爬虫实战2_有道翻译sign破解
目标url 有道翻译
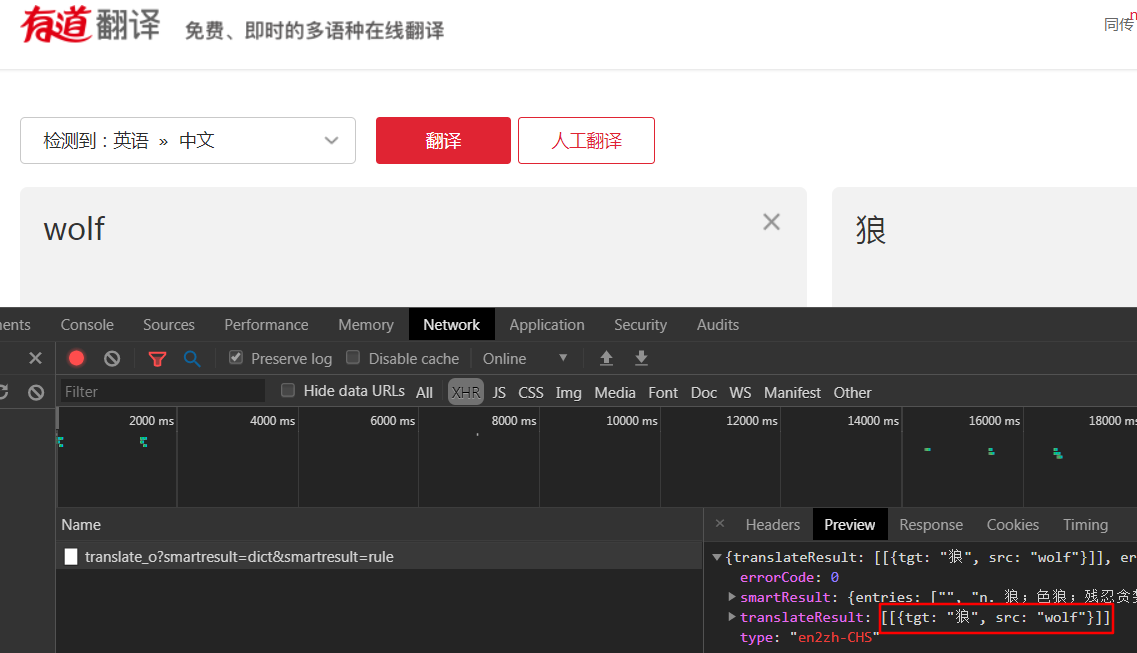
- 打开网站输入要翻译的内容,一一查找network发现数据返回json格式,红框就是我们的翻译结果
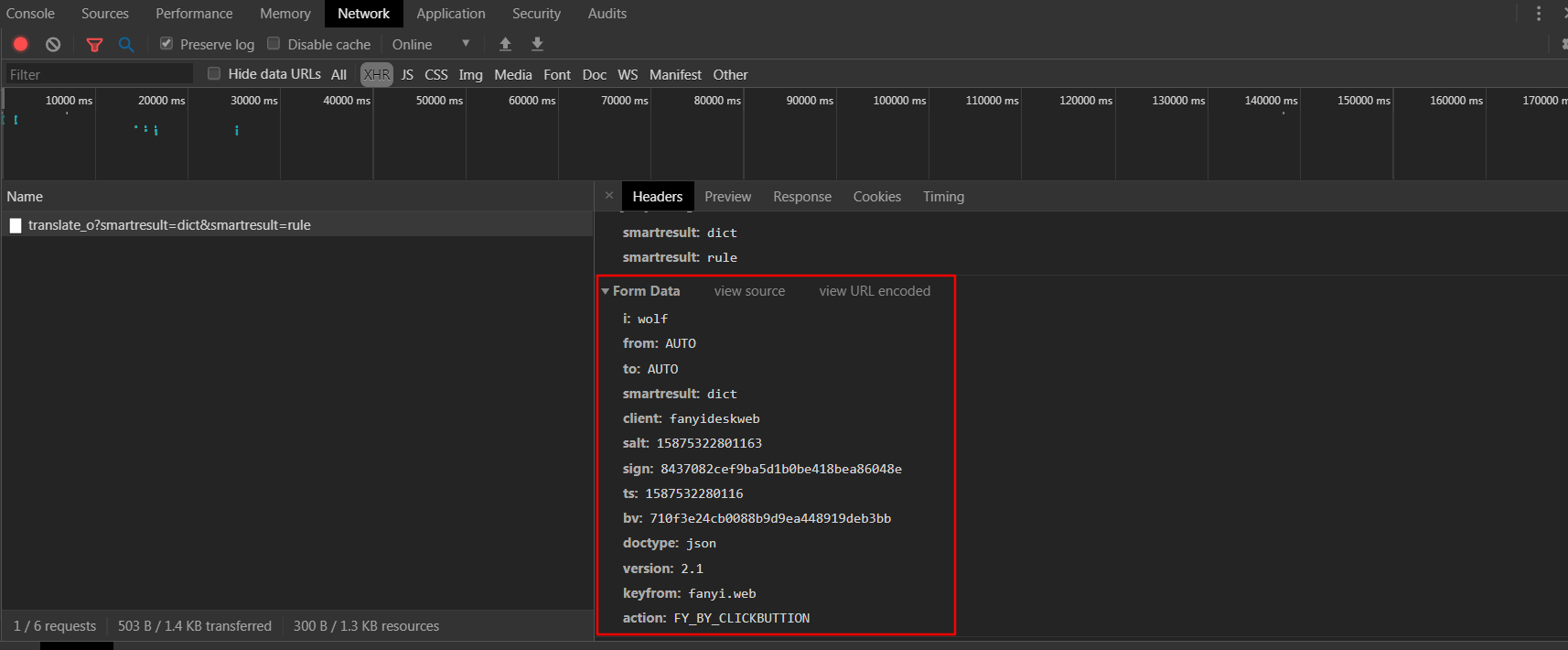
- 查看headers,发现返回结果的请求是post请求,且携带一大堆form_data,一一理下一表单数据
- i:要翻译的数据
- from、to:from to 表示从哪国语言翻译到哪国语言
- smartresult、doctype:返回结果的形式以字典形式
- client、keyfrom、action:区分客户端类型
- salt、sign、ts、bv:看起来不太友善,好像是反爬虫参数
- 观察ts参数为13整数字符串,大概率是当前时间戳取整
- salt比ts多出一位
- sign和bv都为32位字符串,可以推断为经过MD5加密的字符串

- 使用浏览器的search功能,发现sign藏在一个js文件中,搜索找到并点击
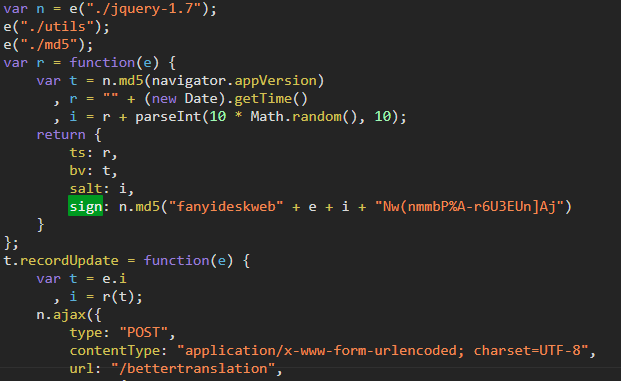
- 经过一番查找,发现这四位老铁是不是挺眼熟,没错,这个函数就是这四个参数的生成算法(js加密参数一般都是用客户端比如.py的参数参数生成算法和服务器端的参数生成算法比较,不是用参数直接比较,这点要注意)
既然已经找到,那我们就用python改写一个这段生成加密参数的js代码,我们把js代码复制到本地以方便改写Python代码
define("newweb/common/service", ["./utils", "./md5", "./jquery-1.7"], function(e, t) {
var n = e("./jquery-1.7");
e("./utils");
e("./md5");
var r = function(e) {
var t = n.md5(navigator.appVersion) # navigator.appVersion就是浏览器版本信息,User-Agent
, r = "" + (new Date).getTime() # 获取当前日期的整数字符串
, i = r + parseInt(10 * Math.random(), 10);
return {
ts: r,
bv: t,
salt: i,
sign: n.md5("fanyideskweb" + e + i + "Nw(nmmbP%A-r6U3EUn]Aj") # 这边的最后一个子串看起来像随机生成的(容易误导),可以在js代码里面打断点多试几遍发现是常量
}
};
def get_sign(self, key_word):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
# ts 为当前时间戳
ts = str(round(time()))
# salt 为ts拼接1-9之间的一个随机整数
salt = ts + str(randint(1 ,9))
# bv browser version 就是User-Agent进过md5加密的数据
bv = hashlib.md5(bytes(user_agent, encoding='utf-8')).hexdigest()
# sign 由四部分组成,起始和结尾的数据都是固定的,中间两个参数分别对应要翻译的对象和 salt
sign = hashlib.md5(bytes('fanyideskweb' + key_word + salt + 'Nw(nmmbP%A-r6U3EUn]Aj', encoding='utf-8')).hexdigest()
self.post_data['salt'] = salt
self.post_data['sign'] = sign
self.post_data['ts'] = ts
self.post_data['bv'] = bv
return self.post_data
- 接下来完事具备,我们就把我们的蜘蛛完善一下
#!/usr/bin/env python
# !@software: PyCharm
# !@coding:
# !@time: 2020/4/22 11:52
# !@author: xiaoma
import requests
from random import randint,sample
from time import time
import hashlib
class FanyiSpider(object):
def __init__(self, key_word):
self.key_word = key_word
self.base_url = 'http://fanyi.youdao.com/'
self.post_data = {
'i': self.key_word,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '',
'sign': '',
'ts': '',
'bv': '',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_CLICKBUTTION'
}
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'Referer': 'http://fanyi.youdao.com/'
}
self.session = requests.session()
def get_sign(self, key_word):
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
# ts 为当前时间戳
ts = str(round(time()))
# salt 为ts拼接1-9之间的一个随机整数
salt = ts + str(randint(1 ,9))
# bv browser version 就是User-Agent进过md5加密的数据
bv = hashlib.md5(bytes(user_agent, encoding='utf-8')).hexdigest()
# sign 由四部分组成,起始和结尾的数据都是固定的,中间两个参数分别对应要翻译的对象和 salt
sign = hashlib.md5(bytes('fanyideskweb' + key_word + salt + 'Nw(nmmbP%A-r6U3EUn]Aj', encoding='utf-8')).hexdigest()
self.post_data['salt'] = salt
self.post_data['sign'] = sign
self.post_data['ts'] = ts
self.post_data['bv'] = bv
return self.post_data
def run(self): # 主要实现逻辑
# 1. 发送get请求
get_res = self.session.get(self.base_url, headers=self.headers)
# 2. 获取加密参数
post_data = self.get_sign(self.key_word)
# print(post_data)
# 3. 发送post,获取响应
post_res = self.session.post(self.base_url+'translate_o', headers=self.headers, data=post_data) # 注意:翻译的base_url和get请求的base_url有不一样的地方,记得拼接
# 4. 解析数据
print(post_res.json().get('translateResult')[0][0]['tgt'])
if __name__ == '__main__':
key_word = input("请输入想要翻译的内容>>>").strip()
youdao = FanyiSpider(key_word)
youdao.run()
爬虫实战2_有道翻译sign破解的更多相关文章
- 爬虫破解js加密(一) 有道词典js加密参数 sign破解
在爬虫过程中,经常给服务器造成压力(比如耗尽CPU,内存,带宽等),为了减少不必要的访问(比如爬虫),网页开发者就发明了反爬虫技术. 常见的反爬虫技术有封ip,user_agent,字体库,js加密, ...
- python爬虫-有道翻译-js加密破解
有道翻译-js加密破解 这是本地爬取的网址:http://fanyi.youdao.com/ 一.分析请求 我们在页面中输入:水果,翻译后的英文就是:fruit.请求携带的参数有很多,先将参数数据保存 ...
- 爬虫新手学习2-爬虫进阶(urllib和urllib2 的区别、url转码、爬虫GET提交实例、批量爬取贴吧数据、fidder软件安装、有道翻译POST实例、豆瓣ajax数据获取)
1.urllib和urllib2区别实例 urllib和urllib2都是接受URL请求相关模块,但是提供了不同的功能,两个最显著的不同如下: urllib可以接受URL,不能创建设置headers的 ...
- python3爬虫:利用urllib与有道翻译获得翻译结果
在实现这一功能时遇到了一些困难,由于按照<零基础入门python>中的代码无法实现翻译,会爆出“您的请求来源非法,商业用途使用请关注有道翻译API官方网站“有道智云”: http://ai ...
- java实现有道翻译爬虫
我的博文地址 https://www.cnblogs.com/lingdurebing/p/11618902.html 使用的库 1.commons-codec 主要是为了加密,可以直接用java原生 ...
- (未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果
环境: 火狐浏览器 pycharm2017.3.3 python3.5 1.url不仅可以是一个字符串,例如:http://www.baidu.com.url也可以是一个Request对象,这就需要我 ...
- 免费翻译API破解(简易翻译工具)
思路:选取有道翻译,用fiddler抓取接口请求信息,提取相关请求参数,破解加密部分. 主要请求数据: i :翻译文本 ts:时间戳 salt:ts +随机数 sign:加密信息,经过抓取信息,发现 ...
- tornado框架学习及借用有道翻译api做自动翻译页面
趁着这几天有时间,就简单的学了一下tornado框架,简单做了个自动翻译的页面 仅为自己学习参考,不作其他用途 文件夹目录结构如下: . ├── server.py ├── static │ └─ ...
- Python制作有道翻译小工具
该工具主要是利用了爬虫,爬取web有道翻译的内容. 然后利用简易GUI来可视化结果. 首先我们进入有道词典的首页,并点击翻译结果的审查元素 之后request响应网页,并分析网页,定位到翻译结果. 使 ...
随机推荐
- 题解 CF1304E 【1-Trees and Queries】
前言 这场比赛,在最后 \(5\) 分钟,我想到了这道题的 \(Idea\),但是,没有打完,比赛就结束了. 正文 题目意思 这道题目的意思就是说,一棵树上每次给 \(x\) 和 \(y\) 节点连 ...
- 好记性-烂笔头:JDK8流操作
1):对象 List<User> 转 Map<String,Object> 案例如下: public class User { private Integer id; priv ...
- shell getopts 用法
http://www.cnblogs.com/xupeizhi/archive/2013/02/18/2915659.html http://blog.csdn.net/xluren/article/ ...
- mybatis入门四 解决字段名与实体类属性名不相同的冲突
一.创建测试需要使用的表和数据 CREATE TABLE orders( order_id INT PRIMARY KEY AUTO_INCREMENT, order_no VARCHAR(20), ...
- Ubuntu文件(文件夹)创建(删除)
创建 创建文件: touch a.txt创建文件夹: mkdir NewFolderName 删除 删除文件: rm a.txt删除文件夹: rmdir FolderName删除带有文件的文件夹: r ...
- Gold30Mins
- sql MariaDB 安装contos
安装和运行MySQL数据库(MariaDB) centos 平台 1.安装和运行 yum install mariadb mariadb-server - 安装 systemctl start mar ...
- F - 我们什么时候能见面? POJ - 2028
F - 我们什么时候能见面? POJ - 2028 ICPC委员会希望尽快召开会议,解决下一届比赛中的每一个小问题.然而,委员会的成员都忙于疯狂地开发(可能是无用的)程序,以至于很难安排他们的会议日程 ...
- 【Java技术系列】爱情36技之追美妹的技术
1. 在古老的非洲大陆上,有个原始人无意中抬头仰望星空,凝视的时间稍微长了一些,超过了外星人设置的阈值,立刻拉响了人类即将产生文明的警报.因为外星人认为,人类已经产生了对宇宙的好奇心,文明的产生,科技 ...
- CentOS 通过 expect 批量远程执行脚本和命令
我们有时可能会批量去操作服务器,比如批量在服务器上上传某个文件,安装软件,执行某个命令和脚本,重启服务,重启服务器等,如果人工去一台台操作的话会特别繁琐,并浪费人力. 这时我们可以使用expect,向 ...