ElasticSearch教程——分片、扩容以及容错机制(转学习使用)
一、Primary shard和replica shard机制
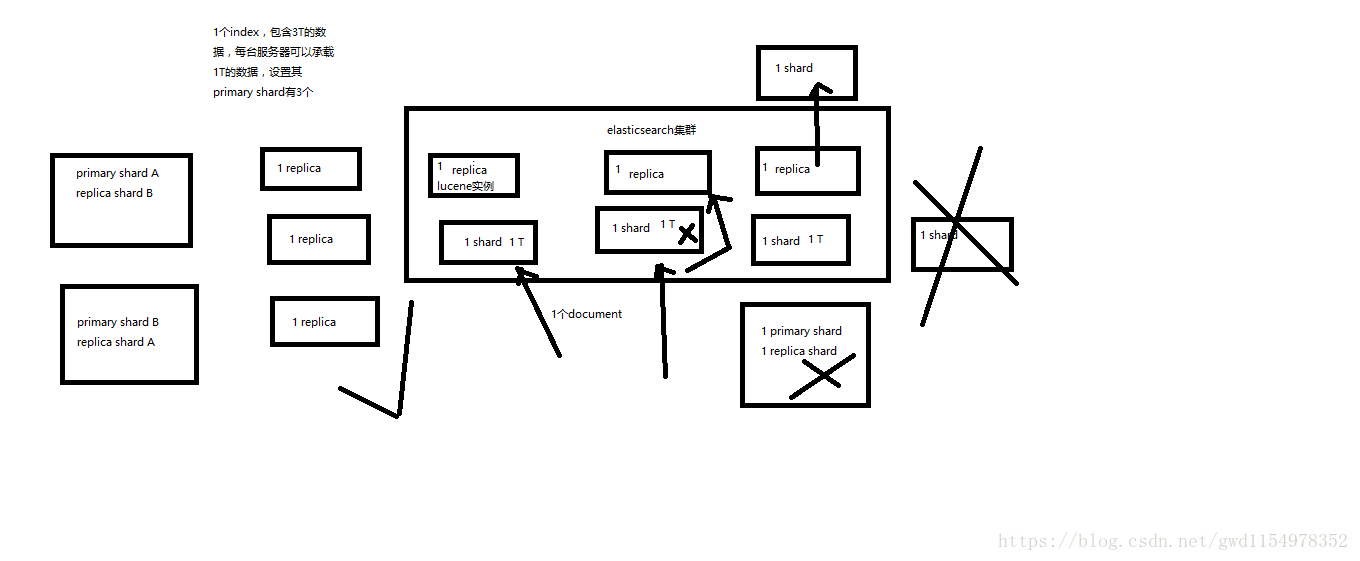
1、index包含多个shard;
2、每个shard都是一个最小的工作单元,承载部分的数据,Lucene实例,完整的简历索引和处理请求的能力;
3、增减节点时,shard会自动在nodes中负载均衡;
4、primary shard和replica shard,每一个document只会存在某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard中;
5、replica shard是primary shard的副本,负责容错,以及承担读请求负载(通常情况下可以让primary shard负责写,replica shard负责读,来实现读写分离)
6、primary shard的数量在创建的时候就固定了,replica shard的数量可以随时修改;
7、primary shard的默认数量是5,replica shard是1,默认有10个shard;其中5个primary shard以及5个replica shard;
8、primary shard和replica shard不能和自己的replica shard 放在一个节点中(这样规定是为避免节点宕机的时候,primary shard和replica shard数据都都丢失,起不到容错的作用),但是可以和其他的primary shard的replica shard放在同一个节点中;
三、性能扩容
就像上面说的primary shard 在创建的时候就已经固定了,不可以再修改。也就是说如果我在创建的时候设置了primary shard是3(6个shard,3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好。那如果我们的超出了上面所说的扩容极限了怎么办呢?primary shard不是不能修改么?
是的,primary shard 在创建后是不能修改的,但是replica shard可以添加啊,我们可以创建9个shard(3primary,6 replica),将服务器扩容到9台机器,吞吐量会大大增加,是3台服务器的三倍,当然为了提高容错率也可以在此基础上在每台服务器上部署多个shard(primary和replica不能在同一台服务器上)
四、容量扩容
上述的扩容指的是性能上的扩容(即高可用),但是在实际生活中可能会面临需要内存上扩容,他的极限就是每个primary shard部署单台服务器(3个primary shard分别部署3台服务器),所以在创建的时候自己要注意创建primary shard的数量,如果内存上问题还是不能解决,那么就需要通过扩容磁盘和定期清理数据来解决内存问题了
五、容错机制
master node宕机后,会自动重新选举master,此时为red;
replica容错:新master是将replica提升为primary shard,此时为yellow(因为replica被升级为primary了,此时replica并不齐全);
重启宕机node,master copy replica到该node,但是该node使用原有的shard并同步宕机后的修改(即仅同步宕机后丢失的数据),此时为green;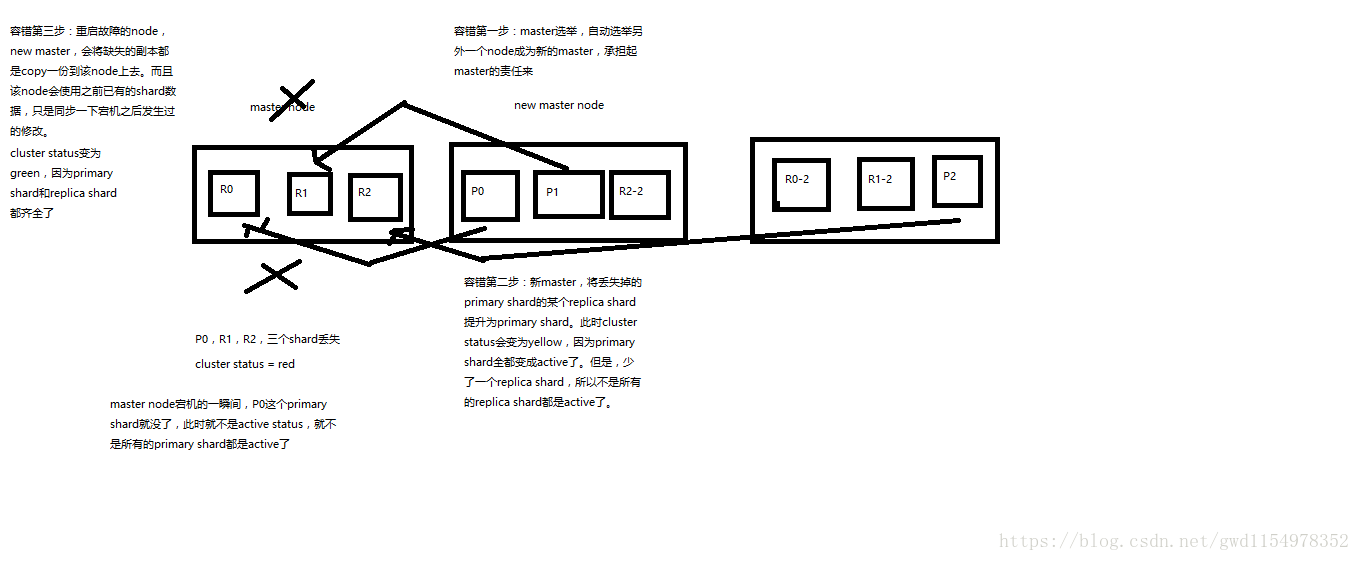
!
ElasticSearch教程——分片、扩容以及容错机制(转学习使用)的更多相关文章
- Elasticsearch由浅入深(二)ES基础分布式架构、横向扩容、容错机制
Elasticsearch的基础分布式架构 Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式系统,分布式是为了应对大数据量. Elasticsearch ...
- Elasticsearch 横向扩容以及容错机制
写在前面的话:读书破万卷,编码如有神-------------------------------------------------------------------- 参考内容: <Ela ...
- ElasticSearch教程——filter与query对比(转学习使用)
一.数据准备 PUT /company/employee/2 { "address": { "country": "china", &quo ...
- Elasticsearch和HDFS 容错机制 备忘
1.Elasticsearch 横向扩容以及容错机制http://www.bubuko.com/infodetail-2499254.html 2.HDFS容错机制详解https://www.cnbl ...
- (转)ElasticSearch教程——汇总篇
https://blog.csdn.net/gwd1154978352/article/details/82781731 环境搭建篇 ElasticSearch教程——安装 ElasticSearch ...
- ElasticSearch 分布式及容错机制
1 ElasticSearch分布式基础 1.1 ES分布式机制 分布式机制:Elasticsearch是一套分布式的系统,分布式是为了应对大数据量.它的特性就是对复杂的分布式机制隐藏掉. 分片机制: ...
- elasticsearch从入门到出门-08-Elasticsearch容错机制:master选举,replica容错,数据恢复
假如: 9 shard,3 node Elasticsearch容错机制:master选举,replica容错,数据恢复 最佳分配情况: 这样分配之后,不管其中哪个node 宕机这个es 依然可以提供 ...
- 第二章·Elasticsearch内部分片及分片处理机制介绍
一.副本分片介绍 什么是副本分片? 副本分片的主要目的就是为了故障转移,如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色. 在索引写入时,副本分片做着与主分片相同的工作.新文档首先被索引 ...
- 总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发. 本文主要内容如 ...
随机推荐
- Python文件操作函数os.open、io.open、内置函数open之间的关系
Python提供了多种文件操作方式,这里简单介绍os.open.io.open.内置函数open之间的关系: 一.内置函数open和io.open实际上是同一个函数,后者是前者的别名: 二.os.op ...
- 第二十二章、 Model/View便利类树型部件QTreeWidget
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.引言 树部件(Tree Widget)是Qt Designer中 Item Widgets(It ...
- Python(一) 快速配置Python编译环境与第一个py文件程序
1. Python基本语法在此不熬述. 2. 到管网下载Python 3.6.x 版本,与本机匹配的版本,如本机是 win7 64 python-3.6.5-amd64 3. 下载IDE:Python ...
- HDU3686 Traffic Real Time Query System
P.S.此题无代码,只有口胡,因为作者码炸了. 题目大意 给你一个有 \(n\) 个点, \(m\) 条边的无向图,进行 \(q\) 次询问,每次询问两个点 \(u\) \(v\),输出两个点的之间的 ...
- 移动 WEB 开发的布局方式 ---- 响应式布局
一.响应式简介 一个页面布局兼容了 PC端 ,iPad端 和 移动端 所谓的响应式就是页面中的布局会随着屏幕的大小变化发生了响应而做出不同的页面布局模型 特点: 响应式布局是不需要单独写移动端页面的 ...
- 【Ubantu 系统显示ip为127.0.0.1 解决办法】
现象:Ubantu : >>>ifconfig Link encap:以太网 硬件地址****************** inet 地址:127.0.0. ...
- CentOS6下的ElasticSearch运行步骤
如何运行ElasticSearch: 1.首先安装jdk1.8版本或以上. 2.下载elasticsearch的压缩包.(我下载的是elasticsearch-6.3.2.tar.gz) 3.使用命令 ...
- 查询id为键的数组
public static function getKeyValuePairs() { $sql = 'SELECT id, name FROM ' . self::tableName() . ' O ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- ThreadX——IPC应用之消息队列
作者:zzssdd2 E-mail:zzssdd2@foxmail.com 一.应用简介 消息队列是RTOS中常用的一种数据通信方式,常用于任务与任务之间或是中断与任务之间的数据传递.在裸机系统中我们 ...