无所不能的Embedding6 - 跨入Transformer时代~模型详解&代码实现
上一章我们聊了聊quick-thought通过干掉decoder加快训练, CNN—LSTM用CNN作为Encoder并行计算来提速等方法,这一章看看抛开CNN和RNN,transformer是如何只基于attention对不定长的序列信息进行提取的。虽然Attention is All you need论文本身是针对NMT翻译任务的,但transformer作为后续USE/Bert的重要组件,放在embedding里也没啥问题。以下基于WMT英翻中的任务实现了transfromer,完整的模型代码详见DSXiangLi-Embedding-transformer
模型组件
让我们先过一遍Transformer的基础组件,以文本场景为例,encoder和decoder的输入是文本序列,每个batch都pad到相同长度然后对每个词做embedding得到batch * padding_len * emb_size的输入向量
假设batch=1,Word Embedding维度为512,Encoder的输入是'Fox hunt rabbit at night', 经过Embedding之后得到1 * 5 * 512的向量,以下的模型组件都服务于如何从这条文本里提取出更多的信息
Attention
序列信息提取的一个要点在于如何让每个词都考虑到它所在的上下文语境
- RNN:上下文信息靠向后/前传递,从前往后传rabbit就能考虑到fox,从后往前传rabbit就能考虑到night
- CNN:靠不同kernel_size定义的局部窗口来获取context信息, kernel_size>=3,rabbit就能考虑到所有其他token的信息
- Attention:通过计算词和上下文之间的相关性(广义),来决定如何把周围信息(value)融合(weighted-average)进当前信息(query),下图来源Reference5
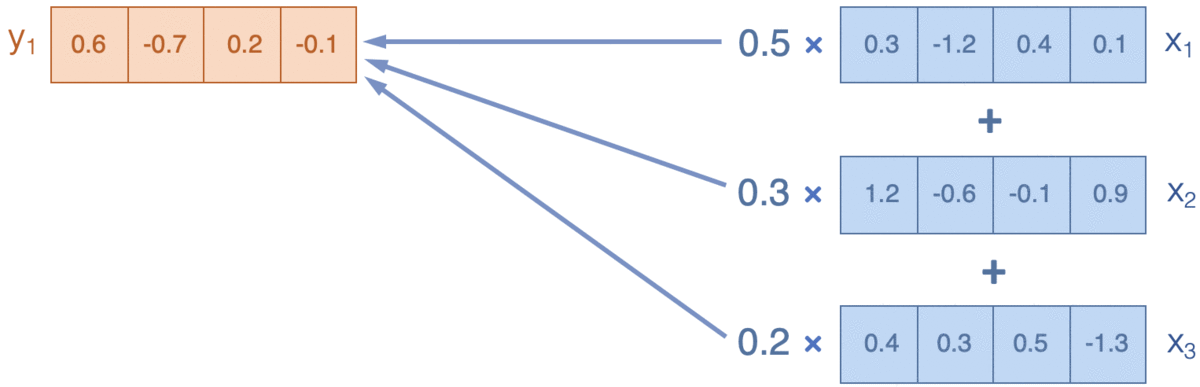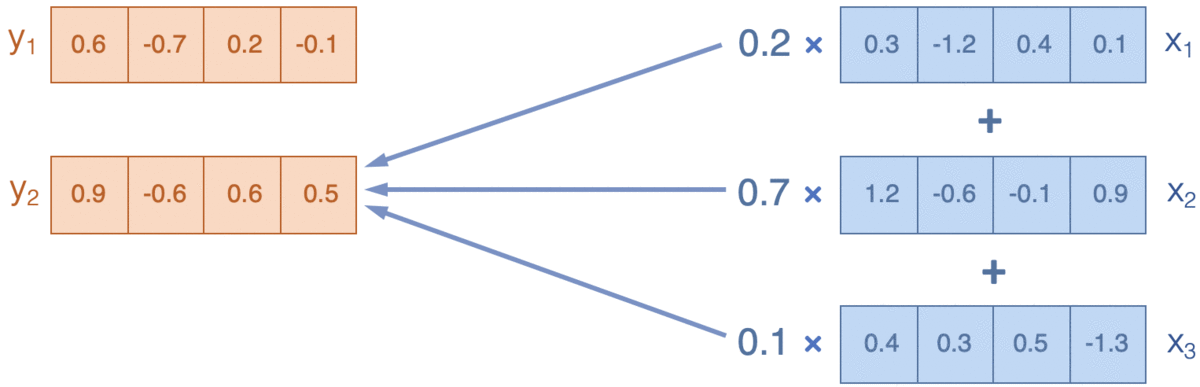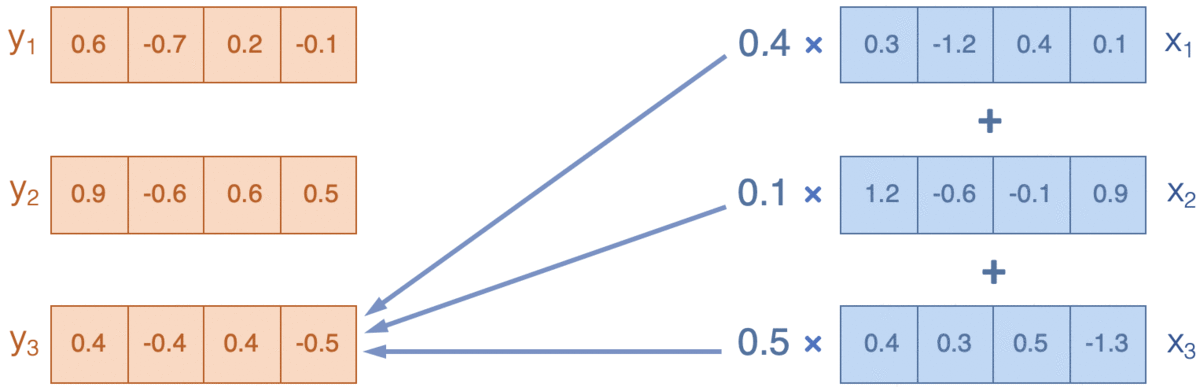
Transformer在attention的基础上有两点改良, 分别是Scaled-dot product attention和multi-head attention。
Scaled-dot product attention

Attention的输入是三要素query,key和value,通过计算query和Key的相关性,这里是广义的相关,可以通过加法/乘法得到权重向量,用权重对value做加权平均作为输出。‘fox hunt rabbit at night’会计算每个词对所有词的相关性,得到[5, 5]的相似度矩阵/权重向量,来对输入[5, 512]进行加权,得到每个词在考虑上下文语义后新的向量表达[5, 512]
Transformer在常规的乘法attention的基础上加入\(d_k\)维度的正则化。这里\(d_k\)是query和key的特征维度,在我们的文本场景下是embedding_size[512] 。正则化的原因是避免高维embedding的内积出现超级大的值,导致softmax的gradient非常小。
直观解释,假设query和key的每个元素都独立服从\(\mu=0 \, \sigma^2=1\)的分布, 那内积\(\sum_{d_k}q_ik_i\)就服从\(\mu=0 \, \sigma^2=d_k\)的分布,因此需要用\(\sqrt{d_k}\)做正则化,保证内积依旧服从\(\mu=0 \, \sigma=1\)的分布。
\]
def scaled_dot_product_attention(key, value, query, mask):
with tf.variable_scope('scaled_dot_product_attention', reuse=tf.AUTO_REUSE):
# scalaed weight matrix : batch_size * query_len * key_len
dk = tf.cast(key.shape.as_list()[-1], tf.float32)# emb_size
weight = tf.matmul(query, key, transpose_b=True)/(dk**0.5)
# apply mask: large negative will become 0 in softmax[mask=0 ignore]
weight += (1-mask) * (-2**32+1)
# normalize on axis key_len so that score add up to 1
weight = tf.nn.softmax(weight, axis=-1)
tf.summary.image("attention", tf.expand_dims(weight[:1], -1)) # add channel dim
add_layer_summary('attention', weight)
# weighted value: batch_size * query_len * emb_size
weighted_value = tf.matmul(weight, value )
return weighted_value
Mask
上面代码中的mask是做什么的呢?mask决定了Attention对哪些特征计算权重,transformer的mask有两种【以下mask=1是保留的部分,0是drop的部分】
其一是padding mask, 让attention的权重只针对真实文本计算其余为0。padding mask的dimension是[batch, 1, key_len], 1是预留给query,会在attention中被broadcast成[batch, query_len, key_len]
def seq_mask_gen(input_, params):
mask = tf.sequence_mask(lengths=tf.to_int32(input_['seq_len']), maxlen=tf.shape(input_['tokens'])[1],
dtype=params['dtype'])
mask = tf.expand_dims(mask, axis=1)
return mask
如果输入文本长度分别为3,4,5,都padding到5,padding mask维度是[3,1,5] 如下

其二是future mask只用于decoder,mask每个token后面的序列,保证在预测T+1的token时只会用到T及T以前的信息,如果不加future mask,预测T+1时就会用到T+1的文本本身,出现feature leakage。
def future_mask_gen(input_, params):
seq_mask = seq_mask_gen(input_, params) # batch_size * 1 * key_len
mask = tf.matmul(seq_mask, seq_mask, transpose_a=True) # batch_size * key_len * key_len
mask = tf.matrix_band_part(mask, num_lower=-1, num_upper=0)
return mask
还是上面的例子,future mask的维度是[3,5,5] 如下

multi-head attention

这些年对multi-head为啥有效的讨论有很多,下面Reference3~8都从不同方面给出了不同的Insight。最开始看multi-head的设计,第一反应是你莫不是在逗我?!你把掰成8瓣再拼回来告诉我这不是一个了???翻过来倒过去的琢磨感觉这个设计和CNN的filters似乎有些同一个配方,熟悉的味道~也没啥严谨的证明,要是跑偏了也请指正~
假设\(d_{model}=512\), \(head=8\), \(d_k=d_v=d_{model}/head=64\)
multi-head attention的计算过程是,每个head都进行如下操作
- 8个head的query,key,value各自过一层线性映射从维度从512->64,权重矩阵\(W \in R^{512*64}\),这里和single-head所需的parameter数量一致,single-head是直接做512->512的映射
- 映射后的query, key, value做scaled-dot product attention,得到batch * input_len * 64的输出
\]
再把8个head进行拼接,得到和输入相同维度\(d_{model}\)的输出,针对输出再做一步线性映射就齐活了。
\]
清楚计算方式我们来看下multi-head和single-head的差异。Single-head每个token, 会用全部512维的embedding来和其他token的embedding计算相关性。这里其实是存在bottleneck的,因为不论512维的信息多么丰富,也只能通过两两内积归一化后得到scaler来表达,多丰富的信息都会被平均,这一步是存在信息损失的。既然存在bottleneck,那何不降低\(d_{model}\)的维度,增加head呢。multi-head类似把[5,512]的输入,先reshape成[5,64,8],这里8类似CNN的channel,通过第一步的线性映射我们可能让每个head(channel)的key,query,value都分别关注不同信息,可能有的是语法,语义,语序等等,然后用降维到64维的embedding来计算Attention。从而在不增加parameter的条件下提取更多的信息。
def multi_head_attention(key, value, query, mask, params, mode):
with tf.variable_scope('multi_head_attention', reuse=tf.AUTO_REUSE):
d_model = value.shape.as_list()[-1] # emb_size
# linear projection with dimension unchaangned
new_key = tf.layers.dense(key, units=d_model, activation=None) # batch_size * key_len * emb_size
new_value = tf.layers.dense(value, units=d_model, activation=None)
new_query = tf.layers.dense(query, units=d_model, activation=None)
# split d_model by num_head and compute attention in parallel
# (batch_size * num_head) * key_len * (emb_size/num_head)
new_key = tf.concat(tf.split(new_key, num_or_size_splits=params['num_head'], axis=-1), axis=0)
new_value = tf.concat(tf.split(new_value, num_or_size_splits=params['num_head'], axis=-1), axis=0)
new_query = tf.concat(tf.split(new_query, num_or_size_splits=params['num_head'], axis=-1), axis=0)
# calculate dot-product attention
weighted_val = scaled_dot_product_attention(new_key, new_value, new_query, tf.tile(mask, [params['num_head'], 1, 1]))
# concat num_head back
# (batch_size * num_head) * query_len * (emb_size/num_head) -> batch_size * query_len * emb_size
weighted_val = tf.concat(tf.split(weighted_val, num_or_size_splits=params['num_head'], axis=0), axis=-1)
# Linear projection
weighted_val = tf.layers.dense(weighted_val, units=d_model, activation=None)
# Do dropout
weighted_val = tf.layers.dropout(weighted_val, rate=params['dropout_rate'],
training=(mode == tf.estimator.ModeKeys.TRAIN))
add_layer_summary('raw_multi_head', weighted_val)
weighted_val = add_and_norm_layer(query, weighted_val)
return weighted_val
positional encoding
清楚了上面的multi-head的attention会发现有一个问题,就是attention的计算并没有考虑到词的相对和绝对位置,这意味着‘fox hunt rabbit at night’和'rabbit hunt fox at night'会有完全一样的向量表达。Transformer的处理是加入了positional encoding,模型的输入变为word embedding + positional encoding,因此要求positional encoding和embedding的维度相同都是\(d_{model}\)。
举个(以下句子去除停用词)
- 句1: Dog sit on chair
- 句2: Cat is sleeping on floor
要想全面的表达位置信息,transformer需要满足以下4个条件
- 相对距离: on和chair,on和floor, sit 和on, sleeping和on的相对距离都是1,它们之间的相对距离相同,且和绝对位置以及句子长度无关
- 绝对位置:dog和cat都是句子的第一个词,它们的绝对位置相同, encoding需要一致
- 句子长度:encoding需要能够generalize到训练样本中unseen的句子长度
如果我们用[0,句子长度],步长为1,不满足条件3,如果测试集出现更长的句子会无法处理。如果用[0,1], 步长为1/句长,不满足条件2,因为不同长度的句子步长代表的相对距离不一致。让我们看看Transformer是如何做encoding的
\begin{cases}
sin(pos /w_k),& \text{if i=2k}\\
cos(pos /w_k),& \text{if i=2k+1}
\end{cases}
\]
\]
因为PE不是trainable变量,所以可以在最开始算好,然后用输入的position去lookup的,实现如下
def positional_encoding(d_model, max_len, dtype):
with tf.variable_scope('positional_encoding'):
encoding_row = np.array([10000**((i-i%2)/d_model) for i in range(d_model)])
encoding_matrix = np.array([i/encoding_row for i in range(max_len)])
def sin_cos(row):
row = [np.cos(val) if i%2 else np.sin(val) for i, val in enumerate(row)]
return row
encoding_matrix = np.apply_along_axis(sin_cos, 1, encoding_matrix)
encoding_matrix = tf.cast(tf.constant(encoding_matrix), dtype)
return encoding_matrix
还是上面的句子,假设\(d_{model}=4\),Dog sit on chair的\(PE\)如下
d_{model} & \text{Dog} & \text{sit} & \text{on} & \text{chair} \\
\hline
0 & sin(\frac{0}{10000^{0/4}}) & sin(\frac{1}{10000^{0/4}}) & sin(\frac{2}{10000^{0/4}}) & sin(\frac{3}{10000^{0/4}}) \\
1 & cos(\frac{0}{10000^{0/4}}) & cos(\frac{1}{10000^{0/4}}) & cos(\frac{2}{10000^{0/4}}) & cos(\frac{3}{10000^{0/4}}) \\
2 & sin(\frac{0}{10000^{2/4}}) & sin(\frac{1}{10000^{2/4}}) & sin(\frac{2}{1000^{2/4}}) &sin(\frac{3}{1000^{2/4}}) \\
3 & cos(\frac{0}{10000^{2/4}}) & cos(\frac{1}{10000^{2/4}}) & cos(\frac{2}{10000^{2/4}}) & cos(\frac{3}{10000^{2/4}}) \\
\end{array}
\]
清楚计算方式后,不知道你是不是也有如下的困惑
- 这sin/cos的设计有何目的?肯定不是为了好看嘛
- \(w_k\)的计算又是为了啥?encoding不能是个scaler么?
第一个困惑要看下positional encoding的使用场景。之前提到positional encoding是直接加在word embedding上作为输出,之后会在计算attention的过程中在两两向量内积时被使用,可能会表达类似相对距离越近attention权重越高之类的信息。因此这里表达位置和距离是依赖encoding做向量乘法,而使用sin/cos的好处在于位移和绝对位置无关,也就是\(PE(pos+\Delta)=f(\Delta) * PE(pos)\),详细推导看这里Timo Denk's Blog, 以\(d_{model}=2\)为例,线性变换如下
sin(w_k, pos+\Delta) \\
cos(w_k, pos+\Delta)\\
\end{bmatrix}=
\begin{bmatrix}
cos(w_k,\Delta) & sin(w_k,\Delta) \\
-sin(w_k,\Delta) & cos(w_k,\Delta) \\
\end{bmatrix}
\cdot
\begin{bmatrix}
sin(w_k, pos) \\
cos(w_k, pos)\\
\end{bmatrix}
\]
第二个困惑也就是\(w_k\)在embedding维度的计算。有人说是为了和embedding做向量加法,但上面的线性变换只要有一个[sin,cos]对就能做到,那我把\(R^2\) broadcast到\(R^{d_{model}}\)不成么, 毕竟PE只是个常量并不trinable。这里\(w_k\)的计算是随着k的上升降低了sin/cos的Frequency, PE在不同pos随i的变化如下图

看个极端case当\(2k \to d_{model}\),PE会近似constant,其中\(sin(pos/k) \to 0\), \(cos(pos/k) \to 1\),和embedding结合来看,部分语义信息的提取更多依赖位置信息,自然也存和位置信息依赖较少或者无关的信息,在embedding纬度上做差异化的位置信息表达,可以帮助模型学到这一点~
Add & Norm
Transformer 每个Block之后都会都跟一层Add & Norm,也就是先做residua再做Layer Norm。如果Add & Norm是跟在multi-head Attention之后,这一层的计算便是 Layer_norm(x + multi-head(x))。
def layer_norm(x):
with tf.variable_scope('layer_normalization', reuse=tf.AUTO_REUSE):
d_model = x.shape.as_list()[-1]
epsilon = tf.constant(np.finfo(np.float32).eps)
mean, variance = tf.nn.moments(x, axes=-1, keep_dims=True)
x = (x - mean)/((variance + epsilon)**0.5) # do layer norm
kernel = tf.get_variable('norm_kernel', shape=(d_model,), initializer=tf.ones_initializer())
bias = tf.get_variable('norm_bias', shape=(d_model,),initializer=tf.zeros_initializer())
x= tf.multiply(kernel, x) +bias
return x
def add_and_norm_layer(x, sub_layer_x):
with tf.variable_scope('add_and_norm'):
x = tf.add(x, sub_layer_x)
x = layer_norm(x)
return x
Residual Connection
对于Residual Connection,还是推荐之前在CTR DeepCrossing里推荐过的一篇文章残差网络解决了什么,为什么有效?。
简单来说是为了解决网络退化的问题,既随着网络深度增加,网络的表现先是逐渐增加接近饱和,然后迅速下降。这里的下降并非指参数增加导致的过拟合,而是理论上如果10层便是最优解,而你的网络有20层,虽然20层包含了10层的信息,理论上后10层只要做恒等变化把第10层的结果传递出去就行,但结果却变得很差,原因更多怀疑是神经网络较难学习这种恒等变幻。
放在Transformer里除了以上的作用,也有传递底层词向量和positional encoding信息的作用,我们既希望通过串联的Attention来不断抽取更抽象底层的信息,但也同时希望向前传递Bag of words信息以及positional encoding携带的相对/绝对位置信息。Anyway残差结构都带着更多pratical science的经验主义,如果有其他的观点欢迎一起讨论哟~
Layer Normalization
LayerNorm也推荐一篇文章详解深度学习中的Normalization,BN/LN/WN
LayerNorm没有BatchNorm那么常用。Batch Norm的假设是所有样本的同一个特征(神经元)服从相同的分布,因此用采样的样本(mini-batch)来估计总体在某个特征上的均值和方差来做归一化。但BatchNorm对于sequence输入并不适用,因为不同输入的序列长度同一个特征有的样本有有的没有,自然不满足同分布的假设。而LayerNorm的假设是每个样本的某一层layer是同分布的,因此是每个样本自身计算stat来做归一化。
神经元有点抽象,让我们用传统ML来举个~ 一个预测债券价格的模型有2个特征:历史价格和做市商报价。多数情况下的归一化都是按列进行,所有样本的历史价格,做市商报价进行归一化,对应batch=全样本的BatchNorm。而LayerNorm对应每个样本的历史价格,做市商报价自己进行归一化,多数情况下因为不同特征的量纲不同很少做行正则。但如果不同债券的类型不同,多数在100少数在30,而所有特征都是不同来源的报价,这时对行做正则可能效果更好,因为特征间分布比样本间一致性更高。
回到transformer,这里的layer Norm是embedding的维度上进行正则化,也就是每个样本每个token的embedding自身做归一化。
Feed Forward Layer
每个Multi-head的Attention之后都会跟一个Feed Forward Blok, 是一个两层的全联接神经网络, 中间层是relu,既帮助Attention的输出提取更抽象的信息,也通过relu过滤无效信息保留更重要的部分。
\]
def ffn(x, params, mode):
with tf.variable_scope('ffn', reuse=tf.AUTO_REUSE):
d_model = x.shape.as_list()[-1] # emb_size
y = tf.layers.dense(x, units=params['ffn_hidden'], activation='relu')
y = tf.layers.dense(y, units=d_model, activation=None)
y = tf.layers.dropout(y, rate=params['dropout_rate'],
training=(mode == tf.estimator.ModeKeys.TRAIN))
y = add_and_norm_layer(x, y)
return y
模型实现
愉快的拼乐高时间到,我们来按照以下的模型图来组合上面的组件,分成encoding和decoding两个部分。我选了个英文->中文的翻译任务来实现transformer,完整代码详见DSXiangLi-Embedding-transformer

Encoder
Encoding的输入是padding的sequence先做词向量映射得到 batch * pad_len * emb_size的词向量矩阵, 再加上相同维度的positional encoding向量。计算部分比较简单是由6个self-attention layer串联构成。
每个self-attention layer都包括, multi-head attention,encoder source自身既是query也是key和value,过Add&Norm层同时保留变换前和变换后的信息,再过Feed Forward层做更多的信息提取,再过Add&Norm。这其中需要注意的便是所有操作的dimension都是\(d_{model}\),因此输入纬度不会被改变一直保持到Encoder输出。
def encode(self, features, mode):
with tf.variable_scope('encoding', reuse=tf.AUTO_REUSE):
encoder_input = self.embedding_func(features['tokens'], mode) # batch * seq_len * emb_size
self_mask = seq_mask_gen(features, self.params)
for i in range(self.params['encode_attention_layers']):
with tf.variable_scope('self_attention_layer_{}'.format(i), reuse=tf.AUTO_REUSE):
encoder_input = multi_head_attention(key=encoder_input, query=encoder_input, value=encoder_input,
mask=self_mask, params=self.params, mode=mode)
encoder_input = ffn(encoder_input, self.params, mode)
return ENCODER_OUTPUT(output=encoder_input, state=encoder_input[:, -1, :])
Decoder
Decoder和encoder一样也是6个layer串联。和Encoder相比只是在self-attention和FFN之间多了一层encoder-decoder attention,这时key和value是encoder的输出,query是decoder在self-attention之后的输出,学习的是encoder和decoder间的关联信息。
Decoding部分略复杂些在于训练和预测存在差异,原因是训练会使用teacher forcing用T以前的真实token预测T+1。而预测时真实token未知,因此需要使用loop先预测T=1,拿预测[0,1]去预测T=2,再不断滚动向前预测
以下是训练时使用Teacher Forcing的Demo,decoder的输入文本在source和target要做不同的处理, source第一个token加入\(\lt go\gt\)标记文本开始,如下

这样预测时默认从\(\lt go\gt\)开始,同时形成错位用source<=T的token预测T+1的token,刚好对齐target的第T个token,模型预测如下

以下是训练部分的Decoder
def _decode_helper(self, encoder_output, features, labels, mode):
decoder_input = self.embedding_func(labels['tokens'], mode) # batch * seq_len * emb
self_mask = future_mask_gen(labels, self.params)
encoder_mask = seq_mask_gen(features, self.params)
for i in range(self.params['decode_attention_layers']):
with tf.variable_scope('attention_layer_{}'.format(i), reuse=tf.AUTO_REUSE):
with tf.variable_scope('self_attention', reuse=tf.AUTO_REUSE):
decoder_input = multi_head_attention(key=decoder_input, value=decoder_input,
query=decoder_input, mask=self_mask,
params=self.params, mode=mode)
with tf.variable_scope('encode_attention', reuse=tf.AUTO_REUSE):
decoder_input = multi_head_attention(key=encoder_output.output, value=encoder_output.output,
query=decoder_input, mask=encoder_mask,
params=self.params, mode=mode)
decoder_input = ffn(decoder_input, self.params, mode)
# use share embedding weight for linear project from emb_size to vocab_size
logits = tf.matmul(decoder_input, self.embedding, transpose_b=True) # seq_len * emb_size->seq_len * target_vocab_size
return DECODER_OUTPUT(output=logits, state=decoder_input, seq_len=labels['seq_len'])
模型训练
论文中还有不少的训练细节,例如
- 每个layer之后都跟了drop out
- learning rate选取了先上升再下降的noam scheme
- 样本按句子长度排序
- 每个batch保证有近似的单词数,而非相同的句子数
以及在训练中发现batch_size太小模型完全不收敛等等。考虑这些细节比较task-specific(有点玄学),感兴趣的盆友们可以去看下Martin Popel的Training Tips for the Transformer Model,里面有更多的细节。后面我们更多只用到transformer的encoder部分来提取文本信息,这里就不多说啦~
Reference
- Attention is all you need,
- On Layer Normalization in the Transformer Architecture, 2020
- Analyzing Multi-Head Self-Attention:
Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned, 2019 - Multi-Head Attention: Collaborate Instead of Concatenate, 2020
- What Does BERT Look At? An Analysis of BERT’s Attention, 2019
- ON THE RELATIONSHIP BETWEEN SELF-ATTENTION AND CONVOLUTIONAL LAYERS,2020
- https://github.com/lena-voita/the-story-of-heads
- http://jbcordonnier.com/posts/attention-cnn/
- https://towardsdatascience.com/deconstructing-bert-part-2-visualizing-the-inner-workings-of-attention-60a16d86b5c1
- http://jalammar.github.io/illustrated-transformer/
- 详解深度学习中的Normalization,BN/LN/WN
- Transformer中warm-up和LayerNorm的重要性探究
- https://www.zhihu.com/question/341222779/answer/814111138
- https://github.com/Kyubyong/transformer
无所不能的Embedding6 - 跨入Transformer时代~模型详解&代码实现的更多相关文章
- 无所不能的Embedding 1 - Word2vec模型详解&代码实现
word2vec是google 2013年提出的,从大规模语料中训练词向量的模型,在许多场景中都有应用,信息提取相似度计算等等.也是从word2vec开始,embedding在各个领域的应用开始流行, ...
- 中文NER的那些事儿1. Bert-Bilstm-CRF基线模型详解&代码实现
这个系列我们来聊聊序列标注中的中文实体识别问题,第一章让我们从当前比较通用的基准模型Bert+Bilstm+CRF说起,看看这个模型已经解决了哪些问题还有哪些问题待解决.以下模型实现和评估脚本,详见 ...
- 中文NER的那些事儿2. 多任务,对抗迁移学习详解&代码实现
第一章我们简单了解了NER任务和基线模型Bert-Bilstm-CRF基线模型详解&代码实现,这一章按解决问题的方法来划分,我们聊聊多任务学习,和对抗迁移学习是如何优化实体识别中边界模糊,垂直 ...
- 云时代架构阅读笔记六——Java内存模型详解(二)
承接上文:云时代架构阅读笔记五——Java内存模型详解(一) 原子性.可见性.有序性 Java内存模型围绕着并发过程中如何处理原子性.可见性和有序性这三个特征来建立的,来逐个看一下: 1.原子性(At ...
- ASP.NET Core的配置(2):配置模型详解
在上面一章我们以实例演示的方式介绍了几种读取配置的几种方式,其中涉及到三个重要的对象,它们分别是承载结构化配置信息的Configuration,提供原始配置源数据的ConfigurationProvi ...
- ISO七层模型详解
ISO七层模型详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我刚刚接触运维这个行业的时候,去面试时总是会做一些面试题,笔试题就是看一个运维工程师的专业技能的掌握情况,这个很 ...
- 28、vSocket模型详解及select应用详解
在上片文章已经讲过了TCP协议的基本结构和构成并举例,也粗略的讲过了SOCKET,但是讲解的并不完善,这里详细讲解下关于SOCKET的编程的I/O复用函数. 1.I/O复用:selec函数 在介绍so ...
- 第94天:CSS3 盒模型详解
CSS3盒模型详解 盒模型设定为border-box时 width = border + padding + content 盒模型设定为content-box时 width = content所谓定 ...
- JVM的类加载过程以及双亲委派模型详解
JVM的类加载过程以及双亲委派模型详解 这篇文章主要介绍了JVM的类加载过程以及双亲委派模型详解,类加载器就是根据指定全限定名称将 class 文件加载到 JVM 内存,然后再转化为 class 对象 ...
随机推荐
- LeetCode563. 二叉树的坡度
题目 1 class Solution { 2 public: 3 int ans = 0; 4 int findTilt(TreeNode* root) { 5 postOrder(root); 6 ...
- windows下部署Grafana +prometheus平台监控
1.Prometheus简介 Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖.用户只需要下载对应平台包,解压并且添加基本的配置即可正常启Prometheus S ...
- Zju1100 Mondriaan
题目描述 有一个m行n列的矩阵,用1*2的骨牌(可横放或竖放)完全覆盖,骨牌不能重叠,有多少种不同的覆盖的方法? 你只需要求出覆盖方法总数mod p的值即可. 输入格式 三个整数数n,m,p,m< ...
- 忒修斯的Mac
我有一台Mac笔记本,用了快6年了,当初买它的时候还借了几千块. 三年前,它的屏幕坏了,修理的方式就是直接换屏,而换屏其实就是上半部分连壳带屏幕整个换掉,简单的说:另一台电脑的上半身嫁接过来. 今年, ...
- C#高级编程第11版 - 第九章 索引
[1]9.1 System.String 类 String类中关键的方法.如替换,比较等. [2]9.1.1 构建字符串 1.String类依然有一个缺点:因为它是不可变的数据类型,这意味当你初始化一 ...
- jquery 数据查询
jquery 数据查询 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> & ...
- Excel 一张表最多能装下多少行多少列数据?
一个工作簿可以装下255张,那么每张工作表可以装下多少行多少列数据呢? 1.任意打开或新建一个Excel文档. 2.在文档中,找到其左上角的"文件"按钮,点击选择"选项& ...
- XCTF-easydex
前期工作 查壳,无.安装打开黑屏. 逆向分析 用jadx打开看看 什么都没有,但可以看一下AndroidManifest 可以看到这个是个纯C/C++写的,没有Java代码,是个NativeActiv ...
- Xctf-easyapk
Xctf-easyapk Write UP 前期工作 查壳 无壳 运行 没什么特别的 逆向分析 使用jadx反编译查看代码 先看看文件结构 MainActivity代码 public class Ma ...
- JVM 参数的设置及解析
JVM 参数的设置及解析 1.关于JVM配置: 2.Linux JVM设置: 1.关于JVM配置: 设置jvm内存的参数有四个: -Xmx 设置堆(Java Heap)最大值,默认值为物理内存的1/4 ...