作业3-k均值算法
4. 作业:
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
4). 鸢尾花完整数据做聚类并用散点图显示.
5).想想k均值算法中以用来做什么
答:
(1)
第一轮:13、10、5

第二轮:13、9、4

(2)
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
#导入数据
iris = load_iris()
data = iris.data # 数据值
data.shape # 可知数据的总数和属性个数
n = len(data) # 数据集样本个数
m = data.shape[1] # 数据的属性个数
# 类中心个数(1-5)
k = 3
dist = np.zeros([n, k+1]) # k+1是最后一列要归类
# 选中心
center = data[:k, :] # k为3所以是前三行所有属性
centerNew = np.zeros([k, m]) # 初始化新的类中心
while True:
# 求距离
for i in range(n):
for j in range(k):
dist[i, j] = np.sqrt(sum((data[i, :]-center[j, :])**2)) # 求欧式距离
# 归类
dist[i, k] = np.argmin(dist[i, :k])
for i in range(k):
index = dist[:, k] == i
centerNew[i, :] = data[index, :].mean(axis=0)
# 判定结果
if np.all((center == centerNew)):
break
else:
center = centerNew
print("聚类结果:\n", dist[:, k])
# print(data[:,k])
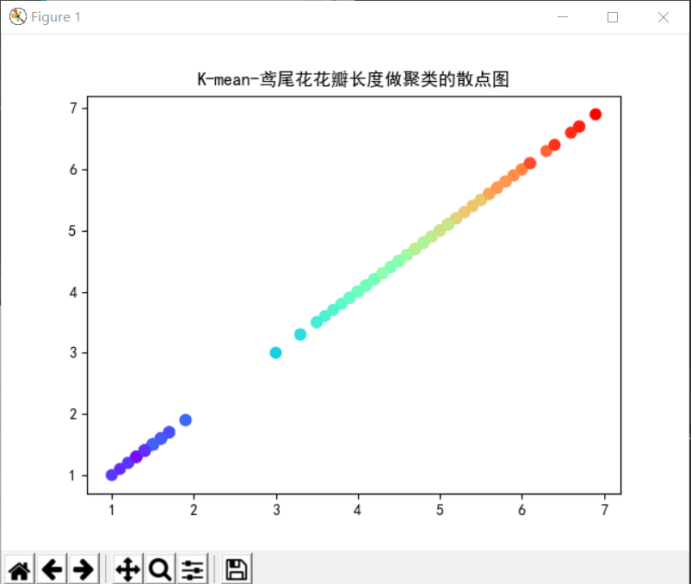
plt.scatter(data[:,2], data[:,2], c=dist[:,2], s=50, cmap='rainbow')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("K-mean-鸢尾花花瓣长度做聚类的散点图")
plt.show()
(3)
# 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans iris = load_iris() # 导入鸢尾花数据
# print(iris)
X = iris.data[:, 2] # 第三列为花瓣长度
X = X.reshape(-1, 1) # 令新数组列为1
# print(X)
y = KMeans(n_clusters=3) # 模型构建(类中心数为3)
y.fit(X) # 模型训练
kc = y.cluster_centers_ # 聚类中心
y_kmeans = y.predict(X) # 预测每个样本的聚类索引
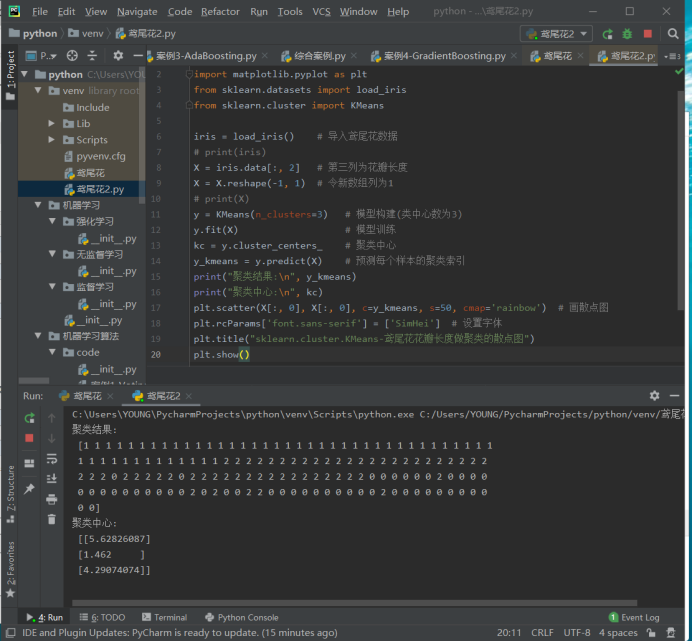
print("聚类结果:\n", y_kmeans)
print("聚类中心:\n", kc)
plt.scatter(X[:, 0], X[:, 0], c=y_kmeans, s=50, cmap='rainbow') # 画散点图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("sklearn.cluster.KMeans-鸢尾花花瓣长度做聚类的散点图")
plt.show()

(4)
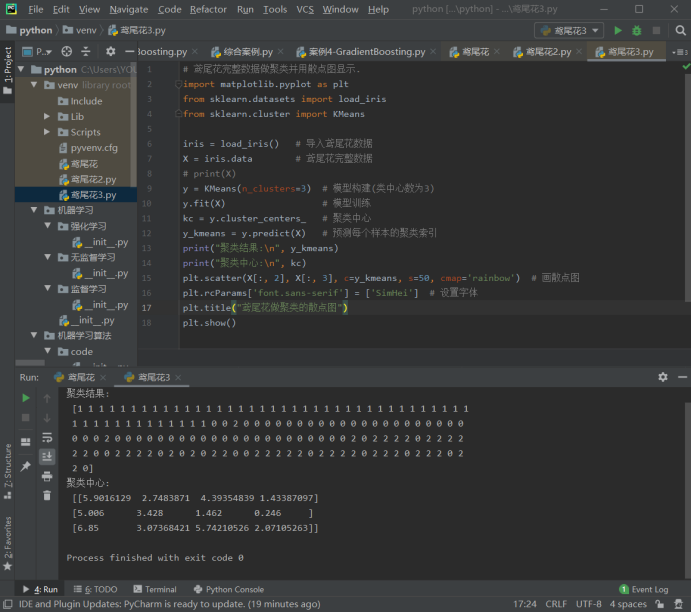
# 鸢尾花完整数据做聚类并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans iris = load_iris() # 导入鸢尾花数据
X = iris.data # 鸢尾花完整数据
# print(X)
y = KMeans(n_clusters=3) # 模型构建(类中心数为3)
y.fit(X) # 模型训练
kc = y.cluster_centers_ # 聚类中心
y_kmeans = y.predict(X) # 预测每个样本的聚类索引
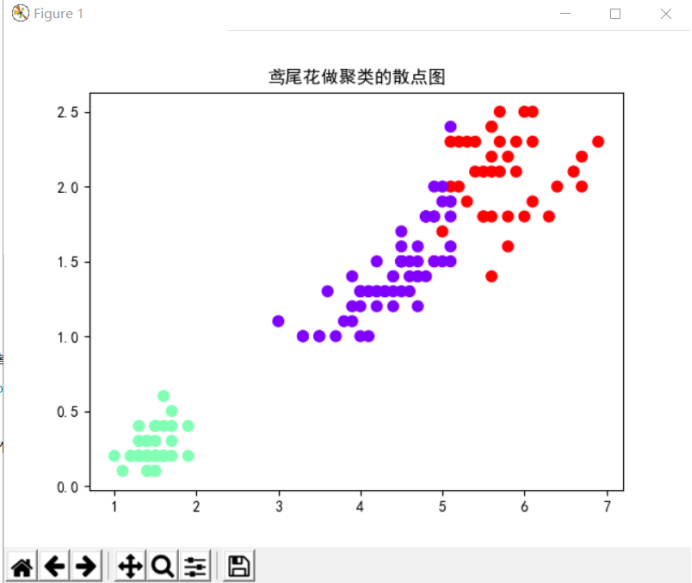
print("聚类结果:\n", y_kmeans)
print("聚类中心:\n", kc)
plt.scatter(X[:, 2], X[:, 3], c=y_kmeans, s=50, cmap='rainbow') # 画散点图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("鸢尾花做聚类的散点图")
plt.show()
(5)可以通过k均值算法进行库存分类,例如按销售活动分组库存或者按制造指标对库存进行分组,也可以用来识别不同类型的癌症特征。
作业3-k均值算法的更多相关文章
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- spark Bisecting k-means(二分K均值算法)
Bisecting k-means(二分K均值算法) 二分k均值(bisecting k-means)是一种层次聚类方法,算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二.之后选择能最大程 ...
随机推荐
- TCP/IP中的传输层协议TCP、UDP
TCP提供可靠的通信传输,而UDP则常用于让广播和细节控制交给应用的通信传输. 传输层协议根据IP数据报判断最终的接收端应用程序. TCP/IP的众多应用协议大多以客户端/服务端的形式运行.客户端是请 ...
- 《JAVA与模式》之责任链模式 【转载】
转载自java_my_life的博客 原文地址:http://www.cnblogs.com/java-my-life/archive/2012/05/28/2516865.html 在阎宏博士的&l ...
- C Cow XOR 奶牛异或
时间限制 : 10000 MS 空间限制 : 65536 KB 问题描述 农民约翰在喂奶牛的时候被另一个问题卡住了.他的所有N(1 <= N <= 100,000)个奶牛在他面前排成一 ...
- vagrant 入门案例 - 快速创建 Centos7
中文文档:http://tangbaoping.github.io/vagrant_doc_zh/v2/ 参考: https://blog.csdn.net/yjk13703623757/articl ...
- ServletConfig&ServletContext对比
上下文初始化参数(ServletContext) Servlet初始化参数(ServletConfig) 部署描述文件 在<web-app>元素中,但是不在具体的<servlet&g ...
- 整数回文数判断 Python
判断一个整数是否是回文数.回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数. 输入:123 输出:false 输入:-121 输出:false 输入:121 输出:true 输入:1 ...
- dotnet CLI工具是如何运行你的代码的
原文连接:https://mattwarren.org/2016/07/04/How-the-dotnet-CLI-tooling-runs-your-code/作者 Matt Warren.授权翻译 ...
- JMeter 接口测试 自动生成签名机制
在进行接口测试时,遇到接口进行了签名校验,为实现自动生成签名,经过一点研究终于成功. 首先,需要从前端获取 签名加密包 XXXsign.jar.. 建议将该jar包放在 jmeter lib 目录 ...
- Matlab入门(一)
1.常用命令 cd 显示或改变当前工作目录 load 加载指定文件的变量 dir 显示当前目录或指定目录下的文件 diary 日志文件命令 clc 清除工作窗中的所有显示内容 ! 调用 DOS 命令 ...
- python3(四)list tuple
# !/usr/bin/env python3 # -*- coding: utf-8 -*- # list是一种有序的集合,可以随时添加和删除其中的元素. classmates = ['Michae ...