Hadoop生态常用数据模型
 Hadoop生态常用数据模型
Hadoop生态常用数据模型
一、TextFile
二、SequenceFile
1、特性
2、存储结构
3、压缩结构与读取过程
4、读写操作
三、Avro
1、特性
2、数据类型
3、avro-tools应用
4、在Hive中使用Avro
5、在Spark中使用Avro
四、Parquet
1、特性
2、数据结构
3、Java API
4、Parquet On Spark
5、Parquet On Hive
五、RC&ORC
1、特性
2、存储结构RC (Record Columnar)ORC(Optimized Row Columnar)
3、ORC On Java
4、ORC On Hive
5、ORC On Spark
六、总结&应用场景
1、相同点
2、不同点
1). AVRO:
2). ORC:
3). Parquet:
3、如何选择平台兼容性:如何选择不同的数据格式不同数据格式最佳实践
一、TextFile
通常采用CSV、JSON等固度长度的纯文本格式
优点:
- 数据交换方便
- 易读
缺点:
- 数据存储量庞大
- 查询效率较低
- 不支持块压缩
二、SequenceFile
1、特性
按行存储键值对为二进制数据,以<Key,Value>形式序列化为二进制文件,HDFS自带
- 支持压缩和分割
- Hadoop中的小文件合并
- 常用于在MapReduce作业之间传输数据
SequenceFile中的Key和Value可以是任意类型的Writable(org.apache.hadoop.io.Writable)
Java API :org.apache.hadoop.io.SequenceFile
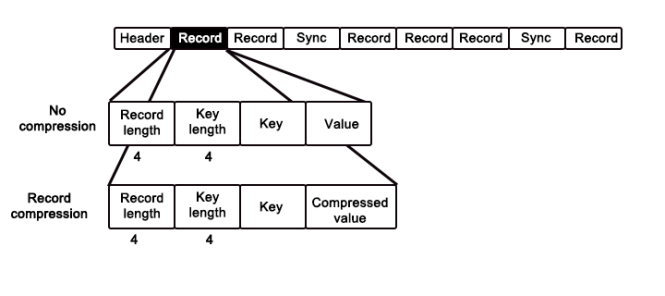
2、存储结构

- 记录结构 : 文件头——(多条记录+同步块)*

- 块结构 :文件头——(数据块+同步块)*
3、压缩结构与读取过程
- 记录级:io.seqfile.compression.type=RECORD
- 块级:io.seqfile.compression.type=BLOCK7
———————————————————————————————————————————
Q:记录级压缩是如何存储的 ?
A:记录级仅压缩value数据,按byte的偏移量索引数据。每个记录头为两个固定长度为4的数据量,一个代表本条Record的长度,一个代表Key值的长度,随后依次存储key值和压缩的value值。
模拟读取过程如下,首先偏移4获得本条记录长度r,然后偏移4获得key类型的长度k,再偏移k读入key的值,最后偏移到位置r,获取压缩后的value值,本条记录读完。
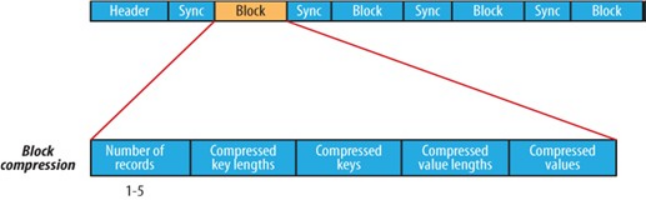
Q:块级压缩是如何存储的 ?
A:块级压缩同时压缩key和value,相同特性的记录将会被归为同一块。块头为定长4byte的代表本块所含的记录数目n、定长4byte的代表压缩后的key的长度的k、压缩后的key值组、定长4byte的达标压缩后的value的长度的v、压缩后的value值组。(n,k_length,k, v_length,v)
模拟读取过程如下,首先偏移4byte,获取当前块存储的记录数目n;偏移4byte,获取压缩后的key类型的长度k,再偏移n*k读入多个key值分别存储;偏移4byte,获取压缩后的value类型的长度v,再偏移n*v读入多个value值分别对应key值。
———————————————————————————————————————————
4、读写操作
读写操作
- SequenceFile.Writer (指定为块压缩)
- SequenceFile.Reader(读取时能够自动解压)
在Hive中使用SequenceFile
//1.方式一STORED AS sequencefile//2.方式二显示指定STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat'
在Spark中使用SequenceFile
val rdd=sc.sequenceFile[Int,String]("/tmp/myseqfile.seq") //装载rdd.saveAsSequenceFile("/tmp/seq") //存储
三、Avro
1、特性
Apache Avro也是一个数据序列化系统,数据定义以JSON格式存储,数据内容以二进制格式存储。
- 丰富的数据结构,被设计用于满足Schema Evolution
- Schema和数据分开保存
- 基于行存储
- 快速可压缩的二进制数据格式
- 容器文件用于持久化数据
- 自带远程过程调用RPC
- 动态语言可以方便地处理Avro数据
优点:
- 高扩展的Schema,为Schema Evolution而生。
- 数据压缩快
2、数据类型
基本数据类型:null, boolean, int, long, float, double, bytes, string
复杂数据类型:record、enum、array、map、union、fixed
//user.json{"name": "Alyssa", "favorite_number": 256, "favorite_color": "black"}{"name": "Ben", "favorite_number": 7, "favorite_color": "red"}{"name": "Charlie", "favorite_number": 12, "favorite_color": "blue"}//user.avsc定义了User对象的Schema{"namespace": "example.avro","type": "record","name": "User","fields": [{"name": "name", "type": "string"},{"name": "favorite_number", "type": "int"},{"name": "favorite_color", "type": "string"}]}
3、avro-tools应用
- 使用schema+data生成avro文件
java -jar avro-tools-1.8.2.jar fromjson --schema-file user.avsc user.json > user.avrojava -jar avro-tools-1.8.2.jar fromjson --codec snappy --schema-file user.avsc user.json > user.avro
- avro转json
java -jar avro-tools-1.8.2.jar tojson user.avrojava -jar avro-tools-1.8.2.jar tojson user.avro --pretty
- 获取avro元数据
java -jar avro-tools-1.8.2.jar getmeta user.avro
4、在Hive中使用Avro
create table CUSTOMERSrow format serde 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'stored as inputformat 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'outputformat 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'tblproperties ('avro.schema.literal'='{"name": "customer", "type": "record","fields": [{"name":"firstName", "type":"string"}, {"name":"lastName", "type":"string"},{"name":"age", "type":"int"}, {"name":"salary", "type":"double"},{"name":"department", "type":"string"}, {"name":"title", "type":"string"},{"name": "address", "type": "string"}]}');//外部表create external table user_avro_ext(name string,favorite_number int,favorite_color string)stored as avrolocation '/tmp/avro';
5、在Spark中使用Avro
拷贝spark-avro_2.11-4.0.0.jar包到Spark目录下的jars目录下。
//需要spark-avroimport com.databricks.spark.avro._//装载val df = spark.read.format("com.databricks.spark.avro").load("input dir")//存储df.filter("age > 5").write.format("com.databricks.spark.avro").save("output dir")
四、Parquet
Apache Parquet是Hadoop生态系统中任何项目都可用的列式存储格式
- Parquet是Spark SQL默认数据源
1、特性
- Spark SQL的默认数据源
- 列式存储,写入性能差,但是可以按需读取列
- 压缩编码,降低空间占用
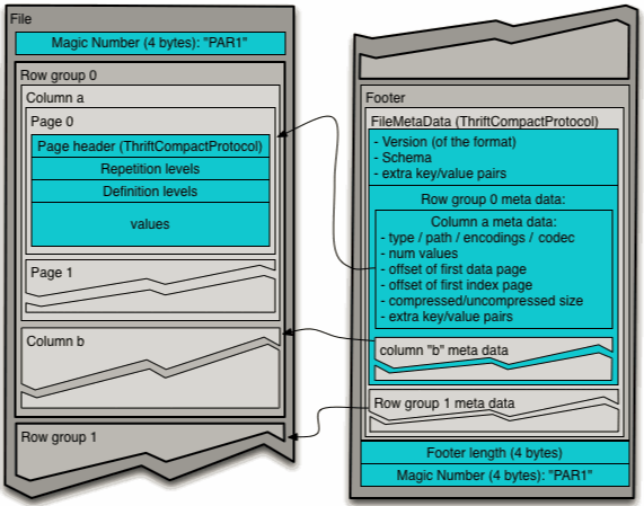
2、数据结构
按照行将数据物理上划分为多个组,每一个行组包含一定的行数,通常行组大小等于HDFS块大小
- 行组Row Group
- 列块Column Chunk
- 页Page
3、Java API
MessageType schema=MessageTypeParser.parseMessageType(schemaStr);ParquetWriter<Group> writer=ExampleParquetWriter.builder(file).withType(schema).build();SimpleGroupFactory groupFactory= new SimpleGroupFactory(schema);Group group1=groupFactory.newGroup();group1.add("name","jason");group1.add("age",9);gropu1.addGroup("family").append("father","XXX").append("mother","XXX");writer.write(group1);//ReaderParquetReader<Group> reader = ParquetReader.builder(new GroupReadSupport(), file).build();SimpleGroup group =(SimpleGroup) reader.read();System.out.println("schema:" +group.getType().toString());System.out.println(group.toString());
4、Parquet On Spark
val df=sc.makeRDD(Seq(("jason",19),("tom",18))).toDF("name","age")//写parquet文件df.write.save("/tmp/parquet")//读parquet文件val df1=spark.read.load("/tmp/parquet")df1.show如果发生数据的模式演化 Schema Evolution ,即新数据的Schema发生变化。可以使用option(mergeSchema,true)读入,但是非常耗费资源。
5、Parquet On Hive
create external table parquet_table(name string,age int)stored as parquetlocation '/tmp/parquet';
五、RC&ORC
1、特性
- 存储行集合,并在集合中以列格式存储行数据
- 引入轻量级索引,允许跳过不相关的行块
- 可分割:允许并行处理行集合
- 可压缩
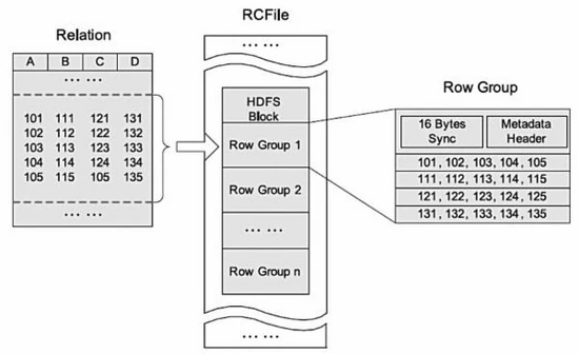
2、存储结构
RC (Record Columnar)
- 集行存储与列存储的优点于一身
- 设计思想与Parquet类似,先按行水平切割为多个行组,再对每个行组内的数据按列存储
ORC(Optimized Row Columnar)
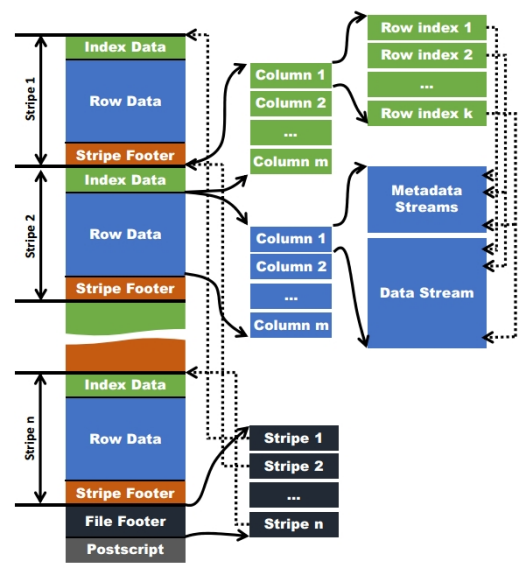
Stripe
- 每个ORC文件首先会被横向切分成多个Stripe
- 每个stripe默认的大小是250MB
- 每个stripe由多组(Row Groups)行数据组成
IndexData
- 保存了该stripe上数据的位置,总行数
RowData
- 以stream的形式保存数据
Stripe Footer
- 包含该stripe统计结果:Max,Min,count等信息
FileFooter
- 该表的统计结果
- 各个Stripe的位置信息
Postscript
- 该表的行数,压缩参数,压缩大小,列等信息
3、ORC On Java
TypeDescription schema = TypeDescription.fromString("struct<name:string,age:int>");Writer writer = OrcFile.createWriter(file,OrcFile.writerOptions(conf).setSchema(schema));VectorizedRowBatch batch=schema.createRowBatch();BytesColumnVector name =(BytesColumnVector) batch.cols[0];name.setVal(0,"jason".getBytes());...//Reader reader=OrcFile.createReader(file,OrcFile.readerOptions(conf));RecordReader rows = reader.rows();VectorizedRowBatch batch = reader.getSchema().createRowBatch();while (rows.nextBatch(batch)) {...}
4、ORC On Hive
create external table user_orc_ext(name string,age int)stored as orclocation '/tmp/users/orc'
5、ORC On Spark
val df=spark.read.format("orc").load("/tmp/user.orc")df.show
六、总结&应用场景
| File Type | Splittable | Block Compressible | Schema Evolution | Hive | Spark | Remark |
|---|---|---|---|---|---|---|
| Text/CSV | Yes | No | No | Yes | Yes | |
| XML/JSON | No | No | Yes | ? | Yes | |
| AvroFile | Yes | Yes | Yes | Yes | Yes | 模式演化好 |
| SequenceFile | Yes | Yes | Yes | Yes | Yes | |
| RCFile | Yes | Yes | No | Yes | Yes | Columnar Storage |
| ORCFile | Yes | Yes | No | Yes | Yes | Columnar Storage |
| ParquetFile | Yes | Yes | Yes | Yes | Yes | Columnar Storage |
1、相同点
1、基于Hadoop文件系统优化出的存储结构
2、提供高效的压缩
3、二进制存储格式
4、文件可分割,具有很强的伸缩性和并行处理能力
5、使用schema进行自我描述
6、属于线上格式,可以在Hadoop节点之间传递数据
2、不同点
1). AVRO:
- 主要为行存储
- 设计的主要目标是为了满足schema evolution
- schema和数据分开保存(同一目录,不同文件)
2). ORC:
- 面向列的存储格式
- 由Hadoop中RC files 发展而来,比RC file更大的压缩比,和更快的查询速度
- Schema 存储在footer中
- 不支持schema evolution
- 支持事务(ACID)
- 为hive而生,在许多non-hive MapReduce的大数据组件中不支持使用
- 高度压缩比并包含索引
3). Parquet:
- 与ORC类似,基于Google dremel
- Schema 存储在footer
- 列式存储
- 高度压缩比并包含索引
- 相比ORC的局限性,parquet支持的大数据组件范围更广
3、如何选择
- Avro——查询随时间变化的数据集(模式演变)
- Parquet ——适合在宽表上查询少数列(列式存储)
- Parquet & ORC以牺牲写性能为代价优化读取性能(列式存储)
- TextFile 读起来很慢(逐行读取)
- Hive 查询快慢:ORC >>Parquet>>Text>>Avro>>SequenceFile
平台兼容性:
- ORC常用于Hive、Presto;
- Parquet常用于Impala、Drill、Spark、Arrow;
- Avro常用于Kafka、Druid。
如何选择不同的数据格式
考虑因素:
- 读写速度
- 按行读多还是按列读多
- 是否支持文件分割
- 压缩率
- 是否支持schema evolution
不同数据格式最佳实践
- 读取少数列可以选择面向列存储的ORC或者Parquet
- 如果需要读取的列比较多,选择AVRO更优
- 如果schema 变更频繁最佳选择avro
- 实际上随着版本不断更新,现在parquet和orc都在一定程度上支持schema evolution,比如最后面加列
- ORC的查询性能优于Parquet
Hadoop生态常用数据模型的更多相关文章
- [转]hadoop hdfs常用命令
FROM : http://www.2cto.com/database/201303/198460.html hadoop hdfs常用命令 hadoop常用命令: hadoop fs 查看H ...
- 安装高可用Hadoop生态 (一 ) 准备环境
为了学习Hadoop生态的部署和调优技术,在笔记本上的3台虚拟机部署Hadoop集群环境,要求保证HA,即主要服务没有单点故障,能够执行最基本功能,完成小内存模式的参数调整. 1. 准备环境 1 ...
- 基于Hadoop生态SparkStreaming的大数据实时流处理平台的搭建
随着公司业务发展,对大数据的获取和实时处理的要求就会越来越高,日志处理.用户行为分析.场景业务分析等等,传统的写日志方式根本满足不了业务的实时处理需求,所以本人准备开始着手改造原系统中的数据处理方式, ...
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别 Pig
Hadoop生态上几个技术的关系与区别:hive.pig.hbase 关系与区别 Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎自己慢慢退出pig的 ...
- Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现. (1)0.20.0~0.20.2: Hadoop的0.20分支非常稳定,虽然看起来有些落后,但是经过生产环境考验,是 Hadoop历史上 ...
- Hadoop生态系统介绍
Hadoop生态系统Hadoop1.x 的各项目介绍1. HDFS2. MapReduce3. Hive4. Pig5. Mahout6. ZooKeeper7. HBase8. Sqoop9. Fl ...
- Hadoop生态新增列式存储系统Kudu
Hadoop生态系统发展到现在,存储层主要由HDFS和HBase两个系统把持着,一直没有太大突破.在追求高吞吐的批处理场景下,我们选用HDFS,在追求低延迟,有随机读写需求的场景下,我们选用H ...
- Hadoop平台常用配置及优化建议
当发现作业运行效率不理想时,需要对作业执行进行性能监测,以及对作业本身.集群平台进行优化.优化后的集群可能最大化利用硬件资源,从而提高作业的执行效率.本文记录了在hadoop集群平台搭建以及作业运行过 ...
- Hadoop中常用的InputFormat、OutputFormat(转)
Hadoop中的Map Reduce框架依赖InputFormat提供数据,依赖OutputFormat输出数据,每一个Map Reduce程序都离不开它们.Hadoop提供了一系列InputForm ...
随机推荐
- AS中的协议---IGP、EGP(BGP)
查考文档: http://www.360doc.com/content/18/0327/23/11935121_740740341.shtml 自治系统(AS)就是指在网络中处于同一个控制下的路由器和 ...
- Object类的常见方法总结
♧ Object类是比较特殊的类,它是所有类的父类.主要提供了11个方法(JDK 1.8为例): /** * native方法,用于返回当前运行时对象的Class对象,使用final关键字修饰,子类不 ...
- mysql高级day3
Mysql高级-day03 1. 应用优化 前面章节,我们介绍了很多数据库的优化措施.但是在实际生产环境中,由于数据库本身的性能局限,就必须要对前台的应用进行一些优化,来降低数据库的访问压力. 1.1 ...
- python工业互联网应用实战5—Django Admin 编辑界面和操作
1.1. 编辑界面 默认任务的编辑界面,对于model属性包含"choices"会自动显示下来列表供选择,"datetime"数据类型也默认提供时间选择组件,如 ...
- 基于C#/Winform实现的Win8MetroLoading动画
非常喜欢Metro风格的界面,所以想模仿一下一些UI效果的实现,网上找到了很多,但都是CSS3,WPF等实现,对于XAML和CSS3一窍不通,无奈下只有自己开始写. 下面是源码: 1 using Sy ...
- 黑客整人代码,vbS整人代码大全(强制自动关机、打开无数计算器、无限循环等)
vbe与vbs整人代码大全,包括强制自动关机.打开无数计算器.无限循环等vbs整人代码,感兴趣的朋友参考下.vbe与vbs整人代码例子:set s=createobject("wscript ...
- 查看文件MD5值
Windows 打开命令窗口(Win+R),然后输入cmd ·输入命令certutil -hashfile 文件绝对路径 MD5 Linux MD5算法常常被用来验证网络文件传输的完整性,防止文件被人 ...
- mysql查询太慢,我们如何进行性能优化?
老刘是即将找工作的研究生,自学大数据开发,一路走来,感慨颇深,网上大数据的资料良莠不齐,于是想写一份详细的大数据开发指南.这份指南把大数据的[基础知识][框架分析][源码理解]都用自己的话描述出来,让 ...
- 【noi 2.6_9281】技能树(DP)
题意:要求二叉树中每个节点的子节点数为0或2,求有N个节点高度为M的不同的二叉树有多少个(输出 mod 9901 后的结果). 解法:f[i][j]表示高度为i的有j个节点的二叉树个数.同上题一样,把 ...
- P2062 分队问题(DP)
题目描述 给定n个选手,将他们分成若干只队伍.其中第i个选手要求自己所属的队伍的人数大等于a[i]人. 在满足所有选手的要求的前提下,最大化队伍的总数. 注:每个选手属于且仅属于一支队伍. 输入输出格 ...