小白学 Python 爬虫:Selenium 获取某大型电商网站商品信息
目标
先介绍下我们本篇文章的目标,如图:
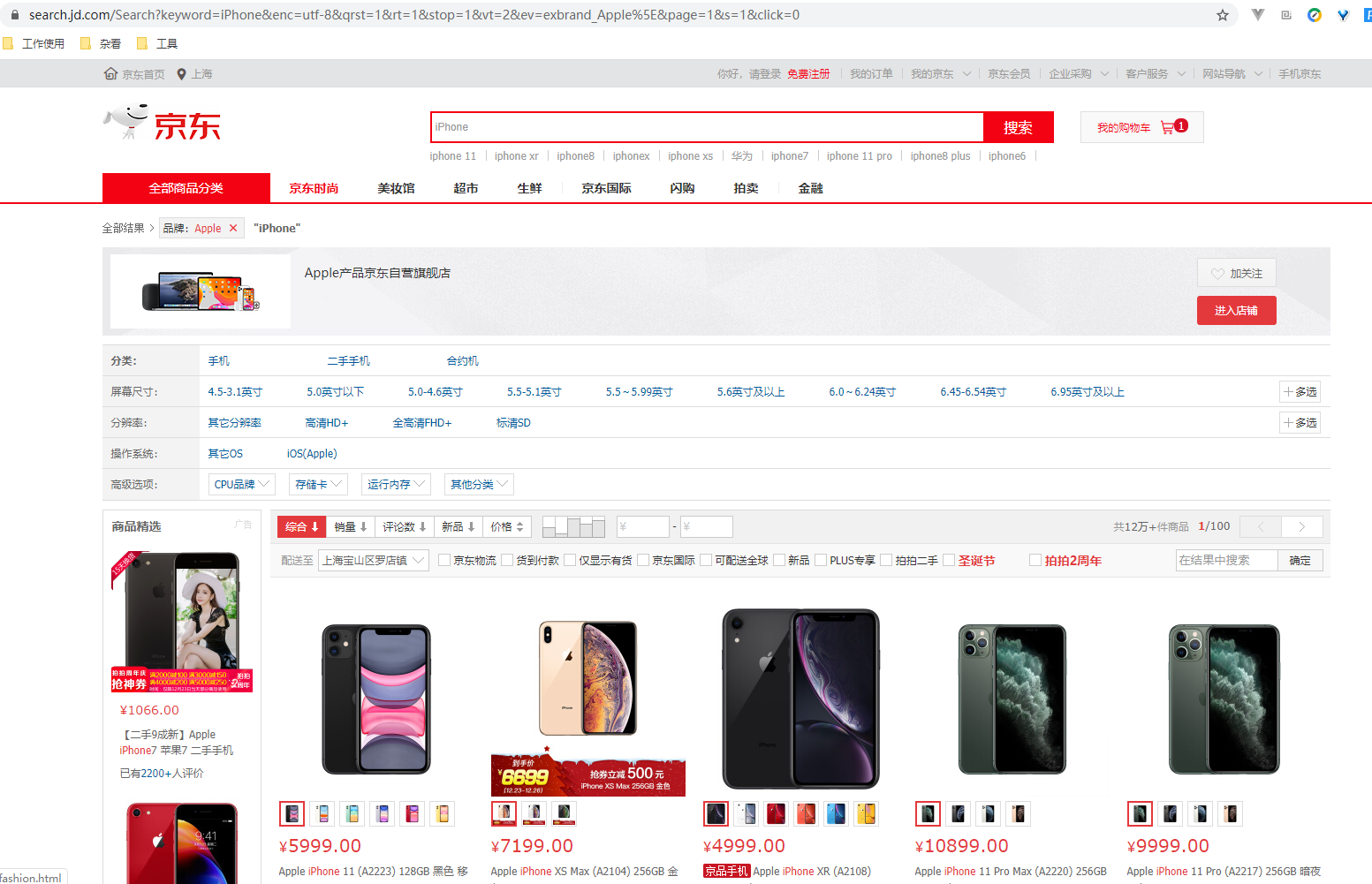
本篇文章计划获取商品的一些基本信息,如名称、商店、价格、是否自营、图片路径等等。
准备
首先要确认自己本地已经安装好了 Selenium 包括 Chrome ,并已经配置好了 ChromeDriver 。如果还没安装好,可以参考前面的前置准备。
分析
接下来我们就要分析一下了。
首先,我们的搜索关键字是 iPhone ,直接先翻到最后一页看下结果,发现有好多商品并不是 iPhone ,而是 iPhone 的手机壳,这个明显不是我们想要的结果,小编这里选择了一下品牌 Apple ,再翻到最后一页,这次就全都是手机了。
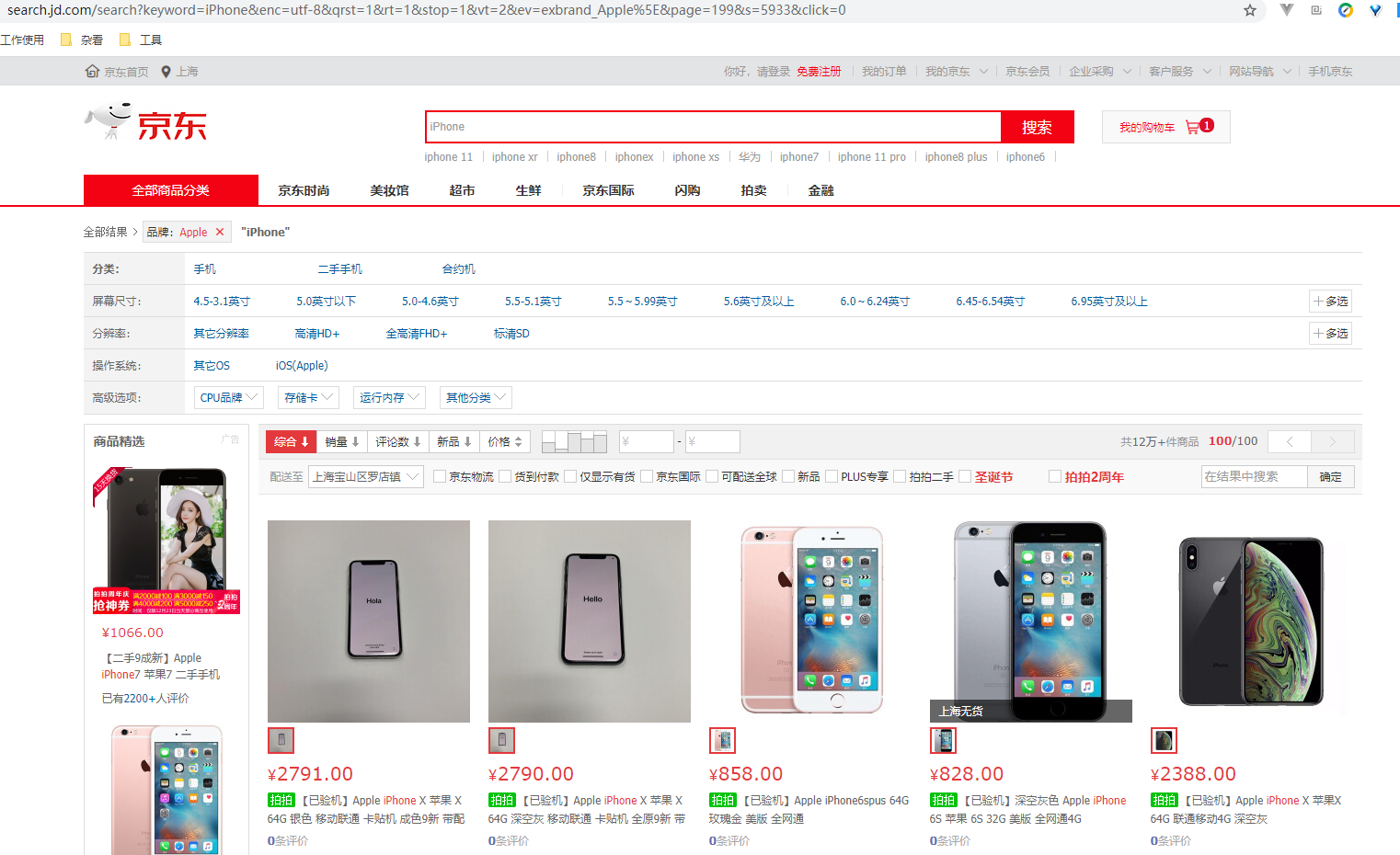
先把地址栏的地址 Copy 出来看一下,里面有很多无效参数:
https://search.jd.com/search?keyword=iPhone&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&ev=exbrand_Apple%5E&page=199&s=5933&click=0如果问小编怎么知道是无效参数还是有效参数,emmmmmmmmm
这个要么靠经验,一般大网站的参数的命名都是比较规范的,当然也不排除命名不规范的。还有一种办法就是试,小编这边试出来的结果是这样滴:
https://search.jd.com/Search?keyword=iPhone&ev=exbrand_Apple第一个参数 keyword 就是我们需要的商品名称,第二个参数 ev 是品牌的参数。
接下来我们看如何获取商品的详细信息,我们使用 F12 打开开发者模式,使用看下具体的信息都放在哪里:
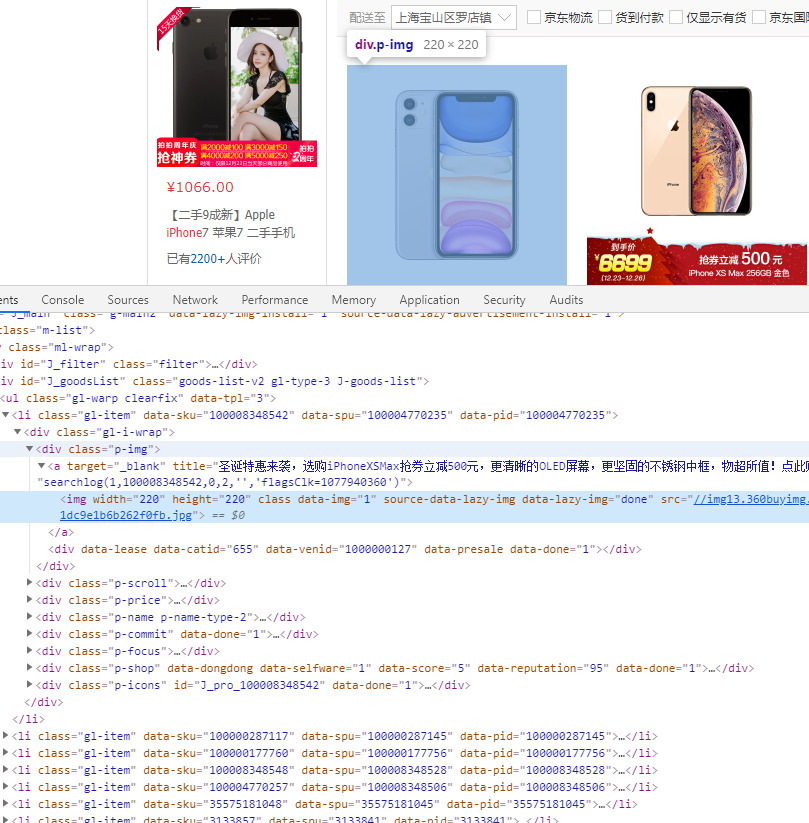
可以看到,我们想要获取的信息在这个页面的 DOM 节点中都能获取到。
接下来因为我们是使用 Selenium 来模拟浏览器访问电商网站,所以后续的接口分析也就不需要做了,直接获取浏览器显示的内容的源代码就可以轻松获取到各种信息。
获取商品列表页面
首先,我们需要构造一个获取商品列表页面的 URL ,这个上面已经得到了,接下来就是使用 Selenium 来获取这个页面了:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.set_window_size(1280,800)
def index_page(page):
"""
抓取索引页
:param page: 页码
"""
print('正在爬取第', str(page), '页数据')
try:
url = 'https://search.jd.com/Search?keyword=iPhone&ev=exbrand_Apple'
driver.get(url)
if page > 1:
input = driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[2]/input')
button = driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[2]/a')
input.clear()
input.send_keys(page)
button.click()
get_products()
except TimeoutException:
index_page(page)这里我们依然使用隐式等待来进行 URL 访问,这里小编通过 xpath 的方式获取到了整个页面最下面的翻页组件:

小编这里的翻页实际上是使用这里的输入框和后面的确认按钮进行的。
获取商品详细数据
这里其实有一个坑,JD 的首页上的图片是懒加载的,就是当页面的滚动条没有滚到这个图片可以显示在屏幕上的位置的时候,这个图片是不会加载出来的。这就造成了小编一开始的只能获取到前 4 个商品的图片地址。
小编后来想了个办法,使用 JavaScript 来模拟滚动条滚动,先将所有的图片加载出来,然后再进行数据的获取,代码如下:
def get_products():
"""
提取商品数据
"""
js = '''
timer = setInterval(function(){
var scrollTop=document.documentElement.scrollTop||document.body.scrollTop;
var ispeed=Math.floor(document.body.scrollHeight / 100);
if(scrollTop > document.body.scrollHeight * 90 / 100){
clearInterval(timer);
}
console.log('scrollTop:'+scrollTop)
console.log('scrollHeight:'+document.body.scrollHeight)
window.scrollTo(0, scrollTop+ispeed)
}, 20)
'''
driver.execute_script(js)
time.sleep(2.5)
html = driver.page_source
doc = PyQuery(html)
items = doc('#J_goodsList .gl-item .gl-i-wrap').items()
i = 0
for item in items:
insert_data = {
'image': item.find('.p-img a img').attr('src'),
'price': item.find('.p-price i').text(),
'name': item.find('.p-name em').text(),
'commit': item.find('.p-commit a').text(),
'shop': item.find('.p-shop a').text(),
'icons': item.find('.p-icons .goods-icons').text()
}
i += 1
print('当前第', str(i), '条数据,内容为:' , insert_data)中间那段 js 就是模拟滚动条向下滚动的代码,这里小编做了一个定时任务,这个定时任务将整个页面的长度分成了 100 份,每 20 ms 就向下滚动 1% ,共计应该总共 2s 可以滚到最下面,这里下面做了 2.5s 的睡眠,保证这个页面的图片都能加载出来,最后再获取页面上的数据。
主体代码到这里就结束了,剩下的代码无非就是将数据保存起来,不管是保存在数据中还是保存在 Excel 中,或者是 CSV 中,又或者是纯粹的文本文件 txt 或者是 json ,都不难,小编这次就不写了,希望大家能自己完善下这个代码。
运行的时候,可以看到一个浏览器弹出来,然后滚动条自动以比较顺滑的速度滚到最下方(小编为了这个顺滑的速度调了很久),确保所有图片都加载出来,再使用 pyquery 获取相关的数据,最后组成了一个 json 对象,给大家看下抓取下来的结果吧:

Chrome 无界面模式
我们在爬取数据的时候,弹出来一个浏览器总感觉有点老不爽了,可以使用如下命令将这个浏览器隐藏起来,不过需要的是 Chrome 比较新的版本。
# 开启无窗口模式
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options)首先,创建 ChromeOptions 对象,接着添加 headless 参数,然后在初始化 Chrome 对象的时候通过 chrome_options 传递这个 ChromeOptions 对象,这样我们就可以成功启用 Chrome 的Headless模式了。
FireFox
如果我们不想使用 Chrome 浏览器,还可以使用 FireFox 浏览器,前提是需要安装好 FireFox 和对应的驱动 GeckoDriver ,并且完成相关配置,不清楚如何安装的同学可以翻一翻前面的前置准备。
我们需要切换 FireFox 浏览器的时候,异常的简单,只需要修改一句话就可以了:
driver = webdriver.Firefox()这里我们修改了 webdriver 初始化的方式,这样在接下来的操作中就会自动使用 FireFox 浏览器了。
如果 Firefox 也想开启无界面模式的话,同样也是可以的,和上面 Chrome 开启无界面模式大同小异:
# FireFox 开启无窗口模式
firefox_options = webdriver.FirefoxOptions()
firefox_options.add_argument('--headless')
driver = webdriver.Firefox(firefox_options=firefox_options)一样是在 Webdriver 初始化的时候增加 headless 参数就可以了。
好了,本篇的内容就到这里了,希望各位同学可以自己动手练习下哦~~~
小白学 Python 爬虫:Selenium 获取某大型电商网站商品信息的更多相关文章
- 小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(30):代理基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(31):自己构建一个简单的代理池
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- cef源码分析之cefsimple
下面是cefsimple的入口代码,主要分成两个部分 // Entry point function for all processes. int APIENTRY wWinMain(HINSTANC ...
- C# byte[]转string, string转byte[] 的四种方法
转载:https://blog.csdn.net/tom_221x/article/details/71643015 第一种 string str = System.Text.Encoding ...
- Windows下MD5校验
参考博客:https://www.cnblogs.com/liubinghong/p/9299276.html 参考博客:https://www.jianshu.com/p/1e1d56552e03 ...
- FileOutputStream,BufferedOutputStream,FileWriter 效率比较
测试代码: /** * 写文件 * FileOutputStream, BufferedOutputStream, FileWriter * 三个流 效率比较 */ @Test public void ...
- 论STA | POCV/SOCV 对lib 的要求 (4)
在芯片制造过程中的工艺偏差由global variation 和local variation 两部分组成. 在集成电路设计实现中,global variation 用PVT 跟 RC-corner ...
- ARM64架构下面安装mysql5.7.22
MySQL下载地址为: https://obs.cn-north-4.myhuaweicloud.com/obs-mirror-ftp4/database/mysql-5.7.27-aarch64.t ...
- spark-shell中往mysql数据库写数据报错
今天在看spark方面的知识的时候,在spark-shell中往mysql写数据时报错,错误信息如下: ERROR Executor: Exception in task 0.0 in stage 4 ...
- Azure IoT Hub 十分钟入门系列 (4)- 实现从设备上传日志文件/图片到 Azure Storage
本文主要分享一个案例: 10分钟内通过Device SDK上传文件到IoTHub B站视频:https://www.bilibili.com/video/av90224073/ 本文主要有如下内容: ...
- Dockerfile文档编写
图片显示问题,附上有道云笔记中链接:http://note.youdao.com/noteshare?id=fba6d2f53fd6447ba32c3b7accfeb89b&sub=B36B5 ...
- django之orm的高级操作以及xcc安全攻击
查询用法大全: 1. 比较运算符 # id > 3 res = models.UserInfo.objects.filter(id__gt=3) # id >= 3 res = model ...