大型Kubernetes集群的资源编排优化
背景
云原生这个词想必大家应该不陌生了,容器是云原生的重要基石,而Kubernetes经过这几年的快速迭代发展已经成为容器编排的事实标准了。越来越多的公司不论是大公司还是中小公司已经在他们的生产环境中开始使用Kubernetes, 原生Kubernetes虽然已经提供了一套非常完整的资源调度及管理方案但是在实际使用过程中还是会碰到很多问题:
- 集群节点负载不均衡的问题
- 业务创建Pod资源申请不合理的问题
- 业务如何更快速的扩容问题
- 多租户资源抢占问题
这些问题可能是大家在使用Kubernetes的过程中应该会经常遇到的几个比较典型的资源问题,接下来我们将分别介绍在腾讯内部是如果解决和优化这些问题的。
集群节点负载不均衡的问题
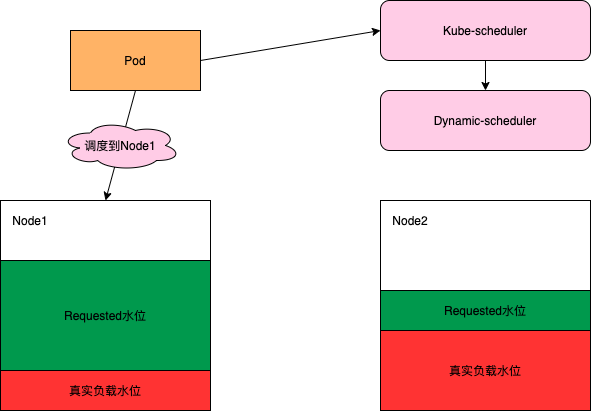
我们知道Kubernetes原生的调度器多是基于Pod Request的资源来进行调度的,没有根据Node当前和过去一段时间的真实负载情况进行相关调度的决策。这样就会导致一个问题在集群内有些节点的剩余可调度资源比较多但是真实负载却比较高,而另一些节点的剩余可调度资源比较少但是真实负载却比较低, 但是这时候Kube-scheduler会优先将Pod调度到剩余资源比较多的节点上(根据LeastRequestedPriority策略)。

如上图,很显然调度到Node1是一个更优的选择。为了将Node的真实负载情况加到调度策略里,避免将Pod调度到高负载的Node上,同时保障集群中各Node的真实负载尽量均衡,我们扩展了Kube-scheduler实现了一个基于Node真实负载进行预选和优选的动态调度器(Dynamic-scheduler)。
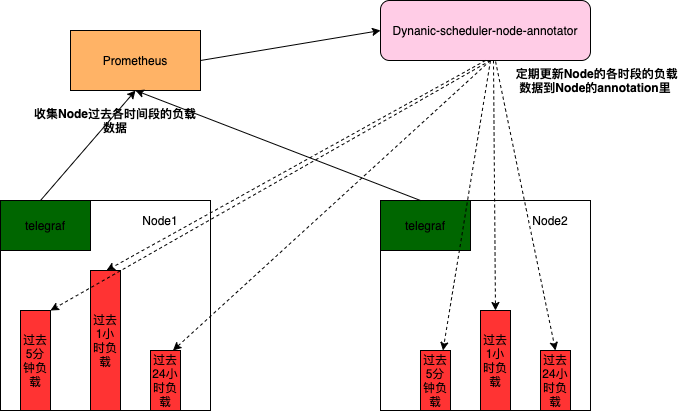
Dynamic-scheduler在调度的时候需要各Node上的负载数据,为了不阻塞动态调度器的调度这些负载数据,需要有模块定期去收集和记录。如下图所示node-annotator会定期收集各节点过去5分钟,1小时,24小时等相关负载数据并记录到Node的annotation里,这样Dynamic-scheduler在调度的时候只需要查看Node的annotation便能很快获取该节点的历史负载数据。
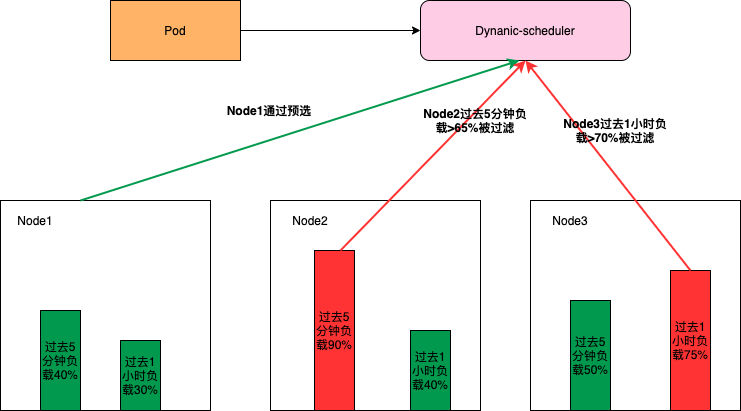
为了避免Pod调度到高负载的Node上,需要先通过预选把一些高负载的Node过滤掉,如下图所示(其中的过滤策略和比例是可以动态配置的,可以根据集群的实际情况进行调整)Node2过去5分钟的负载,Node3过去1小时的负载多超过了对应的域值所以不会参与接下来的优选阶段。
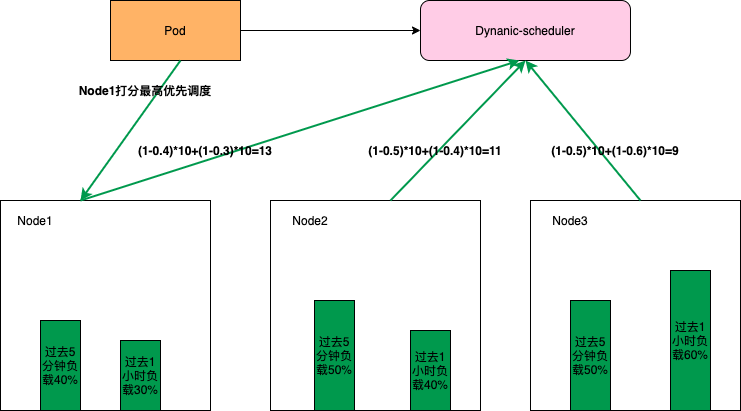
同时为了使集群各节点的负载尽量均衡,Dynamic-scheduler会根据Node负载数据进行打分, 负载越低打分越高。如下图所示Node1的打分最高将会被优先调度(这些打分策略和权重也是可以动态配置的)。
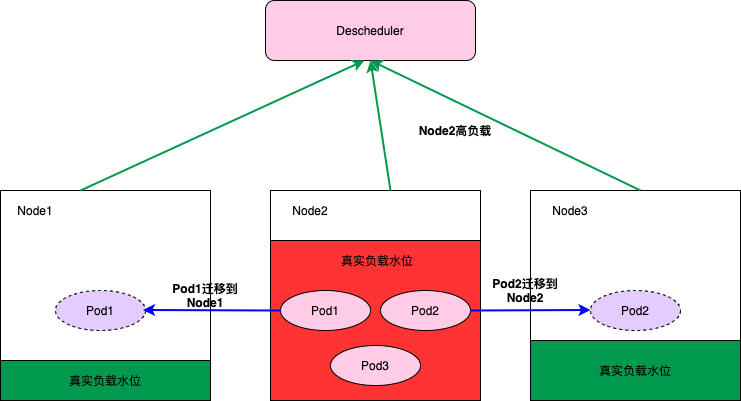
Dynamic-scheduler只能保证在调度的那个时刻会将Pod调度到低负载的Node上,但是随着业务的高峰期不同Pod在调度之后这个Node可能会出现高负载。为了避免由于Node的高负载对业务产生影响我们在Dynamic-scheduler之外还实现了一个Descheduler,它会监控Node的高负载情况将一些配置了高负载迁移的Pod迁移到负载比较低的Node上。
业务如何更快速的扩容问题
业务上云的一个重要优势就是在云上能实现更好的弹性伸缩,Kubernetes原生也提供了这种横向扩容的弹性伸缩能力(HPA)。但是官方的这个HPA Controller在实现的时候用的是一个Gorountine来处理整个集群的所有HPA的计算和同步问题,在集群配置的HPA比较多的时候可能会导致业务扩容不及时的问题,其次官方HPA Controller不支持为每个HPA进行单独的个性化配置。
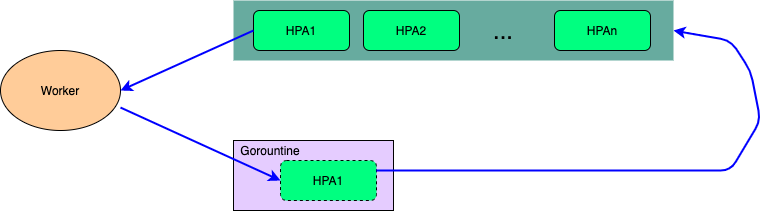
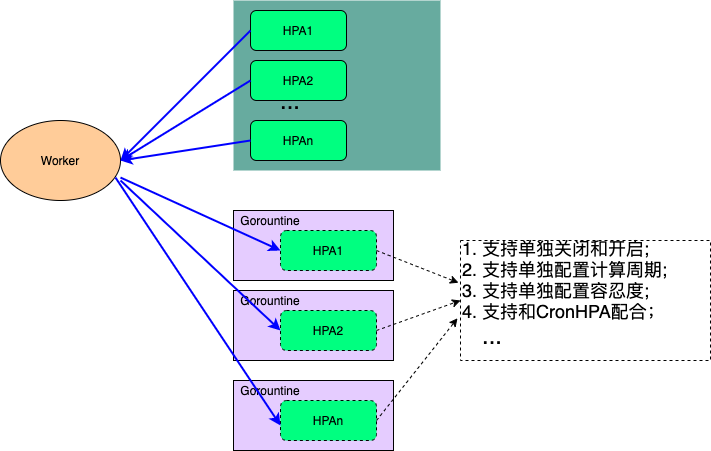
为了优化HPA Controller的性能和个性化配置问题,我们把HPA Controller单独抽离出来单独部署。同时为每一个HPA单独配置一个Gorountine,并且每一个HPA多可以根据业务的需要进行单独的配置。
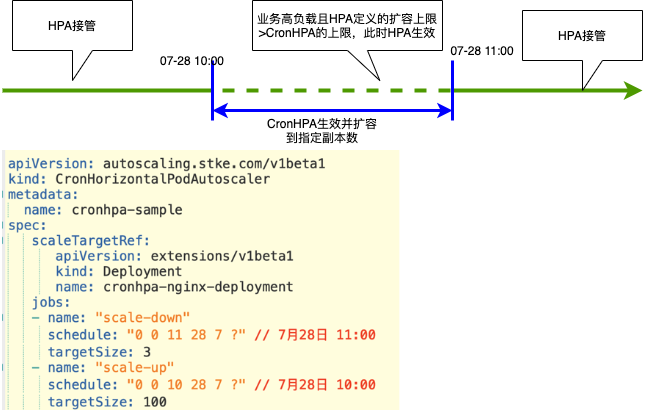
其实仅仅优化HPA Controller还是不能满足一些业务在业务高峰时候的一些需求,比如在业务做活动的时候希望在流量高峰期之前就能够把业务扩容好。这个时候我们就需要一个定时HPA的功能,为此我们定义了一个CronHPA的CRD和CronHPA Operator。CronHPA会在业务定义的时间进行扩容和缩容,同时还能和HPA一起配合工作。
业务创建Pod资源申请不合理的问题
通过Dynamic-scheduler和Descheduler来保障集群各节点的负载均衡问题。但是我可能会面临另一个比较头疼的问题就是集群的整体负载比较低但是可调度资源已经没有了,从而导致Pod Pending。这个往往是由于Pod 资源申请不合理或者业务高峰时段不同所导致的,那我们是否可以根据Node负载情况对Node资源进行一定比例的超卖呢。于是我们通过Kubernetes的MutatingWebhook来截获并修改Node的可调度资源量的方式来对Node资源进行超卖。
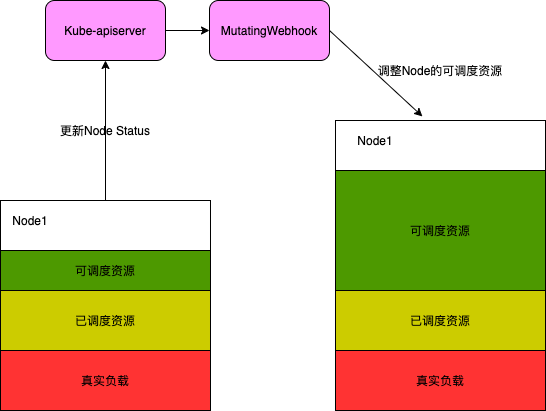
这里需要注意的是节点的超卖控制需要比较灵活不能一概而论,比如负载高的Node超卖比例应该要设置比较小或者不能设置超卖。
多租户资源抢占问题
当平台用户增多的时候,如果对资源不做任何控制那么各租户之间资源抢占是不可避免的。Kubernetes原生提供的ResourceQuota可以提供Namespace级别对资源配额限制。但是腾讯内部资源预算管理通常是按产品维度,而一个产品可能会包括很多Namespace的显然ResourceQuota不太适合这种场景。其次ResourceQuota只有资源限制功能不能做资源预留,当业务要做活动的时候不能保证活动期间有足够的资源可以使用。
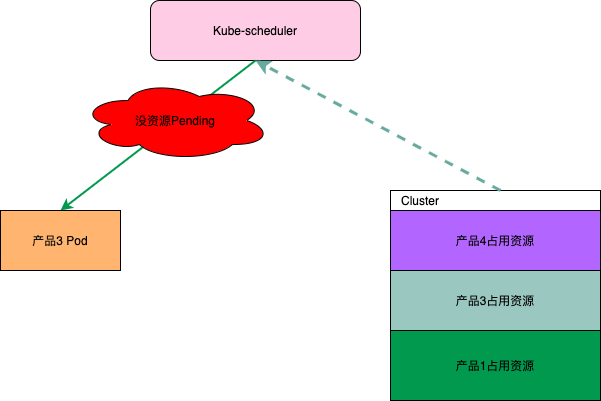
为了实现一个产品维度且有资源预留功能的配额管理功能,我们设计了一个DynamicQuota的CRD来管理产品在各集群的配额。如下图所示产品2在各集群所占的配额资源其它产品多无法使用。
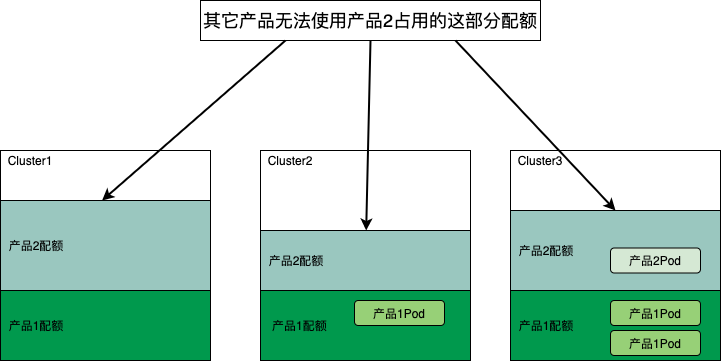
如果一个产品占用配额一直不使用就可能会导致平台资源的浪费,因此我们在产品配额预留的基础上提供了在不同产品间配额借调的功能。如下图所示产品1暂时不用的配额可以借调给产品2临时使用。
当平台有多集群的时候,产品配额需要如何分配。为了简化配下发操作,如下图所示管理员在下发产品配额的时候只需配置一个该产品的配额总量,配额下发模块会根据产品目前在各集群的使用情况按比例分配到各个集群。
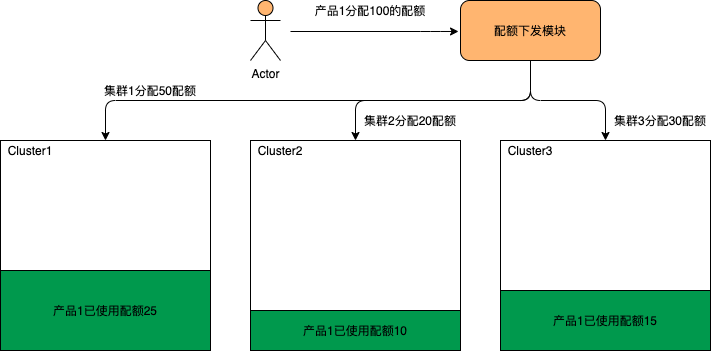
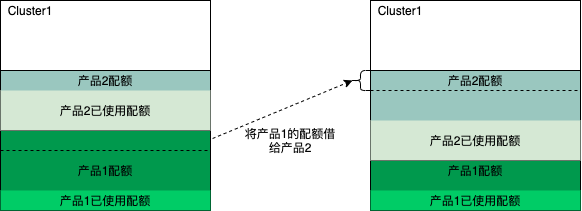
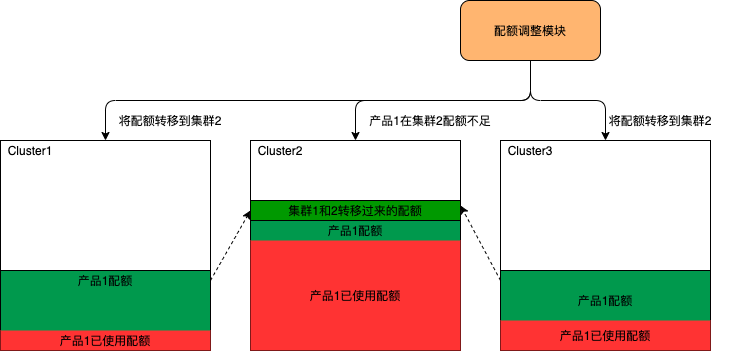
产品在各集群的资源使用情况是会时刻变化的,所以产品在各集群配额也需要根据业务的使用情况进行动态的调整。如下图所示产品在集群2中的配额已经快用完的时候,配额调整模块会动态的把配额从使用不多的集群1和集群3调到集群2。
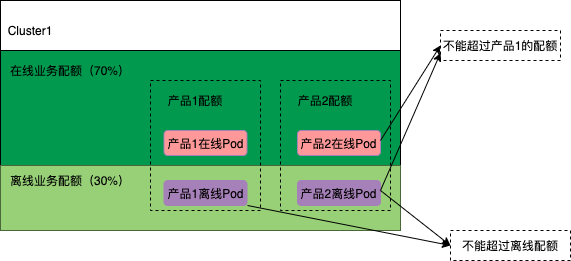
在线业务和离线业务混合部署是云平台的发展趋势,所以我们在设计配额管理的时候也把在离线配额控制考虑进去了。如下图所示我们在集群维度加了一个离线配额控制,一个集群的离线业务资源使用不能超过该集群总资源的30%(这个比例可以根据实际情况进行调整)。其次一个产品的在线业务和离线业务配额之和又不能超过产品在该集群的总配额。
总结
上面提到的方案只是简单说了一下我们的一些解决问题的思路,其实在真正运作的过程中还有很多细节需要考虑和优化。比如:上面提到的产品配额管理如果一个产品的配额不足了,这时候业务有高峰需要进行HPA扩容,这时候配额管理模块需要对这种扩容优化并放行。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

大型Kubernetes集群的资源编排优化的更多相关文章
- vivo 公司 Kubernetes 集群 Ingress 网关实践
文章转载自:https://mp.weixin.qq.com/s/qPqrJ3un1peeWgG9xO2m-Q 背景 vivo 人工智能计算平台小组从 2018 年底开始建设 AI 计算平台至今,已经 ...
- Kubernetes集群调度器原理剖析及思考
简述 云环境或者计算仓库级别(将整个数据中心当做单个计算池)的集群管理系统通常会定义出工作负载的规范,并使用调度器将工作负载放置到集群恰当的位置.好的调度器可以让集群的工作处理更高效,同时提高资源利用 ...
- 阿里云上万个 Kubernetes 集群大规模管理实践
点击下载<不一样的 双11 技术:阿里巴巴经济体云原生实践> 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击上方图片即可下载! 作者 | 汤志敏,阿里 ...
- Kubernetes集群
Kubernetes已经成为当下最火热的一门技术,未来一定也会有更好的发展,围绕着云原生的周边产物也越来越多,使得上云更加便利更加有意义,本文主要讲解一些蔚来汽车从传统应用落地到Kubernetes集 ...
- 二进制部署kubernetes集群(上篇)
1.实验架构 1.1.硬件环境 准备5台2c/2g/50g虚拟机,使用10.4.7.0/24 网络 .//因后期要直接向k8s交付java服务,因此运算节点需要4c8g.不交付服务,全部2c2g足够. ...
- 如何在 Kubernetes 集群中玩转 Fluid + JuiceFS
作者简介: 吕冬冬,云知声超算平台架构师, 负责大规模分布式机器学习平台架构设计与功能研发,负责深度学习算法应用的优化与 AI 模型加速.研究领域包括高性能计算.分布式文件存储.分布式缓存等. 朱唯唯 ...
- vivo大规模 Kubernetes 集群自动化运维实践
作者:vivo 互联网服务器团队-Zhang Rong 一.背景 随着vivo业务迁移到K8s的增长,我们需要将K8s部署到多个数据中心.如何高效.可靠的在数据中心管理多个大规模的K8s集群是我们面临 ...
- Airbnb的动态kubernetes集群扩缩容
Airbnb的动态kubernetes集群扩缩容 本文介绍了Airbnb的集群扩缩容的演化历史,以及当前是如何通过Cluster Autoscaler 实现自定义扩展器的.最重要的经验就是Airbnb ...
- 企业运维实践-还不会部署高可用的kubernetes集群?使用kubeadm方式安装高可用k8s集群v1.23.7
关注「WeiyiGeek」公众号 设为「特别关注」每天带你玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 文章目录: 0x00 前言简述 ...
随机推荐
- map进程数量和reduce进程数量
1-map task的并发数量是由切片的数量决定的,有多少个切片就有启动多少个map task: 2-切片是一个逻辑的概念,指的是文件中数据的偏移量范围: 3-切片的具体大小应该根据所处理的文件大小来 ...
- Chrome-AdGuard 无与伦比的广告拦截扩展
一款无与伦比的广告拦截扩展,对抗各式广告与弹窗. AdGuard 广告拦截器可有效的拦截所有网页上的所有类型的广告,甚至是在 Facebook.Youtube 以及其他万千网站上的广告! AdGuar ...
- C++基础面试题及答案
C++ C++ 和C的主要区别 C语言是面向过程编程,C++是面向对象编程,C++ 完全兼容C C++有哪些特性,简述对他们的理解 封装.继承.多态 封装 将的事物抽象成一个个集合(也就是所说的类), ...
- Java常用类:包装类,String,日期类,Math,File,枚举类
Java常用类:包装类,String,日期类,Math,File,枚举类
- ECS7天实践进阶训练营Day1:使用阿里云ECS,快速搭建、管理VuePress静态网站
一.概述 VuePress是2018年由尤雨溪发布的一个全新的基于Vue的静态网站生成器,它是一个非常轻量级的静态网站生成器.VuePress主要用于生成技术文档,其类似于Gitbook,我们可以用于 ...
- Who Am I? Personality Detection based on Deep Learning for Texts 阅读笔记
文章目录 源代码github地址 摘要 2CLSTM 过程 1. 词嵌入 2. 2LSTM处理 3. CNN学习LSGCNN学习LSG 4. Softmax分类 源代码github地址 https:/ ...
- menset与fill
menset函数一般只对int型数组进行0.-1的赋值.原因:menset对数组是按字节赋值,对每个字节的赋值是相同的,故int的4个字节全部被赋相同的值,而0正好二进制编码全为0,-1的二进制编码全 ...
- Hydra's plan
省选前的计划,实时更新(不知道能不能把挖的坑填完呢qwq) 链接
- 用心整理的 献丑啦 一些关于http url qs fs ...模块的方法
http: const http = require("http"); http.createServer((req , res)=>{ req:request 请求 ...
- .NET Core + K8S + Apollo 玩转配置中心
1.引言 Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境.不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限.流程治理等特性,适用于微服务配置管理 ...