Flink Task 并行度
并行的数据流
Flink程序由多个任务(转换/运算符,数据源和接收器)组成,Flink中的程序本质上是并行和分布式的。
在执行期间,流具有一个或多个流分区,并且每个operator具有一个或多个operator*子任务*。
operator子任务彼此独立,并且可以在不同的线程中执行,这些线程又可能在不同的机器或容器上执行。
operator子任务的数量是该特定operator的并行度。
流的并行度始终是其生成operator的并行度。
同一程序的不同operator可能具有不同的并行级别。
示意图:
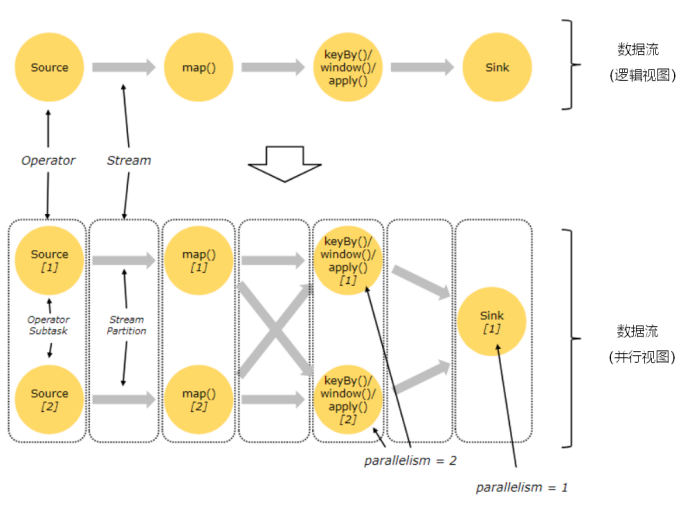
流可以以一对一(或重新分配)模式或以重新分发模式在两个运营商之间传输数据:
- 一对一流
- 如上图中的Source和map运算符之间
- 保留元素的分区和排序
- 这意味着map运算符的subtask [1] 将看到与Source运算符的subtask [1]生成的顺序相同的元素
- 重新分配流
- 在上面的map和keyBy / window之间,以及 keyBy / window和Sink之间重新分配流
- 每个运算符子任务将数据发送到不同的目标子任务, 具体取决于所选的转换。
- 图中是根据 keyby算子进行数据的重新分布。
- 一对一流
任务并行度设置
算子级别
可以通过调用其setParallelism()方法来定义单个运算符,数据源或数据接收器的并行度。
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取数据源,并进行转换操作
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("ronnie01", 9999)
.flatMap(new Splitter())
.keyBy(0)
//每5秒触发一批计算
.timeWindow(Time.seconds(5))
// 设置并行度
.sum(1).setParallelism(3);
执行环境级别
执行环境级别的并行度是本次任务中所有的操作符,数据源和数据接收器的并行度。
可以通过显式的配置运算符并行度来覆盖执行环境并行度。
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(3);
客户端级别
- 在向Flink提交作业时,可以在客户端设置并行度,通过使用指定的parallelism参数-p。
- 例如:
- ./bin/flink run -p 10 ../examples/WordCount-java.jar
系统级别
- 通过设置flink_home/conf/flink-conf.yaml 配置文件中的parallelism.default配置项来定义默认并行度。
Flink Task 并行度的更多相关文章
- Flink task之间的数据交换
Flink中的数据交换是围绕着下面的原则设计的: 1.数据交换的控制流(即,为了启动交换而传递的消息)是由接收者发起的,就像原始的MapReduce一样. 2.用于数据交换的数据流,即通过电缆的实际数 ...
- flink solt,并行度
转自:https://www.jianshu.com/p/3598f23031e6 简介 Flink运行时主要角色有两个:JobManager和TaskManager,无论是standalone集群, ...
- spark内核篇-task数与并行度
每一个 spark job 根据 shuffle 划分 stage,每个 stage 形成一个或者多个 taskSet,了解了每个 stage 需要运行多少个 task,有助于我们优化 spark 运 ...
- Flink并行度
并行执行 本节介绍如何在Flink中配置程序的并行执行.FLink程序由多个任务(转换/操作符.数据源和sinks)组成.任务被分成多个并行实例来执行,每个并行实例处理任务的输入数据的子集.任务的并行 ...
- 追源索骥:透过源码看懂Flink核心框架的执行流程
li,ol.inline>li{display:inline-block;padding-right:5px;padding-left:5px}dl{margin-bottom:20px}dt, ...
- Flink 靠什么征服饿了么工程师?
Flink 靠什么征服饿了么工程师? 2018-08-13 易伟平 阿里妹导读:本文将为大家展示饿了么大数据平台在实时计算方面所做的工作,以及计算引擎的演变之路,你可以借此了解Storm.Spa ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-split & select(拆分流)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink on YARN时,如何确定TaskManager数
转自: https://www.jianshu.com/p/5b670d524fa5 答案写在最前面:Job的最大并行度除以每个TaskManager分配的任务槽数. 问题 在Flink 1.5 Re ...
随机推荐
- 解决请求中的post、get乱码问题以及响应的乱码问题
post: get: response:
- JavaScript内置对象Array、String 的方法
Array push() //将一个或多个数据加入到数组的末端,并返回新的数组长度. pop() //取出数组中的最后一项,修改length属性,并返回被删除的数据 shift() //取出数组中的第 ...
- pwn之偏移量offset
0x7fffffffdd00: 0x4141414141414141 0x4141414141414141 0x7fffffffdd10: 0x4141414141414141 0x414141414 ...
- English-Names
English-Names 1. 西方姓名的组成 2. 职业姓氏 3. 更多相关链接 中国的姓名,姓氏在前,名子在后.传统也有中间字(世代字).名子非常多.所谓百家姓,姓氏数量有限,约500个左右. ...
- sql语句中,传入的参数带单引号的问题
今天在大批量操作数据时,遇到此问题,解决如下: if(cateName.indexOf("'")!=-1){ oql = " select * where name = ...
- PHP登陆页面完整代码
/* 包括的文件 */ /* login.php */ <?phprequire('./mysql.php');$username=$_REQUEST['username'];$passwd ...
- LINQ---查询表达式的结构
重要事项: 子句必须按照一定的顺序出现 from子句和select...group子句这两部分是必须的 其他子句是可选的 在LINQ查询表达式中,select子句在表达式最后. 可以后任意多的from ...
- NO20文件属性--inode--block-企业场景题
壹 Linux文件属性描述:在Linux里一切皆文件Linux系统中的文件或目录的属性主要包括:索引节点(inode).文件类型.权限属性.链接数.所归属的用户和用户组.最近修改时间等内容. 例子: ...
- greenplum 存储过程 索引信息
涉及的索引表 参考:http://blog.nbhao.org/1539.html pg_index pg_indexes pg_stat_all_indexes # 记录当前数据库中所有的索引的使用 ...
- MySQL学习之SQL基础(一)DDL
Sql基础 DDL (data defination language) 创建表 CREATE TABLE emp( ename varchar(10), hiredate date, sal dec ...