MapReduce的工作流程
MapReduce的工作流程
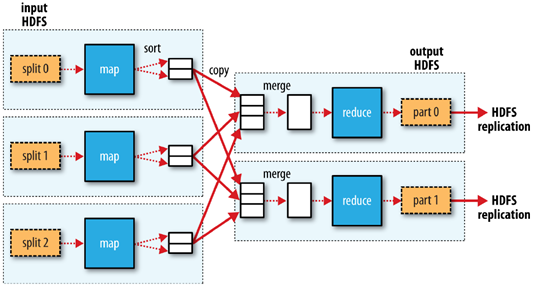
1.客户端将每个block块切片(逻辑切分),每个切片都对应一个map任务,默认一个block块对应一个切片和一个map任务,split包含的信息:分片的元数据信息,包含起始位置,长度,和所在节点列表等
2.map按行读取切片数据,组成键值对,key为当前行在源文件中的字节偏移量,value为读到的字符串
3.map函数对键值对进行计算,输出<key,value,partition(分区号)>格式数据,partition指定该键值对由哪个reducer进行处理。通过分区器,key的hashcode对reducer个数取模。
4.map将kvp写入环形缓冲区内,环形缓冲区默认为100MB,阈值为80%,当环形缓冲区达到80%时,就向磁盘溢写小文件,该小文件先按照分区号排序,区号相同的再按照key进行排序,归并排序。溢写的小文件如果达到三个,则进行归并,归并为大文件,大文件也按照分区和key进行排序,目的是降低中间结果数据量(网络传输),提升运行效率
5.如果map任务处理完毕,则reducer发送http get请求到map主机上下载数据,该过程被称为洗牌shuffle
6.可以设置combinclass(需要算法满足结合律),先在map端对数据进行一个压缩,再进行传输,map任务结束,reduce任务开始
7.reduce会对洗牌获取的数据进行归并,如果有时间,会将归并好的数据落入磁盘(其他数据还在洗牌状态)
8.每个分区对应一个reduce,每个reduce按照key进行分组,每个分组调用一次reduce方法,该方法迭代计算,将结果写到hdfs输出
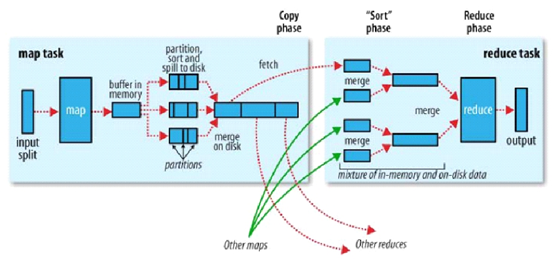
洗牌阶段
1.copy:一个reduce任务需要多个map任务的输出,每个map任务完成时间很可能不同,当只要有一个map任务完成,reduce任务立即开始复制,复制线程数配置mapred-site.xml参数“mapreduce.reduce.shuffle.parallelcopies",默认为5.
2.copy缓冲区:如果map输出相当小,则数据先被复制到reduce所在节点的内存缓冲区大小配置mapred-site.xml参数“mapreduce.reduce.shuffle.input.buffer.percent”,默认0.70),当内存缓冲区大小达到阀值(mapred-site.xml参数“mapreduce.reduce.shuffle.merge.percent”,默认0.66)或内存缓冲区文件数达到阀值(mapred-site.xml参数“mapreduce.reduce.merge.inmem.threshold”,默认1000)时,则合并后溢写磁盘。
3.sort:复制完成所有map输出后,合并map输出文件并归并排序
4.sort的合并:将map输出文件合并,直至≤合并因子(mapred-site.xml参数“mapreduce.task.io.sort.factor”,默认10)。例如,有50个map输出文件,进行5次合并,每次将10各文件合并成一个文件,最后5个文件。
K,V使用自定义数据类型
框架会对键,值序列化,因此键类型和值类型需要实现writable接口
框架会对键进行排序,因此必须实现writableComparable接口
MapReduce的工作流程的更多相关文章
- MapReduce简述、工作流程及新旧API对照
什么是MapReduce? 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查而且数出有多少张是黑桃. MapReduce方法则是: 1. 给在座的全部玩家中分配这摞牌. 2. 让每一个玩家数自己手 ...
- MapReduce与Yarn 的详细工作流程分析
MapReduce详细工作流程之Map阶段 如上图所示 首先有一个200M的待处理文件 切片:在客户端提交之前,根据参数配置,进行任务规划,将文件按128M每块进行切片 提交:提交可以提交到本地工作环 ...
- MapReduce工作流程及Shuffle原理概述
引言: 虽然MapReduce计算框架简化了分布式程序设计,将所有的并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,用户只需关注自己的应用程序的逻辑实现,提高了开发效率,但是开发如果对Map ...
- Hadoop随笔(一):工作流程的源码
一.几个可能会用到的属性值 1.mapred.map.tasks.speculative.execution和mapred.reduce.tasks.speculative.execution 这两个 ...
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- yarn工作流程
YARN 是 Hadoop 2.0 中的资源管理系统, 它的基本设计思想是将 MRv1 中的 JobTracker拆分成了两个独立的服务 : 一个全局的资源管理器 ResourceManager 和每 ...
- MapReduce的工作原理
MapReduce简介 MapReduce是一种并行可扩展计算模型,并且有较好的容错性,主要解决海量离线数据的批处理.实现下面目标 ★ 易于编程 ★ 良好的扩展性 ★ 高容错性 MapReduce ...
- kafka工作流程| 命令行操作
1. 概述 数据层:结构化数据+非结构化数据+日志信息(大部分为结构化) 传输层:flume(采集日志--->存储性框架(如HDFS.kafka.Hive.Hbase))+sqoop(关系型数 ...
- Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(二)
本文继<Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(一)>,接着讲述MapReduce作业在MRAppMaster上处理总流程,继上篇讲到作业初始化之后的作 ...
随机推荐
- 【应用服务 App Service】Azure 应用服务测试网络访问其他域名及请求超时限制(4分钟 ≈ 230秒)
测试App Service是否可以访问其他DNS 当应用服务(Azure App Service)创建完成后,想通过ping命令来查看是否可以访问其他站点或解析DNS,但是发现ping命令无法使用.这 ...
- Linux基础命令之.命令
. 点命令 .命令等同source 可以让配置文件被读到进程中,立刻生效
- 主流开源分布式图数据库 Benchmark
本文由美团 NLP 团队高辰.赵登昌撰写 首发于 Nebula Graph 官方论坛:https://discuss.nebula-graph.com.cn/t/topic/1377 1. 前言 近年 ...
- python第二章:控制流
变成实际上是一个过程的提现,每个过程都是有多个流程块组成. 比如:判断是否下雨的过程 1.布尔值 在第一章最后举例了比较操作后,最终返回的结果 True or False True 和 False是一 ...
- 对于72种常用css3的使用经验
对于72种常用css3的使用经验 保存网站源码 目的 保证有足够的css和js文件源码 拿到当前网页的整体布局 本地化 创建web项目 将web项目创建出来 在项目中创建一个文件夹 将所有的js和cs ...
- oracle 1day
1.主流数据库: 2.项目选择数据库的原则: 3.oracle 常用用户sys (sysdba系统管理员),system(sysoper系统操作员),scott(密码tiger) sys login: ...
- C# 9.0 新特性预览 - init-only 属性
C# 9.0 新特性预览 - init-only 属性 前言 随着 .NET 5 发布日期的日益临近,其对应的 C# 新版本已确定为 C# 9.0,其中新增加的特性(或语法糖)也已基本锁定,本系列文章 ...
- requestS模块发送请求的时候怎么传递参数
首先要确定接口的传递参数是什么类型的,如果接口是查询,使用get请求方法,传递参数的时候使用params, 如果接口需要的json型参数的话,使用json,如果是上传文件的话,通过files参数在传递 ...
- 初始化vue项目
1.创建vue项目命令 vue init webpack deaxios # 使用脚手架创建项目 deaxios(项目名,随便取得) cd deaxios # 进入项目 npm install axi ...
- python给图片添加文字
如何用几行代码给图片加上想要的文字呢? 下面为大家说下实现过程. 关注公众号 "轻松学编程"了解更多. 有图如下,想添加自写的诗句 诗句 静安心野 朝有赤羽暮落霞, 小舟载我湖旋停 ...