noip 提高组 2010
T1:机器翻译
题目背景
小晨的电脑上安装了一个机器翻译软件,他经常用这个软件来翻译英语文章。
题目描述
这个翻译软件的原理很简单,它只是从头到尾,依次将每个英文单词用对应的中文含义来替换。对于每个英文单词,软件会先在内存中查找这个单词的中文含义,如果内存中有,软件就会用它进行翻译;如果内存中没有,软件就会在外存中的词典内查找,查出单词的中文含义然后翻译,并将这个单词和译义放入内存,以备后续的查找和翻译。
假设内存中有MM个单元,每单元能存放一个单词和译义。每当软件将一个新单词存入内存前,如果当前内存中已存入的单词数不超过M-1M−1,软件会将新单词存入一个未使用的内存单元;若内存中已存入MM个单词,软件会清空最早进入内存的那个单词,腾出单元来,存放新单词。
假设一篇英语文章的长度为NN个单词。给定这篇待译文章,翻译软件需要去外存查找多少次词典?假设在翻译开始前,内存中没有任何单词。
输入输出格式
输入格式:
共22行。每行中两个数之间用一个空格隔开。
第一行为两个正整数M,NM,N,代表内存容量和文章的长度。
第二行为NN个非负整数,按照文章的顺序,每个数(大小不超过10001000)代表一个英文单词。文章中两个单词是同一个单词,当且仅当它们对应的非负整数相同。
输出格式:
一个整数,为软件需要查词典的次数。
输入输出样例
说明
每个测试点1s1s
对于10\%10%的数据有M=1,N≤5M=1,N≤5。
对于100\%100%的数据有0≤M≤100,0≤N≤10000≤M≤100,0≤N≤1000。
整个查字典过程如下:每行表示一个单词的翻译,冒号前为本次翻译后的内存状况:
空:内存初始状态为空。
1.11:查找单词1并调入内存。
2. 1 212:查找单词22并调入内存。
3. 1 212:在内存中找到单词11。
4. 1 2 5125:查找单词55并调入内存。
5. 2 5 4254:查找单词44并调入内存替代单词11。
6.2 5 4254:在内存中找到单词44。
7.5 4 1541:查找单词1并调入内存替代单词22。
共计查了55次词典。
题解:
其实不难看出是个队列题,
当队列未满时,若这个单词在内存中没有,便直接放在队尾,并且将这个单词打上存在标记,表示这个单词在内存中有;
当队列已满且仍有单词在内存中没有出现,则踢出队首,将队首的存在标记删除,并将这个单词放入队列,打上存在标记。
每重复以上操作ans++;
若单词存在,那自然是继续操作喽。
代码:
#include<cstdio>
#include<iostream>
#include<algorithm>
using namespace std;
int n,m,x,ans,l,r,a[],b[];
int main() {
cin>>m>>n;
for(int i=; i<=n; i++) {
scanf("%d",&x);
if(a[x]==) {
ans++,r++,b[r]=x,a[x]=;
if(r>m) l++,a[b[l]]=;
}
}
cout<<ans;
return ;
}
T2 乌龟棋


题解:
取或不取,很容易就想到是到DP题。
但会不会做,又是另一回事了。
看着看着题,突然想起来之前有做过一道题,和这道题很像。
之前考DP的时候考过,当时好像就我一个A了?
哎呀,切入主题。
开一个四维的数组,
ans[i][j][k][q]表示当1有i张,2有j张,3有k张,4有q张时的得分。
引入一个flag数组记录1~4的牌每种有几张。
用四重循环来遍历一下四种牌的所有可能。
当然题目中说了乌龟棋子自动获得起点格子的分数。
所以当1~4的牌都不用的时候,ans[0][0][0][0]为起点点数。
循环过程中定义一个get_power=i+j+k+q。
因为ans[i][j][k][q]就等于上一次尝试最大值加上这次到达的格子的点数。
于是ans[i][j][k][q]=max(ans[i][j][k][q],ans?+num[get_power])
慢慢你会发现,这个,,,不是个背包思想吗。
于是根据背包思想,你就可以很愉快地写代码了。
哦对了,要注意判断i,j,k,q不能等于0,因为我们在与上一层比较时难免会遇到i-1啊j-1什么的。,
最后输出ans[flag[1]][flag[2]][flag[3]][flag[4]]就好了
代码:
#include<iostream>
int ans[][][][],num[],flag[],n,m,x;
int main() {
std::cin>>n>>m;
std::cin>>num[];
ans[][][][]=num[];
for(int i=; i<=n; i++)
std::cin>>num[i];
for(int i=; i<=m; i++)
std::cin>>x,flag[x]++;
for(int i=; i<=flag[]; i++)
for(int j=; j<=flag[]; j++)
for(int k=; k<=flag[]; k++)
for(int q=; q<=flag[]; q++) {
int get_power=+i+j*+k*+q*;
if(i!=) ans[i][j][k][q]=std::max(ans[i][j][k][q],ans[i-][j][k][q]+num[get_power]);
if(j!=) ans[i][j][k][q]=std::max(ans[i][j][k][q],ans[i][j-][k][q]+num[get_power]);
if(k!=) ans[i][j][k][q]=std::max(ans[i][j][k][q],ans[i][j][k-][q]+num[get_power]);
if(q!=) ans[i][j][k][q]=std::max(ans[i][j][k][q],ans[i][j][k][q-]+num[get_power]);
}
std::cout<<ans[flag[]][flag[]][flag[]][flag[]];
return ;
}
T3 关押罪犯

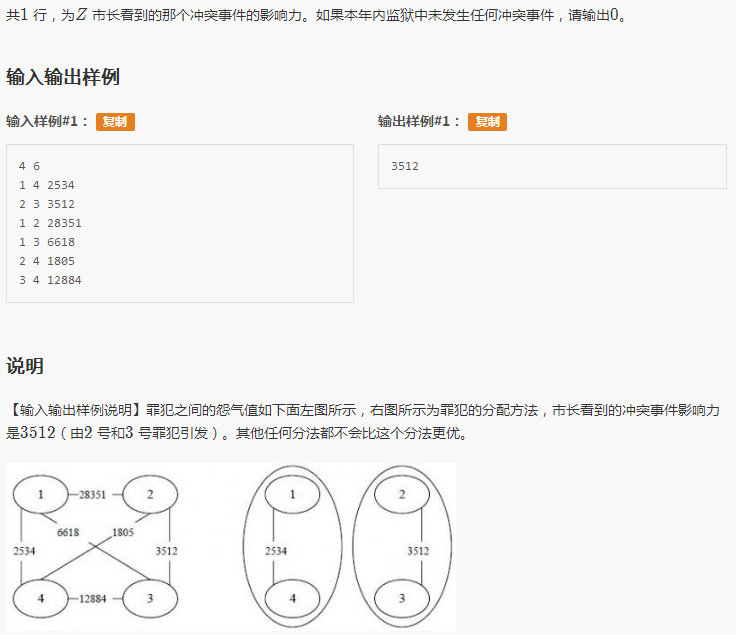

题解:
这里我用的并查集,出去学习的时候,老师们讲并查集时总会拿着个当例题。
于是在听过了几个老师巴拉巴拉地讲了好几遍后,埋头写这个题。
首先把所有冲突按照从大到小进行排序,然后进行操作。
检验,对于当前冲突的两个人是否能把他俩分开。
直到遇到两个人,他俩不可能被分开(如果分开了就跟前面冲突了),那他俩的冲突度就是最后的答案了。
利用并查集可以维护已知的一些人的关系。
代码:
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
struct node {
int x,y,z;
} f[];
int n,m,a[],b[];
bool cmp(node a,node b) {
return a.z>b.z;
}
int find(int x) {
if(a[x]==x) return x;
return a[x]=find(a[x]);
}
void ad(int x,int y) {
a[find(a[x])]=find(a[y]);
}
bool check(int x,int y) {
return find(x)==find(y)?:;
}
void add(int p,int mmp,int mml,int mmz) {
f[p].x=mmp,f[p].y=mml,f[p].z=mmz;
}
int main() {
scanf("%d%d",&n,&m);
for(int i=; i<=n; i++) a[i]=i;
for(int i=,fa,fb,fc; i<=m; i++)
scanf("%d%d%d",&fa,&fb,&fc),add(i,fa,fb,fc);
sort(f+,f+m+,cmp);
for(int i=; i<=m+; i++) {
if(check(f[i].x,f[i].y)) {
printf("%d",f[i].z);
break;
} else {
if(!b[f[i].x]) b[f[i].x]=f[i].y;
else ad(b[f[i].x],f[i].y);
if(!b[f[i].y]) b[f[i].y]=f[i].x;
else ad(b[f[i].y],f[i].x);
}
}
return ;
}
T4 引水入城

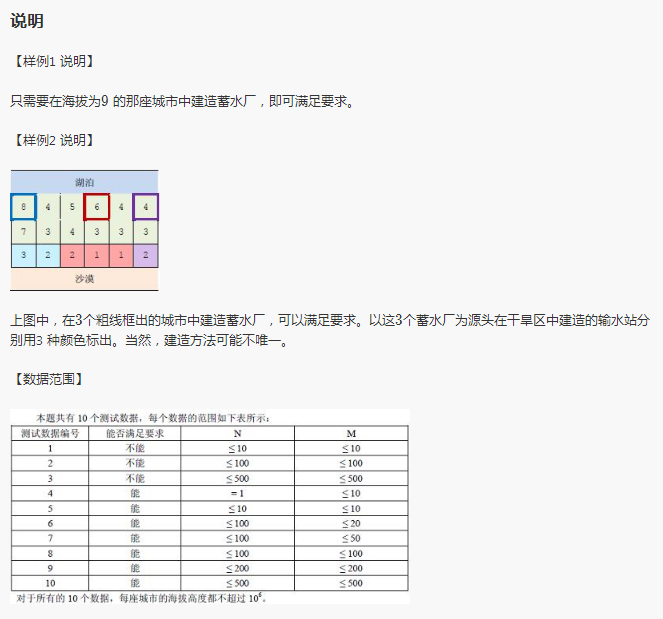
题解:
当初考DP时,这是第三题,得了八十分还是多少分来着。鬼知道我为什么会得一个这么鬼畜的分。
记忆化搜索,我最讨厌搜索了。
鬼知道我为什么对于搜索看到的第一眼就是不喜欢。
但是,迫不得已,毕竟,学习学习嘛。
首先,第一问。
很好做,直接dfs或bfs求一下最下面一排的店有没有不能被覆盖到的就行了。
接下来第二问。
对第一排每个点进行dfs或bfs,搜出每个点能够覆盖到的区间,再做线段覆盖就行了。
代码:
#include<iostream>
#include<cstring>
#include<cstdio>
using namespace std;
struct node{
int l,r;
}edge[];
int n,m,map[][],f[],cnt;
bool comp(node a,node b) {
return a.l<b.l;
}
bool vis[][],ans[];
void dfs(int x,int y,int tot) {
vis[x][y]=;
if(x==m) {
ans[y]=;
edge[tot].l=min(edge[tot].l,y);
edge[tot].r=max(edge[tot].r,y);
}
if(map[x+][y]<map[x][y]&&x!=m&&!vis[x+][y]) dfs(x+,y,tot);
if(map[x-][y]<map[x][y]&&x!=&&!vis[x-][y]) dfs(x-,y,tot);
if(map[x][y+]<map[x][y]&&y!=n&&!vis[x][y+]) dfs(x,y+,tot);
if(map[x][y-]<map[x][y]&&y!=&&!vis[x][y-]) dfs(x,y-,tot);
}
int main() {
cin>>m>>n;
for(int i=; i<=n; ++i) edge[i].l=f[i]=0x7fffffff;
for(int i=; i<=m; ++i)
for(int j=; j<=n; ++j)
cin>>map[i][j];
for(int i=; i<=n; ++i) {
memset(vis,,sizeof(vis));
dfs(,i,i);
}
for(int i=; i<=n; ++i)
if(!ans[i]) ++cnt;
if(cnt) printf("0\n%d\n",cnt);
else {
puts("");
for(int i=; i<=n; ++i)
for(int j=; j<=n; ++j)
if(i>=edge[j].l&&i<=edge[j].r)
f[i]=min(f[i],f[edge[j].l-]+);
printf("%d\n",f[n]);
}
return ;
}
一世安宁
noip 提高组 2010的更多相关文章
- noip提高组 2010 关押罪犯 (洛谷1525)
题目描述 S 城现有两座监狱,一共关押着N 名罪犯,编号分别为1~N.他们之间的关系自然也极不和谐.很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突.我们用"怨气值"( ...
- NOIP提高组2010 关押罪犯
题目描述 S 城现有两座监狱,一共关押着N 名罪犯,编号分别为1~N.他们之间的关系自然也极不和谐.很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突.我们用“怨气值”(一个正整数值)来表示 ...
- NOIP提高组2010 乌龟棋
小明过生日的时候,爸爸送给他一副乌龟棋当作礼物. 乌龟棋的棋盘是一行N个格子,每个格子上一个分数(非负整数).棋盘第1格是唯一的起点,第N格是终点,游戏要求玩家控制一个乌龟棋子从起点出发走到终点. 乌 ...
- 题解 【luogu P1541 NOIp提高组2010 乌龟棋】
题目链接 题解 题意: 有一些格子,每个格子有一定分数. 给你四种卡片,每次可以使用卡片来前进1或2或3或4个格子并拾取格子上的分数 每张卡片有数量限制.求最大分数. 分析 设\(dp[i]\)为第前 ...
- 题解【luoguP1525 NOIp提高组2010 关押罪犯】
题目链接 题解 算法: 一个经典的并查集 但是需要用一点贪心的思想 做法: 先将给的冲突们按冲突值从大到小进行排序(这很显然) 然后一个一个的遍历它们 如果发现其中的一个冲突里的两个人在同一个集合里, ...
- NOIP提高组2004 合并果子题解
NOIP提高组2004 合并果子题解 描述:在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆.多多决定把所有的果子合成一堆. 每一次合并,多多可以把两堆果子合并到一起,消 ...
- 计蒜客 NOIP 提高组模拟竞赛第一试 补记
计蒜客 NOIP 提高组模拟竞赛第一试 补记 A. 广场车神 题目大意: 一个\(n\times m(n,m\le2000)\)的网格,初始时位于左下角的\((1,1)\)处,终点在右上角的\((n, ...
- 1043 方格取数 2000 noip 提高组
1043 方格取数 2000 noip 提高组 题目描述 Description 设有N*N的方格图(N<=10,我们将其中的某些方格中填入正整数,而其他的方格中则放入数字0.如下图所示(见样 ...
- [NOIP提高组2018]货币系统
[TOC] 题目名称:货币系统 来源:2018年NOIP提高组 链接 博客链接 CSDN 洛谷博客 洛谷题解 题目链接 LibreOJ(2951) 洛谷(P5020) 大视野在线评测(1425) 题目 ...
随机推荐
- Python网络爬虫笔记(四):使用selenium获取动态加载的内容
(一) 说明 上一篇只能下载一页的数据,第2.3.4....100页的数据没法获取,在上一篇的基础上修改了下,使用selenium去获取所有页的href属性值. 使用selenium去模拟浏览器有点 ...
- gitlab查看项目ID/projectId
背景 最近有个CI打包平台,项目projectId弄错,导致拉取到错误仓库.笔者一直通过项目名称(project name)访问,首次接触project id,搜索一圈才找到快捷查看方法,记录于此. ...
- 在SQL Server中用好模糊查询指令LIKE (转载)
like在sql中的使用:在SQL Server中用好模糊查询指令LIKE:查询是SQL Server中重要的功能,而在查询中将Like用上,可以搜索到一些意想不到的结果和效果,like的神奇 一.一 ...
- 解决:Tomcat 局域网IP地址 访问不了
解决:Tomcat 局域网IP地址 访问不了 2014年10月17日 ⁄ 综合 ⁄ 共 1000字 ⁄ 字号 小 中 大 ⁄ 评论关闭 如果连最基本的localhost:8080都失败的话. 原因就一 ...
- md5sum 和 sha256sum用于 验证软件完整性
md5sum 和 sha256sum 都用来用来校验软件安装包的完整性,本次我们将讲解如何使用两个命令进行软件安装包的校验: sha 是什么? sha 为 安全散列算法(英语:Secur ...
- JRebel for Hybris ,Idea and Windows
参考: Jrebel官网参考地址:https://manuals.zeroturnaround.com/jrebel/standalone/hybris.html Wiki Hybris参考地址:ht ...
- SmartUpload相关类的说明
㈠ File类 这个类包装了一个上传文件的所有信息.通过它,可以得到上传文件的文件名.文件大小.扩展名.文件数据等信息. File类主要提供以下方法: 1.saveAs作用:将文件换名另存. 原型: ...
- python 下 安装openCV
安装openCV openCV是Intel 创建的计算机视觉库,用于计算机图像处理. 安装anaconda,在命令行中输入conda install cv2/opencv 报错汇总 网络连接问题 报错 ...
- AlloyDesigner 使用
前端开发视觉是很重要的一部分,所以视觉的还原度很重要,今天给大家介绍一个很好用的视觉精度调整插件 一.下载AlloyDesigner插件 下载插件 二.保存视觉稿为图片格式 1.psd 用ps直接保存 ...
- CSS3 新增的文本属性
一.CSS1&2中的文本属性(W3C标准) text-indent CSS1 检索或设置对象中的文本的缩进 letter-spacing CSS1 检索或设置对象中的文字之间的间隔 word- ...