[ DLPytorch ] 文本预处理&语言模型&循环神经网络基础
文本预处理
实现步骤(处理语言模型数据集距离)
文本预处理的实现步骤
读入文本:读入zip / txt 等数据集
with zipfile.ZipFile('./jaychou_lyrics.txt.zip') as zin:
with zin.open('jaychou_lyrics.txt') as f:
corpus = f.read().decode('utf-8')
分词:把换行符替换成空格。如果处理的是英文,最好把大写改成小写。(因为第一次接触文本处理,理解的都很浅显)
corpus = corpus.replace('\n', ' ').replace('\r', ' ')[:20000]
建立字典,将每个词映射到一个唯一的索引(index):将每个字符映射成一个从0开始的连续整数,又称索引,来方便之后的数据处理。为了得到索引,将数据集里所有不同字符取出来,然后将其逐一映射到索引来构造词典。
例如:[1]我; [2]组
#print(set(corpus)) -> {'我', '你', ...}
#print(list(set(corpus))) -> ['我', '你', ...]
idx_to_char = list(set(corpus))
#字典 key=>value: '字': number
char_to_idx = dict([(char, step) for step, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx)
将文本从词的序列转换为索引的序列,方便输入模型:
indices = [char_to_idx[char] for char in corpus] #歌词中每个字的数字
####时序数据的采样
**随机采样**
在随机采样中,每个样本是原始序列上任意截取的一段序列。相邻的两个随机小批量在原始序列上的位置不一定相毗邻。因此,**我们无法用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态**。在训练模型时,每次随机采样前都需要重新初始化隐藏状态。
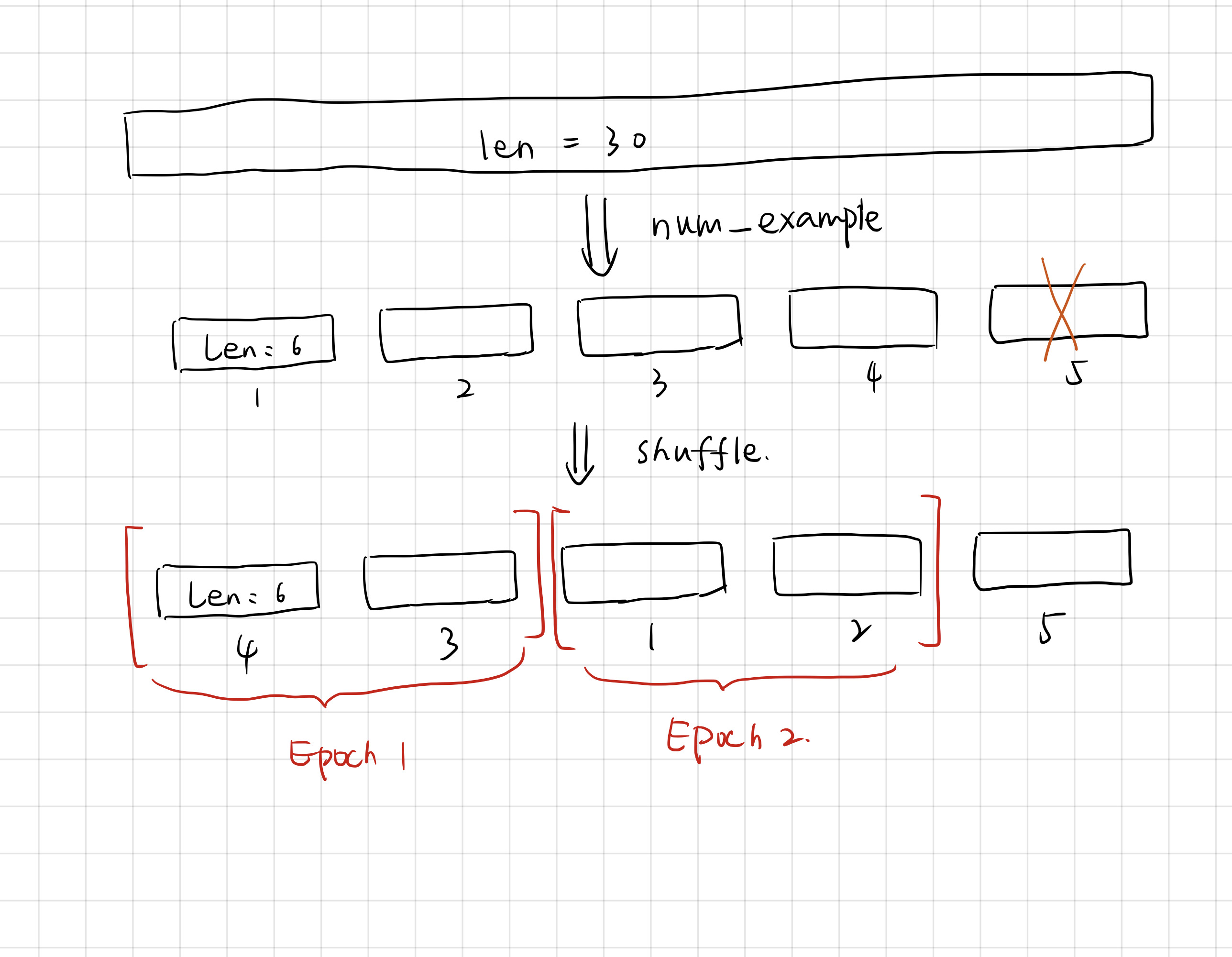
```python
#需要减1是因为y和x相差1
num_example = (len(indices) - 1) // num_step # 30 // 6 = 4
epoch_size = num_example // batch_size #4 // 2 就是例子中的两个X两个Y
example_indices = list(range(num_example))
```
**相邻采样**
令相邻的两个随机小批量在原始序列上的位置相毗邻。这时候,我们就可以用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态,从而使下一个小批量的输出也取决于当前小批量的输入,并如此循环下去。
**注意**:也就是说,比如现在可以分成四组,Z1(X, Y), Z2(X, Y).. Z4(X, Y)。在相邻采样中,任意的X_i与$X_{i-1}$或$X_{i+1}$在取值上是相邻的。这么说来,类似于符合时间顺序的输入。所以,它可以采用保存隐藏状态的方式对下一个批量的隐藏状态初始化。
语言模型
新手还是看看基础教学视频吧- - ...
概念引入


RNN
基础知识
循环神经网络的不同点在于,以时间为步长,本次时间点下的输出是下一个时间点的输入,因此改变输入顺序,会改变输出结果。而处于对过去记忆的保留或忘记,添加了state状态。所以在网络开始时,需要初始化状态。
画图时,更常见的是把function铺平展开,而不是画一个箭头右出左进。
运行过程中,从store中取出state,结合本个时间点的输入x,计算出output和new_state。
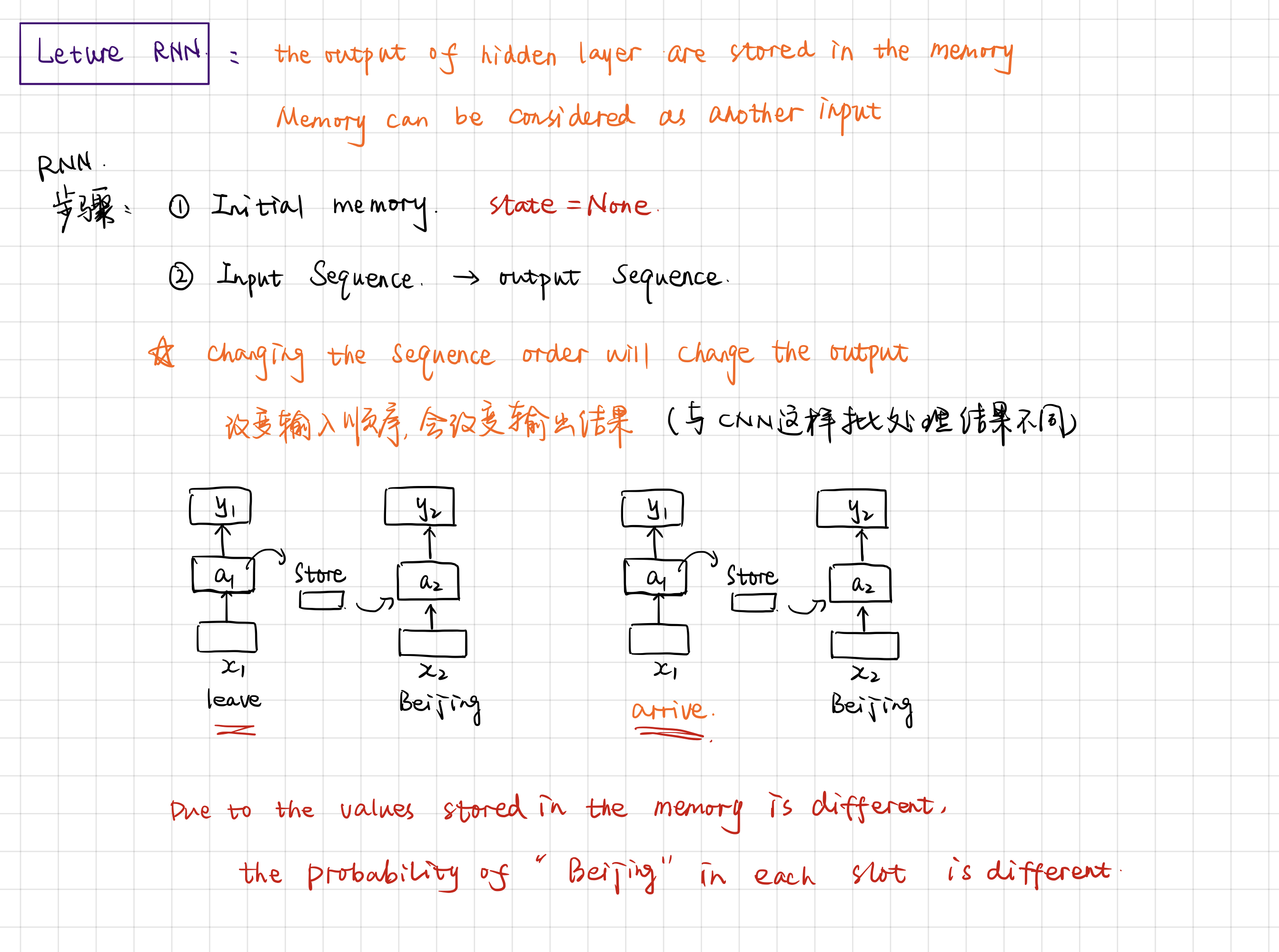
工作过程
因为代码有些复杂,尤其是各种shape,2维的3维的很乱,所以只好图解了一下整个训练的过程。
之前在采样的地方卡顿了很久。注意在将样本传入model的时候是逐个时间步处理整个批量的。
输入形状:(时间步数, 批量大小, 输入个数);输出形状:(时间步数, 批量大小, 隐藏单元个数);隐藏状态h的形状为(层数, 批量大小, 隐藏单元个数)。

学习笔记
one-hot
假设词典中不同字符的数量为\(N\)(即词典大小vocab_size),每个字符已经同一个从0到\(N-1\)的连续整数值索引一一对应。如果一个字符的索引是整数\(i\), 那么我们创建一个全0的长为\(N\)的向量,并将其位置为\(i\)的元素设成1。
def one_hot(x, n_class, dtype=torch.float32):
# X shape: (batch), output shape: (batch, n_class)
x = x.long()
res = torch.zeros(x.shape[0], n_class, dtype=dtype, device=x.device)
res.scatter_(1, x.view(-1, 1), 1)
return res
x = torch.tensor([0, 2])
one_hot(x, vocab_size)
scatter函数
res.scatter_(dim, index, src) 在dim维度下,将index中的value值作为res所要更改数值的列,即res的第value列,修改为src
class_num = 10
batch_size = 4
label = torch.LongTensor(batch_size, 1).random_() % class_num
tensor([[6],
[0],
[3],
[2]])
torch.zeros(batch_size, class_num).scatter_(1, label, 1)
tensor([[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.]])
join函数
print(' '.join(['a', 'b', 'c']))
# a b c
detach函数
当我们再训练网络的时候可能希望保持一部分的网络参数不变,只对其中一部分的参数进行调整;或者值训练部分分支网络,并不让其梯度对主网络的梯度造成影响,这时候我们就需要使用detach()函数来切断一些分支的反向传播。
返回一个新的Variable,从当前计算图中分离下来的,但是仍指向原变量的存放位置,不同之处只是requires_grad为false,得到的这个Variable永远不需要计算其梯度,不具有grad。
即使之后重新将它的requires_grad置为true,它也不会具有梯度grad。
这样我们就会继续使用这个新的Variable进行计算,后面当我们进行反向传播时,到该调用detach()的Variable就会停止,不能再继续向前进行传播。
[ DLPytorch ] 文本预处理&语言模型&循环神经网络基础的更多相关文章
- 用tensorflow实现自然语言处理——基于循环神经网络的神经语言模型
自然语言处理和图像处理不同,作为人类抽象出来的高级表达形式,它和图像.声音不同,图像和声音十分直觉,比如图像的像素的颜色表达可以直接量化成数字输入到神经网络中,当然如果是经过压缩的格式jpeg等必须还 ...
- [DeeplearningAI笔记]序列模型1.5-1.6不同类型的循环神经网络/语言模型与序列生成
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.5不同类型的循环神经网络 上节中介绍的是 具有相同长度输入序列和输出序列的循环神经网络,但是对于很多应用\(T_{x}和 ...
- L26 使用卷积及循环神经网络进行文本分类
文本情感分类 文本分类是自然语言处理的一个常见任务,它把一段不定长的文本序列变换为文本的类别.本节关注它的一个子问题:使用文本情感分类来分析文本作者的情绪.这个问题也叫情感分析,并有着广泛的应用. 同 ...
- 基础篇|一文搞懂RNN(循环神经网络)
基础篇|一文搞懂RNN(循环神经网络) https://mp.weixin.qq.com/s/va1gmavl2ZESgnM7biORQg 神经网络基础 神经网络可以当做是能够拟合任意函数的黑盒子,只 ...
- [ DLPytorch ] 循环神经网络进阶&拟合问题&梯度消失与爆炸
循环神经网络进阶 BPTT 反向传播过程中,训练模型通常需要模型参数的梯度. \[ \frac{\partial L}{\partial \boldsymbol{W}_{qh}} = \sum_{t= ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- Recurrent Neural Networks(RNN) 循环神经网络初探
1. 针对机器学习/深度神经网络“记忆能力”的讨论 0x1:数据规律的本质是能代表此类数据的通用模式 - 数据挖掘的本质是在进行模式提取 数据的本质是存储信息的介质,而模式(pattern)是信息的一 ...
- 学习笔记TF057:TensorFlow MNIST,卷积神经网络、循环神经网络、无监督学习
MNIST 卷积神经网络.https://github.com/nlintz/TensorFlow-Tutorials/blob/master/05_convolutional_net.py .Ten ...
- 循环神经网络(Recurrent Neural Networks, RNN)介绍
目录 1 什么是RNNs 2 RNNs能干什么 2.1 语言模型与文本生成Language Modeling and Generating Text 2.2 机器翻译Machine Translati ...
随机推荐
- Git-配置SSH公钥
前言:Git是分布式的代码管理工具,远程的代码管理是基于SSH的,所以要使用远程的Git则需要SSH的配置. 以下操作都在git-bash命令行中进行. 查看所有配置项: git config --l ...
- Python 数据分析实战 | 用数据带你回顾乔丹的职业生涯
乔丹是联盟上下公认的历史第一人,芝加哥公牛在他带领下几乎统治了上世纪 90 年代 NBA 整整 10 年,包括分别在 91-93 赛季和 96-98 赛季拿下的两次三连冠,要知道,NBA72 年历史上 ...
- 【网易官方】极客战记(codecombat)攻略-地牢-高举之剑
关卡连接: https://codecombat.163.com/play/level/the-raised-sword 为了战斗,学会武装你自己. 简介 依照名字攻击每个食人魔.记住,每个食人魔需要 ...
- IntelliJ IDEA 2017.3尚硅谷-----创建工程
- VS Code 配置 C/C++ (Windwos)
下载VSCode https://code.visualstudio.com/Download 在扩展里安装C/C++插件 配置MinGW 需要再环境变量中的path中添加MinGW的bin目录 修改 ...
- 【译】PHP 内核 — zval 基础结构
[译]PHP 内核 - zval 基础结构 原文地址:http://www.phpinternalsbook.com/php7/internal_types/zvals/basic_structure ...
- 关于pgsql 的json 和jsonb 的数据查询操作笔记整理
关于pgsql 的json 和jsonb 的数据处理笔记 1. json 和jsonb 区别两者从用户操作的角度来说没有区别,区别主要是存储和读取的系统处理(预处理)和耗时方面有区别.json写入快, ...
- 一张linux光盘查看是哪个版本号的方法
在此查看版本号,方法如下:打开光盘,查找rpm包中的release,就是版本号.
- JAVA(3)之关于运算符的优先级
关于运算符的优先级,我做了一个小测试,区别在于平常的运算思维和计算机思维 int result=2; result =(result=result*2)*6*(result=3+result); Sy ...
- Abaqus脚本接口及简单应用
目录 1.脚本接口简介 2. 宏录制 3. 宏回放 4. 宏编辑 5. 宏控制 1.脚本接口简介 Abaqus中的脚本接口(ASI)是在Python应用程序的基础上开发的,基于Abaqus中的脚本接口 ...