Python 爬取 热词并进行分类数据分析-[数据修复]
日期:2020.02.01
博客期:140
星期六
【本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)】
所有相关跳转:
a.【简单准备】
b.【云图制作+数据导入】
c.【拓扑数据】
d.【数据修复】(本期博客)
e.【解释修复+热词引用】
f.【JSP演示+页面跳转】
g.【热词分类+目录生成】
h.【热词关系图+报告生成】
i . 【App制作】
j . 【安全性改造】
今天问了一下老师,好像是之前数据爬取的内容就不对,不应该爬取标签,我仔细想了一下,也确实不是,所以今天我们来爬取IT新闻里的高频词!
我大致分了下面几个步骤
1、选择想要爬取的网站
之前那个网站有标签,所以我按照那个爬的,实际上没有必要,随便一个IT新闻网站都可以爬的!而且上一次的爬取网站有很大的问题就是它不能加载太多数据,加载个200次,就基本卡死了!所以我们尽量要找到一个有页数下表的列表类型的网页,要不然就是有“下一页”或“下一篇新闻”类似的链接的网页。
下面是提供参考的网站:
(1)、IT之家(大概可以爬到700条数据,数据大致横跨7天,推荐每周爬取一次,并进行汇总查重,其中有非信息类新闻夹杂)
(2)、博客园(推荐,大概可以一次爬3000条数据,数据大致横跨2个月零4天,推荐隔2个月爬一次,其中有少量非信息类新闻夹杂,且单项数据的文字数目较少)
(3)、DoNews(这个是针对互联网的)
(4)、ZOL中关村在线(这个只有一页,数据横跨两周,推荐隔13天爬)
(5)、IT界(可以直接一次爬取14969项新闻,其中有少量非信息类新闻夹杂,仅提供一次性爬取,最早数据日期为2012-04-23)
(6)、51CTO(上次推荐的网站,有标签标记和关键索引)
(7)、走廊网(和上面一样是滚动式网站,一样的弊病,还有这个网站分类有IT类,但是内容不完全是IT相关的)
(8)、说IT资讯网(数据都是老数据了,2011年还行,我们要的是热词,不推荐)
国外IT新闻网站推荐博客地址:https://www.cr173.com/html/5311_1.html
2、开始针对于网站进行爬取(目标:获得文字内容和网址链接)
我最终还是决定爬博客园了(我爬我自己),因为数据量足够(虽然不及老师的要求10万,但以上几个网站的数据量都那样吧,想要大量新闻数据...也说不定还有第三次重新数据爬取的博客呢!)
分析博客园的新闻链接地址
第一页链接:https://news.cnblogs.com/
第二页链接:https://news.cnblogs.com/n/page/2/
第n(n>=2&n<=100)页链接:https://news.cnblogs.com/n/page/{$n}/
来分析数据项
需要爬取标题、内部内容和本地链接,如果需要以“下一篇”的形式做数据跳转,那你还需要爬取下一篇的链接地址
爬取数据格式如下:
import codecs class News:
title = ""
info = ""
link = "" def __init__(self,title,info,link):
self.title = title
self.info = info
self.link = link def __toString__(self):
return self.title+"\t"+self.info+"\t"+self.link def __toFile__(self,filePath):
f = codecs.open(filePath, "a+", 'utf-8')
f.write(self.__toString__() + "\n")
f.close()
News.py
数据处理以后对应格式如下:
import codecs class KeyWords:
word = ""
link = ""
num = 0 def __init__(self,word,link,num):
self.word = word
self.link = link
self.num = num def __toString__(self):
return self.word +"\t"+str(self.num)+"\t"+self.link def __toFile__(self,filePath):
f = codecs.open(filePath, "a+", 'utf-8')
f.write(self.__toString__() + "\n")
f.close()
KeyWords.py
爬取工具编写:
这个工具写了很久,因为博客园爬取需要模拟验证码登录,但你以为我成功找到了自动输入验证码的工具了吗?不!我只是取巧了一下:Canvas的代码我还不太了解,不可能深入去学习的(因为今天必须要爬到数据),嗯,怎么解决呢?你想一下,步枪有全自动的也有半自动的啊!我就不能来个半自动爬取吗?诶!我还真就是这样做的,登录需要点击验证码,我们就使用time.sleep()方法让代码晚一点再执行,等到它模拟出来了验证码,咱们人工给它验证一下!再然后呢?就等着它的数据自动被爬了呗!当然,等待多少时间因你的主机情况和网速而定,网速较慢的话,就给等待时间长一点!
单个新闻页面爬取类
import parsel
from urllib import request
import codecs
from selenium import webdriver
import time # [ 一次性网页爬取的对象 ]
from itWords.retire.Kord import News # [ 对字符串的特殊处理方法-集合 ]
class StrSpecialDealer:
# 取得当前标签内的文本
@staticmethod
def getReaction(stri):
strs = StrSpecialDealer.simpleDeal(str(stri))
strs = strs[strs.find('>')+1:strs.rfind('<')]
return strs # 去除基本的分隔符
@staticmethod
def simpleDeal(stri):
strs = str(stri).replace(" ", "")
strs = strs.replace("\t", "")
strs = strs.replace("\r", "")
strs = strs.replace("\n", "")
return strs # 删除所有标签标记
@staticmethod
def deleteRe(stri):
strs = str(stri)
st = strs.find('<')
while(st!=-1):
str_delete = strs[strs.find('<'):strs.find('>')+1]
strs = strs.replace(str_delete,"")
st = strs.find('<') return strs # 删除带有 日期 的句子
@staticmethod
def de_date(stri):
lines = str(stri).split("。")
strs = ""
num = lines.__len__()
for i in range(0,num):
st = str(lines[i])
if (st.__contains__("年") | st.__contains__("月")):
pass
else:
strs += st + "。"
strs = strs.replace("。。", "。")
return strs # 取得带有 日期 的句子之前的句子
@staticmethod
def ut_date(stri):
lines = str(stri).split("。")
strs = ""
num = lines.__len__()
for i in range(0, num):
st = str(lines[i])
if (st.__contains__("年")| st.__contains__("月")):
break
else:
strs += st + "。"
strs = strs.replace("。。","。")
return strs @staticmethod
def beat(stri,num):
strs = str(stri)
for i in range(0,num):
strs = strs.replace("["+str(i)+"]","") return strs class Oranpick:
basicURL = ""
profile = "" # ---[定义构造方法]
def __init__(self, url):
self.basicURL = url
self.profile = webdriver.Firefox()
self.profile.get("https://account.cnblogs.com/signin?returnUrl=https%3A%2F%2Fnews.cnblogs.com%2Fn%2F654191%2F")
self.profile.find_element_by_id("LoginName").send_keys("初等变换不改变矩阵的秩")
self.profile.find_element_by_id("Password").send_keys("password") # your password
time.sleep(2)
self.profile.find_element_by_id("submitBtn").click()
# 给予 15s 的验证码人工验证环节
time.sleep(15)
self.profile.get(url) # 重新设置
def __reset__(self,url):
self.basicURL = url
self.profile.get(url) # ---[定义释放方法]
def __close__(self):
self.profile.quit() # 获取 url 的内部 HTML 代码
def getHTMLText(self):
a = self.profile.page_source
return a # 获取基本数据
def getNews(self):
index_html = self.getHTMLText()
index_sel = parsel.Selector(index_html)
context = index_sel.css('#news_title a')[0].extract()
context = StrSpecialDealer.getReaction(context)
context = StrSpecialDealer.simpleDeal(context)
conform = index_sel.css('#news_body')[0].extract()
conform = StrSpecialDealer.deleteRe(conform)
conform = StrSpecialDealer.simpleDeal(conform)
news = News(title=context, info=conform, link=self.basicURL)
return news def main():
url = "https://news.cnblogs.com/n/654221/"
ora = Oranpick(url)
# print(ora.getNews().__toString__()) # main()
Oranpick.py
新闻页面地址爬取类
import time import parsel
from urllib import request
import codecs from itWords.retire.Oranpick import Oranpick # [ 连续网页爬取的对象 ] class Surapity:
page = 1
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'}
basicURL = ""
oran = "" # ---[定义构造方法]
def __init__(self):
self.page = 1
self.basicURL = "https://news.cnblogs.com/"
self.oran = Oranpick("https://start.firefoxchina.cn/") def __close__(self):
self.oran.__close__() def __next__(self):
self.page = self.page + 1
self.basicURL = 'https://news.cnblogs.com/n/page/'+str(self.page)+'/' # 获取 url 的内部 HTML 代码
def getHTMLText(self):
req = request.Request(url=self.basicURL, headers=self.headers)
r = request.urlopen(req).read().decode()
return r # 获取页面内的基本链接
def getMop(self,filePath):
index_html = self.getHTMLText()
index_sel = parsel.Selector(index_html)
links = index_sel.css(".news_entry a::attr(href)").extract()
size = links.__len__()
for i in range(0,size):
link = "https://news.cnblogs.com"+links[i]
self.oran.__reset__(link)
self.oran.getNews().__toFile__(filePath) def fileReset(filePath):
f = codecs.open(filePath, "w+", 'utf-8')
f.write("")
f.close() def main():
filepath = "../../testFile/rc/news.txt"
s = Surapity()
fileReset(filepath)
s.getMop(filepath)
s.__next__()
s.getMop(filepath)
while s.page <= 100:
s.__next__()
s.getMop(filepath)
s.__close__() main()
Surapity.py
这样就能够爬取到相关数据
3、利用 Python 的 开源 jieba 组件进行中文词频统计
jieba组件下载地址:https://pypi.org/project/jieba/
我的下载方法:(确保电脑处于联机状态——就是你联网了,你也可以参照上述官网下载地址的下载方法)
(1)打开PyCharm
(2)在非菜单栏、非窗口、非代码演示部分鼠标右击,并选中"Open in Terminal"
(3) 输入命令(因你运行的 Python 环境而异)
easy_install jieba 无限制
pip install jieba Python 2 & Python 3
pip3 install jieba Python 3
(4)等待其下载完成,如图: 
使用方法参照以下博客(本期博客非针对jieba,不再过多赘述):
小注:
其实我们对 jieba 组件的使用还有一些问题的,不过我们只要高频词,使用那三种模式应该无所谓了(还是推荐精准模式)
4、制作词语筛选部分,并进行封装
测试文件
《2019年OPPO开放平台年度总结》正式发布
近日,OPPO开放平台通过官微平台发布了《2019年OPPO开放平台年度总结》。
这份年度总结对OPPO智能服务新生态的用户属性、用户偏好、市场增长,以及OPPO开放平台的技术能力和服务能力进行了详细的介绍,帮助开发者及合作伙伴挖掘数据背后的衍生价值,携手共创更优质的用户体验。
ColorOS全球月活超3.2亿,以优质年轻群体为主
根据《2019年OPPO开放平台年度总结》显示,目前ColorOS全球月活跃用户数已超过3.2亿,覆盖国家和地区超过140个。而在国内用户中,25岁~34岁的优质年轻群体占比更是高达63%,24岁以下用户占比为21%,足见OPPO手机设备深受年轻群体所喜爱。
正因如此,OPPO无论是硬件端的产品创新,还是软件端的“黑科技”研发,也都始终迎合年轻群体偏好。如在2019年10月上市的OPPO Reno Ace,其配置为骁龙855 Plus、65W超级闪充、90Hz电竞屏、最高12GB+256GB存储组合,2999元起的高性价比优势,让其开售5分钟销售额破亿,斩获全平台手机单品销量&销售额双冠军。
此外,该产品搭载OPPO“五大系统能力开放引擎”之一的Hyper Boost,并与游戏厂商深度合作,更充分地发挥了硬件性能。OPPO Reno Ace高性价比的产品配置以及“黑科技”加持,让年轻消费者直呼“这很Ace!”。
OPPO开放平台携手合作伙伴共建智能服务新生态,打造优质用户体验
产品受到用户喜爱,同样也离不开智能服务新生态的建设。OPPO开放平台为了给用户带来更优质的产品体验,将其技术能力深度赋能给合作伙伴,携手合作伙伴合作共赢。
根据《2019年OPPO开放平台年度总结》显示,在OPPO开放平台的应用分发情况分析中,视频播放类、教育学习类、实用工具类APP是最受用户青睐的应用类别。
时代大环境下,OPPO积极建设视频功能迎合用户需求,OPPO短视频业务月活跃用户已突破6000万,每日人均使用时长超过50分钟,为优质的视频内容分发和应用分发,提供了可以结合用户手机操作偏好的又一大渠道。
在短视频类目的软件能力建设方面,OPPO也始终走在创新前沿。当抖音、快手等热门短视频类APP接入“五大系统能力开放引擎”之一的CameraUnit,调用OPPO手机核心功能“超级防抖”,就能够让用户直接拍摄出稳定、清晰的视频。
深度挖掘数据的衍生价值,OPPO早已不再是一家纯粹的手机公司
硬件产品受到年轻用户喜爱,软件能力不断创新,也让OPPO的业务线早已不再局限于手机制造。当前,OPPO已经建设了更为完善的开放生态,除了技术能力加持赋能合作伙伴,依托自身市场优势,也为应用、游戏、快应用、小游戏等产品分发推广和联运提供了更为广阔的发展空间,为各链端合作伙伴提供全方位的服务。
根据《2019年OPPO开放平台年度总结》显示,以OPPO软件商店和游戏中心的全球月活跃用户数已超过3亿,全球日分发次数也超过7.8亿次。同时,OPPO开放平台还在积极扩展自身的业务服务范围,并不断创新服务形式。以应用分发业务为例,通过数据赋能、活动赋能、素材A/B test、活动组建化赋能等形式,帮助开发者实现更加高效的APP运营。
除此之外,OPPO还在科技的各个领域积极探索。例如,在2019年12月19日的2019 OPPO开发者大会上发布IoT“启能行动”,将帮助更多品牌厂商快速实现产品的智能化。
此外,2020年OPPO将继续投入价值10亿资源,为应用、服务、内容、出海领域的优秀合作伙伴,提供开发、流量、营销推广等一系列的资源支持,全方位助力合作伙伴的业务发展;OPPO荣获中文机器阅读理解挑战赛DuReader 2019年度冠军,AI领域再次取得新突破……
由此可见,通过对多维度技术的持续、广泛的布局,OPPO早已不再是一家纯粹的手机公司。据OPPO创始人陈明永介绍,OPPO未来三年将投入500亿研发预算,持续关注5G、人工智能、AR、大数据等前沿技术,并着力构建底层硬件核心技术以及软件工程和系统能力。
OPPO开放平台作为B端业务的主要窗口,这份《2019年OPPO开放平台年度总结》的公布既能让行业窥见到OPPO综合能力的一方天地,也将吸引更多合作伙伴加入OPPO开放平台,合作共创新未来。
查看完整年度总结,请关注OPPO开放平台官方微信公众号“OPPO开发者”或微博“OPPO开放平台”。
ad.txt
标准规范类
# 新闻段落高频词分析器
import jieba
import jieba.analyse class ToolToMakeHighWords:
test_str = "" # 初始化
def __init__(self,test_str):
self.test_str = str(test_str)
pass def buildWithFile(self,filePath,type):
file = open(filePath, encoding=type)
self.test_str = file.read() def buildWithStr(self,test_str):
self.test_str = test_str
pass # 统计词
def getWords(self,isSimple,isAll):
if(isSimple):
words = jieba.lcut_for_search(self.test_str)
return words
else:
# True - 全模式 , False - 精准模式
words = jieba.cut(self.test_str, cut_all=isAll)
return words # 统计词频并排序
def getHighWords(self,words):
data = {}
for charas in words:
if len(charas) < 2:
continue
if charas in data:
data[charas] += 1
else:
data[charas] = 1 data = sorted(data.items(), key=lambda x: x[1], reverse=True) # 排序 return data # 以频率要求数目为依据进行筛选
def selectObjGroup(self,num):
a = jieba.analyse.extract_tags(self.test_str, topK=num, withWeight=True, allowPOS=())
return a def selectWordGroup(self,num):
b = jieba.analyse.extract_tags(self.test_str, topK=num, allowPOS=())
return b def main():
file = open('../testFile/rc/ad.txt', encoding="utf-8")
file_context = file.read()
ttmhw = ToolToMakeHighWords(file_context)
li = ttmhw.selectWordGroup(2)
print(li) main()
ToolToMakeHighWords.py
测试截图

5、相关类进行关联得到需要的数据
整理以上代码
对已经写好的Surapity.py文件进行修改:(使其在爬取的过程中,直接完成统计,并记录网址)
import time import parsel
from urllib import request
import codecs from itWords.retire.Kord import KeyWords
from itWords.retire.Oranpick import Oranpick # [ 连续网页爬取的对象 ]
from itWords.retire.highWords import ToolToMakeHighWords class Surapity:
page = 1
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'}
basicURL = ""
oran = "" # ---[定义构造方法]
def __init__(self):
self.page = 1
self.basicURL = "https://news.cnblogs.com/"
self.oran = Oranpick("https://start.firefoxchina.cn/") def __close__(self):
self.oran.__close__() def __next__(self):
self.page = self.page + 1
self.basicURL = 'https://news.cnblogs.com/n/page/'+str(self.page)+'/' # 获取 url 的内部 HTML 代码
def getHTMLText(self):
req = request.Request(url=self.basicURL, headers=self.headers)
r = request.urlopen(req).read().decode()
return r # 获取页面内的基本链接
def getMop(self,filePath):
index_html = self.getHTMLText()
index_sel = parsel.Selector(index_html)
links = index_sel.css(".news_entry a::attr(href)").extract()
size = links.__len__()
for i in range(0,size):
link = "https://news.cnblogs.com"+links[i]
self.oran.__reset__(link)
news = self.oran.getNews()
ttm = ToolToMakeHighWords(news.getSimple())
words = ttm.getHighWords(ttm.getWords(False,False))
leng = words.__len__()
# 频数 要在 15次 以上
for i in range(0,leng):
if words[i][1]<=15:
break
keyw = KeyWords(word=words[i][0],link=link,num=words[i][1])
keyw.__toFile__(filePath) def fileReset(filePath):
f = codecs.open(filePath, "w+", 'utf-8')
f.write("")
f.close() def main():
filepath = "../../testFile/rc/news.txt"
s = Surapity()
fileReset(filepath)
s.getMop(filepath)
s.__next__()
s.getMop(filepath)
while s.page <= 100:
s.__next__()
s.getMop(filepath)
s.__close__() main()
Surapity.py
对应测试截图:
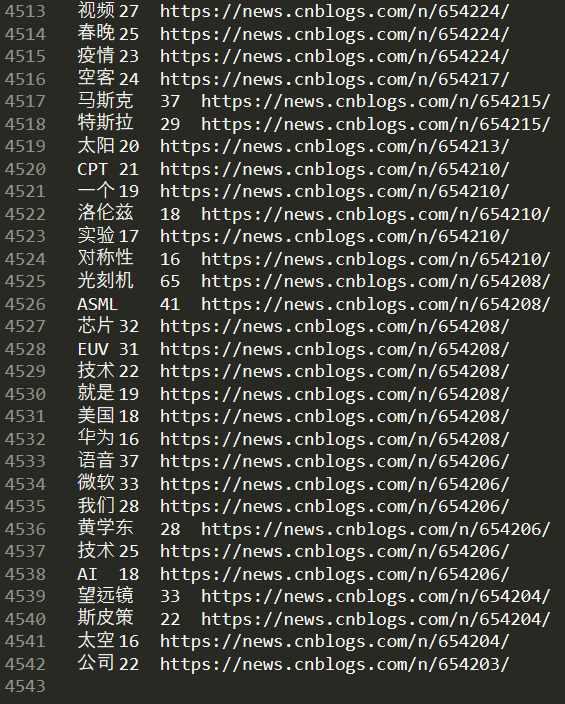
小注:这只是中间过程,需要进一步统计(上述是实现了每一篇新闻的频数大于15的高频词)
上述结果已经可以导入MySql了,如果不想用文件导入,就用下面的Sql语句,别忘了输出之前先建表(words表)
有了文件sql语句可以由此生成:
import codecs filePath = "../../testFile/rc/words_sql.txt"
f = codecs.open(filePath, "w+", 'utf-8')
f.write("")
f.close() fw = open("../../testFile/rc/news.txt", mode='r', encoding='utf-8')
tmp = fw.readlines() num = tmp.__len__() for i in range(0,num):
group = tmp[i].split("\t")
group[0] = "'" + group[0] + "'"
group[2] = "'" + group[2][0:group[2].__len__()-1] + "'"
f = codecs.open(filePath, "a+", 'utf-8')
f.write("Insert into words values ("+group[0]+","+group[1]+","+group[2]+");"+"\n")
f.close()
SqlDeal.py
数据库对应Sql文件下载地址:https://files.cnblogs.com/files/onepersonwholive/words.zip
之后建立视图 keywords
视图定义如下:
SELECT
`words`.`word` AS `word`,
sum(`words`.`num`) AS `num`
FROM
`words`
GROUP BY
`words`.`word`
ORDER BY
`num` DESC
keywords(View)
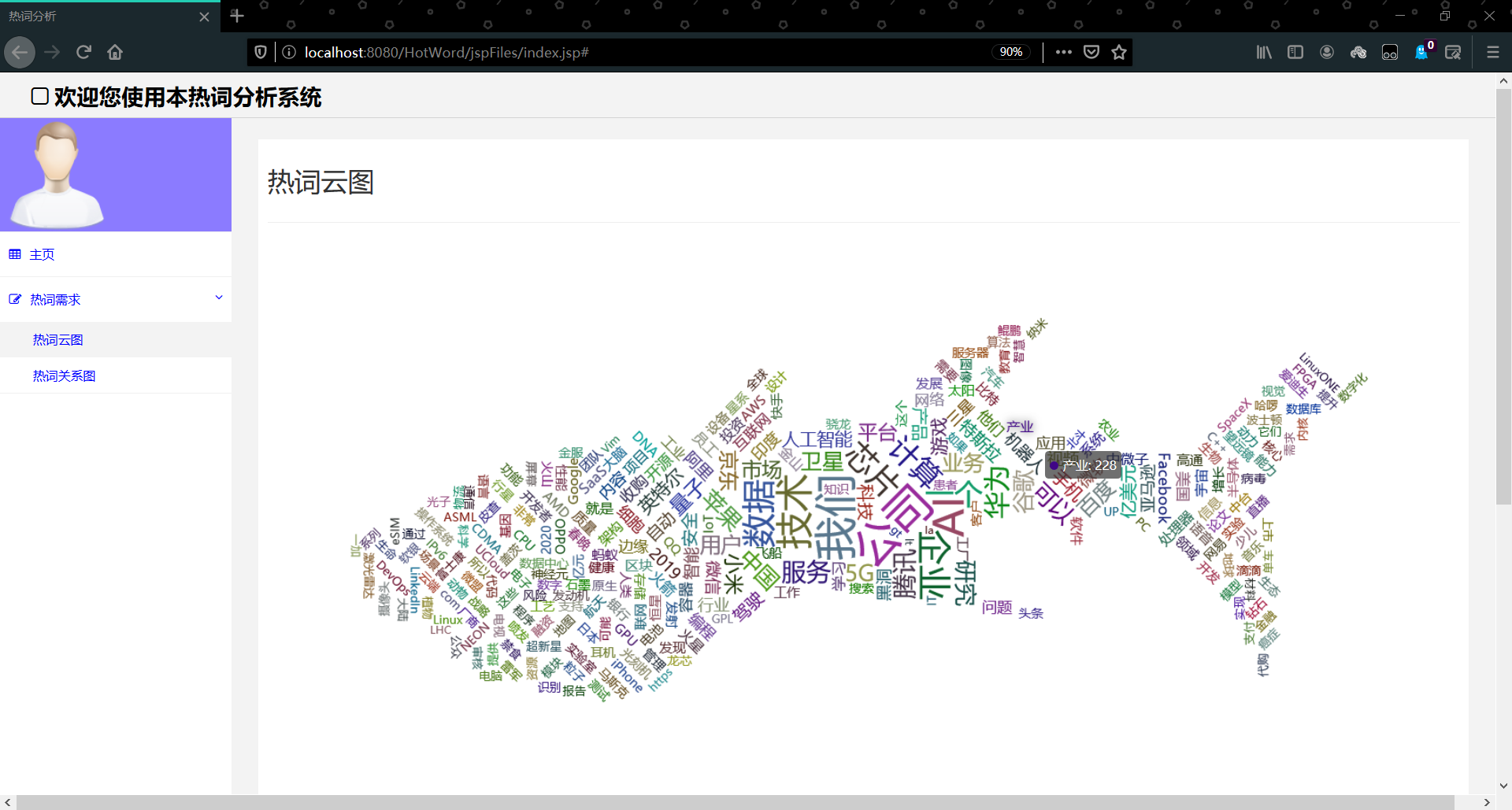
视图展示:

然后,将第136期博客的 Servlet 修改一下:
package com.servlet; import java.io.IOException;
import java.sql.SQLException;
import java.util.List; import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse; import org.json.JSONArray;
import org.json.JSONObject; import com.dblink.basic.utils.SqlUtils;
import com.dblink.basic.utils.sqlKind.MySql_s;
import com.dblink.basic.utils.user.UserInfo;
import com.dblink.bean.BeanGroup;
import com.dblink.sql.DBLink; @SuppressWarnings("unused")
public class ServletForWords extends HttpServlet{
/**
*
*/
private static final long serialVersionUID = 1L;
//----------------------------------------------------------------------//
public void doPost(HttpServletRequest request,HttpServletResponse response) throws ServletException, IOException
{
request.setCharacterEncoding("utf-8");
response.setCharacterEncoding("utf-8");
response.setContentType("application/json");
response.setHeader("Cache-Control", "no-cache");
response.setHeader("Pragma", "no-cache"); JSONArray jsonArray = new JSONArray(); DBLink dbLink = new DBLink(new SqlUtils(new MySql_s("rc"),new UserInfo("root","123456")));
BeanGroup bg = null;
try {
bg = dbLink.getSelect("Select * From keywords ").beans;//where num > 6
int leng = bg.size();
for(int i=0;i<leng;++i)
{
JSONObject jsonObject = new JSONObject();
jsonObject.put("name",bg.get(i).get(0));
jsonObject.put("value",bg.get(i).get(1));
jsonArray.put(jsonObject);
}
} catch (SQLException e) {
// Do Nothing ...
}
dbLink.free(); ServletOutputStream os = response.getOutputStream();
os.write(jsonArray.toString().getBytes());
os.flush();
os.close();
}
//---------------------------------------------------------------------------------//
}
ServletForWords.java
对应截图:
Python 爬取 热词并进行分类数据分析-[数据修复]的更多相关文章
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[云图制作+数据导入]
日期:2020.01.28 博客期:136 星期二 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入](本期博客) ...
- Python 爬取 热词并进行分类数据分析-[简单准备] (2020年寒假小目标05)
日期:2020.01.27 博客期:135 星期一 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备](本期博客) b.[云图制作+数据导入] ...
- Python 爬取 热词并进行分类数据分析-[热词分类+目录生成]
日期:2020.02.04 博客期:143 星期二 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[ ...
- Python 爬取 热词并进行分类数据分析-[拓扑数据]
日期:2020.01.29 博客期:137 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[App制作]
日期:2020.02.14 博客期:154 星期五 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[JSP演示+页面跳转]
日期:2020.02.03 博客期:142 星期一 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[热词关系图+报告生成]
日期:2020.02.05 博客期:144 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
随机推荐
- Bugku-CTF之本地包含( 60)
Day36
- the MTS failed last time时的解决办法
关于6.6.3SP2版本提示The MTS failed last time 1.1 发生前提条件 在重启系统 shutdown -r now后,网页打不开,发现MTS服务无法启动,我自己涉及的 ...
- AcWing STL初步学习
vector, 变长数组,倍增的思想 size() 返回元素个数 empty() 返回是否为空 clear() 清空 front()/back() push_back()/pop_back() beg ...
- SQL实现group by 分组后组内排序
在一个月黑风高的夜晚,自己无聊学习的SQL的时候,练习,突发奇想的想实现一个功能查询,一张成绩表有如下字段,班级ID,英语成绩,数据成绩,语文成绩如下图 实现 查询出 每个班级英语成绩最高的前两名的记 ...
- cgroup的学习笔记
1.cgroup是什么? cgroup是一个linux内核提供的机制.目的是为了做资源隔离,资源限制,资源记录. 2.cgroup怎么安装? yum install cgroup service cg ...
- 转载:Linux 时钟基础学习
1.HZ Linux核心每隔固定周期会发出timer interrupt (IRQ 0),HZ是用来定义每一秒有几次timer interrupts.举例来说,HZ为1000,代表每秒有1000次ti ...
- unittest 测试套件使用汇总篇
# coding=utf-8import unittestfrom inspect import isfunction def usage(): """also unit ...
- Windows Server 2016安装.NET Framework 3.5
1.打开“服务器管理器” 2.点击“添加角色和功能” 3.点击“下一步” 4.点击“下一步” 5.点击“下一步” 6.点击“下一步” 7.勾选“.NET Framework 3.5功能”,点击“下一步 ...
- [vue学习] 卡片展示分行功能简单实现
如图所示,实现简单的卡片展示分行功能. 分行功能较多地用于展示商品.相册等,本人在学习的过程中也是常常需要用到这个功能:虽然说现在有很多插件都能实现这个功能,但是自己写出来,能够理解原理,相信能够进步 ...
- 排序算法大荟萃——希尔(Shell)排序算法
1.基本思想:先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组.所有距离为d1的倍数的记录放在同一个组中.先再各族中进行直接插入排序,然后取第二个增量d2<d1重复上述的分组 ...