SQL优化之SQL 进阶技巧(上)
由于工作需要,最近做了很多 BI 取数的工作,需要用到一些比较高级的 SQL 技巧,总结了一下工作中用到的一些比较骚的进阶技巧,特此记录一下,以方便自己查阅,主要目录如下:
SQL 的书写规范 SQL 的一些进阶使用技巧 SQL 的优化方法
SQL 的书写规范
在介绍一些技巧之前,有必要强调一下规范,这一点我发现工作中经常被人忽略,其实遵循好的规范可读性会好很多,应该遵循哪些规范呢
1、 表名要有意义,且标准 SQL 中规定表名的第一个字符应该是字母。
2、注释,有单行注释和多行注释,如下
-- 单行注释
-- 从SomeTable中查询col_1
SELECT col_1
FROM SomeTable;
/*
多行注释
从 SomeTable 中查询 col_1
*/
SELECT col_1
FROM SomeTable;多行注释很多人不知道,这种写法不仅可以用来添加真正的注释,也可以用来注释代码,非常方便
3、缩进
就像写 Java,Python 等编程语言一样 ,SQL 也应该有缩进,良好的缩进对提升代码的可读性帮助很大,以下分别是好的缩进与坏的缩进示例
-- 好的缩进
SELECT col_1,
col_2,
col_3,
COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = ( SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100 )
GROUP BY col_1,
col_2,
col_3
-- 坏的示例
SELECT col1_1, col_2, col_3, COUNT(*)
FROM tbl_A
WHERE col1_1 = 'a'
AND col1_2 = (
SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100
) GROUP BY col_1, col_2, col_3
4、空格
代码中应该适当留有一些空格,如果一点不留,代码都凑到一起, 逻辑单元不明确,阅读的人也会产生额外的压力,以下分别是是好的与坏的示例
-- 好的示例
SELECT col_1
FROM tbl_A A, tbl_B B
WHERE ( A.col_1 >= 100 OR A.col_2 IN ( 'a', 'b' ) )
AND A.col_3 = B.col_3;
-- 坏的示例
SELECT col_1
FROM tbl_A A,tbl_B B
WHERE (A.col_1>=100 OR A.col_2 IN ('a','b'))
AND A.col_3=B.col_3;
4、大小写
关键字使用大小写,表名列名使用小写,如下
SELECT col_1, col_2, col_3,
COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = ( SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100 )
GROUP BY col_1, col_2, col_3花了这么多时间强调规范,有必要吗,有!好的规范让代码的可读性更好,更有利于团队合作,之后的 SQL 示例都会遵循这些规范。
SQL 的一些进阶使用技巧
一、巧用 CASE WHEN 进行统计
来看看如何巧用 CASE WHEN 进行定制化统计,假设我们有如下的需求,希望根据左边各个市的人口统计每个省的人口
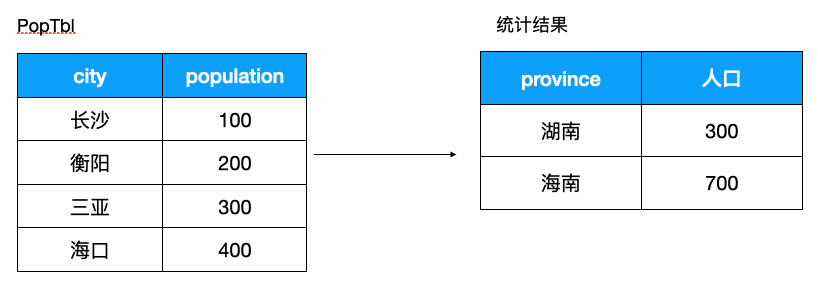
使用 CASE WHEN 如下
SELECT CASE pref_name
WHEN '长沙' THEN '湖南'
WHEN '衡阳' THEN '湖南'
WHEN '海口' THEN '海南'
WHEN '三亚' THEN '海南'
ELSE '其他' END AS district,
SUM(population)
FROM PopTbl
GROUP BY district;二、巧用 CASE WHEN 进行更新
现在某公司员人工资信息表如下:
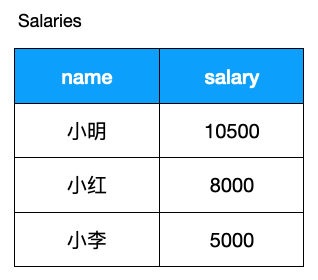
现在公司出台了一个奇葩的规定
对当前工资为 1 万以上的员工,降薪 10%。 对当前工资低于 1 万的员工,加薪 20%。
一些人不假思索可能写出了以下的 SQL:
--条件1
UPDATE Salaries
SET salary = salary * 0.9 WHERE salary >= 10000;
--条件2
UPDATE Salaries
SET salary = salary * 1.2
WHERE salary < 10000;这么做其实是有问题的, 什么问题,对小明来说,他的工资是 10500,执行第一个 SQL 后,工资变为 10500 * 0.9 = 9450, 紧接着又执行条件 2, 工资变为了 9450 * 1.2 = 11340,反而涨薪了!
如果用 CASE WHEN 可以解决此类问题,如下:
UPDATE Salaries
SET salary = CASE WHEN salary >= 10000 THEN salary * 0.9
WHEN salary < 10000 THEN salary * 1.2
ELSE salary END;三、巧用 HAVING 子句
一般 HAVING 是与 GROUP BY 结合使用的,但其实它是可以独立使用的, 假设有如下表,第一列 seq 叫连续编号,但其实有些编号是缺失的,怎么知道编号是否缺失呢,
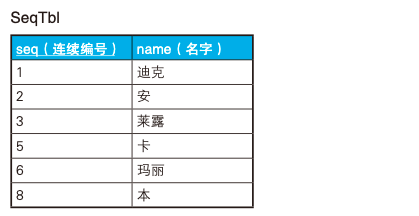
用 HAVING 表示如下:
SELECT '存在缺失的编号' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq);四、自连接
针对相同的表进行的连接被称为“自连接”(self join),这个技巧常常被人们忽视,其实是有挺多妙用的
1、删除重复行
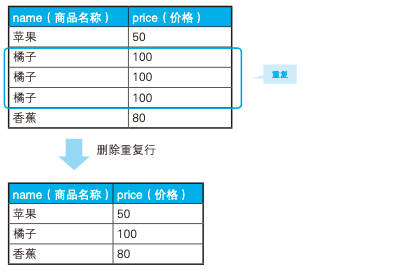
上图中有三个橘子,需要把这些重复的行给删掉,用如下自连接可以解决:
DELETE FROM Products P1
WHERE id < ( SELECT MAX(P2.id)
FROM Products P2
WHERE P1.name = P2.name
AND P1.price = P2.price ); 2、排序
在 db 中,我们经常需要按分数,人数,销售额等进行排名,有 Oracle, DB2 中可以使用 RANK 函数进行排名,不过在 MySQL 中 RANK 函数未实现,这种情况我们可以使用自连接来实现,如对以下 Products 表按价格高低进行排名
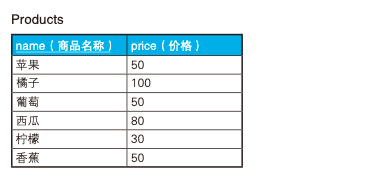
使用自连接可以这么写:
-- 排序从 1 开始。如果已出现相同位次,则跳过之后的位次
SELECT P1.name,
P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price > P1.price) + 1 AS rank_1
FROM Products P1
ORDER BY rank_1;结果如下:
name price rank
----- ------ ------
橘子 100 1
西瓜 80 2
苹果 50 3
葡萄 50 3
香蕉 50 3
柠檬 30 6五、巧用 COALESCE 函数
此函数作用返回参数中的第一个非空表达式,假设有如下商品,我们重新格式化一样,如果 city 为 null,代表商品不在此城市发行,但我们在展示结果的时候不想展示 null,而想展示 'N/A', 可以这么做:
SELECT
COALESCE(city, 'N/A')
FROM
customers;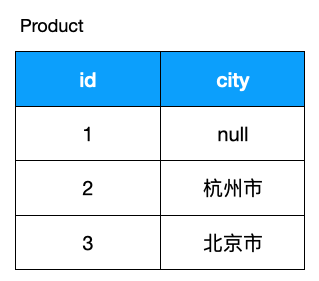
SQL 性能优化技巧
一、参数是子查询时,使用 EXISTS 代替 IN
如果 IN 的参数是(1,2,3)这样的值列表时,没啥问题,但如果参数是子查询时,就需要注意了。比如,现在有如下两个表:
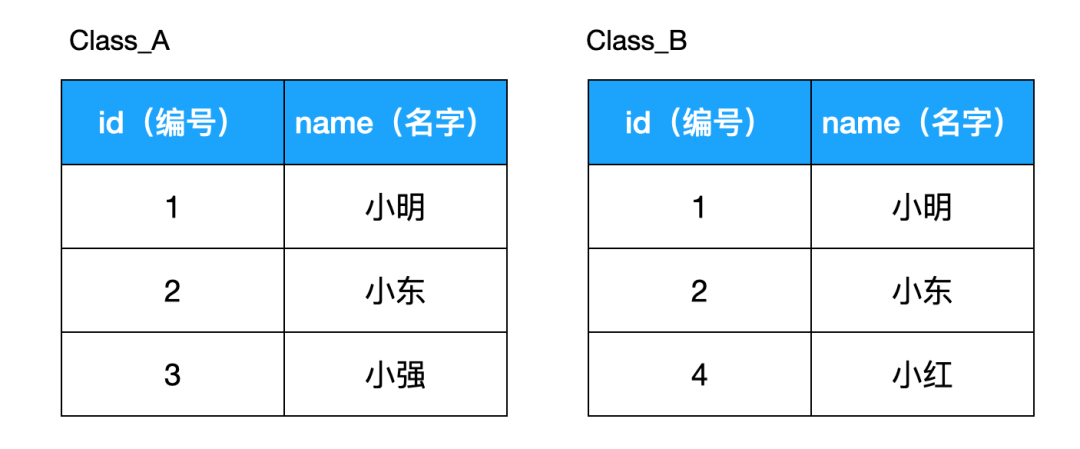
现在我们要查出同时存在于两个表的员工,即田中和铃木,则以下用 IN 和 EXISTS 返回的结果是一样,但是用 EXISTS 的 SQL 会更快:
-- 慢
SELECT *
FROM Class_A
WHERE id IN (SELECT id
FROM CLASS_B);
-- 快
SELECT *
FROM Class_A A
WHERE EXISTS
(SELECT *
FROM Class_B B
WHERE A.id = B.id);为啥使用 EXISTS 的 SQL 运行更快呢,有两个原因
可以`用到索引,如果连接列 (id) 上建立了索引,那么查询 Class_B 时不用查实际的表,只需查索引就可以了。 如果使用 EXISTS,那么只要查到一行数据满足条件就会终止查询, 不用像使用 IN 时一样扫描全表。在这一点上 NOT EXISTS 也一样
另外如果 IN 后面如果跟着的是子查询,由于 SQL 会先执行 IN 后面的子查询,会将子查询的结果保存在一张临时的工作表里(内联视图),然后扫描整个视图,显然扫描整个视图这个工作很多时候是非常耗时的,而用 EXISTS 不会生成临时表。
当然了,如果 IN 的参数是子查询时,也可以用连接来代替,如下:
-- 使用连接代替 IN SELECT A.id, A.name
FROM Class_A A INNER JOIN Class_B B ON A.id = B.id;用到了 「id」列上的索引,而且由于没有子查询,也不会生成临时表
二、避免排序
SQL 是声明式语言,即对用户来说,只关心它能做什么,不用关心它怎么做。这样可能会产生潜在的性能问题:排序,会产生排序的代表性运算有下面这些
GROUP BY 子句 ORDER BY 子句 聚合函数(SUM、COUNT、AVG、MAX、MIN) DISTINCT 集合运算符(UNION、INTERSECT、EXCEPT) 窗口函数(RANK、ROW_NUMBER 等)
如果在内存中排序还好,但如果内存不够导致需要在硬盘上排序上的话,性能就会急剧下降,所以我们需要减少不必要的排序。怎样做可以减少排序呢。
1、 使用集合运算符的 ALL 可选项
SQL 中有 UNION,INTERSECT,EXCEPT 三个集合运算符,默认情况下,这些运算符会为了避免重复数据而进行排序,对比一下使用 UNION 运算符加和不加 ALL 的情况:
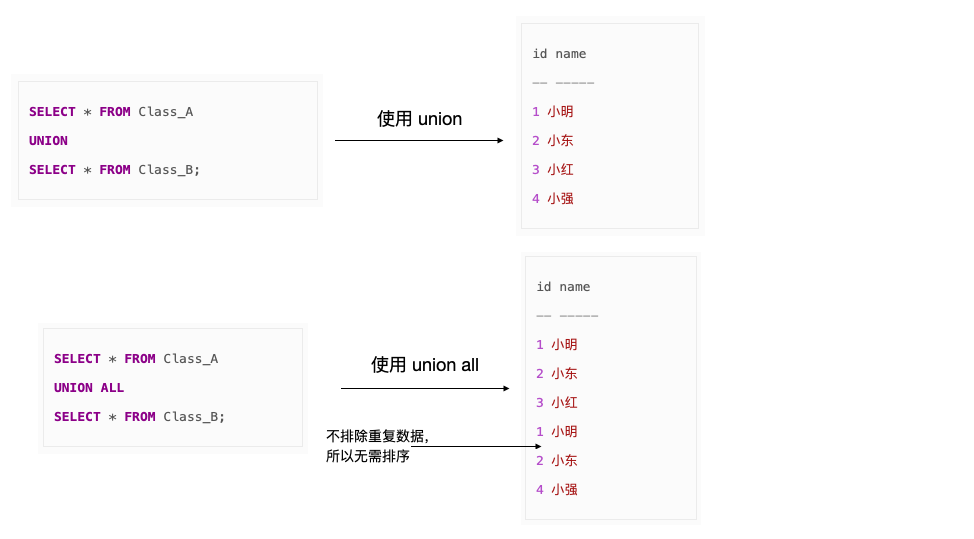
注意:加 ALL 是优化性能非常有效的手段,不过前提是不在乎结果是否有重复数据。
2、使用 EXISTS 代表 DISTINCT
为了排除重复数据, DISTINCT 也会对结果进行排序,如果需要对两张表的连接结果进行去重,可以考虑用 EXISTS 代替 DISTINCT,这样可以避免排序。
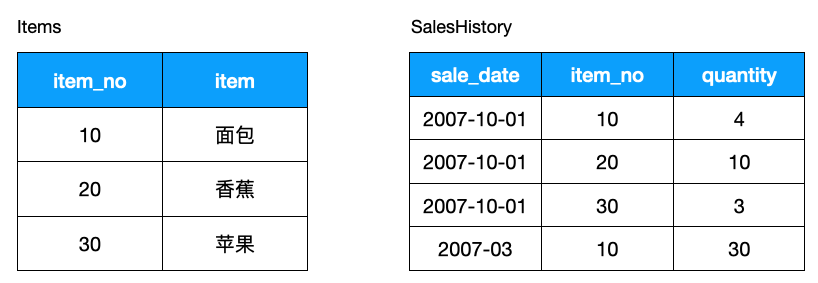
如何找出有销售记录的商品,使用如下 DISTINCT 可以:
SELECT DISTINCT I.item_no
FROM Items I INNER JOIN SalesHistory SH
ON I. item_no = SH. item_no;不过更好的方式是使用 EXISTS:
SELECT item_no FROM Items I
WHERE EXISTS
(SELECT *
FROM SalesHistory SH
WHERE I.item_no = SH.item_no);既用到了索引,又避免了排序对性能的损耗。
三、在极值函数中使用索引(MAX/MIN)
使用 MAX/ MIN 都会对进行排序,如果参数字段上没加索引会导致全表扫描,如果建有索引,则只需要扫描索引即可,对比如下
-- 这样写需要扫描全表
SELECT MAX(item)
FROM Items;
-- 这样写能用到索引
SELECT MAX(item_no)
FROM Items;注意:极值函数参数推荐为索引列中并不是不需要排序,而是优化了排序前的查找速度(毕竟索引本身就是有序排列的)。
四、能写在 WHERE 子句里的条件不要写在 HAVING 子句里
下列 SQL 语句返回的结果是一样的:
-- 聚合后使用 HAVING 子句过滤
SELECT sale_date, SUM(quantity)
FROM SalesHistory GROUP BY sale_date
HAVING sale_date = '2007-10-01';
-- 聚合前使用 WHERE 子句过滤
SELECT sale_date, SUM(quantity)
FROM SalesHistory
WHERE sale_date = '2007-10-01'
GROUP BY sale_date;使用第二条语句效率更高,原因主要有两点
使用 GROUP BY 子句进行聚合时会进行排序,如果事先通过 WHERE 子句能筛选出一部分行,能减轻排序的负担 在 WHERE 子句中可以使用索引,而 HAVING 子句是针对聚合后生成的视频进行筛选的,但很多时候聚合后生成的视图并没有保留原表的索引结构
五、在 GROUP BY 子句和 ORDER BY 子句中使用索引
GROUP BY 子句和 ORDER BY 子句一般都会进行排序,以对行进行排列和替换,不过如果指定带有索引的列作为这两者的参数列,由于用到了索引,可以实现高速查询,由于索引是有序的,排序本身都会被省略掉
六、使用索引时,条件表达式的左侧应该是原始字段
假设我们在 col 列上建立了索引,则下面这些 SQL 语句无法用到索引
SELECT *
FROM SomeTable
WHERE col * 1.1 > 100;
SELECT *
FROM SomeTable
WHERE SUBSTR(col, 1, 1) = 'a';以上第一个 SQL 在索引列上进行了运算, 第二个 SQL 对索引列使用了函数,均无法用到索引,正确方式是把列单独放在左侧,如下:
SELECT *
FROM SomeTable
WHERE col_1 > 100 / 1.1;当然如果需要对此列使用函数,则无法避免在左侧运算,可以考虑使用函数索引,不过一般不推荐随意这么做。
七、尽量避免使用否定形式
如下的几种否定形式不能用到索引:
<> != NOT IN
所以以下 了SQL 语句会导致全表扫描
SELECT *
FROM SomeTable
WHERE col_1 <> 100;可以改成以下形式
SELECT *
FROM SomeTable
WHERE col_1 > 100 or col_1 < 100;八、进行默认的类型转换
假设 col 是 char 类型,则推荐使用以下第二,三条 SQL 的写法,不推荐第一条 SQL 的写法
× SELECT * FROM SomeTable WHERE col_1 = 10;
○ SELECT * FROM SomeTable WHERE col_1 = '10';
○ SELECT * FROM SomeTable WHERE col_1 = CAST(10, AS CHAR(2));虽然第一条 SQL 会默认把 10 转成 '10',但这种默认类型转换不仅会增加额外的性能开销,还会导致索引不可用,所以建议使用的时候进行类型转换。
九、减少中间表
在 SQL 中,子查询的结果会产生一张新表,不过如果不加限制大量使用中间表的话,会带来两个问题,一是展示数据需要消耗内存资源,二是原始表中的索引不容易用到,所以尽量减少中间表也可以提升性能。
十、灵活使用 HAVING 子句
这一点与上面第八条相呼应,对聚合结果指定筛选条件时,使用 HAVING 是基本的原则,可能一些工程师会倾向于使用下面这样的写法:
SELECT *
FROM (SELECT sale_date, MAX(quantity) AS max_qty
FROM SalesHistory
GROUP BY sale_date) TMP
WHERE max_qty >= 10;虽然上面这样的写法能达到目的,但会生成 TMP 这张临时表,所以应该使用下面这样的写法:
SELECT sale_date, MAX(quantity)
FROM SalesHistory
GROUP BY sale_date
HAVING MAX(quantity) >= 10;HAVING 子句和聚合操作是同时执行的,所以比起生成中间表后再执行 HAVING 子句,效率会更高,代码也更简洁
10、需要对多个字段使用 IN 谓词时,将它们汇总到一处
一个表的多个字段可能都使用了 IN 谓词,如下:
SELECT id, state, city
FROM Addresses1 A1
WHERE state IN (SELECT state
FROM Addresses2 A2
WHERE A1.id = A2.id)
AND city IN (SELECT city
FROM Addresses2 A2
WHERE A1.id = A2.id);这段代码用到了两个子查询,也就产生了两个中间表,可以像下面这样写
SELECT *
FROM Addresses1 A1
WHERE id || state || city
IN (SELECT id || state|| city
FROM Addresses2 A2);这样子查询不用考虑关联性,没有中间表产生,而且只执行一次即可。
总结
本文一开始花了挺大的篇幅来讲解 SQL 的规范,请大家务必重视这部分内部,良好的规范有利于团队协作,对于代码的阅读也比较友好。
之后介绍了一些 SQL 的比较高级的用法,巧用这些技巧确实能达到事半功倍的效果,由于本文篇幅有限只是介绍了一部分,下篇我们会再介绍一些其他的技巧,敬请期待哦
相关文章
SQL优化之SQL 进阶技巧(上)的更多相关文章
- SQL优化之SQL 进阶技巧(下)
上文( SQL优化之SQL 进阶技巧(上) )我们简述了 SQL 的一些进阶技巧,一些朋友觉得不过瘾,我们继续来下篇,再送你 10 个技巧 一. 使用延迟查询优化 limit [offset], [r ...
- [terry笔记]Oracle SQL 优化之sql tuning advisor (STA)
前言:经常可以碰到优化sql的需求,开发人员直接扔过来一个SQL让DBA优化,然后怎么办? 当然,经验丰富的DBA可以从各种方向下手,有时通过建立正确索引即可获得很好的优化效果,但是那些复杂SQL错综 ...
- SQL优化(SQL TUNING)可大幅提升性能的实战技巧之一——让计划沿着索引跑
我们进行SQL优化时,经常会碰到对大量数据集进行排序,然后从排序后的集合取前部分结果的需求,这种情况下,当我们按照常规思路去写SQL时,系统会先读取过滤获得所有集合,然后进行排序,再从排序结果取出极少 ...
- SQL优化- 数据库SQL优化——使用EXIST代替IN
数据库SQL优化——使用EXIST代替IN 1,查询进行优化,应尽量避免全表扫描 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引 . 尝试下面的 ...
- Oracle12c中SQL优化(SQL TUNING)新特性之SQL计划指令
SQL计划指令是Oracle12c中自适应查询优化的功能之一.SQL计划指令就像“额外的提醒” ,用以提醒优化器你先前选择了的计划并不是最优的,典型的是因为错误的势评估.错误的势评估往往是由统计信息缺 ...
- Oracle自带工具sql优化集-SQL Tuning Advisor (使用心得体会)
如何有效的诊断和监控高负载的SQL对于DBA来说并非是件容易的事情,对SQL语句手工调优需要很多的经验和技巧, 结合个人经验常见如下问题: . 对SQL语句本身进行优化以便获得更优的 ...
- oracle11g中SQL优化(SQL TUNING)新特性之SQL Plan Management(SPM)
1. 简介 Oracle Database11gR1引进了SQL PlanManagement(简称SPM),一套允许DBA捕获和保持任意SQL语句执行计划最优的新工具,这样,限制了刷新优化器统计 ...
- 【SQL优化】SQL优化工具
SQLAdvisor 是由美团点评公司北京DBA团队开发维护的 SQL 优化工具:输入SQL,输出索引优化建议. 它基于 MySQL 原生词法解析,再结合 SQL 中的 where 条件以及字段选择度 ...
- SQL优化工具 - SQL Server Profiler与数据库引擎优化顾问
最近项目做到几千个学生分别去人脸识别记录(目前约630000行)中查询最后一次记录,可想而知性能这块是个麻烦.于是乎,GET到了SQL Server Profiler和数据库引擎优化顾问这俩工SHEN ...
随机推荐
- soloPi安装使用
SoloPi脚本转化器正式发布,支持转化为 Appium 与 Macaca 脚本:https://github.com/soloPi/SoloPi-Convertor,脚本转化器使用教程: https ...
- graph generation model
Generative Graph Models 第八章传统的图生成方法> The previous parts of this book introduced a wide variety of ...
- C++在C的基础上改进了哪些细节
C++ 是在C语言的基础上改进的,C语言的很多语法在 C++ 中依然广泛使用,例如: C++ 仍然使用 char.short.int.long.float.double 等基本数据类型: ...
- unicode与编码的关系
参考链接先贴上来:https://blog.csdn.net/humadivinity/article/details/79403625https://www.cnblogs.com/kevin2ch ...
- 20181301刘天宁 MyOD
一.题目要求: 1.复习c文件处理内容编写myod.c 2.用myod XXX实现Linux下od -tx -tc XXX的功能 3.main与其他分开,制作静态库和动态库 4.编写Makefile ...
- 用Matlab对导出的数据进行可视化
我这里是MapReduce导出的数据,MapReduce导出的数据中,Key和Value之间用制表符分隔的,可以直接作为表格型数据进行操作,复制一下导出的数据 1. 首先在Matlab工作区创建一个元 ...
- 23longest-consecutive-sequence
题目描述 给定一个无序的整数类型数组,求最长的连续元素序列的长度. 例如: 给出的数组为[100, 4, 200, 1, 3, 2], 最长的连续元素序列为[1, 2, 3, 4]. 返回这个序列的长 ...
- 腾讯云对象存储COS新品发布——智能分层存储,自动优化您的存储成本
近日,腾讯云正式发布对象存储新品--智能分层存储,能够根据用户数据的访问模式,自动地转换数据的冷热层级,为用户提供与标准存储一致的低延迟和高吞吐的产品体验,同时具有更低的存储成本. 熟悉数据存储的用户 ...
- 后端狗的Vue学习历程(一) - demo示例与基本逻辑语法
目录 demo的三部分结构 判断:v-if.v-else-if.v-else 循环:v-for 事件绑定 v-on:eventType 内容输入的双向绑定v-model 源码:Github demo的 ...
- 手把手教你使用rpm部署ceph集群
环境准备 1.在运行 Ceph 守护进程的节点上创建一个普通用户,ceph-deploy 会在节点安装软件包,所以你创建的用户需要无密码 sudo 权限.如果使用root可以忽略. 为赋予用户所有权限 ...