kafka的学习1
1.Kafka是什么?
Apache Kafka 是一款开源的分布式消息引擎系统。倘若“消息引擎系统”这个词对你来说有点陌生的话,那么“消息队列”“消息中间件”的提法想必你一定是有所耳闻的。不过说实话我更愿意使用消息引擎系统这个称谓,因为消息队列给出了一个很不明确的暗示,仿佛 Kafka 是利用队列的方式构建的;而消息中间件的提法有过度夸张“中间件”之嫌,让人搞不清楚这个中间件到底是做什么的。
像 Kafka 这一类的系统国外有专属的名字叫 Messaging System,国内很多文献将其简单翻译成消息系统。我个人认为并不是很恰当,因为它片面强调了消息主体的作用,而忽视了这类系统引以为豪的消息传递属性,就像引擎一样,具备某种能量转换传输的能力,所以我觉得翻译成消息引擎反倒更加贴切
2.'消息引擎系统' 又是什么?
维基百科的定义:消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
民间版:系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A 发送的消息。最基础的消息引擎就是做这点事的
不论是上面哪个版本,它们都提到了两个重要的事实:
- 消息引擎传输的对象是消息
- 如何传输消息属于消息引擎设计机制的一部分
既然消息引擎是用于在不同系统之间传输消息的,那么如何设计待传输消息的格式从来都是一等一的大事:一个比较容易想到的是使用已有的一些成熟解决方案,比如使用 CSV、XML 亦或是 JSON;又或者你可能熟知国外大厂开源的一些序列化框架,比如 Google 的 Protocol Buffer 或 Facebook 的 Thrift.
但是Kafka使用的是纯二进制的字节序列。当然消息还是结构化的,只是在使用之前都要将其转换成二进制的字节序列。
消息设计出来之后还不够,消息引擎系统还要设定具体的传输协议,即我用什么方法把消息传输出去。常见的有两种方法:
- 点对点模型:也叫消息队列模型。如果拿上面那个“民间版”的定义来说,那么系统 A 发送的消息只能被系统 B 接收,其他任何系统都不能读取 A 发送的消息。日常生活的例子比如电话客服就属于这种模型:同一个客户呼入电话只能被一位客服人员处理,第二个客服人员不能为该客户服务。
- 发布 / 订阅模型:与上面不同的是,它有一个主题(Topic)的概念,你可以理解成逻辑语义相近的消息容器。该模型也有发送方和接收方,只不过提法不同。发送方也称为发布者(Publisher),接收方称为订阅者(Subscriber)。和点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息。生活中的报纸订阅就是一种典型的发布 / 订阅模型。()
Kafka 同时支持这两种消息引擎模型。
消息引擎系统的另一大好处在于发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互。
3.为什么要学习kafka?
Kafka 能够有效隔离上下游业务,将上游突增的流量缓存起来,以平滑的方式传导到下游子系统中,避免了流量的不规则冲击。能够很好地应对数据量激增、数据复杂度增加以及数据变化速率变快,不仅如此,我们还能用 Kafka 实现消息引擎应用、应用程序集成、分布式存储构建,甚至是流处理应用的开发与部署。目前 Apache Kafka 被认为是整个消息引擎领域的执牛耳者,
4.Kafka中的术语
生产者:
向主题发布消息的客户端应用程序称为生产者(Producer),生产者程序通常持续不断地向一个或多个主题发送消息
消费者:
订阅这些主题消息的客户端应用程序就被称为消费者(Consumer)。和生产者类似,消费者也能够同时订阅多个主题的消息。
客户端:
生产者和消费者统称为客户端(Clients)。你可以同时运行多个生产者和消费者实例,这些实例会不断地向 Kafka 集群中的多个主题生产和消费消息。
服务器端:
Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化.
副本(replica):
Kafka实现高可用机制的手段之一的备份机制,备份的思想很简单,就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本。
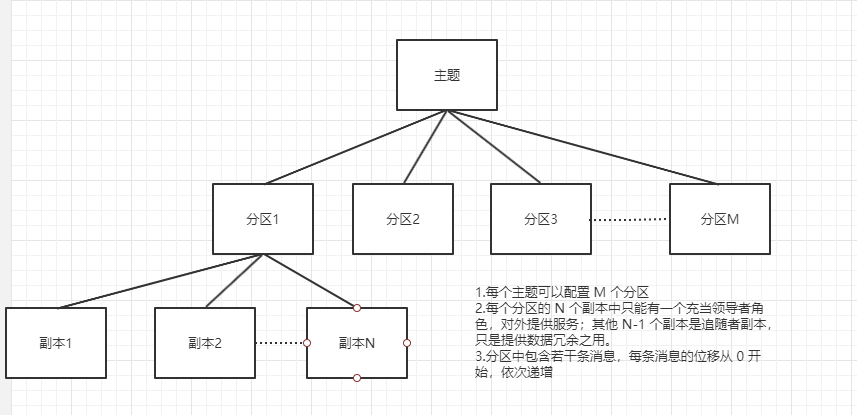
这些副本保存着相同的数据,但却有不同的角色和作用。Kafka 定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica
领导者副本(Leader Replica):
可以对外提供服务的称为领导者副本,这里的对外指的是与客户端程序进行交互。
追随者副本(Follower Replica):
只是被动地追随领导者副本而已,不能与外界进行交互。它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。常用于领导者副本发生故障无法对外提供服务时快速切换。
分区(Partitioning):
如果你了解其他分布式系统,你可能听说过分片、分区域等提法,比如 MongoDB 和 Elasticsearch 中的 Sharding、HBase 中的 Region,其实它们都是相同的原理,只是 Partitioning 是最标准的名称。Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),用于解决领导者副本积累的数据达到单台 Broker 机器磁盘空间上限的问题。
生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中
5.Kafka 的高可用,也即如何避免单点故障:
- Kafka 集群由多个 Broker 组成,将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务
- 备份机制,就是通过异步的方式把相同的数据拷贝到多台机器上,常用于领导者副本发生故障无法对外提供服务时快速切换。
思考:
1.为什么系统 A 不能直接发送消息给系统 B,中间还要隔一个消息引擎呢?
简单来说:“削峰填谷“
复杂来说:缓冲上下游瞬时突发流量,使其更平滑。特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”。但是,一旦有了消息引擎,它能够有效地对抗上游的流量冲击,真正做到将上游的“峰”填满到“谷”中,避免了流量的震荡。
举个例子:
在处理该订单会依次调用下游的多个子系统服务 ,比如调用支付宝和微信支付的接口、查询你的登录信息、验证课程信息等。显然上游的订单操作比较简单,它的 TPS 要远高于处理订单的下游服务,因此如果上下游系统直接对接,势必会出现下游服务无法及时处理上游订单从而造成订单堆积的情形。特别是当出现类似于秒杀这样的业务时,上游订单流量会瞬时增加,可能出现的结果就是直接压跨下游子系统服务。
2. 第一个问题有提到秒杀队列,Kafka是如何解决秒杀队列的问题?
当出现秒杀业务时,Kafka 能够将瞬时增加的订单流量全部以消息形式保存在对应的主题中,既不影响上游服务的 TPS,同时也给下游子服务留出了充足的时间去消费它们。这就是 Kafka 这类消息引擎系统的最大意义所在。
3. 下单这个操作涉及更新的数据库表有很多,对于一些可以同时更新的表可以怎么处理?前端一个请求怎么同时被后端多个服务同时处理?
当引入了 Kafka 之后。上游订单服务不再直接与下游子服务进行交互。当新订单生成后它仅仅是向 Kafka Broker 发送一条订单消息即可。类似地,下游的各个子服务订阅 Kafka 中的对应主题,并实时从该主题的各自分区(Partition)中获取到订单消息进行处理,从而实现了上游订单服务与下游订单处理服务的解耦
4. 为什么 Kafka 不像 MySQL 那样允许追随者副本对外提供读服务?
- Mysql的读写分离适用于读多写少的场景,但是Kafka涉及频繁地生产消息和消费消息,Kafka的读应该是一种像消费者push消息,同时持久化保存消息的过程。所以和mysql的读不一样。
- Kafka的主从同步是一种异步的机制,因此同一时刻主从会存在不一致性。如果从要提供读服务,又需要解决一下数据一致性的问题。主写从读无非就是为了减轻leader节点的压力,将读请求的负载均衡到follower节点,如果Kafka的分区相对均匀地分散到各个broker上,同样可以达到负载均衡的效果,没必要刻意实现主写从读增加代码实现的复杂程度
kafka的学习1的更多相关文章
- kafka基本原理学习
下载安装地址:http://kafka.apache.org/downloads.html 原文链接:http://www.jasongj.com/2015/01/02/Kafka深度解析 Kafk ...
- Kafka入门学习(一)
====常用开源分布式消息系统 *集群:多台机器组成的系统叫集群. *ActiveMQ还是支持JMS的一种消息中间件. *阿里巴巴metaq,rocketmq都有kafka的影子. *kafka的动态 ...
- Kafka入门学习随记(二)
====Kafka消费者模型 参考博客:http://www.tuicool.com/articles/fI7J3m --分区消费模型 分区消费架构图 图中kafka集群有两台服务器(Server), ...
- Kafka入门学习--基础
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就可 ...
- kafka初步学习
消息系统 什么是消息系统? 消息系统负责将数据从一个应用程序传输到另一个应用程序,因此应用程序可以专注于数据,但不担心如何共享它.分布式消息传递给予可靠消息队列的概念.消息在客户端应用程序和消息传递系 ...
- Kafka自我学习-报错篇
1. kafka启动出现:Unsupported major.minor version 52.0 错误, 具体的错误输出: Exception in thread "main" ...
- Kafka自我学习3-Scalable
1.After created the zookeeper cluster, we found all broker cluster topic can be find in zoo1, zoo2, ...
- Kafka自我学习2-Zookeeper cluster
Test enviroment : zoo1, zoo2, zoo3 cluster 1. Install zookeeper, package in kafka [root@zoo1 ~]# pwd ...
- Kafka自我学习1-Multi-broker cluster
====================================Testing environment =========================================== ...
- 大数据kafka视频教程 学习记录【B站尚硅谷 】
视频地址: https://www.bilibili.com/video/av35354301/?p=1 2019/03/06 21:59 消息队列的内部实现: Kafka基础: ...
随机推荐
- Esp8266 网络结构体
Esp8266建立网络连接相关结构体如下: 结构体头文件espconn.h /** Protocol family and type of the espconn */ enum espconn_ty ...
- 记一次线上服务CPU 100%的处理过程
告警 正在开会,突然钉钉告警声响个不停,同时市场人员反馈客户在投诉系统登不进了,报504错误.查看钉钉上的告警信息,几台业务服务器节点全部报CPU超过告警阈值,达100%. 赶紧从会上下来,SSH登录 ...
- scala 数据结构(十):折叠、扫描、拉链(合并)、迭代器
1 折叠 fold函数将上一步返回的值作为函数的第一个参数继续传递参与运算,直到list中的所有元素被遍历. 1)可以把reduceLeft看做简化版的foldLeft. 如何理解: def redu ...
- Scala 面向对象(十):特质(接口) 三
1 在特质中重写抽象方法特例 提出问题,看段代码 trait Operate5 { def insert(id : Int) } trait File5 extends Operate5 { def ...
- JVM 专题十四:本地方法接口
1. 本地方法接口 2. 什么是本地方法? 简单来讲,一个Native Method就是一个Java调用非Java代码的接口.一个Native Method是这样一个java方法:该方法的实现由非Ja ...
- nginx配置文件服务器——带说明
需求: 搭建一个文件服务器,提供指定软件下载,在访问文件服务器下载软件时,在访问的主页上要有对应的软件使用.安装等说明(本来是可以搞一个readme的,但这个在文件服务器上要下载还要打开,还不如直接显 ...
- Python Ethical Hacking - TROJANS Analysis(4)
Adding Icons to Generated Executables Prepare a proper icon file. https://www.iconfinder.com/ Conver ...
- 机房vscode使用方法
问题 众所周知,机房中的电脑有一个win7系统,(非常的好,摆脱linux了),同时win7上有一个 vscode ,更好了. 但是!vscode 由于老师不允许联网,导致插件无法安装,更为恶心的事, ...
- 题解 洛谷 P1552 【[APIO2012]派遣】
根据题意,我们不难发现忍者之间的关系是树形结构. 发现答案的统计只是在该节点的子树中,因此我们考虑通过树形\(DP\)来解决问题. 从叶子节点开始,从下往上考虑,因为一个节点的最优答案只与他的领导力和 ...
- 一文入门DNS?从访问GitHub开始
前言 大家都是做开发的,都有GitHub的账号,在日常使用中肯定会遇到这种情况,在不修改任何配置的情况下,有时可以正常访问GitHub,有时又直接未响应,来一起捋捋到底是为啥. GitHub访问的千层 ...