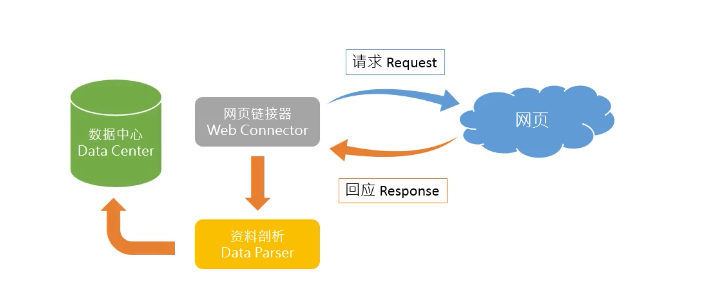
首先我们要有一个网页链接器,然后去网站的服务器进行请求,然后服务器给我们反应。我们可以又键鼠标,然后选择检查
然后选择Network选项,然后点击左上角的刷新按钮,发现左下角有67个请求。
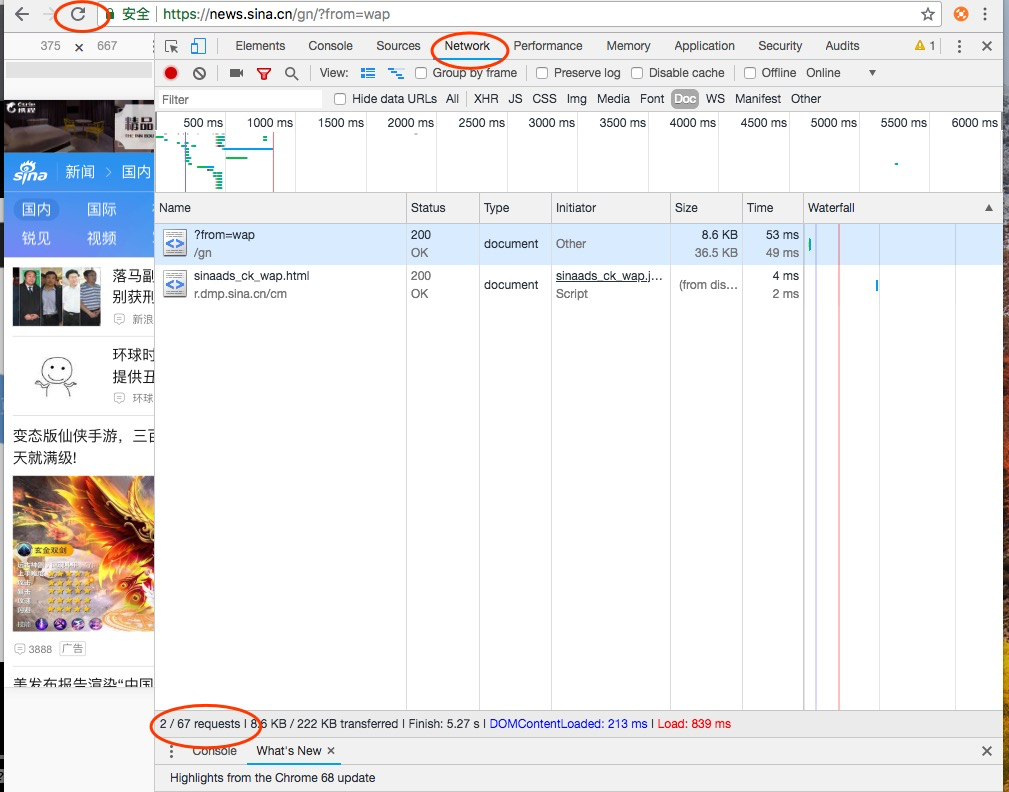
这些功能原本是给网页开发人员使用的,但network也可以给我们轻松使用,分析得到什么样的请求,得到了什么回应。
我们点击左上角的漏斗行的按钮,发现得到很多信息。
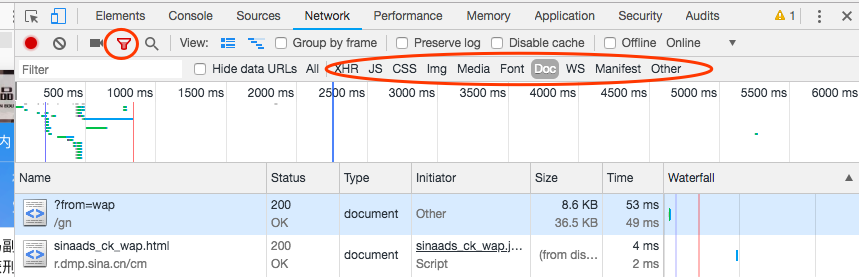
XHR:网站回应的内容
JS:和网页互动
CSS:网站的化妆品,呈现颜色等
Img:图片
Media:多媒体资料,如视频
Font:文字
Doc:网页资料
WS:是websocket
Manifest:宣告
Other:其他
我们的新闻内容一般就是放在了Doc里边了,点击Doc按钮,选择第一个页面的Response。
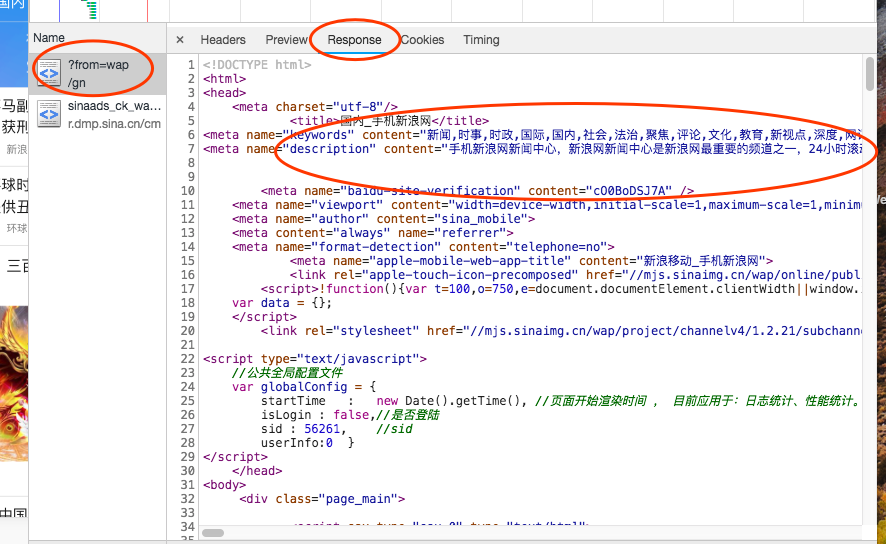
通过比较我们的网站内容和html,发现很像,那么这些资料很有可能就是我们需要的资料。
二 网络爬虫背后的秘密
如何观察一个网页,然后把有用的内容抓取下来?
首先我们可以用开发人员工具,右键选择检查,然后选择Doc,在选择第一个链接。
为什么可以在Doc里边找到呢?因为每一个网站都需要被搜索引擎爬虫到的需求,百分之九十的都会在Doc里边找到。如何判断这个链接就是我们需要抓取的内容呢?我们可以通过比较html内容和网页内容来判断。
我们选择Headers内容:
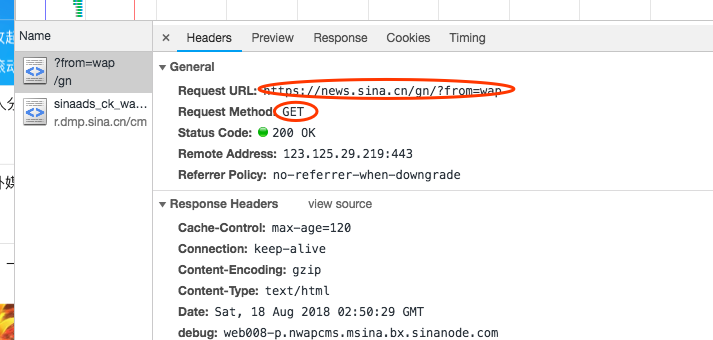
什么是get方法呢?
我们可以把get方法想象成一个明信片,我们通过get方法来访问服务器,当服务器收到我们的get之后,知道了我们的来意,就可以把相应的回应返回给我们。
通过pip安装套件:
pip insatll requests
pip install BeautifulSoup4
三 编写第一个网络爬虫
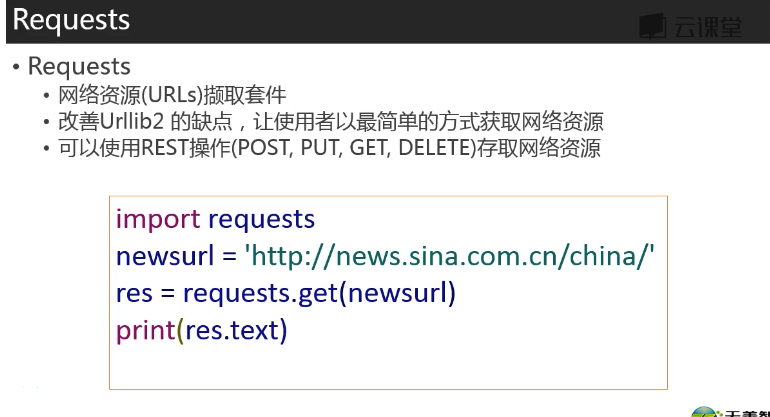
使用Request进行操作,(不实用Urllib2,因为它用起来非常的麻烦)。
回到新浪页面,既然可以用get得到这个页面,那么就用这个网址进行获取这个页面。

import requests
res=requests.get('https://news.sina.cn/gn/?from=wap')
print(res)
import requests
res=requests.get('https://news.sina.cn/gn/?from=wap')
print(res.text)

乱码是因为解码的问题,python误认为是其他的编码方式,
可以用encoding查看编码形式
import requests
res=requests.get('https://news.sina.cn/gn/?from=wap')
print(res.encoding)

修改代码如下:
import requests
res=requests.get('https://news.sina.cn/gn/?from=wap')
res.encoding='utf-8'
print(res.text)
此时不会再乱码了

但是现在的信息依然存在html中,如何把这些信息转成结构化信息呢?
我们可以使用DOM的方法,即Document Object Model,这是一组API,可以用来和网页元素进行互动,

我们可以看到这么一棵树,最上边是html,然后下边是body。
# import requests
#
# res=requests.get('https://news.sina.cn/gn/?from=wap')
# res.encoding='utf-8'
# print(res.text) from bs4 import BeautifulSoup html_samp=" \
<html> \
<body> \
<h1 id='title'>hello world</h1> \
<a href='#' class ='link'>this is link1</a> \
<a href='# link2' class='link'>this is link2</a> \
</body> \
</html>" soup=BeautifulSoup(html_samp)
print(soup.text)
运行得到:
输出了内容,但是有一个警告,因为我们没有指定一个剖析器,此时程序会给我们一个默认的。我们也可以指定一个剖析器,避免这个警告。
改写语句:
soup=BeautifulSoup(html_samp,'html.parser')
我们要抓取的内容也许是在特殊的标签之中,那么如何从特殊的标签和节点之中找到我们需要的数据呢?
我们可以用select方法,把含有特定标签的数据取出来

from bs4 import BeautifulSoup html_samp=" \
<html> \
<body> \
<h1 id='title'>hello world</h1> \
<a href='#' class ='link'>this is link1</a> \
<a href='# link2' class='link'>this is link2</a> \
</body> \
</html>" soup=BeautifulSoup(html_samp,'html.parser')
header=soup.select('h1')
#因为soup中可能会有很多的h1标签,所以上边的header是一个list,所以header[0]表示第一个h1标签
print(header[0])
输出为:

如果要输出其中的内容的画,可以用header[0].text得到其中的内容。
css是网页化妆品,当我们取用里边的词,当里边的id为title时,必须要加上‘#’,才可以存取,如果为class的话,必须要加上‘.’才可以存取。
from bs4 import BeautifulSoup html_samp=" \
<html> \
<body> \
<h1 id='title'>hello world</h1> \
<a href='#' class ='link'>this is link1</a> \
<a href='# link2' class='link'>this is link2</a> \
</body> \
</html>" soup=BeautifulSoup(html_samp,'html.parser')
#为title的要加上'#'
alink=soup.select('#title')
print(alink) #为class的,要加上'.'
for link in soup.select('.link'):
print(link)
最后,还有一个需求,在网页的链接上,我们会用a tag去联系到不同的网页,a tag里边有一个特殊的属性href,使用href才可以联系到其他的网页。

from bs4 import BeautifulSoup html_samp=" \
<html> \
<body> \
<h1 id='title'>hello world</h1> \
<a href='#' class ='link'>this is link1</a> \
<a href='# link2' class='link'>this is link2</a> \
</body> \
</html>" soup=BeautifulSoup(html_samp,'html.parser') alinks=soup.select('a')
for link in alinks:
print(link)
#之所以我们会用link['href']这样的写法,是因为其中的存取是使用了字典的形式
print(link['href'])

四 抓取新浪新闻内容
我们已经知道,1.使用requests.get取得页面内容;使用beautifulsoup4把内容剖析出来。
那我们应该怎么对新浪新闻的标题,时间,链接等取出来呢?
python进行爬虫的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
随机推荐
- How Computers Boot Up.计算机的引导过程
原文标题:How Computers Boot Up 原文地址:http://duartes.org/gustavo/blog/ [注:本人水平有限,只好挑一些国外高手的精彩文章翻译一下.一来自己复习 ...
- 使用sqoop从mysql导入数据到hive
目录 前言 一.使用的导入命令 二.遇到的问题及解决 1. 用文本字段进行分区的问题 2. Hadoop历史服务器Hadoop JobHistory没开启的问题 3. 连接元数据存储数据库报错 4 ...
- jQuery插件——下拉选择框
其实,之前也写过jQuery插件,今天写的是一个模拟select选择的下拉插件. 既然是jQuery插件,那么必然是依赖jQuery的了. 老规矩,直接上代码吧! ;(function () { $. ...
- 微信小程序笔记<六>模块化 —— module.exports
微信小程序中所有 js 文件作用域皆为独立的,每一个 js 文件即为一个模块.模块与模块之间的引用通过 module.exports 或 exports 对外暴露接口. 注意: exports 是 m ...
- [UnityShader基础]02.深度测试 & 深度写入
参考链接: https://blog.csdn.net/v_xchen_v/article/details/79380222 前面说到了渲染队列,对于两个不透明的物体A和B,它们处于同一个渲染队列中. ...
- mongodb对数据的增删改查
数据类型 下表为MongoDB中常用的几种数据类型: Object ID:文档ID String:字符串,最常用,必须是有效的UTF-8 Boolean:存储一个布尔值,true或false Inte ...
- 寻找cost函数最小值:梯度下降与最小二乘法
Editted by MarkDown 寻找cost函数最小值:梯度下降与最小二乘法 参考:最小二乘法小结--刘建平 背景: 目标函数 = Σ(观测值-理论值)2 观测值就是我们的多组样本,理论值就是 ...
- 字符串格式化+json解析
java String.formate("xxx%sxxx", "yyy") python "xxx%sxxx" % "yyy& ...
- PyQt5 qt desinger
https://jaist.dl.sourceforge.net/project/eric-ide/eric6/stable/18.08/eric6-18.08.zip pip --timeout 3 ...
- charles抓包的安装,使用说明以及常见问题解决(windows)
charles抓包的安装,使用说明以及常见问题解决(windows) https://blog.csdn.net/zhangxiang_1102/article/details/77855548