滴滴数据驱动利器:AB实验之分组提效

桔妹导读:在各大互联网公司都提倡数据驱动的今天,AB实验是我们进行决策分析的一个重要利器。一次实验过程会包含多个环节,今天主要给大家分享滴滴实验平台在分组环节推出的一种提升分组均匀性的新方法。本文首先会介绍一下滴滴AB实验的相关情况,以及在实验分组环节中遇到的问题。然后介绍目前在实验对象分组方面的通用做法,以及我们对分组环节的改进。最后是新方法的效果介绍。
1. AB实验概述
互联网公司中,当用户规模达到一定的量级之后,数据驱动能够帮助公司更好的决策和发展。在滴滴各个团队中,我们经常会面临不同的产品设计方案的选择或者多个算法方案的决策,比如顶部导航栏的排序方案一二三,派单算法一二三等等。传统的解决方法通常是由该领域经验丰富的专家来决定,或者由团队成员讨论决定,有时候甚至是随机选择一个方案上线。虽然在某些情况下传统解决办法也是有效的,但是让AB实验后的数据说话,会让方案选择更加有信服力。
滴滴Apollo AB实验平台,支持了滴滴诸多业务的功能优化、策略优化以及运营活动,提供了在线实验以及离线实验的能力,并行实验数达到 6000+ / 周。在分组方法上提供随机分组以及时间片分组来应对不同的实验场景。效果分析方面,我们对基础指标、率指标、均值指标、留存指标等多种类型的指标提供了均值检验、VCM、Bootstrap等多种分析手段。
2. 分组的问题
一次完整的AB实验可以分为以下几步:

第一步:
设计实验方案,包括确定实验对象,划分实验组,确定实验提升目标等。
第二步:
进行人群分组,一般是一个空白组加一个或多个实验组
第三步:
将需要实验的策略,方案或者功能施加到各个组,收集数据
第四步:
对实验关心的指标进行分析观察
本文主要讨论其中第二步的实现。业界在进行实验对象分组的时候,最常用的是随机分组方式。这也是滴滴诸多实验中占比最大的分组方式。随机分组的做法可以实现为对实验对象的某个ID字段进行哈希后对100取模,根据结果值进入不同的桶,多个不同的组分别占有一定比例的桶。实验对象在哈希取模之后,会得到0 ~ 99的一个数,即为该实验对象落入的桶。这个桶所属的组就是该实验对象的组。

上述的这种分组方式称为CR(Complete Randomization)完全随机分组。进行一次CR,能将一批实验对象分成对应比例的组。但是由于完全随机的不确定性,分完组后,各个组的实验对象在某些指标特性上可能天然就分布不均。均值,标准差等差异较大。如果分组不均,则将会影响到第四步的实验效果分析的进行,可能遮盖或者夸大实验的效果。
待分流的个体具备一定的内在特点,比如就GMV这个指标来说,人群中会存在高GMV,中等GMV,低GMV等不同层次的用户。如下图所示,对于实验人群进行完全随机分流的方式,存在一定概率的不均匀,比如高GMV人群在某个组中的分配比例偏高,导致两个组的GMV相对差异较大。比如一次实验中,希望提升北京市的GMV 1%,在进行分组之后,实验组的人群GMV天然就比对照组的人群GMV高2%。这样实验进行的结果就变的无法比较。如果没有注意到实验前的组间不均情况,甚至可能验证出错误的结论。
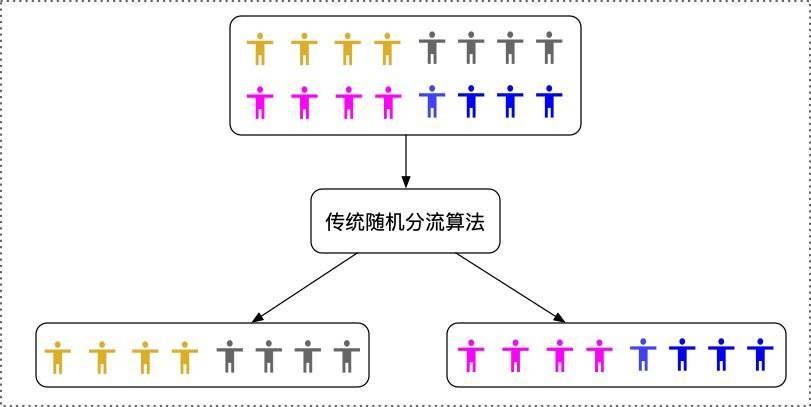
基于CR的风险较大的情况,一般会对CR进行简单的一步优化,即进行RR(Rerandomization)。RR是在每次跑CR之后,验证CR的分组结果组间的差异是否小于实验设定的阈值。当各组的观察指标小于阈值或者重新分组次数大于最大允许分组次数后,停止分组。

相比于CR,RR通过牺牲计算时间,能在一定概率上得到符合要求的分组。重分组次数与输入的实验对象样本大小相关。样本量越大,需要进行重分的次数一般较少。但是RR分组能得到符合要求的分组有一定的概率,且需要花更多的时间。所以,我们希望通过对分组算法的改进,在一次分组过程中分出观察指标均匀的分组结果,如下图所示。

3. 自适应分组
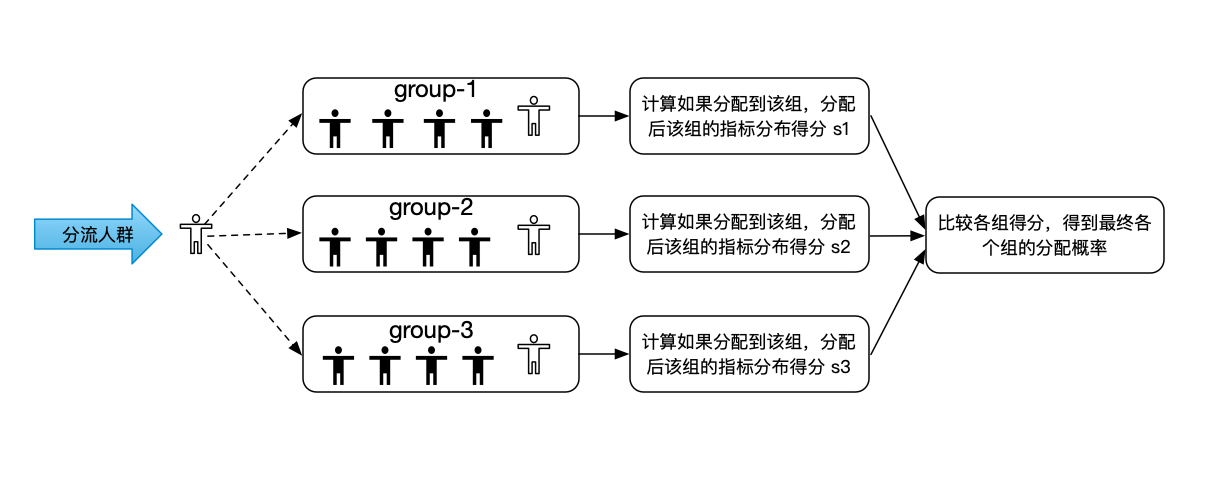
Apollo实验平台实现了滴滴AI LAB团队设计的Adaptive(自适应)分组算法。Adaptive分组方法可以在只分组一次的情况下,让选定的观测指标在分组后每组分布基本一致,可以极大的缩小相对误差。相比于传统的CR分组,Adaptive分组的算法更加复杂,在遍历人群进行分组的同时,每个组都需要记录目前为止已经分配的样本数,以及已经分配的样本在选定的观测指标上的分布情况。从分流人群中拿到下一个要分的对象后。会对实验的各个组进行计算,计算该对象如果分配到本组。本组的观测指标分布得分情况。然后综合各个组的预分配得分情况,得到最终各个组对于该实验对象的分配概率。
4. 系统设计
系统交互流程如下:
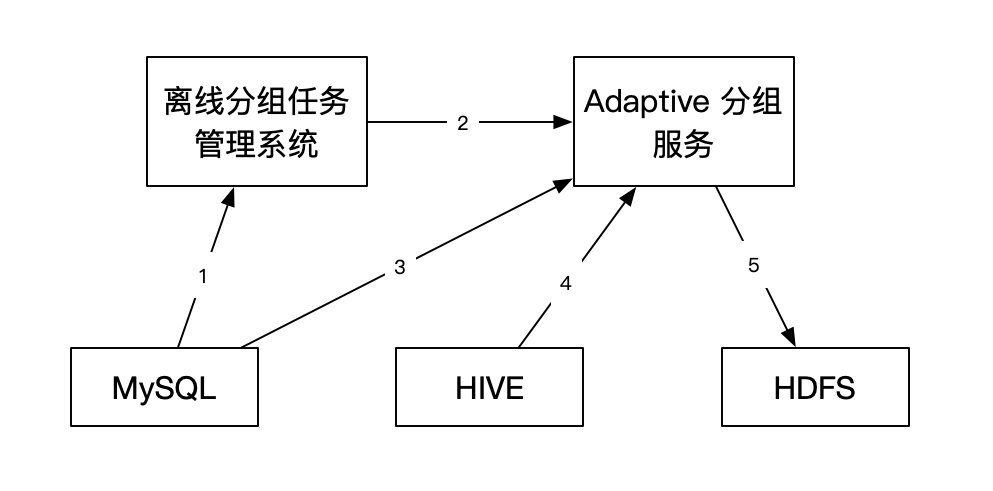
Adaptive分组方案的设计与实现复用了Apollo AB实验已有离线分组架构的能力。用户在实验平台通过API接口或者页面创建完Adaptive实验之后,实验平台会将分组需求发送到分组任务管理系统,生成分组任务存入数据库中。Adaptive分组执行分为以下几个步骤:
首先分组任务管理系统从数据库中获取需要进行分组的任务。然后根据任务类型调用不同的分组服务。Adaptive分组服务从数据库中获取实验对应的计算信息。根据实验计算信息中的观察指标,从HIVE中获取指标数据,根据人群信息的地址获取人群数据。执行完分组算法之后,将分组结果写入HDFS。
5. 算法介绍
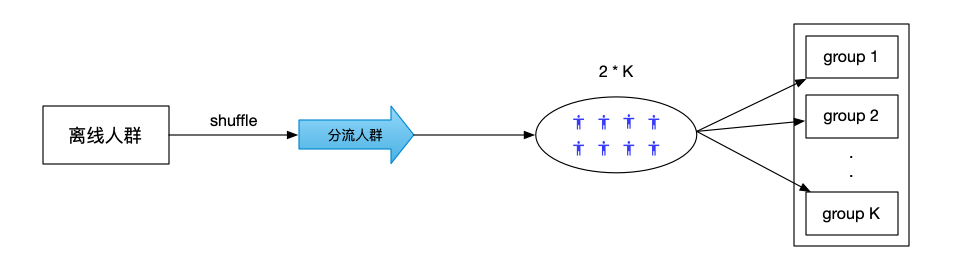
样本打乱&随机分配
将人群shuffle打乱之后,对于人群的前2 * K(K是组数)的人进行随机分组,保证每个组中至少有两个样本之后再开始进行Adaptive分组。
组参数初始化
根据实验的组以及每个组的人群比例计算出各个组的直接分配概率和间接分配概率。每个组上的直接分配概率和间接分配概率,分别表示了在直接分配以及间接分配情况下,选中该组后,样本分配到各个组的概率。根据已经分配的样本数据,初始化观测指标分布情况。
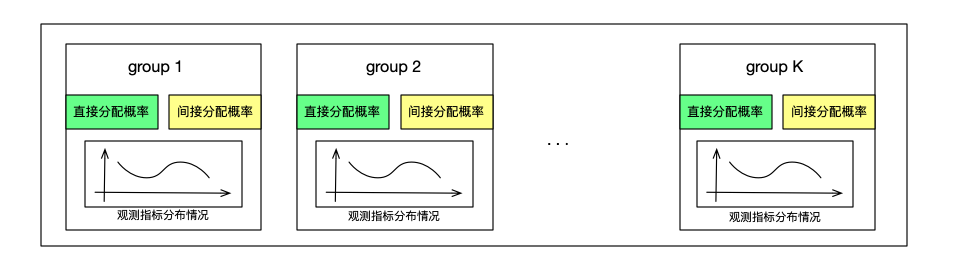
判断直接或间接分配
计算各组已分配样本数和组所占比例之间的关系,得到各个组的平衡系数BS,如果各个组的比例平衡系数相差较大,则进行直接分配。选用BS最小的组的直接分配概率来分配接下来的一个样本。通过直接分配来粗粒度的调整各组的分配比例。如果平衡系数相差不大,则走接下来的指标分布计算,来决定使用哪个组的间接分配概率。
计算各组预分配得分
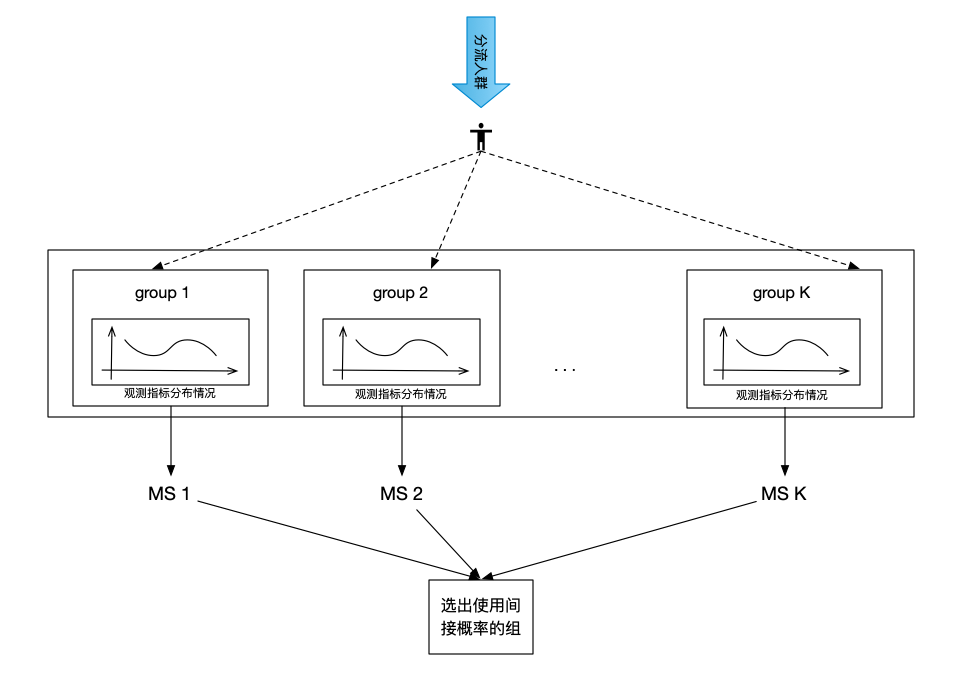
计算将要分配的一个样本,如果分配到组k后,组k的指标分布得分MS k,MS是根据ANOVA模型计算出来的每个组在各个观察指标上的均值,方差情况。通过比较各组的MS,选出向下偏离平均水平的组,以该组的间接分配概率作为各个组本样本的分配概率。
更新指标分布
通过上述的流程,无论使用直接分配还是间接分配,最终得到一个样本的实际分组后。用这个样本在各个观测指标上的数据更新分配到的组的指标分布数据。如此遍历,直到分配完所有样本。
6. 方案效果
使用Adaptive分组之后,1次分组得到符合要求的分组概率超过95%。
而不同算法间对于组间差异的实际优化情况不仅是与算法有关,也和进行分组的人群的大小,人群的分布特性相关。一般来说,人群大小越大,分布越均匀,使用随机分组的分组结果就会越好。组间差异会越小。下面进行测试的数据人群规模不大,所以直接随机分组的差异会显得比较大,并不代表所有情况。
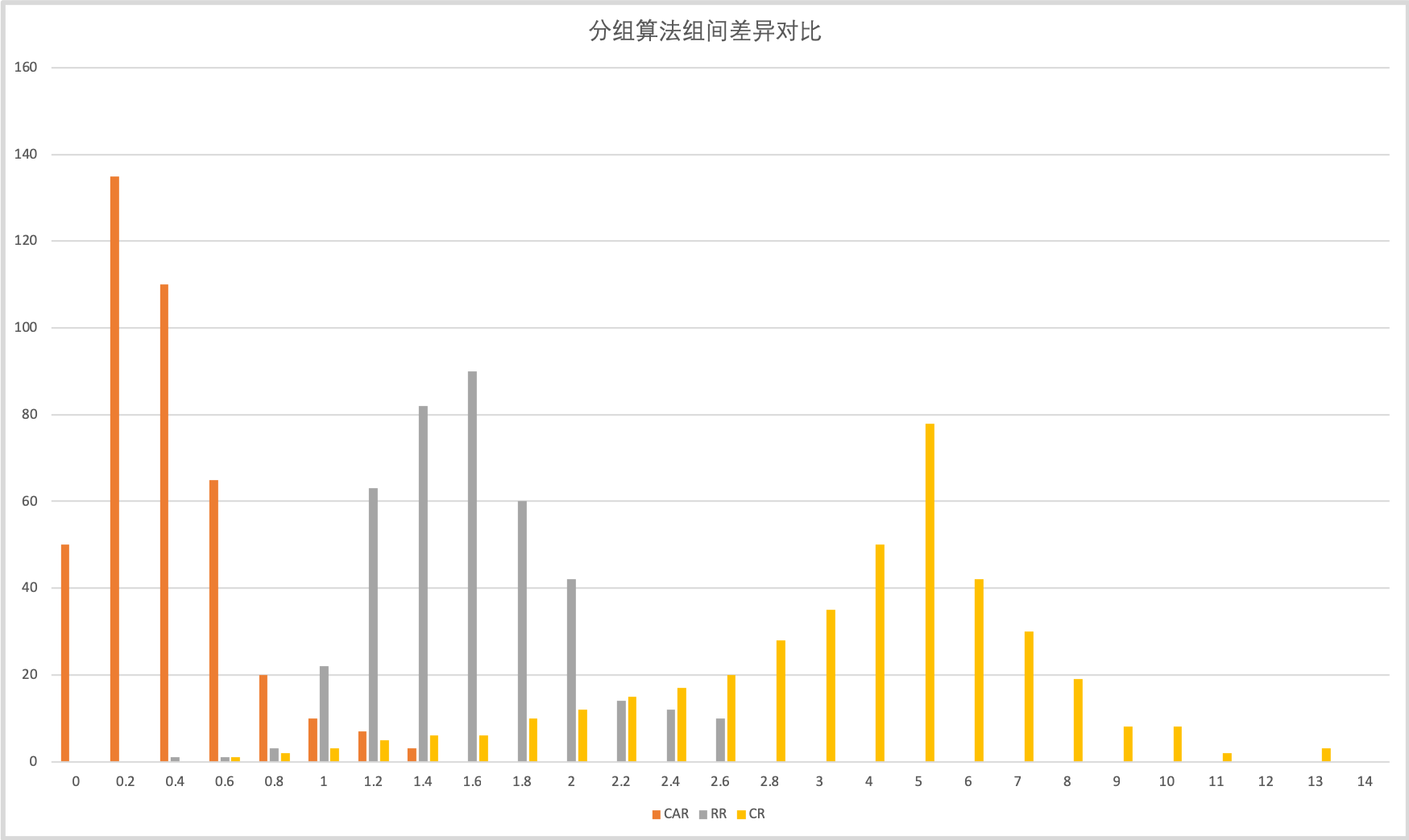
如上图所示,是对一个大小为10000的司机人群进行分组测试,并观察分组后的结果在7日GMV,7日在线时长,全兼职三个指标上的分布情况,并取每次分组结果中三个指标上差异最大百分比作为本次分组的差异。其中CR(Complete Randomization)是指一次随机分组,RR(每次是跑CR100次,取最优结果得到),CAR(Covariates Adaptive Randomization)是指一次Adaptive分组。图中的纵坐标是该区间的次数,横坐标是差异的百分比。
每种方式均执行了400次,统计指标的组间最大差异。CR方式的差异最大,最大差异可能达到14%以上。RR在CR的基础上,通过时间换准确性,较大的降低了组间差异,最大组间差异能在2.7%以下,但是这个差异依然在实验中不能被接受。CAR通过算法的优化,进一步降低了组间的差异。95%的情况下能把差异控制在0.8%以下。
7. 总结
通过提供Adaptive自适应分组能力,我们极大的提高了随机分组实验的数据精度。降低了无效实验的概率,缩短了实验周期。然而,对于已经通过CR方式完成的随机分流实验,用上述的这一套方案已经无法重新均衡。如何从这种已经完成的实验分组中抽取分布平衡的样本进行效果评估是一个更大的挑战,目前正在设计中,欢迎大家在本文留言,提宝贵意见,一起探讨实验相关问题。
团队介绍

滴滴工程效能团队肩负通过工程技术持续提升组织效能的使命,致力于建设世界一流的工程能力体系。为工程师提供极致的工作体验,打造高效能研发组织。
作者介绍

2018年北邮硕士毕业加入滴滴。在工程效能团队Apollo AB实验项目组,从事实验效果评估相关工作,负责实验科学性相关的研究。
欢迎关注滴滴技术公众号!

本文由博客群发一文多发等运营工具平台 OpenWrite 发布
滴滴数据驱动利器:AB实验之分组提效的更多相关文章
- 为什么在数据驱动的路上,AB 实验值得信赖?
在线AB实验成为当今互联网公司中必不可少的数据驱动的工具,很多公司把自己的应用来做一次AB实验作为数据驱动的试金石. 文 | 松宝 来自 字节跳动数据平台团队增长平台 在线AB实验成为当今互联网公司中 ...
- AB实验的高端玩法系列3 - AB组不随机?观测试验?Propensity Score
背景 都说随机是AB实验的核心,为什么随机这么重要呢?有人说因为随机所以AB组整体不存在差异,这样才能准确估计实验效果(ATE) \[ ATE = E(Y_t(1) - Y_c(0)) \] 那究竟随 ...
- AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!
背景 AB实验可谓是互联网公司进行产品迭代增加用户粘性的大杀器.但人们对AB实验的应用往往只停留在开实验算P值,然后let it go...let it go ... 让我们把AB实验的结果简单的拆解 ...
- Paper慢慢读 - AB实验人群定向 Learning Triggers for Heterogeneous Treatment Effects
这篇论文是在 Recursive Partitioning for Heterogeneous Casual Effects 的基础上加入了两个新元素: Trigger:对不同群体的treatment ...
- Paper慢慢读 - AB实验人群定向 Recursive Partitioning for Heterogeneous Casual Effects
这篇是treatment effect估计相关的论文系列第一篇所以会啰嗦一点多给出点背景. 论文 Athey, S., and Imbens, G. 2016. Recursive partition ...
- AB实验的高端玩法系列4- 实验渗透低?用户未被触达?CACE/LATE
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
- 哈工大 计算机网络 实验三 IPv4 分组收发实验&IPv4 分组转发实验
计算机网络实验代码与文件可见github:计算机网络实验整理 实验名称 IPv4 分组收发实验&IPv4 分组转发实验 实验目的: (注:实验报告模板中的各项内容仅供参考,可依照实际实验情况进 ...
- Paper慢慢读 - AB实验人群定向 Double Machine Learning
Hetergeneous Treatment Effect旨在量化实验对不同人群的差异影响,进而通过人群定向/数值策略的方式进行差异化实验,或者对实验进行调整.Double Machine Learn ...
- 阿里巴巴如何进行测试提效 | 阿里巴巴DevOps实践指南
编者按:本文源自阿里云云效团队出品的<阿里巴巴DevOps实践指南>,扫描上方二维码或前往:https://developer.aliyun.com/topic/devops,下载完整版电 ...
随机推荐
- 在终端输入npm run serve时出现npm ERR! code ELIFECYCLE npm ERR! errno 1 npm ERR! test_vue_0613@1.0.0 dev: 错误的解决方法
在vscode终端使用命令 npm run serve 的时候报错 错误原因在于由于文件 node_modules 太大,在项目上传时有些人会删掉 导致我们下载的项目中缺少这个文件 在尝试把自己项目的 ...
- HttpPoolUtils 连接池管理的GET POST请求
package com.nextjoy.projects.usercenter.util.http; import org.apache.http.Consts; import org.apache. ...
- STM32 Keil 软件仿真设置
设置 Dialog.DLL 分别为:DARMSTM.DLL和TARMSTM.DLL, Parameter 均为:-pSTM32F103RC,用于设置支持芯片的软硬件仿真
- 太高效了!玩了这么久的Linux,居然不知道这7个终端快捷键!
大家好,我是良许. 作为 Linux 用户,大家肯定在 Linux 终端下敲过无数的命令.有的命令很短,比如:ls .cd .pwd 之类,这种命令大家毫无压力.但是,有些命令就比较长了,比如: $ ...
- 容器技术之Docker基础入门
前文我们了解了下LXC的基础用法以及图形管理工具LXC WEB Panel的简单使用,有兴趣的朋友可以参考https://www.cnblogs.com/qiuhom-1874/p/12904188. ...
- BZOJ 1070 拆点 费用流
1070: [SCOI2007]修车 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 5860 Solved: 2487[Submit][Status] ...
- java——assert(断言)方法
包:org.junit.Assert; assertEqual(a,b,[msg='测试失败时打印的信息']): 断言a和b是否相等,相等则测试用例通过. assertNotEqual(a,b,[ms ...
- tp隐藏入口文件
[ Apache ] httpd.conf配置文件中加载了mod_rewrite.so模块 AllowOverride None 将None改为 All 把下面的内容保存为.htaccess文件放到应 ...
- ELK-日志管理平台
elk日志收集工具 1.日志在工作当中的重要性 1 分析日志的意义: 2 1.分析日志监控系统运行的状态 3 2.分析日志来定位程序的bug 4 3.分析日志监控网站访问流量 ...
- VSCode开发Vue-代码格式化最完美设置
Vue在VsCode上面的开发,代码格式话是个老大难问题了. 有很多文章介绍Prettier四个配置方法,以及如何启用.但是结果就是:一个一个配完,还是看着难受 现在尝试出一种最完美格式化方式,分享出 ...