Python读取word文档内容
1,利用python读取纯文字的word文档,读取段落和段落里的文字。
先读取段落,代码如下:
1 '''
2 #利用python读取word文档,先读取段落
3 '''
4 #导入所需库
5 from docx import Document
6
7 #打开word文档
8 document = Document("D:/路径/长恨歌.docx")
9
10 #获取所有段落
11 all_paragraphs = document.paragraphs
12 #打印看看all_paragraphs是什么东西
13 print(type(all_paragraphs)) #<class 'list'>,打印后发现是列表
14 #是列表就开始循环读取
15 for paragraph in all_paragraphs:
16 #打印每一个段落的文字
17 print(paragraph.text)
效果:
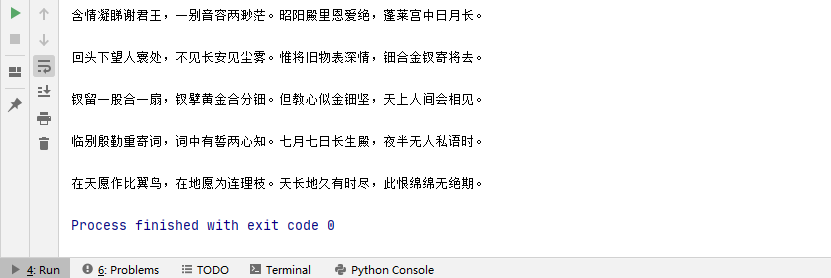
再读取段落里的内容,代码如下:
1 '''
2 #利用python读取word文档
3 '''
4 #导入所需库
5 from docx import Document
6
7 #打开word文档
8 document = Document("D:/路径/长恨歌.docx")
9
10 #获取所有段落
11 all_paragraphs = document.paragraphs
12 #打印看看all_paragraphs是什么东西
13 print(type(all_paragraphs)) #<class 'list'>,打印后发现是列表
14 #是列表就开始循环读取
15 for paragraph in all_paragraphs:
16 #打印每一个段落的文字
17 #print(paragraph.text)
18 #循环读取每个段落里的run内容
19 for run in paragraph.runs:
20 print(run.text) #打印run内容
效果如下:
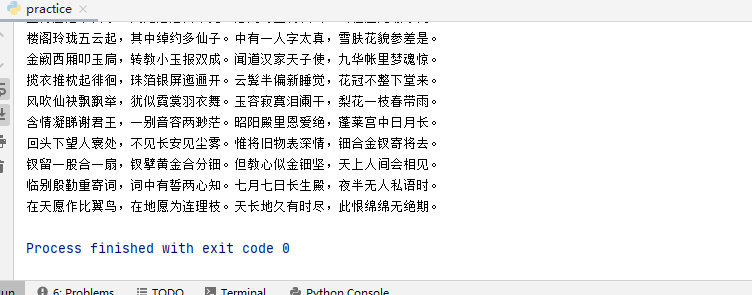
其实都准确的获取了文字内容,但是paragraph是保留了word文档里的换行符,而run是没有保留的。
2,利用python读取纯表格文档,那要读取的文字都是存储在单元格里,需要读取单元格里的内容:
1 '''
2 #利用python读取word文档,表格文档
3 '''
4 #导入所需库
5 from docx import Document
6
7 #打开文件
8 document = Document("D:/路径/长恨歌-表格.docx")
9 #获取文档所有表格
10 all_tables = document.tables
11
12 #打印all_tables类型
13 print(type(all_tables)) #得到<class 'list'>,即列表
14 #开始循环读取表格列表
15 for table in all_tables:
16 #循环读取表格的每一行
17 for row in table.rows:
18 #print(row)
19 #循环读取表格的每一个单元格
20 for cell in row.cells:
21 #打印单元格里的内容
22 print(cell.text) #打印
3,利用python读取word文档,文档是表格加文字组合而成的。这个就设计word文档格式问题了。将要处理的word文档后缀名改为zip,发现也可以打开,里面有几个文件如图:
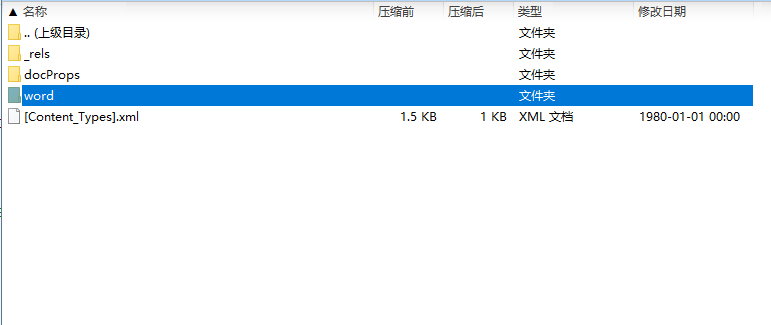
点开word目录,发现有个document.xml,这就是我们要处理的文件。

代码开始:
1 '''
2 #利用python读取word文档,表格文档
3 '''
4 #导入所需库
5 import zipfile #解压文件库
6 #先将要处理的word文档用zipfile进行压缩
7 word = zipfile.ZipFile('D:/路径/长恨歌-文字+表格.docx')
8
9 #找到要处理的xml文件并以utf-8的格式读取
10 xml = word.read('word/document.xml').decode('utf-8')
11 #打印看看
12 #print(type(xml)) #字符串
13 #print(xml) #打印整个字符串
14 #接下来分割字符串并存储到列表中
15 xml_list = xml.split('<w:t>') #以字符串<w:t>进行分割字符串
16 #打印看是否符合预期
17 #print(type(xml_list)) #是列表
18 #print(xml_list) #列表内容
19
20 #开始切片,找标签</w:t>
21 text_list = [] #新建空list用以存储切出来的数据
22 #开始循环读取列表xml_list
23 for i in xml_list:
24 #条件查找
25 if i.find('</w:t>') + 1: #切片查找是如果没找到是会返回-1,我们+1让他返回0,再运行else分支
26 text_list.append(i[:i.find('</w:t>')]) #如果不是返回0就把找到的依次追加到text_list末尾
27 else:
28 pass
29 #print(text_list)
30 #再将得到的列表拆分为字符串
31 text = ''.join(text_list) #以空字符串为间隔,将列表拆分为字符串
32 print(text)
第三个表格加文字的取出文字有点绕,多处理几遍就行了。
Python读取word文档内容的更多相关文章
- Python读取word文档(python-docx包)
最近想统计word文档中的一些信息,人工统计的话...三天三夜吧 python 不愧是万能语言,发现有一个包叫做 docx,非常好用,具体查看官方文档:https://python-docx.read ...
- C#读取Word文档内容代码
首先要添加引用com组件:然后引用: using Word = Microsoft.Office.Interop.Word; 获取内容: /// /// 读取 word文档 返回内容 /// //// ...
- ASP 读取Word文档内容简单示例
以下通过Word.Application对象来读取Doc文档内容并显示示例. 下面进行注册Word组件:1.将以下代码存档命名为:AxWord.wsc XML code复制代码 <?xml ve ...
- 2018-10-04 [日常]用Python读取word文档中的表格并比较
最近想对某些word文档(docx)的表格内容作比较, 于是找了一下相关工具. 参考Automate the Boring Stuff with Python中的word部分, 试用了python-d ...
- python读取word文档
周末需要做一个统计word文档字数的问题,刚开始以为很简单,因为之前做过excel表格相关的任务,所以认为利用扩展模块应该比较简单. 通过搜索,确实搜到了一个python操作word的模块,pytho ...
- 使用NPOI读取Word文档内容并进行修改
前言 网上使用NPOI读取Word文件的例子现在也不少,本文就是参考网上大神们的例子进行修改以适应自己需求的. 参考博文 http://www.cnblogs.com/mahongbiao/p/376 ...
- Python读取本地文档内容并发送邮件
当需要将本地某个路径下的文档内容读取后并作为邮件正文发送的时候可以参考该文,使用到的模块包括smtplib,email. #! /usr/bin/env python3 # -*- coding:ut ...
- ASP 读取Word文档内容简单示例_组件开发_新兴网络_20161014161610.jpg
- 使用python编辑和读取word文档
python调用word接口主要用到的模板为python-docx,基本操作官方文档有说明. python-docx官方文档地址 使用python新建一个word文档,操作就像文档里介绍的那样: fr ...
随机推荐
- Java基础教程——线程池
启动新线程,需要和操作系统进行交互,成本比较高. 使用线程池可以提高性能-- 线程池会提前创建大量的空闲线程,随时待命执行线程任务.在执行完了一个任务之后,线程会回到空闲状态,等待执行下一个任务.(这 ...
- CentOS 7搭建本地yum源
问题 CentOS7.1安装rpm包时提示缺失包,有些包iso里面也没有,只能从外网yum,这种情况下,可以提前yum好所需的依赖包,做成一个本地yum源.将这些文件拷贝到没联网的机器就可以使用了. ...
- 团队作业第六次——Beta冲刺
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 这个作业要求在哪里 Beta 冲刺 这个作业的目标 团队进行Beta冲刺 作业正文 正文 其他参考文献 无 代码规范与计划 代码 ...
- 20190705_关于winform程序修改程序名后, 报未将对象引用设置到对象的实例
winform做了一个小项目, 其中要用到数据库连接, 字符串, private string ConnStringSource = System.Configuration.Configuratio ...
- MVTMVC 区别
1,MVC的意思是 M:model V:views C:controller model是 主要是封装对数据库层的访问,对数据库中的数据进行增删改查操作 views 是 用于封装结果, 生程页面展示 ...
- 并发编程实战-J.U.C核心包
J.U.C - AQS java.util.concurrent(J.U.C)大大提高了并发性能,AQS 被认为是 J.U.C 的核心.它核心是利用volatile和一个维护队列. AQS其实就是ja ...
- PyQt(Python+Qt)学习随笔:QAbstractItemView的defaultDropAction属性
老猿Python博文目录 老猿Python博客地址# 一.概述 defaultDropAction属性用于控制QAbstractItemView及其子类的实例视图中拖放时放下的默认操作.该属性的类型为 ...
- PyQt(Python+Qt)学习随笔:Qt Designer中部件的快捷菜单策略(contextMenuPolicy)取值及含义
在Qt Designer中可以设置部件的快捷菜单策略,快捷菜单通过在部件上点击鼠标右键触发. 快捷菜单策略通过枚举类型Qt.ContextMenuPolicy来定义,对应枚举类型取值及含义如下: 通过 ...
- PyQt(Python+Qt)学习随笔:QAbstractItemView的autoScroll和autoScrollMargin属性
老猿Python博文目录 老猿Python博客地址 QAbstractItemView的autoScroll属性用于确认鼠标在视口边缘时是否自动滚动内容,默认值为True,autoScrollMarg ...
- Thread interrupt() 线程中断的详细说明
GitHub源码地址 原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 一个线程不应该由其他线程来强制中断或停止,而是应该由线程自己自行停止 ...