hadoop之完全分布式集群配置(centos7)
一、基础环境
现在我们有两台虚拟机了,再克隆两台:

克隆好之后需要做三件事:1、更改主机名称 2、修改ip地址 3、将ip地址和对应的主机号加入到/etc/hosts文件中
1、永久修改主机名
hostnamectl set-hostname hadoop03 等等
2、修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
删除掉UUID,然后注意红色框中的

3、将ip地址和主机名加入到/etc/hosts中
vim /etc/hosts
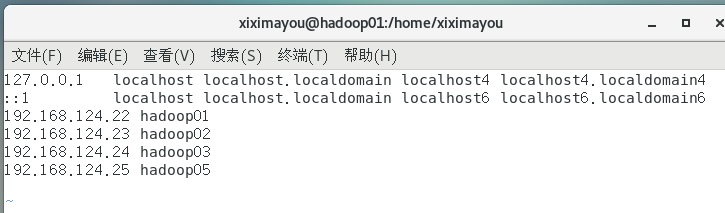
(图中最后应该是hadoop04)
同理对于hadoop04也这么做。hadoop02是我之前学习伪分布式时已经克隆配置好了的。也要在hadoop01和hadoop02中将这四个也添加上去。hadoop01是克隆源,里面的UUID不可删去。
二、集群配置
1、集群部署规划
| hadoop02 | hadoop03 | hadoop04 | |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
说明:NameNode和SecondaryNameNode要求不在一个节点上。ResourceManager不能和NameNode、SecondaryNameNode在同一个节点上。
2、修改hadoop02中的配置
在hadoop-2.9.2目录下:vim etc/hadoop/core-site.xml
<!--指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop02:9000</value>
</property>
<!--指定hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.9.2/data/tmp</value>
</property>
在vim etc/hadoop/hadoop-env.sh中配置JAVA_HOME路径
在vim etc/hadoop/hdfs-site.xml中
<configuration>
<!--备份的个数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--辅助节点的位置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop04:50090</value>
</property>
</configuration>
在vim etc/hadoop/yarn-env.sh中配置JAVA_HOME路径
在vim etc/hadoop/yarn-site.xml中配置
<configuration>
<!--Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定yarn的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
</configuration>
在vim etc/hadoop/mapred-env.sh中配置JAVA_HOME路径
vim etc/hadoop/mapred-site.xml中配置
<!--指定MR运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3、配置好hadoop02,利用之前博客中的集群分发脚本将配置文件传给hadoop03、hadoop04
xsync.sh /opt/module/hadoop-2.9.2/etc/hadoop/
然后去hadoop03和hadoop04中查看是否成功:
4、在hadoop02、hadoop03、hadoop04中删除掉之前运行的data和logs文件夹,在/opt/modul/hadoop-2.9.2/下
rm -rf data logs
5、集群节点启动
可使用jps指令查看节点是否启动。
(1)在hadoop02中:
首先格式化namenode:bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
(2) 在hadoop03中:
sbin/hadoop-daemon.sh start datanode
(3)在hadoop04中:
sbin/hadoop-daemon.sh start datanode
(4)关闭hadoop02中的防火墙
三、查看
在windows中输入http://192.168.124.23:50070/,若出现以下界面:

四、ssh无密码登录
问题:我们都是一个个去别的虚拟机启动节点,当节点很多时,我们要一个个去输入?
事实上,在当前虚拟机中终端中输入:ssh 主机名就可以登录到其他虚拟机
比如,当前的是hadoop02,那么输入ssh hadoop03,就可以登录到hadoop03,只不过每次切换的时候都需要输入密码。为了避免麻烦,可以部署免密登录,只需要输入一次密码,之后再次登录就不需要密码了。那么如何进行操作呢?
免密登录原理:

先来到hadoop02: 输入ls -al查看隐藏的文件,有一个.ssh。cd .ssh

里面有你访问过的主机名称。
生成相应的密钥:ssh-keygen -t rsa
然后输入三次回车。
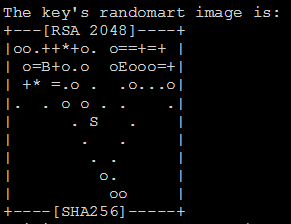

id_rsa就是私钥,id_rsa.pub就是公钥
将id_rsa.pub中的内容拷贝到hadoop03和hadoop04中:
在hadoop02的.ssh目录下输入:
ssh-copy-id hadoop03
ssh-copy-id hadoop04
然后我们再输入ssh hadoop03
发现就不需要再输入密码了,并且在.ssh目录下会生成一个authorized_keys:里面存放的就是hadoop02的公钥

同时也需要在hadoop02中的.ssh目录下:
ssh-copy-id hadoop02,
也要将root用户配置ssh免密登录:su切换到root,然后执行以上操作
同样对hadoop03和hadoop04重复上述的操作 。
五、群起集群
1、配置slaves
在hadoop02中
vim /opt/module/hadoop-2.9.2/etc/hadoop/slaves
在该文件中加入以下内容(将原本的localhost删除掉):主要是datanode,hadoop02、hadoop03、hadoop04上面都有
hadoop02
hadoop03
hadoop04
注意末尾不能有空格、回车。
然后使用集群分发脚本将其分发给hadoop03、hadoop04
在/opt/module/hadoop-2.9.2/etc/hadoop目录下输入:xsync.sh slaves
接下来将之前启动的那些节点都给停止掉:
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
然后在hadoop02中的/opt/module/hadoop-2.9.2目录下输入:sbin/start-dfs.sh

诸葛检查一下吧,首先是hadoop02:

hadoop03:

hadoop04:

说明是成功的,不容易啊。
六、启动yarn
这里注意,我们要在hadoop03中启动。即如果NameNode和ResourceManager不在同一台机器上,要在ResourceManager机器上启动yarn
输入:sbin/start-yarn.sh

可能会报权限不够问题。
那就改权限吧:需要注意看清前面是哪个服务器有权限问题
sudo chmod 777 /tmp/yarn-xiximayou-resourcemanager.pid
sudo chmod 777 /tmp/yarn-xiximayou-nodemanager.pid
之后再执行:

查看一下:
hadoop03:
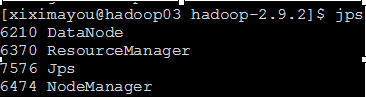
hadoop02:
hadoop04:

跟预期的对照一下:

七、进行测试
记得将hadoop03和hadoop04的防火墙也给关闭掉
1、上传一个文件到集群
在hadoop02中的hadoop-2.9.2目录下:
先上传一个小文件:
bin/hdfs dfs -put wcinput/wc.input /
再上传一个大文件:
bin/hdfs dfs -put /opt/software/Market.zip /
然后我们去查看
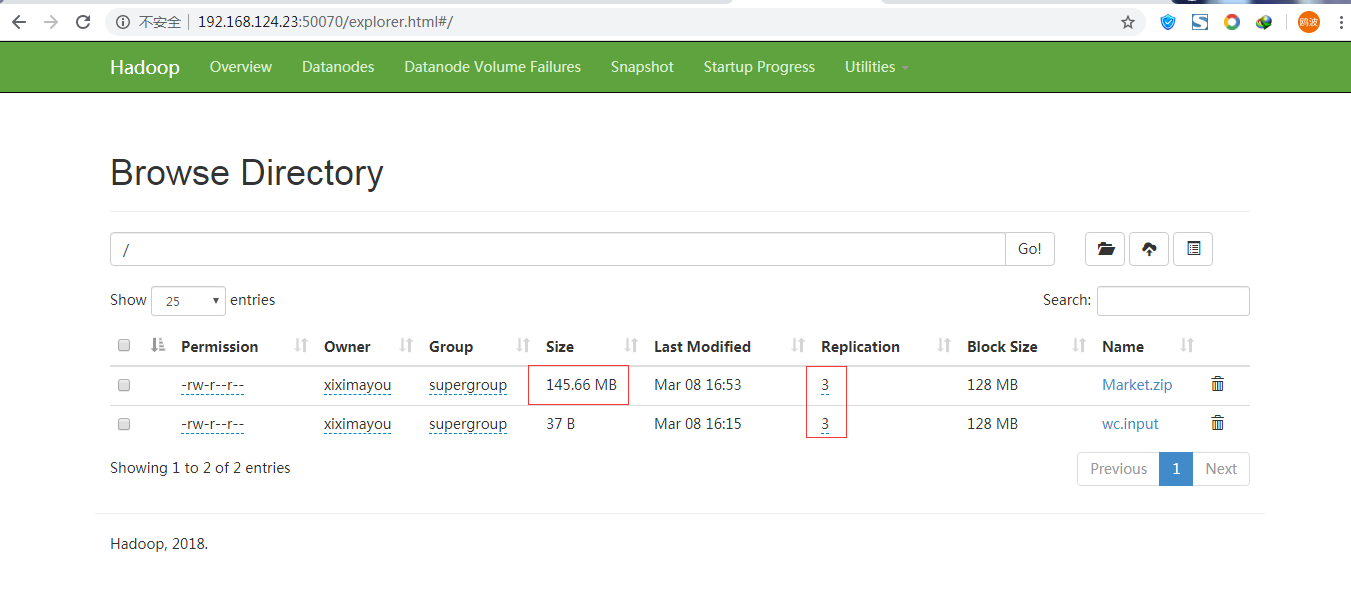
点开Market.zip
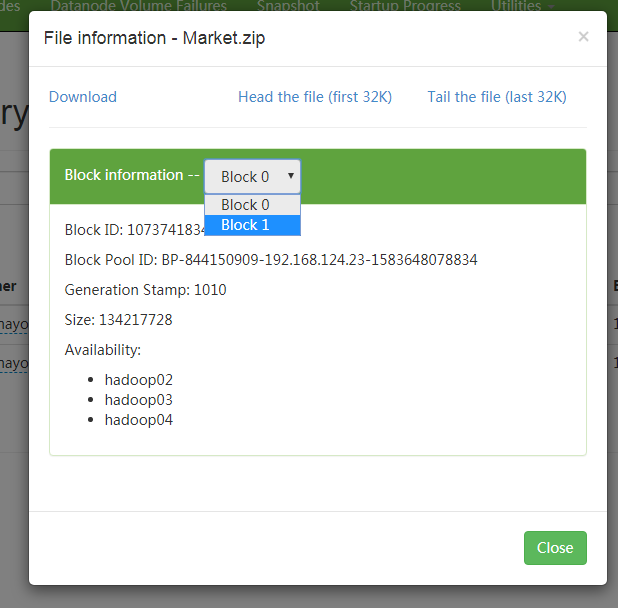
大文件(超过128M)分成了两块 ,同时在hadoop02、03、04上都有一份备份。
八、集群停止
sbin/stop-yarn.sh
sbin/stop-dfs.sh
hadoop之完全分布式集群配置(centos7)的更多相关文章
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 1.如何在虚拟机ubuntu上安装hadoop多节点分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- Hadoop(25)-高可用集群配置,HDFS-HA和YARN-HA
一. HA概述 1. 所谓HA(High Available),即高可用(7*24小时不中断服务). 2. 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA ...
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- Linux下Apache与Tomcat的完全分布式集群配置(负载均衡)
最近公司要给客户提供一套集群方案,项目组采用了Apache和Tomcat的集群配置,用于实现负载均衡的实现. 由于以前没有接触过Apache,因此有些手生,另外在网上搜寻了很多有关这方面的集群文章,但 ...
- apache + tomcat 负载均衡分布式集群配置
Tomcat集群配置学习篇-----分布式应用 现目前基于javaWeb开发的应用系统已经比比皆是,尤其是电子商务网站,要想网站发展壮大,那么必然就得能够承受住庞大的网站访问量:大家知道如果服务器访问 ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置HA配置
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置及HA配置(待)
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
随机推荐
- curl查看请求你响应时间
[root@localhost ~]# curl -o /dev/null -s -w time_namelookup:%{time_namelookup}"\n"time_con ...
- BZOJ3566 [SHOI2014]概率充电器 (树形DP&概率DP)
3566: [SHOI2014]概率充电器 Description 著名的电子产品品牌 SHOI 刚刚发布了引领世界潮流的下一代电子产品——概率充电器:“采用全新纳米级加工技术,实现元件与导线能否通电 ...
- markdown常见用法
命令 生成目录 [TOC] 插入标题 # 一级标题## 二级标题### 三级标题#### 四级标题##### 五级标题###### 六季标题 插入shell 开头:```shell 结尾 ...
- 隐藏windows7/8“卸载或更改程序”里的软件
隐藏windows7/8“卸载或更改程序”里的软件 通过修改注册表即可隐藏电脑中已安装的软件,这个方法会造成卸载列表无法加载已安装的软件,请谨慎操作!提示:删除注册表后windows自带的卸载程序.其 ...
- <JZOJ5937&luogu3944>斩杀计划&肮脏的牧师
第一次写桶排相关题.... #include<cstdio> #include<iostream> #define rint register int template < ...
- Ionic3学习笔记(十五)自定义 tab icon
本文为原创文章,转载请标明出处 美工做了一套 icon,自然是要用的.将 icon copy 到 assets 文件夹下. 例如 .icon-ios-home-custom 为 iOS icon 选中 ...
- Ubuntu上搭建GPU服务器
1.安装显卡驱动 2.安装CUDA 3.安装cuDNN 下载: 根据显卡类型以及操作系统,选定CUDA版本和语言设置,下载对应的显卡驱动. 驱动下载地址 安装 $ sudo ./NVIDIA-Linu ...
- python socket粘包及实例
1.在linux中经常出现粘包的出现(因为两个send近靠着,造成接受到的数据是在一起的.)解决方法: 在服务端两send的中间中再添加一个recv(),客户端添加一个send(),服务端收到信息确认 ...
- http://yuedu.baidu.com/ebook/36edd3d7ba1aa8114531d911
本书概述: 全面深入自动化测试技术,包括接口自动化测试.app自动化测试.性能自动化测试技术:实践,理论结合,方案,环境,代码 java语言,python语言,自动化测试开发 ...
- JDK_Packages_java_utils
utils包需要关注的主要有 集合框架.并发包.函数式编程.观察者模式@see PropertyChangeSupport java.util(集合框架) Contains the collect ...