HBase的架构设计为什么这么厉害!
老刘是一名即将找工作的研二学生,写博客一方面是复习总结大数据开发的知识点,一方面是希望能够帮助和自己一样自学编程的伙伴。由于老刘是自学大数据开发,博客中肯定会存在一些不足,还希望大家能够批评指正,让我们一起进步!
今天为大家带来的内容是HBase的架构设计,讲讲HBase的架构设计为什么这么牛?本文内容不会很长,全是老刘总结的精华,大家不可错过!

1 背景
我们要提前知道两个问题,这两个问题的解决也恰好回答了HBase的架构设计为什么这么牛!
第一个问题是HBase作为一个分布式数据库,它是如何确保在海量数据中,做到低延时的随机读写的呢?
第二个问题是Hbase是如何确保在分布式架构中,保证数据安全的呢?
2 第一个问题解答
确保在海量数据中,低延时的随机读写,HBase真的花了很多心思,做了很多设计,下面让老刘给大家好好说一说!
2.1 内存+磁盘
这个设计在众多框架中都存在,这样做的好处是在数据安全性和数据操作效率之间做了一个权衡,既追求数据安全,也追求数据操作效率。
2.2 内存数据良好的数据结构
HBase为了确保数据操作有更高的效率,也为了保证内存中的数据刷写出来形成有序的文件,这句话是什么意思?什么是数据操作更加高效?
即内存文件为了保证插入删除数据等操作高效,数据有序,所以用到了ConcurentSkipListMap的数据结构!
2.3 范围分区+排序
海量数据做查询一般采用什么方法?
最粗暴的方式就是暴力扫描,但大家一般都不采用,道理都懂!所以我们一般会采用先排序,再范围分区+分段扫描的办法。那海量数据为了能够让数据有序,在采用插入数据过程中,怎么做到数据有序的呢?
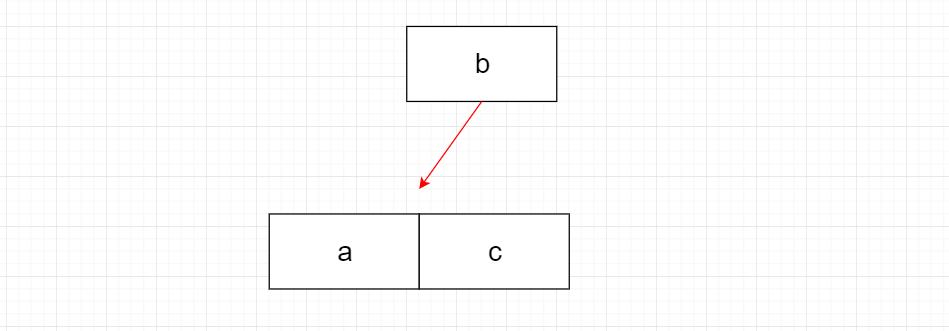
根据上图,老刘来解释下其中的道理,a先来c随后,最后b也来了,但我们如何做到把b放在a和c之间呢?
先把数据放在内存里面,a和c已经相邻,现在b来了,要保证abc这样的顺序,其实很容易做到,我们可以利用数组或链表,把c往后面挪,再把b插入进来,但内存有限,就需要每隔一段时间,把内存中数据写入到磁盘文件,磁盘里的文件就是有序,这样就能方便以后快速定位!
2.4 跳表Topo结构
这是什么意思呢?其实说的是HBase的寻址方式。
HBase的寻址方式分两种,一种是0.96版本之前,一种是0.96版本之后。
在HBase-0.96版本以前,HBase有两个特殊的表,分别是-ROOT-表和.META.表,其中-ROOT-的位置存储在ZooKeeper中,-ROOT-本身存储了.META. Table的RegionInfo信息 。寻址方式的流程如下:
- Client请求ZooKeeper获得-ROOT-所在的RegionServer地址。
- Client请求-ROOT-所在的RS地址,获取.META.表的地址,Client会将-ROOT-的相关信息cache下来,以便下一次快速访问。
- Client请求.META.表的RegionServer地址,获取访问数据所在RegionServer的地址,Client会将.META.的相关信息cache下来,以便下一次快速访问。
- Client请求访问数据所在RegionServer的地址,获取对应的数据。
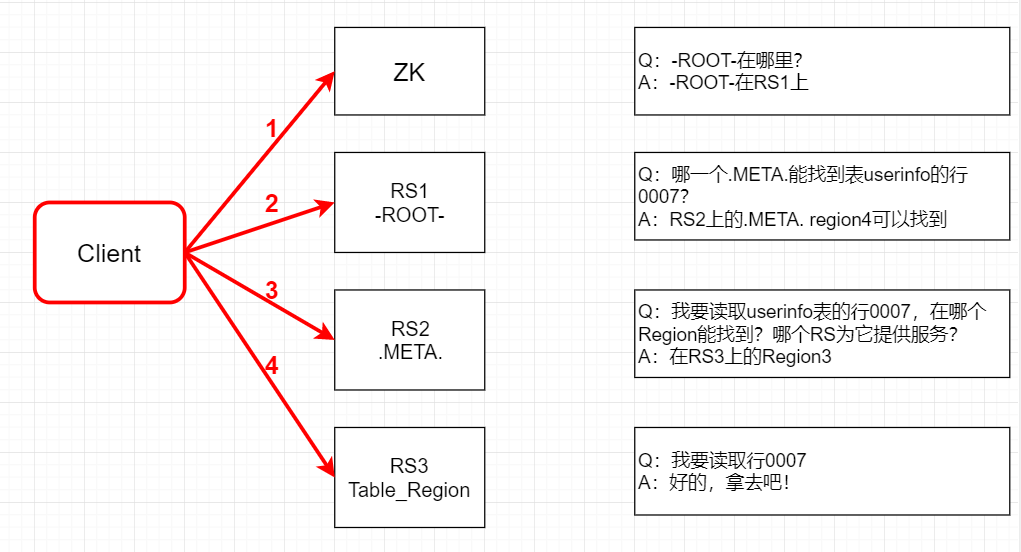
我们可以看出,用户需要3次请求才能知道用户表真正的位置,这在一定程度上带来性能的下降。在0.96之前使用3层设计的主要原因是考虑到元数据可能需要很大。
那0.96版本之后的寻址流程如下:
- Client请求ZooKeeper获取.META.所在的RegionServer的地址。
- Client请求.META.所在的RegionServer获取访问数据所在的RegionServer地址,Client会
将.META.的相关信息cache下来,以便下一次快速访问。 - Client请求数据所在的RegionServer,获取所需要的数据。
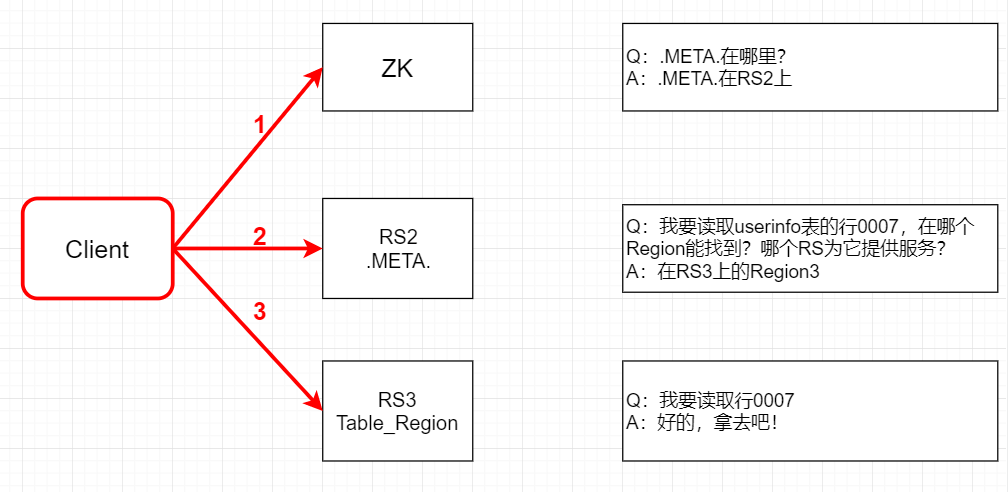
去掉-ROOT-的原因主要就是HBase-1.x以后,默认每个region的最大大小为10G,之前是128M,现在就发现2层的结构已经满足集群的需求了,性能也相对提高了。
讲完Region寻址方式,回到正题跳表Topo结构,就拿0.96版本之前的讲,跳表有三层,第一层是user table,第二层是meta table,第三层是root table,那为什么要设计这样的跳表呢?
假设有一张表的数据特别大,一台服务器存不下来,就需要把这张表拆分成好几个部分(例如4个部分)。如果这张表再进行拆分的时候老早已经排好顺序,那拆分出来的数据应该是一段一段的,每一段就包含了这一段的所有数据。
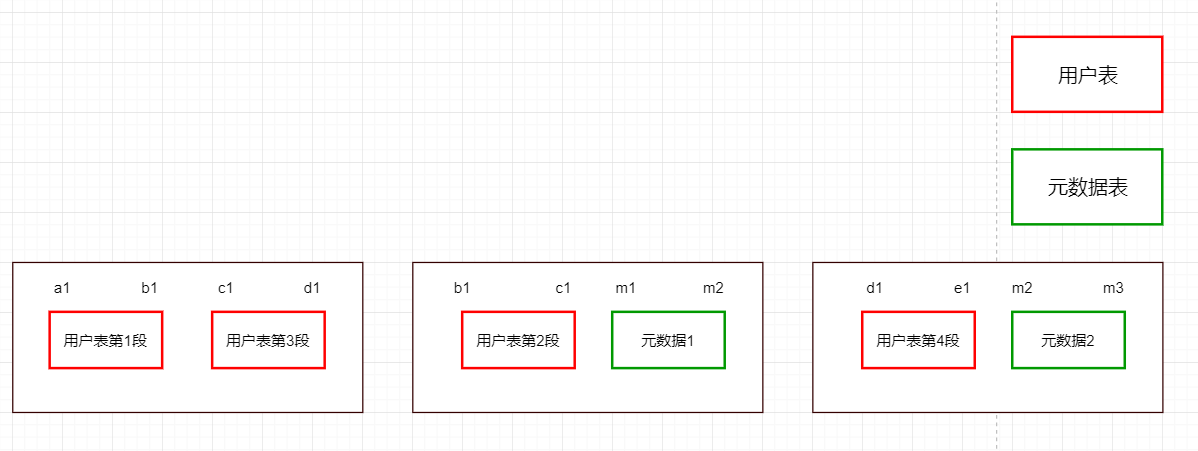
那客户端现在来查询数据,过来扫描数据,那它到底扫描哪一台服务器呢?我们不确定,可能每台服务器都要扫描一遍,这样做导致效率很差!
我们可以先去找一个中间机构去确认要找的数据在这4段中的哪一段,创建一个元数据表meta存真正数据的Region位置,先去找meta表。当元数据表变得特别大,也会切分多个段放在RegionServer中,这个时候就会提供一个ROOT表来确定meta表的位置。
这就形成了一种层级关系,从ROOT表跳到meta表跳到具体RegionServer。
形成跳表Topo结构降低了扫描次数,原来需要n次或4次扫描,现在变为1次扫描,性能得到提高,并且可以管理非常多的数据。
如何理解可以管理非常多的数据?
hbase1.0之前,每个Region默认大小是128M,每条元数据为1KB,那它就能存储1千多个元数据,那3层结构就会存储几千万上亿的记录。hbase1.0之后,每个Region默认大小是10G,两层结构能够存储的数据也足够大,满足集群需求。
2.5 读缓存+写缓存
内存分读缓存和写缓存,把经常查询的数据放在读缓存,可以提升效率。写缓存怎么扫描文件速率最高?就是利用内存+磁盘的方式,先把数据放在内存排序后,再把数据写入到磁盘中,这样磁盘里的文件就是有序的了,接着对磁盘文件二分查找,效率变高。
3 第二个问题解答
为了确保在分布式架构中,数据的安全,HBase怎么做?
3.1 内存+磁盘
HBase采用了内存+磁盘存储的方式,这样做的好处是在数据安全性和数据操作效率之间做了一个权衡,既追求数据安全,也追求数据操作效率。
3.2 WAL机制
WAL意为Write Ahead Log,类似MySQL中的binlog,用来做灾难恢复之用。HBase为了防止数据写入缓存之后不会因RegionServer进程发生异常导致数据丢失,在写入缓存之前会首先将数据顺序写入到HLog(WAL)中。如果不幸一旦发生RegionServer宕机或者其他异常,这种设计可以从HLog中进行日志回放进行数据补救,保证数据不丢失。HBase故障恢复的最大看点就在于如何通过HLog回放补救丢失数据。
4 总结
好啦,HBase的架构设计大致聊得差不多了,老刘主要给大家讲了讲为什么HBase的架构设计这么牛。尽管当前水平可能不及各位大佬,但老刘还是希望能够变得更加优秀,能够帮助更多自学编程的伙伴。
如果有相关问题,请联系公众号:努力的老刘。如果觉得帮到了您,不妨点赞关注支持一波!

HBase的架构设计为什么这么厉害!的更多相关文章
- Solr与HBase架构设计
摘要:本篇是本人在做一个大数据项目时,对于系统架构的一点总结,如何在保证存储量的情况下,又能保证数据的检索速度. 前提: Solr.SolrCloud提供了一整套的数据检索方案,HBase提 ...
- 【大数据技术】HBase与Solr系统架构设计
如何在保证存储量的情况下,又能保证数据的检索速度. HBase提供了完善的海量数据存储机制,Solr.SolrCloud提供了一整套的数据检索方案. 使用HBase搭建结构数据存储云,用来存储海量数据 ...
- 架构师必备:HBase行键设计与应用
首先要回答一个问题,为何要使用HBase? 随着业务不断发展.数据量不断增大,MySQL数据库存在这些问题: MySQL支持的数据量为TB级,不能一直保留历史数据.而HBase支持的数据量为PB级,适 ...
- 【JAVA进阶架构师指南】之一:如何进行架构设计
前言 本博客是长篇系列博客,旨在帮助想提升自己,突破技术瓶颈,但又苦于不知道如何进行系统学习从而提升自己的童鞋.笔者假设读者具有3-5年开发经验,java基础扎实,想突破自己的技术瓶颈,成为一位优 ...
- 【转】Flume(NG)架构设计要点及配置实践
Flume(NG)架构设计要点及配置实践 Flume NG是一个分布式.可靠.可用的系统,它能够将不同数据源的海量日志数据进行高效收集.聚合.移动,最后存储到一个中心化数据存储系统中.由原来的Fl ...
- 两年内从零到每月十亿 PV 的发展来谈 Pinterest 的架构设计(转)
原文:Scaling Pinterest - From 0 To 10s Of Billions Of Page Views A Month In Two Years 译文:两年内从零到每月十亿 PV ...
- MySQL性能调优与架构设计-架构篇
架构篇(1) 读书笔记 1.Scale(扩展):从数据库来看,就是让数据库能够提供更强的服务能力 ScaleOut: 是通过增加处理节点的方式来提高整体处理能力 ScaleUp: 是通过增加当前处理节 ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
随机推荐
- 我的js公共函数合集
export default { isDefin: function(value) { //数据是否被定义 if (value == null || value == &quo ...
- 第四次作业 描述HDFS体系结构、工作原理与流程
1.用自己的图,描述HDFS体系结构.工作原理与流程. 读数据的流程 2.伪分布式安装Hadoop.
- thinkphp thinkphp6 安装JWT
第一步:composer安装 composer require firebase/php-jwt 下图是执行成功 cd 进入项目目录的vendor 找到firebase 看到下面有一个php-jw ...
- 【面试专栏】ArrayList 非线程安全案例并提供三种解决方案
1. 复现问题 import java.util.ArrayList; import java.util.List; import java.util.UUID; /** * 复现问题 * * @au ...
- 环境篇:Atlas2.1.0兼容CDH6.3.2部署
环境篇:Atlas2.1.0兼容CDH6.3.2部署 Atlas 是什么? Atlas是一组可扩展和可扩展的核心基础治理服务,使企业能够有效地满足Hadoop中的合规性要求,并允许与整个企业数据生态系 ...
- MySQL中的 ”SELECT FOR UPDATE“ 一次实践
背景 最近工作中遇到一个问题,两个不同的线程会对数据库里的一条数据做修改,如果不加锁的话,会得到错误的结果. 就用了MySQL中for update 这种方式来实现 本文主要测试主键.唯一索引和普通索 ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- solidworks 2018 因动态绘制边线显示视图延迟的解决方案
每次鼠标移动到一个物体上时总是会卡顿几秒,直到完成所有边线的绘制后才可以继续进行其他操作,这体验实在是不好. 解决方案很简单,只要取消这个默认开启的动态高亮显示就可以了. 1.去 选项->系统选 ...
- 服务器安装ESXI6.7
1 从官网下载ESXI镜像文件到本地 https://my.vmware.com/web/vmware/details?downloadGroup=ESXI670&productId=7 ...
- OSPF综合实验
实验要求: 1.R4为ISP,其上只能配置IP地址,R4与其他所有直连设备间使用共有IP 2.R3--R5/6/7为MGRE环境,R3为中心站点 3.整个OSPF环境IP地址为172.16.0.0/1 ...